【CV知识点汇总与解析】| optimizer和学习率篇
【写在前面】
本系列文章适合Python已经入门、有一定的编程基础的学生或人士,以及人工智能、算法、机器学习求职的学生或人士。系列文章包含了深度学习、机器学习、计算机视觉、特征工程等。相信能够帮助初学者快速入门深度学习,帮助求职者全面了解算法知识点。
1、常见的优化函数(optimizer)有哪些?
1. SGD(随机梯度下降)
Batch Gradient Descent
在每一轮的训练过程中,Batch Gradient Descent算法用整个训练集的数据计算cost fuction的梯度,并用该梯度对模型参数进行更新:
Θ = Θ − α ⋅ ∇ Θ J ( Θ ) \Theta=\Theta-\alpha \cdot \nabla \Theta J(\Theta) Θ=Θ−α⋅∇ΘJ(Θ)
优点:
- cost fuction若为凸函数,能够保证收敛到全局最优值;若为非凸函数,能够收敛到局部最优值
缺点:
-
由于每轮迭代都需要在整个数据集上计算一次,所以批量梯度下降可能非常慢
-
训练数较多时,需要较大内存
-
批量梯度下降(Batch Gradient Descent)不允许在线更新模型,例如新增实例。
Stochastic Gradient Descent
和批梯度下降算法相反,Stochastic gradient descent 算法每读入一个数据,便立刻计算cost fuction的梯度来更新参数:
Θ = Θ − α ⋅ ∇ Θ J ( Θ ; x ( i ) , y ( i ) ) \Theta=\Theta-\alpha \cdot \nabla_{\Theta} J\left(\Theta ; x^{(i)}, y^{(i)}\right) Θ=Θ−α⋅∇ΘJ(Θ;x(i),y(i))
优点:
-
算法收敛速度快(在Batch Gradient Descent算法中, 每轮会计算很多相似样本的梯度, 这部分是冗余的)
-
可以在线更新
-
有几率跳出一个比较差的局部最优而收敛到一个更好的局部最优甚至是全局最优
缺点:
- 容易收敛到局部最优,并且容易被困在鞍点
Mini-batch Gradient Descent
mini-batch Gradient Descent的方法是在上述两个方法中取折衷, 每次从所有训练数据中取一个子集(mini-batch) 用于计算梯度:
