本来不想再写Ceph相关的文章了,最近在做ceph元数据优化研究及架构,整体思路是:将rados作为数据存储引擎,构建分布式元数据集群来管理元数据,如:将rgw或者fs相关的元数据从ceph的元数据池中抽取出来,转存到分布式元数据集群中,以此达到提升单集群处理能力的目的;要达到这个目的,有两个基础条件:1.对ceph中rgw或者fs的各CURD操作原理及IO路径非常熟悉,2.对ceph中元数据的组织及存储非常熟悉;然后才能在rgw或者mds的IO路径中进行数据及元数据的分离操作,并以合适的格式将元数据转存到分布式元数据集群中。
前期通过三篇文章介绍了上述的第一项基础条件,本篇介绍第二项基础条件,这是第一篇:rgw关键流程分析及业务逻辑
下文的操作在最新的Nautilus版本环境下进行,基于s3 API进行,对rgw中的架构,关键流程及处理逻辑进行抽象,以用户管理举例说明
架构概述
简单介绍下rgw的逻辑分层架构,如下图:

我将rgw从逻辑上分成两层:
1)frontend:主要是处理HTTP请求以及业务逻辑封装,并提供到下层store的语义转化。
2)store:主要负责io处理,对librados的封装。
根据这个分层,很显然要对元数据进行分布式存储,通过添加新的store,然后将元数据相关的OP定向到新的store即可:)。
业务逻辑
rgw中,对资源的请求都是这么个思路:
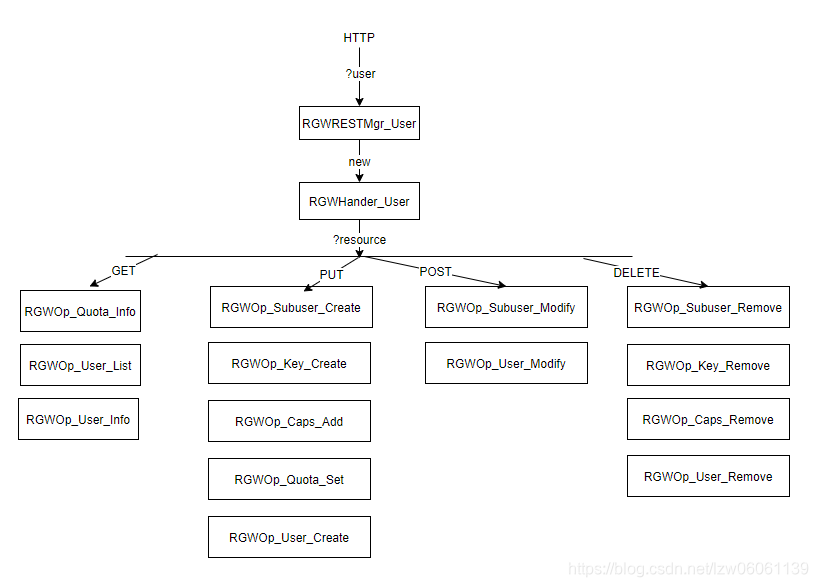
1)根据HTTP请求中的prefix获取REST管理器RGWRESTMgr_, 类型包括:s3,swift,admin等。
2)生成资源处理器RGWHander_,类型包括:user,usage,swift_auth,bucket,object等。
3)通过请求类型以及资源类型获得操作对象RGWOp_*。
4)请求预处理,主要是执行安全检查及认证。
5)运行操作对象,与rados交互完成io操作。
以用户管理为例,包括创建,删除,更新等,下面是一张对象图,是对上述逻辑分层图第一层(frontend)以及业务逻辑在User的具体化:
下面来看下,第一层fronend中的关键路径顺序图:(注:exec是统称,泛指对RGWRados的调用)
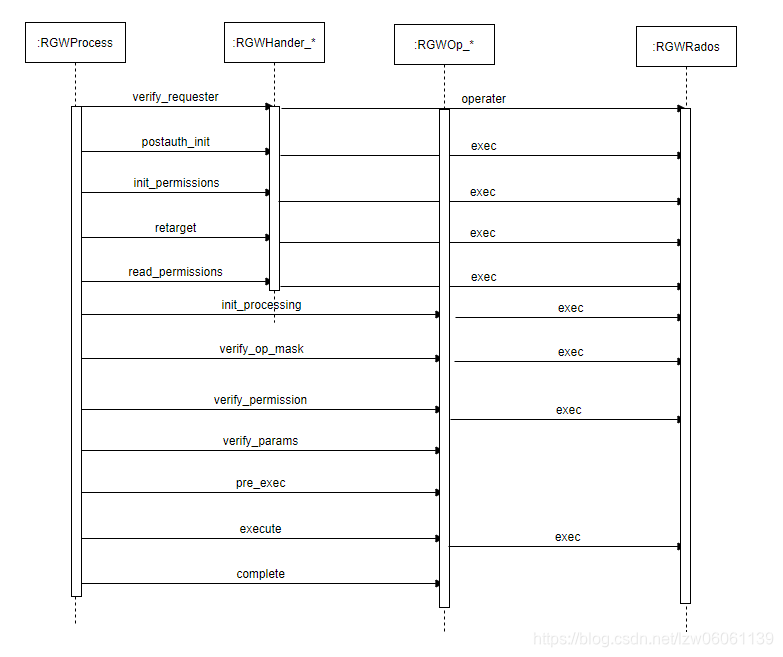
- verify_requester: 校验客户端signature和服务端的signatrue是否一致,用于确认用户身份;这个过程中涉及两个与后端相关的操作:(还记得前面的文章中几点关于用户元数据的分析吧? 这里派上用场了)
1.1)通过access-key获得uid,
1.2)通过uid获得用户信息。 - postauth_init:因为引入tenant,对bucket和object进行名字标准化,如果开启MFA,还会进行MFA校验(这部分操作的元数据作用在
