本文首发于微信公众号 CVHub,严禁私自转载或售卖到其他平台,违者必究。

Title: ZipIt! Merging Models from Different Tasks without Training
Paper: https://arxiv.org/pdf/2305.03053.pdf
Code: https://github.com/gstoica27/ZipIt
导读
典型的深度视觉识别模型能够完成它们训练时的单一任务。在本文中,论文解决了将完全不同的、有着不同初始化的、各自解决不同任务的模型合并成一个多任务模型这个极其困难的问题,而不需要进行任何额外的训练。以往的模型合并方法将一个模型置换到另一个模型的空间中,然后将它们相加。虽然这对于在相同任务上训练的模型有效,但论文发现这未能考虑到在不同任务上训练的模型之间的差异。因此,论文引入了一种名为“ZipIt!”的通用方法,用于合并同一架构的两个任意模型,它包含两个简单策略。首先,为了考虑到不在模型之间共享的特征,论文扩展了模型合并问题,使其允许在每个模型内部合并特征,定义了一种通用的“zip”操作。其次,论文添加了部分压缩模型以达到指定层的支持,自然地创建了一个多头模型。论文发现,这两个变化的结合使先前工作的性能提高了惊人的20-60%,使在不同任务上训练的模型的合并成为可能。
贡献
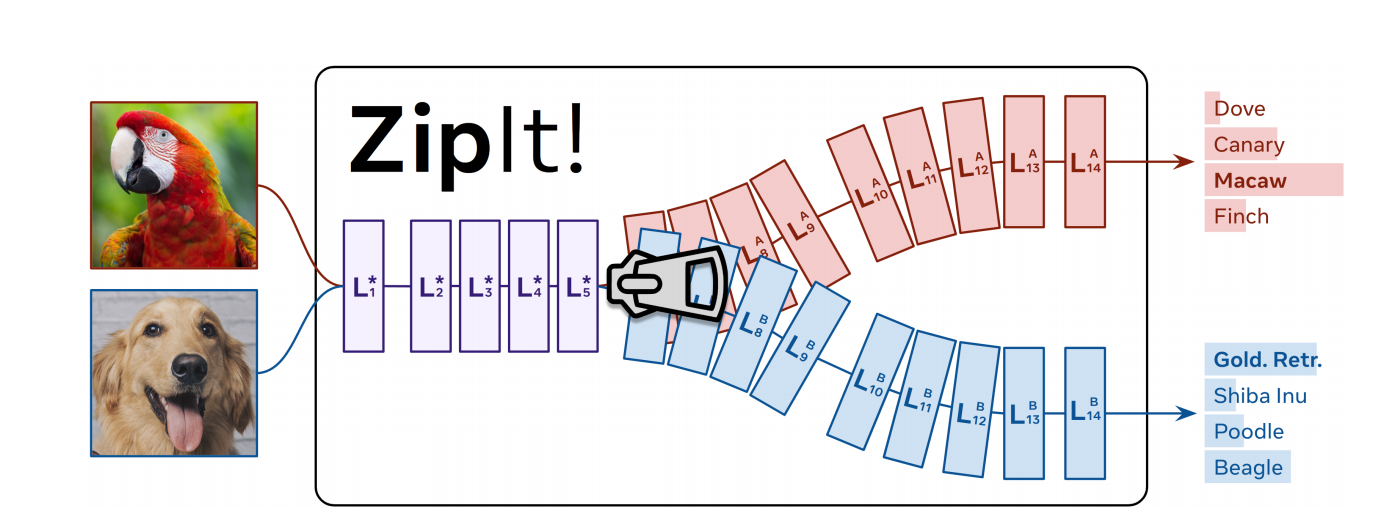
论文的主要贡献是:
-
这篇论文介绍了一种新的方法“ZipIt!”,可以将多个在不同任务上训练的深度学习模型合并成一个单一的多任务模型,而不需要额外的训练。
-
通过泛化模型合并和引入部分压缩,ZipIt!显著改进了在合并在不同任务上训练的模型方面的现有工作,相对于现有方法,它可以获得高达20-60%的精度提高。
-
该论文提出了一种基于图的算法,用于合并和取消合并模型,该算法可以应用于相同架构的模型。此外,该论文分析和剖析了ZipIt!在不同场景中的能力,提供了关于ZipIt!的优点和局限性的见解。
方法