Θ = Θ − α ⋅ ∇ Θ J ( Θ ; x ( i i i + n ) , y ( i : i + n ) ) \Theta=\Theta-\alpha \cdot \nabla_{\Theta} J\left(\Theta ; x^{(i i i+n)}, y^{(i: i+n)}\right) Θ=Θ−α⋅∇ΘJ(Θ;x(iii+n),y(i:i+n))
Mini-batch Gradient Descent在每轮迭代中仅仅计算一个mini-batch的梯度,不仅计算效率高,而且收敛较为稳定。该方法是目前深度学训练中的主流方法。
上述三个方法面临的主要挑战如下:
-
选择适当的学习率α 较为困难。太小的学习率会导致收敛缓慢,而学习速度太块会造成较大波动,妨碍收敛。
-
目前可采用的方法是在训练过程中调整学习率大小,例如模拟退火算法:预先定义一个迭代次数m,每执行完m次训练便减小学习率,或者当cost function的值低于一个阈值时减小学习率。然而迭代次数和阈值必须事先定义,因此无法适应数据集的特点。
-
上述方法中, 每个参数的 learning rate 都是相同的,这种做法是不合理的:如果训练数据是稀疏的,并且不同特征的出现频率差异较大,那么比较合理的做法是对于出现频率低的特征设置较大的学习速率,对于出现频率较大的特征数据设置较小的学习速率。
-
近期的的研究表明,深层神经网络之所以比较难训练,并不是因为容易进入local minimum。相反,由于网络结构非常复杂,在绝大多数情况下即使是 local minimum 也可以得到非常好的结果。而之所以难训练是因为学习过程容易陷入到马鞍面中,即在坡面上,一部分点是上升的,一部分点是下降的。而这种情况比较容易出现在平坦区域,在这种区域中,所有方向的梯度值都几乎是 0。
2. Momentum
SGD方法的一个缺点是其更新方向完全依赖于当前batch计算出的梯度,因而十分不稳定。Momentum算法借用了物理中的动量概念,它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向。这样一来,可以在一定程度上增加稳定性,从而学习地更快,并且还有一定摆脱局部最优的能力:
v t = γ ⋅ v t − 1 + α ⋅ ∇ Θ J ( Θ ) Θ = Θ − v t v_{t}=\gamma \cdot v_{t-1}+\alpha \cdot \nabla_{\Theta} J(\Theta)\\\Theta=\Theta-v_{t} vt=γ⋅vt−1+α⋅∇ΘJ(Θ)Θ=Θ−vt
