基础计算库numpy
思维导图
一、NumPy 介绍
NumPy(Numerical Python)是Python的⼀种开源的数值计算扩展。提供多维数组对象,各种派⽣对象(如掩码数组和矩阵),这种⼯具可⽤来存储和处理⼤型矩阵,⽐Python⾃身的嵌套列表(nested list structure)结构要⾼效的多(该结构也可以⽤来表示矩阵(matrix)),⽀持⼤量的维度数组与矩阵运算,此外也针对数组运算提供⼤量的数学函数库,包括数学、逻辑、形状操作、排序、选择、输⼊输出、离散傅⽴叶变换、基本线性代数,基本统计运算和随机模拟等等。
⼏乎所有从事Python⼯作的数据分析师都利⽤NumPy的强⼤功能。
- 强⼤的N维数组
- 成熟的⼴播功能
- ⽤于整合C/C++和Fortran代码的⼯具包
- NumPy提供了全⾯的数学功能、随机数⽣成器和线性代数功能
1.1安装
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
1.2引用
import numpy as np
二、掌握 NumPy 数组对象 ndarray
NumPy最核心的数据类型是N维数组(The N-dimensional array(ndarry))。
-
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。
-
数组:数组(Array)是有序的元素序列,在程序设计中,为了处理方便, 把具有相同类型的若干元素按有序的形式组织起来的一种形式。这些有序排列的同类数据元素的集合称为数组
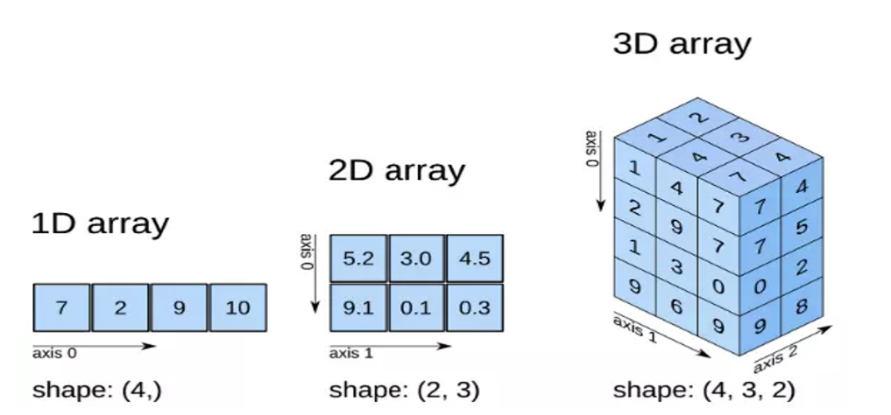
python列表和Numpy数组的区别
1. 列表list与数组array的定义:
列表是由一系列按特定顺序排列的元素组成,可以将任何东西加入列表中,其中的元素之间没有任何关系;Python中的列表(list)用于顺序存储结构。它可以方便、高效的的添加删除元素,并且列表中的元素可以是多种类型。
数组也就是一个同一类型的数据的有限集合。
2. 列表list与数组array的相同点:都可以根据索引来取其中的元素;
3. 列表list与数组array的不同点:
a.列表list中的元素的数据类型可以不一样。数组array里的元素的数据类型一般是一样的;
b.列表list不可以进行数学四则运算,数组array可以进行数学四则运算;
2.1区分列表和数组
import numpy as np
# 定义一个列表
a=[1,2,3,4]
print(a[0])
arr=np.array((1,2,3,4))
print(arr[0])
# # 数组的加法
print(arr+arr)
# # 数据的乘法
print(arr*6)
list1=[1,2,3,4]
list2=[2,3,4,5]
print(list1+list2)
for q,r in zip(list1,list2):
print(q+r)
data=[q+r for q,r in zip(list1,list2)]
print(data)
arr1=np.array(list1)
arr2=np.array(list2)
print(arr1*9)
2.2创建数组函数
numpy.zeros(shape, dtype=float) 创建指定大小的数组,数组元素以 0 来填充
numpy.ones(shape, dtype=float) 创建指定形状的数组,数组元素以 1 来填充
参数描述
shape: 指定行列数(通过list,tuple 的形式均可)
dtype: 数据类型,可选

import numpy as np
#3行3列为0的整型数组
print(np.zeros((3,3),dtype = int))
#3行3列为1的整型数组
print(np.ones((3,3),dtype=int))
2.3用已有数据创建数组 — 数据类型转换
numpy.asarray(a, dtype = None)
numpy.array(object, dtype = None)
参数描述
a 或 object : 任意形式的输入参数,可以是,列表, 元组, 可以多维
dtype: 数据类型,可选
主要区别就是当数据源是ndarray时 asarray为浅拷贝(原数据变化后,新数组也变化),array 为深拷贝(原数据变化后,新数组不变化)
# 验证np.array 与 np.asarray 的区别,np.asarray为浅拷贝
arr1 = np.ones((3,3),dtype=int)
asarr = np.asarray(arr1)
ar_arr1 = np.array(arr1)
arr1[1] =2
print(arr1)
print(asarr)
print(ar_arr1)
2.4 从数值范围创建数组
numpy.arange(start, stop, step, dtype)
参数描述
start:起始值,默认为0
stop:终止值(不包含)
step:步长,默认为1