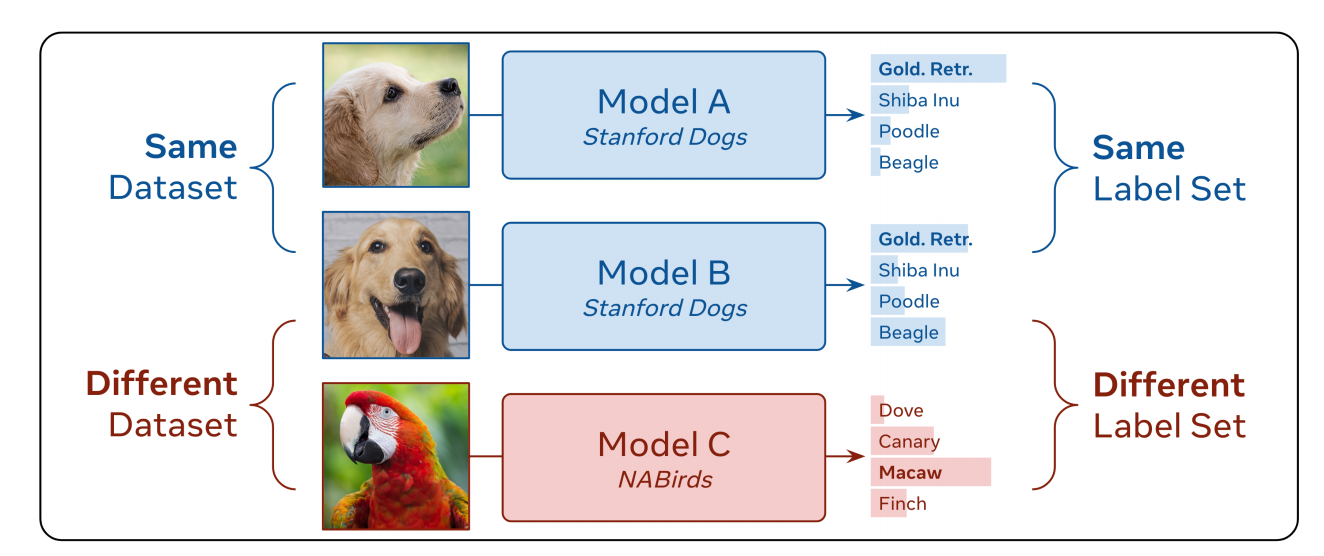
在之前的工作中,重点放在合并来自相同数据集且具有相同标签集的模型上,例如将两个训练用于分类狗品种的模型进行合并。而在这项工作中,论文取消了这个限制,可以**“zip”来自不同数据集且具有不同标签集的模型**,例如合并一个分类狗品种的模型和一个分类鸟种的模型,如上图所示。
在本工作中,论文将模型合并视为将两个模型的checkpoints(即权重集合)联合组合成一个单一的checkpoints,可以执行其组成部分的所有任务。论文通过将一个模型的每一层与另一个模型的相应层合并,并同时修改两个模型来实现这一点(与基于排列的合并相反,后者仅对其中一个模型进行排列)。
论文的目标是从模型 A A A中获取layer L i A ∈ L A L_{i}^{A} \in \mathcal{L}^{A} LiA∈LA,并从模型 B B B中获取 L i B ∈ L B L_{i}^{B} \in \mathcal{L}^{B} LiB∈LB,并将它们合并成一个层 L i ∗ L^∗_i Li∗,该层结合了它们的特征空间,以便在 f i ∗ f_i^∗ fi∗ 中保留来自 f i A f_i^A fiA 和 f i B f_i^B fiB 的信息。
The “Zip” Operation
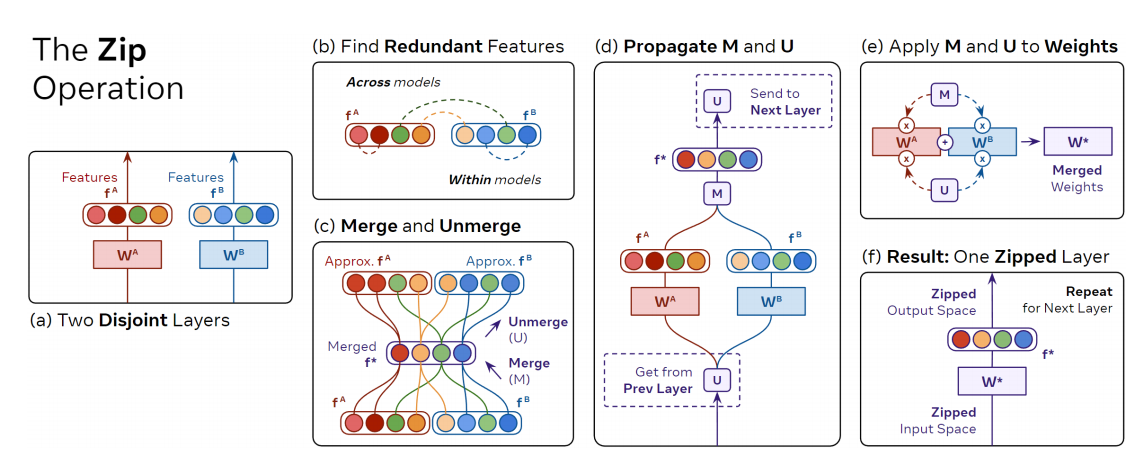
通过利用模型特征中的冗余性逐层合并模型
- 从训练于不同任务的模型中获得具有权重 W A W^A WA和 W B W^B WB的完全不同的层。
- 通过比较它们的激活 f A f^A fA和 f B f^B fB来匹配冗余特征。
- 利用这个匹配来生成merge矩阵 M M M,将 f A f^A fA和 f B f^B fB组合成一个共享的特征空间 f ∗ f^* f∗,并生成相应的撤销合并操作的unmerge矩阵 U U U。
- 为了对齐下一层的输入空间,将 U U U向前传播到网络,并同时从上一层接收一个 U U U矩阵
- 一旦同时拥有输出的 M M M和输入的 U U U,就可以通过应用下面公式将层进行“zip”。