Momentum算法会观察历史梯度 v t − 1 v_{t-1} vt−1,若当前梯度的方向与历史梯度一致(表明当前样本不太可能为异常点),则会增强这个方向的梯度,若当前梯度与历史梯方向不一致,则梯度会衰减。一种形象的解释是**:**我们把一个球推下山,球在下坡时积聚动量,在途中变得越来越快,γ可视为空气阻力,若球的方向发生变化,则动量会衰减。
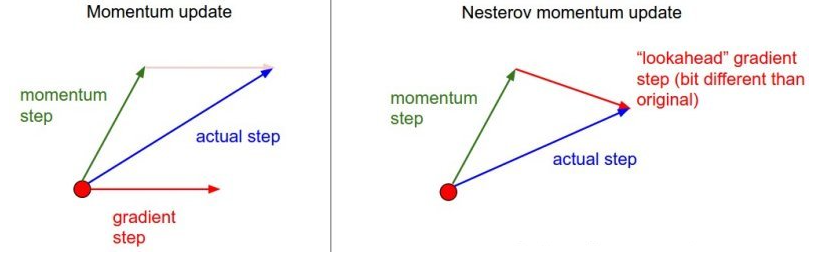
3. Nesterov Momentum
在小球向下滚动的过程中,作者希望小球能够提前知道在哪些地方坡面会上升,这样在遇到上升坡面之前,小球就开始减速。这方法就是Nesterov Momentum,其在凸优化中有较强的理论保证收敛。并且,在实践中Nesterov Momentum也比单纯的 Momentum 的效果好:
v t = γ ⋅ v t − 1 + α ⋅ ∇ Θ J ( Θ − γ v t − 1 ) Θ = Θ − v t v_{t}=\gamma \cdot v_{t-1}+\alpha \cdot \nabla_{\Theta} J\left(\Theta-\gamma v_{t-1}\right)\\\Theta=\Theta-v_{t} vt=γ⋅vt−1+α⋅∇ΘJ(Θ−γvt−1)Θ=Θ−vt
其核心思想是:注意到 momentum 方法,如果只看 γ * v 项,那么当前的 θ经过 momentum 的作用会变成 θ-γ * v。因此可以把 θ-γ * v这个位置看做是当前优化的一个”展望”位置。所以,可以在 θ-γ * v求导, 而不是原始的θ。
4. Adagrad
上述方法中,对于每一个参数 θ i θ_i θi的训练都使用了相同的学习率α。Adagrad算法能够在训练中自动的对learning rate进行调整,对于出现频率较低参数采用较大的α更新;相反,对于出现频率较高的参数采用较小的α更新。因此,Adagrad非常适合处理稀疏数据。
我们设 g t , i g_{t, i} gt,i为第t轮第i个参数的梯度,即 g t , i = ∇ Θ J ( Θ i ) g_{t, i}=\nabla_{\Theta} J\left(\Theta_{i}\right) gt,i=∇ΘJ(Θi)。因此,SGD中参数更新的过程可写为:
Θ t + 1 , i = Θ t , i − α ⋅ g t , i \Theta_{t+1, i}=\Theta_{t, i}-\alpha \cdot g_{t, i} Θt+1,i=Θt,i−α⋅gt,i