dtype:返回ndarray的数据类型,如果没有提供,则会使用输入数据的类型。
np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
start:序列的起始值
stop:序列的终止值,如果endpoint为true,该值包含于数列中
num:要生成的等步长的样本数量,默认为50
endpoint:该值为 true 时,数列中包含stop值,反之不包含,默认是True。
retstep:如果为 True 时,生成的数组中会显示间距,反之不显示。
dtype:ndarray 的数据类型
#创建10到100 并且步长为10的数组(同切片一样包含开始,不包含结束)
arr1 = np.arange(10,100,10)
print(arr1)
#指定区间均匀分割创建数组
arr2 = np.linspace(10,100,10,endpoint=True,dtype=int)
print(arr2)
2.5利用随机函数创建数组
numpy.random.rand() 0-1之间均匀分布的浮点数
numpy.random.randn() 标准正态分布 (均值为0,标准差为1)
numpy.random.randint(low,high,size) 依据形状用low ~high 区间的数值创建数组
numpy.random.uniform(low, high, size) : 产生均匀分布的数组,起始值为low,high为结束值,size为形状
numpy.random.normal(loc, scale, size) : 产生正态分布的数组, loc为均值,scale为标准差,size为形状
在概率论和统计学中,均匀分布也叫矩形分布,它是对称概率分布,在相同长度间隔的分布概率是等可能的
#1.创建2行3列的0-1之间均匀分布浮点数
arr1 = np.random.rand(2,3)
print("0-1间均匀分布\n",arr1)
#2.创建3行3列的标准正态分布的浮点数
arr2 = np.random.randn(3,3)
print("正态分布\n",arr2)
#3.创建3,3列10-100之间的整数
arr3 = np.random.randint(10,100,(3,3))
print("10-100整数\n",arr3)
#4.创建3,3列均值80,标准差10的正态分布
arr5 = np.random.normal(80,10,(3,3))
print("均值为80,标准差为10的浮点数\n",arr5)
三、数组属性
3.1 数组属性
arr.dtype 元素类型
arr.ndim 数组维度
arr.shape 数组形状
arr.size 元素个数 等价于 len(list)
import numpy as np
arr1 = np.array([[1,2,3],[4,5,6]])
print("dtype",arr1.dtype)
print("ndim",arr1.ndim)
print("shape",arr1.shape)
print("size",arr1.size)
3.2 修改数组维度
arr.reshape(shape) 复制数组后改变形状
arr.resize(shape) 不复制,改变当前数组形状
numpy.ravel(arr1) 展开数组,变成1维
#1.创建一个1-40连续的数组维度为5行8列 名为update
update = np.arange(1,41).reshape((5,8))
update
#2.把数组update 改为8行5列
update.resize((8,5))
#或者
update = update.reshape((8,5))
3.3 数组访问与修改
ndarray对象的内容可以通过索引或切片来访问和修改,与 Python 中 list 的切片操作一样[开始:结束:步长]。
ndarray 数组可以基于 0 - n 的下标进行索引
与list, tuple 切片操作一致
一维数组[元素下标]
二维数组[第一个维度(行), 第二个维度(列)] 适合切片
# 一维数组的访问
arr=np.arange(10)
print(arr)
# 访问单个值
print(arr[3])
print(arr[-1])
# 访问范围
print(arr[2:8])
print(arr[8:2:-2])
# 数组的修改
arr[2:4]=10,11
print(arr)
import numpy as np
# 创建二维数组
arr=np.arange(12).reshape(3,4)
print(arr)
# 对于行列都有要求
print(arr[0:2,1:3])
# 按照行的条件选择数据
print(arr[0:2])
# 按照列选择数据
print(arr[:,2:4])
3.4 利用True,False 进行访问与修改
通过相等形状的元素为True,False 的数组对数据进行获取
- 通过对数组进行判断的形式得到相同形状的True,False 数组
ar = np.arange(1,21).reshape((4,5))