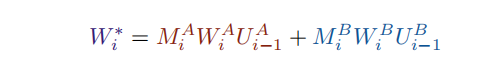
- 结果是一个具有共享输入和输出空间的单个层,然后可以从(1)开始处理下一层。
Zip Propagation
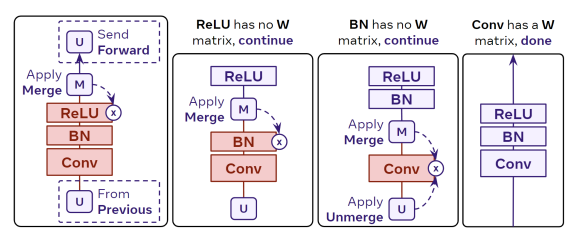
大多数现代神经网络不仅仅是线性层的简单堆叠。在实践中,我们无法将合并和解合并矩阵应用于网络的每一层,因为局部的合并(上面公式)需要该层具有权重矩阵,即该层必须具有独立的输入和输出空间,以便可以解合并输入空间和合并输出空间。其他层(例如BatchNorm、ReLU)没有这样的权重矩阵。
如上图所示,只有当到达Conv层时,我们才能使用上面公式将 M i M_i Mi和 U i U_i Ui合并到其中(在这种情况下,将每个卷积核元素视为独立的)。
实验
论文设计了两种类型的实验来评估不同任务的模型合并(图2):
- 合并在同一数据集的不同类别分割上训练的模型(即,相同数据集但标签集不同)
- 合并在完全不同数据集上训练的模型(即,不同数据集和标签集)。
CIFAR-10 and CIFAR-100
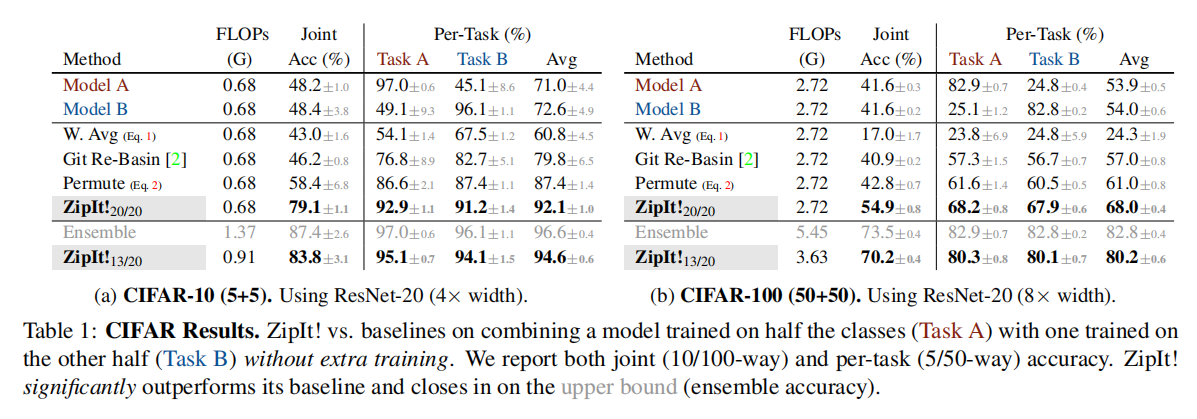
如上表所示,本研究通过训练ResNet-20模型在CIFAR-10和CIFAR-100数据集的不同类别上,展示了ZipIt!方法在合并不相交任务模型方面的优势。与先前方法相比,ZipIt!在联合分类任务中表现出显著的性能提升,超过了Git Re-Basin和基准方法。无论是在CIFAR-10还是CIFAR-100上,ZipIt!都取得了优异的结果,将准确率提高了20%以上。这种方法还支持部分合并,可以根据需要在不同层级上进行模型合并。
ImageNet-1k (200+200)
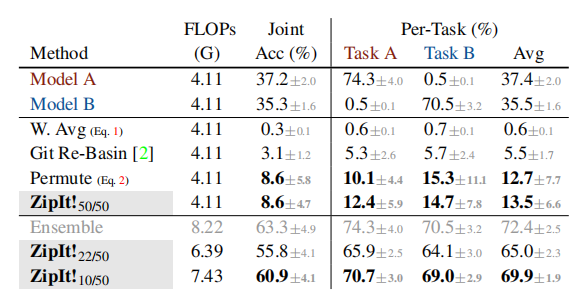
