一、简单介绍
1. 自编码器
自动编码器(AE)的结构与原理:
由编码器和解码器组成,编码器和解码器通常是神经网络模型。
输入的数据经过神经网络降维到一个编码,再通过一个神经网络去解码得到一个与输入原始数据一模一样的生成数据,然后通过比较这两个数据去最小化它们之间的差异来训练编码器和解码器的参数。
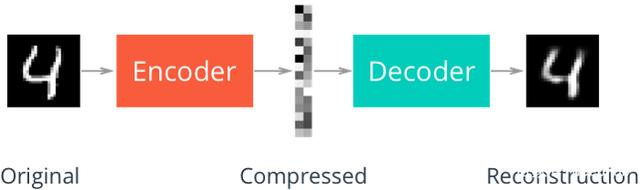
自动编码器特点:
- 与数据相关程度高,因为使用神经网络提取的特征一般是与原始训练集高度相关,意味着自动编码器只能压缩与训练数据相似的数据。
- 压缩数据是有损的。因为在降维的过程中不可避免的要丢失信息。
自动编码器的应用:
- 数据去噪;
- 可视化降维;
- 生成数据。
2. 变分自编码器VAE
2.1 VAE简介
变分自动编码器(VAE):
在自动编码器中需要输入一张图片,然后将图片编码之后得到隐含向量,隐含向量解码得到与原始图片对应的照片。
变分自动编码器可以自己去构造隐藏向量,生成任意图片,只需要给它一个标准正态分布的随机隐含向量,通过解码器就能够生成想要的图片,而不需要给它一个原始的图片。实际情况中需要在准确率与隐含向量服从标准正态分布之间去做一个权衡。KL divergence可以用来权衡两者分布的相似程度。越小表示两种概率分布越接近。
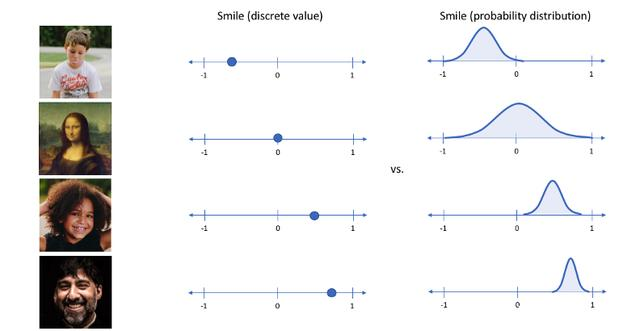
可变自动编码器能够通过正则化潜在空间,使其像下面这样连续地生成新的数据,因此,允许在不同属性之间实现平滑的插值,并消除可能返回不理想输出的间隙。

可变自动编码器以概率方式(分布)编码输入的潜在属性,而不是像普通的自动编码器那样以确定性方式(单值)编码。
2.2 VAE结构
VAE在AE的基础上对均值的encoder添加高斯噪声(正态分布的随机采样),使得decoder(就是右边那个生成器)有噪声鲁棒性;为了防止噪声消失,将所有 p(Z|X) 趋近于标准正态分布,将encoder的均值尽量降为 0,而将方差尽量保持住。这样一来,当decoder训练的不好的时候,整个体系就可以降低噪声;当decoder逐渐拟合的时候,就会增加噪声。

3. 生成对抗网络 GAN
生成对抗网络(Generative Adversarial Networks,GANs)结构与原理:
GANs由生成模型和对抗模型两部分组成。自动编码器就是一般的生成模型。对抗模型就是一个判断真假的判别器。
在训练的时候,先训练判别器。将假的和真的数据都给判别器,优化判别模型。然后训练生成器,具体做法就是固定判别器的参数,通过反向传播优化生成器的参数,希望它得到数据在经过判别器后结果尽可能地接近1,这时只需要通过调整损失函数就可以了。JS Divergence是对称的,它能够用于衡量两种分布之间的差异。
VAE和GAN的本质都是概率分布的映射

CycleGAN
CycleGAN可以看做是2个GAN的融合,一个GAN由生成器G和判别器DY构成,实现从X域到Y域的图像生成和判别;另一个GAN由生成器F和判别器DX构成,实现从Y域到X域的图像生成和判别,两个网络构成循环(cycle)的过程。

4. 扩散模型
扩散模型 是受非平衡热力学的启发。它们定义一个扩散步骤的马尔可夫链,逐渐向数据添加随机噪声,然后学习逆扩散过程,从噪声中构建所需的数据样本。与VAE或流动模型不同,扩散模型是用固定的程序学习的,而且隐变量具有高维度(与原始数据相同)。

