使用OPENCV级联分类器训练模型。首先我们要有opencv_createsamples.exe和opencv_traincascade.exe这两个可执行文件及依赖项。需要的可以私聊我。
第一步:创建一个文件夹,将正样本(想要识别的图片)放到一个文件夹里,这里我们将这个文件夹命名为1。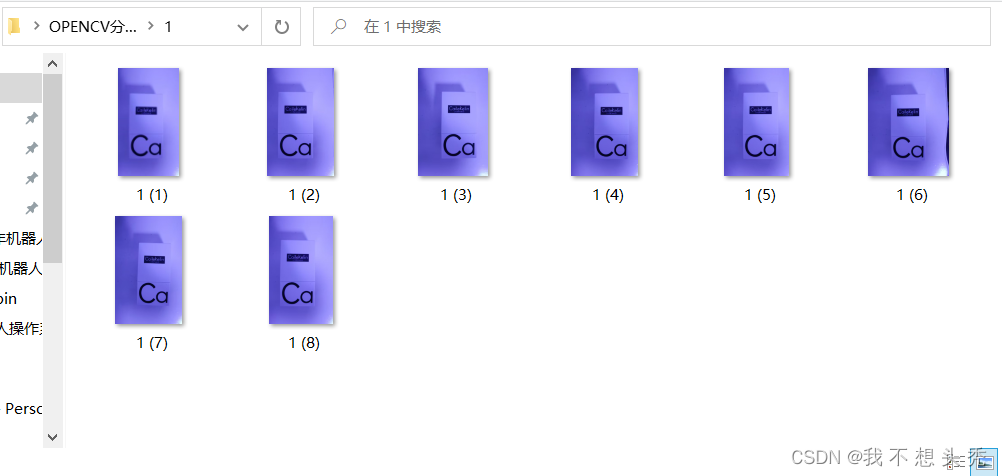
这里我随便找了一个物体作为识别对象,最初拍摄的照片名字很乱,这里我们要进行重命名,以便程序里使用。(注意:这里的正样本数量要足够多,这样识别率会提高,这里为了方便只使用了8个正样本)
第二步:我们要将这些图片转化为灰度图片。
import cv2
imagepath = "C:/Users/huawei/Desktop/1/"
imagepath1 = "C:/Users/huawei/Desktop/pos/"
#转化灰度图和重置大小函数
for i in range(1,9):
image = cv2.imread(imagepath+'1 ('+str(i)+')'+'.jpg',1)
gray = cv2.cvtColor(image,code = cv2.COLOR_BGR2GRAY)
gray1 = cv2.resize(gray,dsize = (50,50))
cv2.imwrite(imagepath1+str(i)+'.jpg',gray1)这里imagepath的路径是未作处理时的正样本图片路径,imagepath1的路径是经过灰度等处理过的将要保存的路径。结果如下图。

第三步:这里提供了负样本处理过的图片,链接:https://pan.baidu.com/s/1omQyLDSn9Buo2jeG5SEJxg
提取码:acno
第四步:创建正样本的描述文件。
import os
PATH = "C:/Users/huawei/Desktop/pos"
dirs = os.listdir(PATH)
for i in dirs:
print(i)
line1 = PATH+'/'+i+' 1 0 0 50 50\n'
with open('C:/Users/huawei/Desktop/info.txt','a') as f:
f.write(line1)
print(f)正样本的描述文件放在info.txt文件里,这里的1 0 0 50 50分别表示 1表示类别 ,0 0 50 50是你处理后正样本的大小格式。
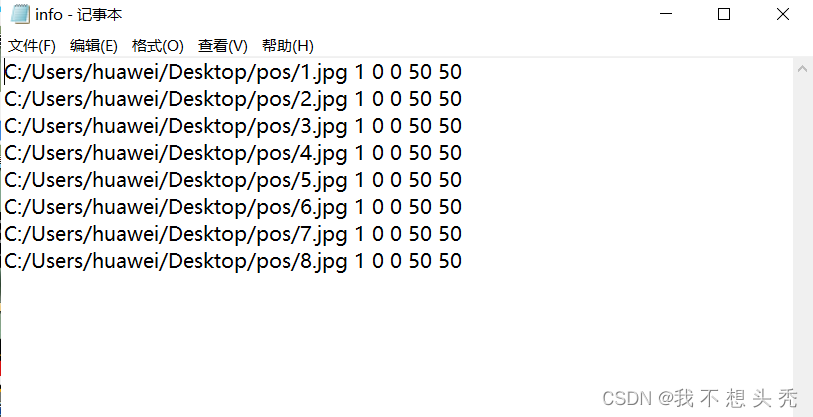
第五步:创建负样本的描述文件 。
#描述负文本
import os
PATH = "D:/OPENCVtrain/neg"
dirs = os.listdir(PATH)
for i in dirs:
print(i)
line1 = PATH+'/'+i+'\n'
with open('C:/Users/huawei/Desktop/bg.txt','a') as f:
f.write(line1)
负样本的描述文件保存到bg.txt文件里,部分截图如下。

第六步:将正样本描述文件(info.txt)和负样本描述文件(bg.txt)放到包含opencv_createsamples.exe和opencv_traincascade.exe的文件夹内,并且创建data文件夹。
第七步:在cmd命令窗口进入含有第六步的两个可执行文件的文件里,输入opencv_createsamples -info info.txt -num 8 -w 50 -h 50 -vec positives.vec,会创建一个下面这个文件。这是我们训练模型时候需要用到的文件。
![]()
第八步:第七步执行后,输入opencv_traincascade.exe -data data -vec positives.vec -bg bg.txt -numPos 8 -numNeg 80 -numStages 10 -w 50 -h 50命令。就会开始训练。
这两条命令里出现很多参数。参数的含义总结如下。
通用参数:
-data <cascade_dir_name>:目录用于保存训练产生的分类器xml文件和中间文件(对于上面的LBP_classifier),如不存在训练程序会创建它;
-vec <vec_file_name>:由 opencv_createsamples 程序生成的包含正样本的vec文件名(对应上面的pos_24_24.vec);
-bg <background_file_name>:背景描述文件,也就是包含负样本文件名的那个描述文件(对应上面的neg\neg.txt);
-numPos <number_of_positive_samples>:每级分类器训练时所用的正样本数目(默认值为2000);
-numNeg <number_of_negative_samples>:每级分类器训练时所用的负样本数目,可以大于 -bg 指定的图片数目(默认值为1000);
-numStages <number_of_stages>:训练的分类器的级数(默认值为20级);