Adagrad在每轮训练中对每个参数 θ i θ_i θi的学习率进行更新,参数更新公式如下:
Θ t + 1 , i = Θ t , i − α G t , i i + ϵ ⋅ g t , i \Theta_{t+1, i}=\Theta_{t, i}-\frac{\alpha}{\sqrt{G_{t, i i}+\epsilon}} \cdot g_{t, i} Θt+1,i=Θt,i−Gt,ii+ϵα⋅gt,i
其中, G t ∈ R d × d G_{t} \in \mathbb{R}^{d \times d} Gt∈Rd×d对角矩阵,每个对角线位置为对应参数 θ i \theta_{i} θi从第1轮到第t轮梯度的平方和。ϵ是平滑项,用于避免分母为0,一般取值1e−8。Adagrad的缺点是在训练的中后期,分母上梯度平方的累加将会越来越大,从而梯度趋近于0,使得训练提前结束。
5. RMSprop
RMSprop是Geoff Hinton提出的一种自适应学习率方法。Adagrad会累加之前所有的梯度平方,而RMSprop仅仅是计算对应的平均值,因此可缓解Adagrad算法学习率下降较快的问题。
E [ g 2 ] t = 0.9 E [ g 2 ] t − 1 + 0.1 g t 2 Θ t + 1 = Θ t − α E [ g 2 ] t + ϵ ⋅ g t E\left[g^{2}\right]_{t}=0.9 E\left[g^{2}\right]_{t-1}+0.1 g_{t}^{2}\\\Theta_{t+1}=\Theta_{t}-\frac{\alpha}{\sqrt{E\left[g^{2}\right]_{t}+\epsilon}} \cdot g_{t} E[g2]t=0.9E[g2]t−1+0.1gt2Θt+1=Θt−E[g2]t+ϵα⋅gt
6. Adam
Adam(Adaptive Moment Estimation)是另一种自适应学习率的方法。它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。公式如下:
m t = β 1 m t − 1 + ( 1 − β 1 ) g t v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 m ^ t = m t 1 − β 1 t v ^ t = v t 1 − β 2 t Θ t + 1 = Θ t − α v ^ t + ϵ m ^ t