马尔科夫链的性质:平稳性。一个概率分布如果随时间变化,那么在马尔可夫链的作用下,它一定会趋于某种平稳分布(例如高斯分布)。只要终止时间足够长,概率分布就会趋近于这个平稳分布。并且,基于马尔可夫链的前向过程,其每一个epoch的逆过程都可以近似为高斯分布。高斯分布是一种很简单的分布,运算量小,这一点是diffusion快的最重要原因。

- 文本生成,Li X L, Thickstun J, Gulrajani I, et al. Diffusion-LM Improves Controllable Text Generation[J]. arXiv preprint arXiv:2205.14217, 2022.
- 少样本条件生成,Sinha A, Song J, Meng C, et al. D2c: Diffusion-decoding models for few-shot conditional generation[J]. Advances in Neural Information Processing Systems, 2021, 34: 12533-12548.
- 翻译,Nachmani E, Dovrat S. Zero-Shot Translation using Diffusion Models[J]. arXiv preprint arXiv:2111.01471, 2021.
- 对话生成,Liu S, Chen H, Ren Z, et al. Knowledge diffusion for neural dialogue generation[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018: 1489-1498.
- 视频生成,Ho J, Salimans T, Gritsenko A, et al. Video diffusion models[J]. arXiv preprint arXiv:2204.03458, 2022.
- 音乐生成,Symbolic music generation with diffusion models[J]. arXiv preprint arXiv:2103.16091, 2021.
- 手写生成 Diffusion models for handwriting generation[J]. arXiv preprint arXiv:2011.06704, 2020.
- 跨模态条件生成 Discrete Contrastive Diffusion for Cross-Modal and Conditional Generation[J]. arXiv preprint arXiv:2206.07771, 2022.
- 语音生成 Diff-tts: A denoising diffusion model for text-to-speech[J]. arXiv preprint arXiv:2104.01409, 2021.
Grad-tts: A diffusion probabilistic model for text-to-speech[C]//International Conference on Machine Learning. PMLR, 2021: 8599-8608. - 少样本 Few-Shot Diffusion Models
- 检索增强的扩散模型 Retrieval-Augmented Diffusion Models
二、代码
Simple GAN
import numpy as np
import matplotlib
from matplotlib import pyplot as plt
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers,optimizers,losses
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.python.keras import backend as K
from tensorflow.keras.utils import plot_model
from IPython.display import Image
import cv2
import PIL
import json, os
import sys
import labelme
import labelme.utils as utils
import glob
import itertools
tf.enable_eager_execution()
class GAN():
def __init__(self, #定义全局变量
):
self.img_shape = (52, 52, 1) #输入图片28x28
self.save_path = r'./GAN.h5' #模型保存的位置
self.img_path = r'./photo' #图片保存的位置
self.batch_size = 20 #
self.latent_dim = 100 #keras输入是100维度的张量
self.sample_interval=1 #生成器生成图片的周期 和epoch有关
self.epoch=10 #100
#建立GAN模型的方法
self.generator_model = self.build_generator() #生成器对象
self.discriminator_model = self.build_discriminator() #判别器对象
self.model = self.bulid_model() #GAN模型训练
def build_generator(self):#生成器
input=keras.Input(shape=self.latent_dim)
x=layers.Dense(256)(input)
x=layers.LeakyReLU(alpha=0.2)(x)
x=layers.BatchNormalization(momentum=0.8)(x)
x = layers.Dense(512)(x)
x = layers.LeakyReLU(alpha=0.2)(x)
x = layers.BatchNormalization(momentum=0.8)(x)
x = layers.Dense(1024)(x)
x = layers.LeakyReLU(alpha=0.2)(x)
x = layers.BatchNormalization(momentum=0.8)(x)
x=layers.Dense(np.prod(self.img_shape),activation='sigmoid')(x)
output=layers.Reshape(self.img_shape)(x)
model=keras.Model(inputs=input,outputs=output,name='generator')
model.summary()
return model
def build_discriminator(self):#判别器
input=keras.Input(shape=self.img_shape) #输入是图片
x=layers.Flatten(input_shape=self.img_shape)(input) #展开
x=layers.Dense(512)(x) #全连接
x=layers.LeakyReLU(alpha=0.2)(x)
x=layers.Dense(256)(x)
x=layers.LeakyReLU(alpha=0.2)(x)
output=layers.Dense(1,activation='sigmoid')(x)