-precalcValBufSize <precalculated_vals_buffer_size_in_Mb>:缓存大小,用于存储预先计算的特征值(feature values),单位为MB(默认值为256);
-precalcIdxBufSize <precalculated_idxs_buffer_size_in_Mb>:缓存大小,用于存储预先计算的特征索引(feature indices),单位为MB(默认值为256);
内存越大,训练时间越短。
-baseFormatSave:这个参数仅在使用Haar特征时有效。如果指定这个参数,那么级联分类器将以老的格式存储(默认不指定该参数项,此时其值为false;一旦指定则其值默认为true);
级联参数:CvCascadeParams类,定义于cascadeclassifier.h
-stageType <BOOST(default)>:级别(stage)参数。目前只支持将BOOST分类器作为级联的类型;
-featureType<{HAAR(default), LBP}>:特征的类型: HAAR - 类Haar特征; LBP - 局部纹理模式特征(默认Harr);
-w <sampleWidth>:训练样本的宽(单位为像素,默认24);
-h <sampleHeight>:训练样本的高(单位为像素,默认24);
训练样本的尺寸必须跟训练样本创建(使用 opencv_createsamples 程序创建)时的尺寸保持一致。
Boosted分类器参数:CvCascadeBoostParams类,定义于boost.h
-bt <{DAB, RAB, LB, GAB(default)}>:Boosted分类器的类型(DAB - Discrete AdaBoost, RAB - Real AdaBoost, LB - LogitBoost, GAB - Gentle AdaBoost为默认);
-minHitRate <min_hit_rate>:分类器的每一级希望得到的最小检测率(默认值为0.995),总的检测率大约为 min_hit_rate^number_of_stages;
-maxFalseAlarmRate <max_false_alarm_rate>:分类器的每一级希望得到的最大误检率(默认值为0.5),总的误检率大约为 max_false_alarm_rate^number_of_stages;
-weightTrimRate <weight_trim_rate>:Specifies whether trimming should be used and its weight,一个还不错的数值是0.95;
-maxDepth <max_depth_of_weak_tree>:弱分类器树最大的深度。一个还不错的数值是1,是二叉树(stumps);
-maxWeakCount <max_weak_tree_count>:每一级中的弱分类器的最大数目(默认值为100)。The boosted classifier (stage) will have so many weak trees (<=maxWeakCount), as needed to achieve the given -maxFalseAlarmRate;
第九步:训练完成后就会在data文件(这是第六步让创建的文件夹)里生成cascade文件,这个就是我们所需要的文件。
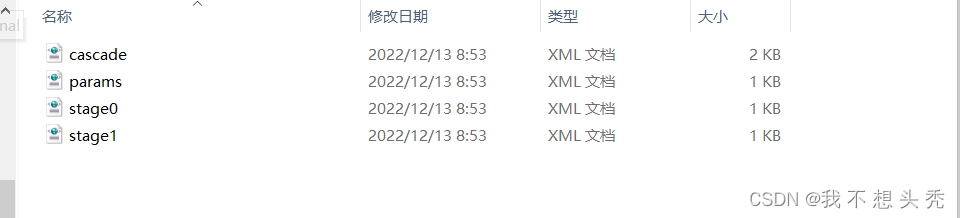
第十步:编写识别物体的程序。
#识别图片
import cv2
import numpy as np
image = cv2.imread("C:/Users/huawei/Desktop/1/1 (1).jpg",1)
gary = cv2.cvtColor(image,code = cv2.COLOR_BGR2GRAY)
face_cascade = cv2.CascadeClassifier('D:/OPENCVtrain/opencv_bin/data/cascade.xml')
box = face_cascade.detectMultiScale(gary,scaleFactor=1.1,minNeighbors=7,minSize=[100,100])
for x,y,w,h in box:
img1 = cv2.rectangle(image,(x,y),(x+w,y+h),(0,0,255),2)
cv2.imshow('img',img1)
cv2.waitKey(0)
cv2.destroyAllWindows()为了方便,我们读取了未处理前的正样本图片进行测试。
cv2.CascadeClassifier('D:/OPENCVtrain/opencv_bin/data/cascade.xml')
#这里的路径就是保存cascade.xml文件的路径这样我们就完成了训练,因为我们这里正样本只用了8个,所以识别效果不是很好,这里只是讲述的一个大概过程,如果想要识别效果好,尽量多的正样本图片。
本人第一次写的博客,如有不对,忘各位指点。