m_{t}=\beta_{1} m_{t-1}+\left(1-\beta_{1}\right) g_{t}\\v_{t}=\beta_{2} v_{t-1}+\left(1-\beta_{2}\right) g_{t}^{2}\\\hat{m}_{t}=\frac{m_{t}}{1-\beta_{1}^{t}}\\\hat{v}_{t}=\frac{v_{t}}{1-\beta_{2}^{t}}\\\Theta_{t+1}=\Theta_{t}-\frac{\alpha}{\sqrt{\hat{v}_{t}}+\epsilon} \hat{m}_{t} mt=β1mt−1+(1−β1)gtvt=β2vt−1+(1−β2)gt2m^t=1−β1tmtv^t=1−β2tvtΘt+1=Θt−v^t+ϵαm^t
Adam 方法也会比 RMSprop方法收敛的结果要好一些, 所以在实际应用中 ,Adam为最常用的方法,可以比较快地得到一个预估结果。
不同优化器的比较
上图描述了在一个曲面上,6种优化器的表现,从中可以大致看出:
① 下降速度:
三个自适应学习优化器Adagrad、RMSProp与AdaDelta的下降速度明显比SGD要快,其中,Adagrad和RMSProp齐头并进,要比AdaDelta要快。
两个动量优化器Momentum和NAG由于刚开始走了岔路,初期下降的慢;随着慢慢调整,下降速度越来越快,其中NAG到后期甚至超过了领先的Adagrad和RMSProp。
② 下降轨迹:
SGD和三个自适应优化器轨迹大致相同。两个动量优化器初期走了“岔路”,后期也调整了过来。
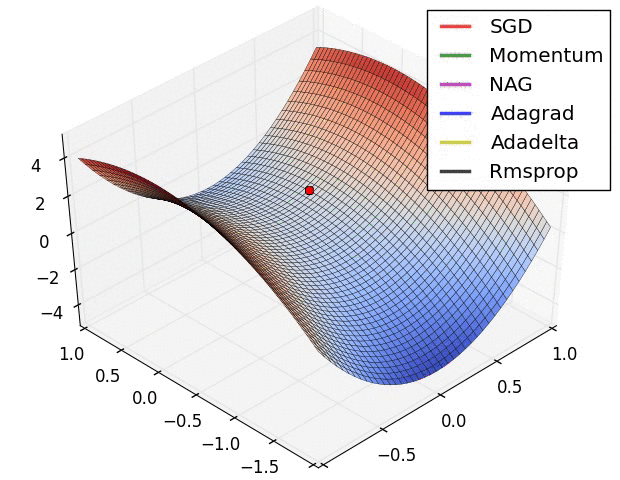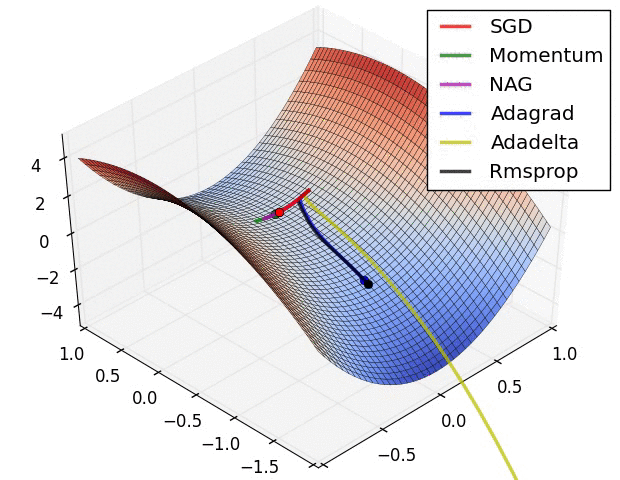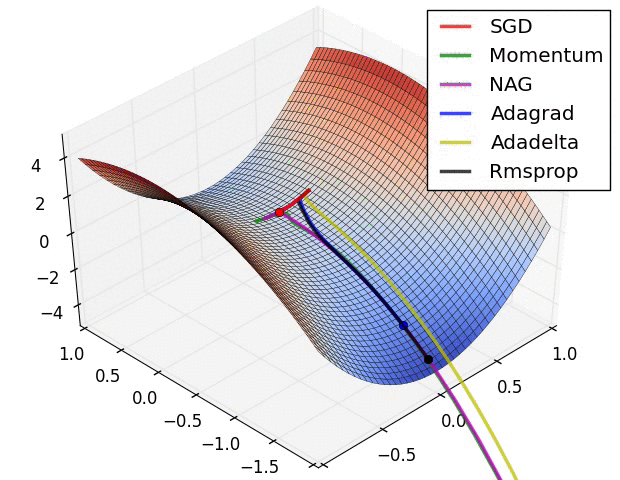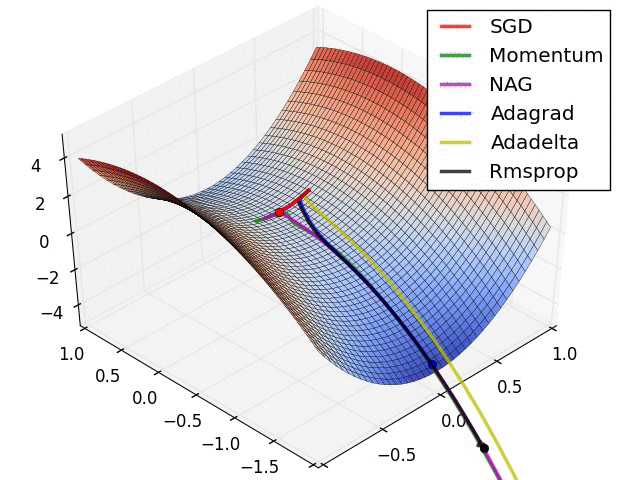
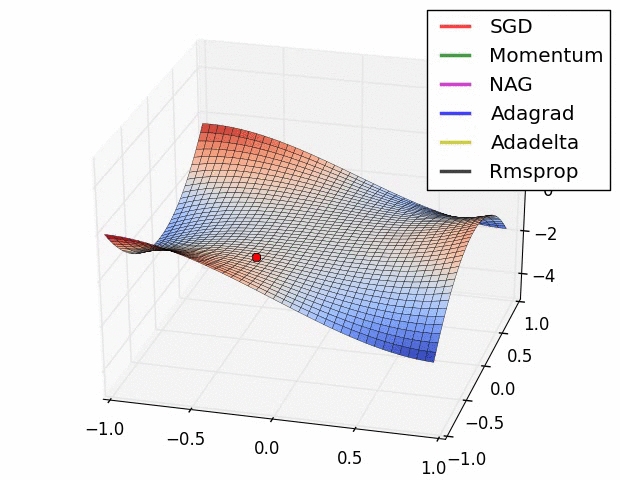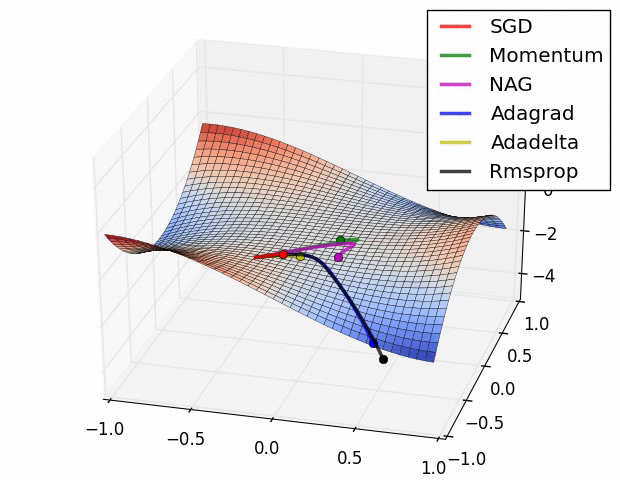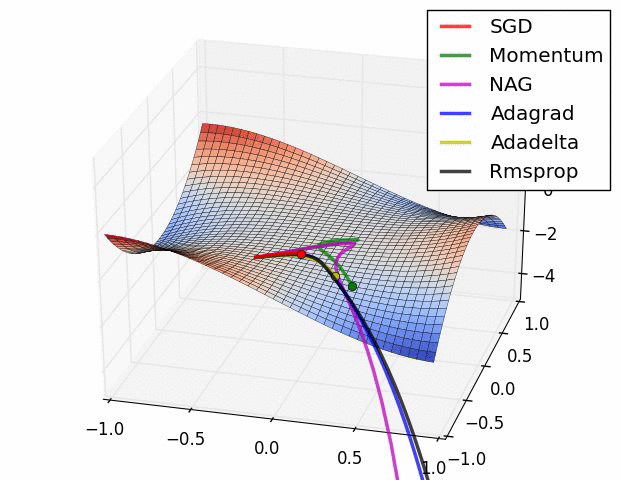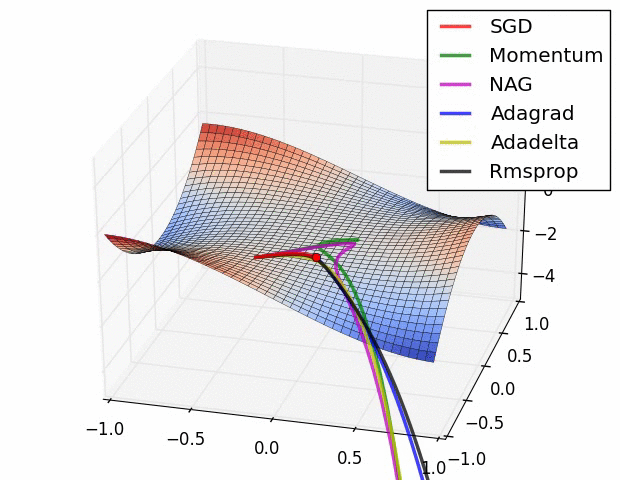
上图在一个存在鞍点的曲面,比较6中优化器的性能表现,从图中大致可以看出:
三个自适应学习率优化器没有进入鞍点,其中,AdaDelta下降速度最快,Adagrad和RMSprop则齐头并进。