model=keras.Model(inputs=input,outputs=output,name='discriminator')
model.summary()
return model
def bulid_model(self):#建立GAN模型
self.discriminator_model.compile(loss='binary_crossentropy',
optimizer=keras.optimizers.Adam(0.0001, 0.000001),
metrics=['accuracy']) #对判别器进行设置loss和优化器
self.discriminator_model.trainable = False #使判别器不训练
inputs = keras.Input(shape=self.latent_dim) #
img = self.generator_model(inputs)
outputs = self.discriminator_model(img)
model = keras.Model(inputs=inputs, outputs=outputs)
model.summary() #输出计算过程
model.compile(optimizer=keras.optimizers.Adam(0.0001, 0.000001),
loss='binary_crossentropy',
)
return model
def load_data(self):
(train_images, train_labels), (test_images, test_labels) = (np.load(r'./data/raw/arr_0.npy')[:30000],np.load(r'./data/raw/arr_1.npy')[:30000]),(np.load(r'./data/raw/arr_0.npy')[30000:],np.load(r'./data/raw/arr_1.npy')[30000:])
train_images = train_images /255 #将像素值归一化
train_images = np.expand_dims(train_images, axis=3) #在axis=3的维度后面增加一个维度 数值是1
print('img_number:',train_images.shape)
return train_images
def train(self):
train_images=self.load_data()#读取数据
#生成标签
valid = np.ones((self.batch_size, 1))
fake = np.zeros((self.batch_size, 1))
step=int(train_images.shape[0]/self.batch_size)#计算步长
print('step:',step)
for epoch in range(self.epoch):
train_images = (tf.random.shuffle(train_images)).numpy()#每个epoch打乱一次
if epoch % self.sample_interval == 0:
self.generate_sample_images(epoch)
for i in range(step):
idx = np.arange(i*self.batch_size,i*self.batch_size+self.batch_size,1)#生成索引
imgs =train_images[idx]#读取索引对应的图片
noise = np.random.normal(0, 1, (self.batch_size, 100)) # 生成标准的高斯分布噪声
gan_imgs = self.generator_model.predict(noise)#通过噪声生成图片
#----------------------------------------------训练判别器
discriminator_loss_real = self.discriminator_model.train_on_batch(imgs, valid) # 真实数据对应标签1
discriminator_loss_fake = self.discriminator_model.train_on_batch(gan_imgs, fake) # 生成的数据对应标签0
discriminator_loss = 0.5 * np.add(discriminator_loss_real, discriminator_loss_fake)
#----------------------------------------------- 训练生成器
noise = np.random.normal(0, 1, (self.batch_size, 100))
generator_loss = self.model.train_on_batch(noise, valid)
if i%10==0:#每十步进行输出
print("epoch:%d step:%d [discriminator_loss: %f, acc: %.2f%%] [generator_loss: %f]" % (
epoch,i,discriminator_loss[0], 100 * discriminator_loss[1], generator_loss))
# self.model.save(self.save_path)#存储模型
def pred(self):#载入模型并生成图片
model=keras.models.load_model(self.save_path) #载入模型
model.summary() #判别器参数报备
noise = np.random.normal(0, 1, (1, self.latent_dim)) #来个噪声
generator=keras.Model(inputs=model.layers[1].input,outputs=model.layers[1].output) #输入输出
generator.summary() #生成器参数报备
img=np.squeeze(generator.predict([noise])) #删除所有1维度的条目
plt.imshow(img)
plt.show()
print(img.shape)
def generate_sample_images(self, epoch):#生成图片
row, col = 5, 5#行列的数字
noise = np.random.normal(0, 1, (row * col, self.latent_dim))#生成噪声
gan_imgs = self.generator_model.predict(noise)
fig, axs = plt.subplots(row, col)#生成5*5的画板
idx = 0
for i in range(row):
for j in range(col):
axs[i, j].imshow(gan_imgs[idx, :, :, 0], cmap='gray')
axs[i, j].axis('off')
idx += 1
# fig.savefig(self.img_path+"/%d.png" % epoch)
plt.close()#关闭画板
if __name__ == '__main__':
GAN = GAN()
GAN.train()推荐阅读
diffusion model最近在图像生成领域大红大紫,如何看待它的风头开始超过GAN? - 知乎