{zone}.rgw.otp池),user场景中不需要处理这个过程。 - init_permissions:处理bucket及用户的acl,bucket policy,这个过程中涉及两个与后端相关的操作:
3.1)通过bucket name获取bucket info信息(包含acl,policy等扩展信息),
3.2)通过instance id获取bucket instance信息,
3.3)通过uid获取user扩展属性(包括acl, sts policy)。 - retarget:s3_website用于访问对象重定向,这里会获取bucket 以及 bucket instance信息(包含website信息),相关的信息在第3)步已经从后端获取缓存在cache中,其他场景不需要处理这个过程。
- read_permissions:读取bucket,object的acl,相关的信息在第3)步已经从后端获取缓存在cache中,这里主要是更新到
req_state中。 - init_processing:获取bucket和user的配额信息,相关的信息在第1)和第3)步已经从后端获取缓存在cache中,这里是将请求信息设置到RGWOp_*对象中。
- verify_op_mask:操作码(read,write,delete)权限校验,用户的操作码与该操作允许的操作码进行比较,用户的信息以及在第1)步中从后端获取缓存在cache中,并设置在了RGWOp_*对象中。
- verify_permission:acl和policy权限校验,租户检查,配额检查等,不同的RGWOp_*的操作会有写差异,可能包括:
8.1)用户的Cap与该操作允许的CAP进行比较
8.2)bucket policy检查
8.3)tenant匹配(只有同一个tenant的user才能访问bucket)
8.4)bucket配额(这里会获取{user}.{bucket}对象信息,包含用户的bucket列表) - verify_params:参数检查
- pre_exec:请求预处理,根据目前的了解,只有几个dump操作。
- execute:执行请求,这里主要调用RGWRados完成io请求,比如:创建用户,就会分别往
{zone}.rgw.meta池的命名空间uid,keys,swfit,email等写入用户信息,access-key,subuser,email信息。 - complete:完成请求,返回应答。
上面的流程可以归纳成这么几部分:
- 步骤1 ~ 5,从后端获取必要的元数据,如:user,bucket,acl,policy等,
- 步骤 6 ~ 10,根据前面获取的元数据做相关的检查,如:权限等,
- 步骤11~12,执行请求,返回应答。
通过前面的元数据组织以及本篇文章,各位应该能基本上理清楚rgw中的处理逻辑以及数据处理思路,具体实现细节就留待各位去挖掘了。下一篇,简单介绍下zonegroup,zone等元数据的处理以及rgw启动过程中元数据的初始化。