两个动量优化器Momentum和NAG以及SGD都顺势进入了鞍点。但两个动量优化器在鞍点抖动了一会,就逃离了鞍点并迅速地下降,后来居上超过了Adagrad和RMSProp。
很遗憾,SGD进入了鞍点,却始终停留在了鞍点,没有再继续下降。
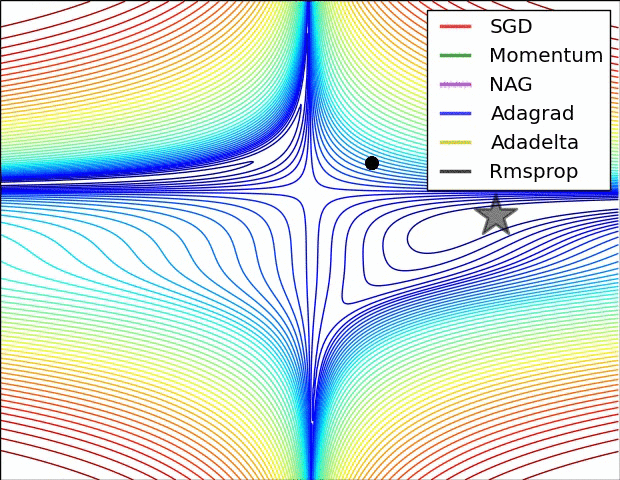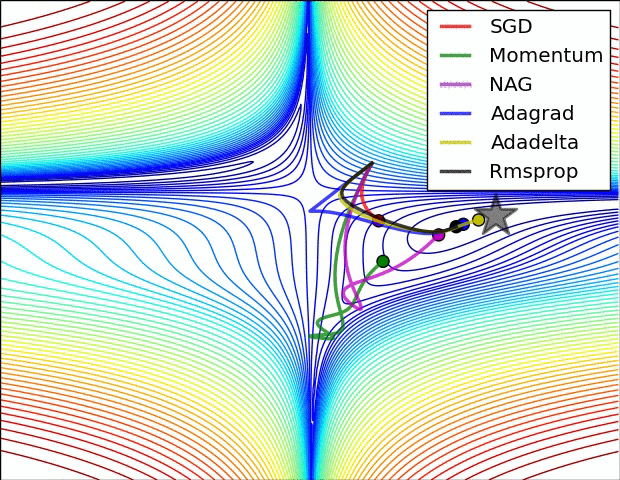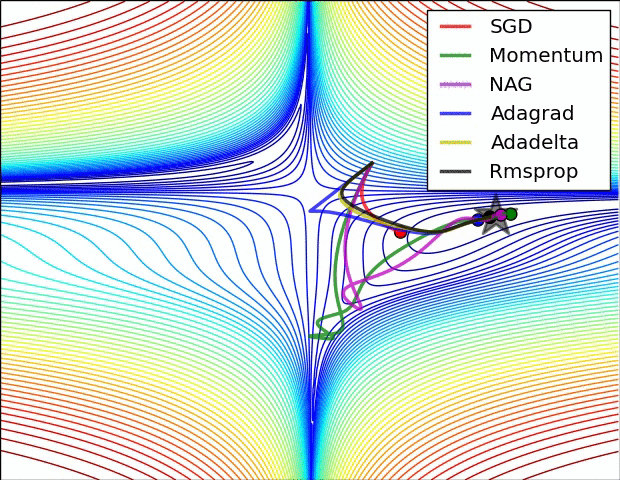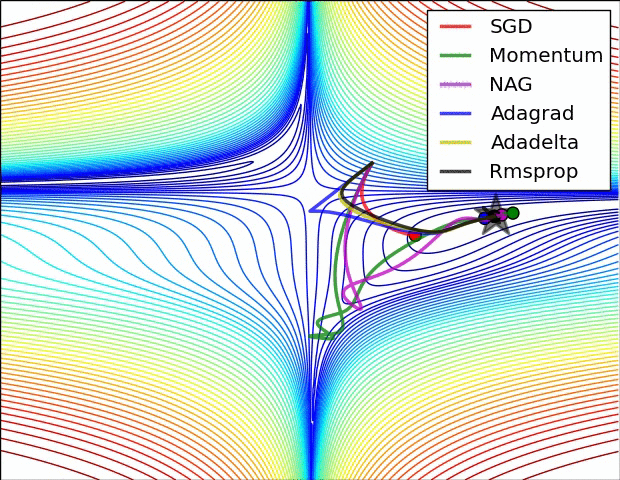
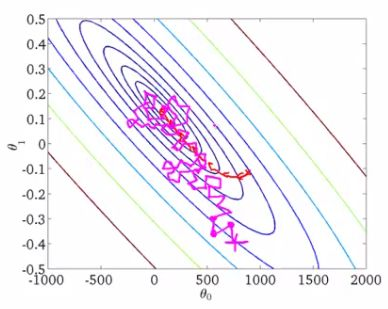
上图比较了6种优化器收敛到目标点(五角星)的运行过程,从图中可以大致看出:
① 在运行速度方面
两个动量优化器Momentum和NAG的速度最快,其次是三个自适应学习率优化器AdaGrad、AdaDelta以及RMSProp,最慢的则是SGD。
② 在收敛轨迹方面
两个动量优化器虽然运行速度很快,但是初中期走了很长的”岔路”。
三个自适应优化器中,Adagrad初期走了岔路,但后来迅速地调整了过来,但相比其他两个走的路最长;AdaDelta和RMSprop的运行轨迹差不多,但在快接近目标的时候,RMSProp会发生很明显的抖动。
SGD相比于其他优化器,走的路径是最短的,路子也比较正。
2、如何选择优化器?
1)如果训练的数据是稀疏的,则选择一个自适应学习率的算法(Adagrad、Adadelta、RMSprop、Adam)。
2)RMSprop是Adagrad一个扩展,它处理的是急剧下降的学习率。
3)Adam则为RMSprop添加了偏差校正和动量,随着梯度变得越来越稀疏,Adam在优化结束时略优于RMSprop。Adam可能是上述算法中最好的选择。
4)Adadelta、RMSprop、Adam三个算法非常相似,在类似的情况下,效果都不错。
3、pytorch中Optimizer的使用
模型训练时的固定搭配如下:
loss.backward()
optimizer.step()
optimizer.zero_grad()
简单来说,loss.backward()就是反向计算出各参数的梯度,然后optimizer.step()更新网络中的参数,optimizer.zero_grad()将这一轮的梯度清零,防止其影响下一轮的更新。
常用优化器都在torch.optim包中,因此需要先导入包:
import torch.optim.Adamimport torch.optim.SGD