如上表所示,论文对大规模数据进行了测试,训练了5个不同初始化的ResNet-50模型,使用交叉熵损失在ImageNet-1k的不相交的200类子集上进行训练。与不支持部分合并的先前方法相比,论文的方法能够显著提高准确率。在这个极具挑战性的任务上,ZipIt!能够接近集成模型的准确率,并且在节约计算资源方面更加高效。
Multi-Dataset Merging
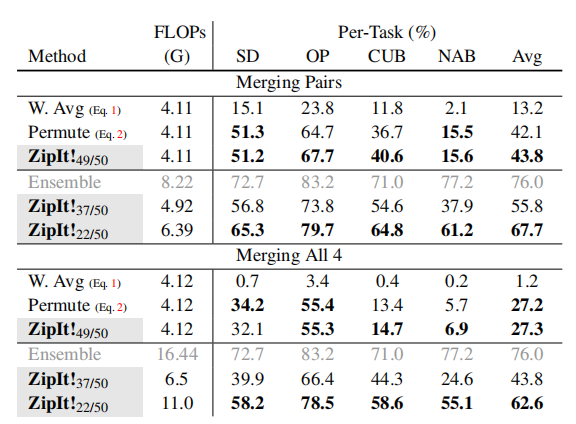
在这个实验中,论文将不同初始化的ResNet-50模型训练在四个完全独立的数据集上,每个数据集都有不同的标签集。通过逐一合并模型对和一次性合并所有四个模型的对比,我们发现ZipIt!稍微优于permute baseline。然而,当论文通过部分解压缩为合并模型增加容量时,ZipIt!在模型对合并上的性能提升高达25.6%,在合并所有四个模型上的性能提升更是达到35.4%。这表明,在合并多个模型时,部分合并是获得强大性能的重要因素。
总结
本文中,研究者着手解决了将训练在完全不同任务上的两个或多个模型合并的极其困难的任务,而无需额外的训练。研究者通过实验证明了之前的工作在这种情况下的不足,并认为这是因为没有在模型内部合并特征,以及一次性合并模型的每一层。然后,研究者引入了名为ZipIt!的通用框架,用于合并模型并解决这些问题,并发现它在许多困难的模型合并设置上明显优于之前的工作和研究者自己的strong baseline。然后,研究者分析了论文方法的行为,并发现在较小的模型容量下,它的性能与基于排列的方法相似,但随着模型容量的增加,它的性能可以更好。研究者希望ZipIt!能成为在合并训练在不同任务上的模型的实际应用中的强大起点。
CVHub是一家专注于计算机视觉领域的高质量知识分享平台,全站技术文章原创率达99%,每日为您呈献全方位、多领域、有深度的前沿AI论文解决及配套的行业级应用解决方案,提供科研 | 技术 | 就业一站式服务,涵盖有监督/半监督/无监督/自监督的各类2D/3D的检测/分类/分割/跟踪/姿态/超分/重建等全栈领域以及最新的AIGC等生成式模型。关注微信公众号,欢迎参与实时的学术&技术互动交流,领取CV学习大礼包,及时订阅最新的国内外大厂校招&社招资讯!