print(ar)
# 5的倍数
print(ar[ar % 5==0])
# 奇数
print(ar[ar % 2==1])
# 偶数
print(ar[ar % 2==0])
四、Numpy 常用函数
4.1 算数函数
-
np.power(arr1,arr2或常数) == 等价于 **
-
np.modf(arr) #分开整数部分和小数部分
-
np.sqrt(arr) 对数组进行开方
-
np.around(arr,小数点位数) 4舍5入后保留指定位数的小数点
-
np.floor(arr) 向下取整 6.9 = 6
-
np.ceil(arr) 向上取整 6.1 = 7
-
np.sign(arr) 取符号,正数为 1, 0, 负数为-1
练习
- 创建3行4列的一个数组,内容为标准正态分布的值,数组命名为arr_fun_ex
- 对数组arr_fun_ex 第一行进行4舍5入并保留2为小数点
- 对数组arr_fun_ex 第二行进行向上取整
- 对第一行第3列数进行开方
- 对每个元素乘以3后取整数部分
import numpy as np
import warnings
warnings.filterwarnings('ignore')
#1 创建3行4列的一个数组,内容为标准正态分布的值,数组命名为arr_fun_ex
arr_fun_ex = np.random.normal(size=(3,4))
arr_fun_ex
#2 对数组arr_fun_ex 第一行进行4舍5入并保留2为小数点
arr_fun_ex[0] = np.around(arr_fun_ex[0],2)
#3 对数组arr_fun_ex 第二行进行向上取整
arr_fun_ex[1] = np.ceil(arr_fun_ex[1])
#4 对第一行第3列数进行开方
arr_fun_ex[0,2] = np.sqrt(arr_fun_ex[0,2])
#6 对每个元素乘以3后取整数部分
np.modf(arr_fun_ex * 3)[1]
4.2 统计函数
| 函数 | 说明 |
|---|---|
| sum | 计算数组的和 |
| mean | 计算数组均值 |
| std | 计算数组标准差 |
| var | 计算数组方差 |
| min | 计算数组最小值 |
| max | 计算数组最大值 |
| argmin | 返回数组最小元素的索引 |
| argmax | 返回数组最大元素的索引 |
| cumsum | 计算所有元素的累计和 |
| cumprod | 计算所有元素的累计积 |
import numpy as np
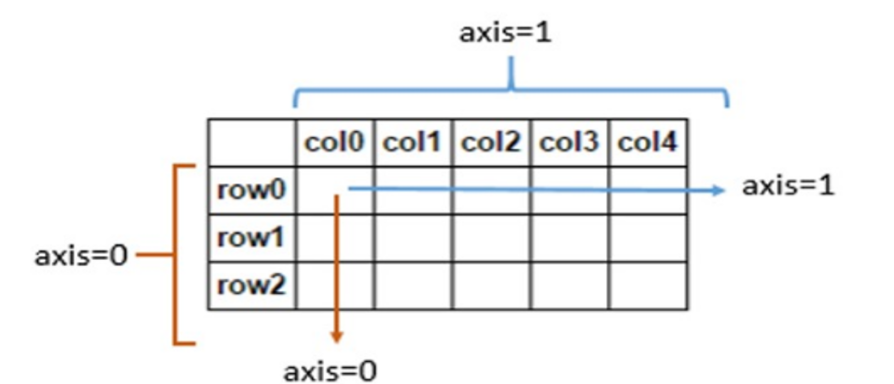
# 使用numpy进行统计分析
arr=np.arange(20).reshape(4,5)
print(arr)
# 求整个数组的总和
print(arr.sum())
# 计算每一行数据的和
print(arr.sum(axis=1))
# 计算每一列数据的和
print(arr.sum(axis=0))
# 计算数据的累积和
print(np.cumsum(arr))
# 按列计算数据累积和
print(np.cumsum(arr,axis=0))
# 计算数据的累积积
print(np.cumprod(arr))
# 按行计算
print(np.cumprod(arr,axis=1))
# 得到最大元素的索引位置
print(np.argmax(arr))
print(np.argmax(arr,axis=0))
# 得到最小元素的索引位置
print(np.argmin(arr))
print(np.argmin(arr,axis=1))
4.3其他函数
numpy.where(条件,True_value,False_Value) #满足条件,返回True_value,否则返回 False_value
np.apply_along_axis(函数名/匿名函数,轴,arr=数组)
np.random.seed(123)
ar = np.random.randint(10,100,(3,4))
ar
# 语文 数学 英语 化学
# [[76, 27, 93, 67],
# [96, 57, 83, 42],
# [56, 35, 93, 88]]
#1,为成绩分段 60 及格 ,60-90 一般,>90优秀
np.where(ar<60,"不及格",np.where(ar<90,"一般","优秀"))
#2,每人的总分
ar.sum(axis= 1)
#3, 语文最低分的人英语分数
ar[ar[:,0] ==ar[:,0].min() ,2]
#4,每科的平均分
ar.mean(axis=0)
#5, 每个人的文理平均分
ar[:,[0,2]].mean(axis=1)
ar[:,[1,3]].mean(axis=1)
np.apply_along_axis(lambda hang:
[hang[[0,2]].mean(),hang[[1,3]].mean()]
,axis=1,arr=ar)