4、Optimizer基本属性
所有Optimizer公有的一些基本属性:
-
lr: learning rate,学习率
-
eps: 学习率最小值,在动态更新学习率时,学习率最小不会小于该值。
-
weight_decay: 权值衰减。相当于对参数进行L2正则化(使模型复杂度尽可能低,防止过拟合),该值可以理解为正则化项的系数。
每个Optimizer都维护一个param_groups的list,该list中维护需要优化的参数以及对应的属性设置。
5、Optimizer基本方法
-
**add_param_group(param_group):**为optimizer的param_groups增加一个参数组。这在微调预训练的网络时非常有用,因为冻结层可以训练并随着训练的进行添加到优化器中。
-
**load_state_dict(state_dict):**加载optimizer state。参数必须是optimizer.state_dict()返回的对象。
-
**state_dict():**返回一个dict,包含optimizer的状态:state和param_groups。
-
step(closure): 执行一次参数更新过程。
-
zero_grad(): 清除所有已经更新的参数的梯度。
我们在构造优化器时,最简单的方法通常如下:
model = Net()
optimizer_Adam = torch.optim.Adam(model.parameters(), lr=0.1)
**model.parameters()**返回模型的全部参数,并将它们传入Adam函数构造出一个Adam优化器,并设置 learning rate=0.1。
因此该 Adam 优化器的 param_groups 维护的就是模型 model 的全部参数,并且学习率为0.1,这样在调用optimizer_Adam.step()时,就会对model的全部参数进行更新。
6、param_groups
Optimizer的param_groups是一个list,其中的每个元素都是一组独立的参数,以dict的方式存储。结构如下:
-param_groups
-0(dict) # 第一组参数
params: # 维护要更新的参数
lr: # 该组参数的学习率
betas:
eps: # 该组参数的学习率最小值
weight_decay: # 该组参数的权重衰减系数
amsgrad:
-1(dict) # 第二组参数
-2(dict) # 第三组参数
...
这样可以实现很多灵活的操作,比如:
1)只训练模型的一部分参数
例如,只想训练上面的model中的layer1参数,而保持layer2的参数不动。可以如下设置Optimizer:
model = Net()
# 只传入layer层的参数,就可以只更新layer层的参数而不影响其他参数。
optimizer_Adam = torch.optim.Adam(model.layer1.parameters(), lr=0.1)
2)不同部分的参数设置不同的学习率
例如,要想使model的layer1参数学习率为0.1,layer2的参数学习率为0.2,可以如下设置Optimizer:
model = Net()
params_dict = [{
'params': model.layer.parameters(), 'lr': 0.1},
{
'params': model.layer2.parameters(), 'lr': 0.2}]
optimizer_Adam = torch.optim.Adam(params_dict)
这种方法更为灵活,手动构造一个params_dict列表来初始化Optimizer。注意,字典中的参数部分的 key 必须为**‘params’**。
7、动态更新学习率
了解了Optimizer的基本结构和使用方法,接下来将介绍如何在训练过程中动态更新 learning rate。
1. 手动修改学习率
前文提到Optimizer的每一组参数维护一个lr,因此最直接的方法就是在训练过程中手动修改Optimizer中对应的lr值。
model = Net() # 生成网络
optimizer_Adam = torch.optim.Adam(model.parameters(), lr=0.1) # 生成优化器
for epoch in range(100): # 假设迭代100个epoch
if epoch % 5 == 0: # 每迭代5次,更新一次学习率
for params in optimizer_Adam.param_groups:
# 遍历Optimizer中的每一组参数,将该组参数的学习率 * 0.9
params['lr'] *= 0.9
# params['weight_decay'] = 0.5 # 当然也可以修改其他属性
2. torch.optim.lr_scheduler
torch.optim.lr_scheduler包中提供了一些类,用于动态修改lr。
-
torch.optim.lr_scheduler.LambdaLr
-
torch.optim.lr_scheduler.StepLR
-
torch.optim.lr_scheduler.MultiStepLR
-
torch.optim.lr_scheduler.ExponentialLR
-
torch.optim.lr_sheduler.CosineAnneaingLR
-
torch.optim.lr_scheduler.ReduceLROnPlateau
pytorch 1.1.0版本之后,在创建了lr_scheduler对象之后,会自动执行第一次lr更新(可以理解为执行一次scheduler.step())。
因此在使用的时候,需要先调用optimizer.step(),再调用scheduler.step()。
如果创建了lr_scheduler对象之后,先调用scheduler.step(),再调用optimizer.step(),则会跳过了第一个学习率的值。
# 调用顺序
loss.backward()
optimizer.step()
scheduler.step()...
【项目推荐】
面向小白的顶会论文核心代码库:https://github.com/xmu-xiaoma666/External-Attention-pytorch
面向小白的YOLO目标检测库:https://github.com/iscyy/yoloair
面向小白的顶刊顶会的论文解析:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading
参考
https://blog.csdn.net/u010089444/article/details/76725843
https://ruder.io/optimizing-gradient-descent/index.html
https://blog.csdn.net/rookie_wei/article/details/85470914
https://zhuanlan.zhihu.com/p/435669796
https://blog.csdn.net/weixin_40170902/article/details/80092628