前言:
本人是个新人博主,本篇博客或有点长,还望各位大佬耐心看完,如果是爬虫小白相信您能有所收货,并完成这个案例运用到自己的生活当中,本项目较为综合,适合爬虫小白在学完协程之后作为一个综合练手项目。
本文涉及的主要爬虫要点如下,如果没有相关知识可以自行先学习一下在看代码,尤其是协程相关内容,建议先补相关的基础再阅读本篇博客作为练手,效果更佳。
1. python基础
2. 请求获取数据的方式
3. xpath提取数据
4. 正则表达式提取数据
5. 协程爬取数据
一、准备工作
各种包的安装
下面是展示本案例所需的各种包的安装,供各位大佬查漏补缺,记得删除#之后注释的内容,不建议大家在pycharm的settings中下载如下的包,并且有条件更建议大家下载anaconda,将自己的环境切换成anaconda的,在anaconda中安装,这样就可以一次吃饱,新建工程后只要环境还是anaconda的,就可以不用再重复装包了。
pip install requests # 安装requests请求的包
pip install lxml # 主要用里面的etree模块,用于xpath解析
pip install asyncio # 使用协程所需要的包
pip install aiohttp # 协程发送请求的包
pip install aiofiles # 协程中保存文件的包
pip install pycrytodome # 用于对数据进行解密(部分电影需要解密)导包的时候导入Crypto
# 如果安装出现错误,请先尝试使用国内镜像源,如用清华源下载requests模块就需要使用如下指令
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple
导包
所需要的各种包在上面均已告知下载方式,下面是具体的导包
import requests # 发送请求的requests模块
import re # 使用正则
import asyncio # 使用协程
import aiohttp # 协程中发送请求
import aiofiles # 协程中的文件流
import os # 使用一些命令行的功能
from lxml import etree # xpath解析所需
from urllib.parse import urljoin # 拼接url,使得url完整
from Crypto.Cipher import AES # 解密模块,此处因为是AES加密,所以导入AES模块
爬取目标
具体地址本博客不放(狗头保命),网站简称wbdy。
视频获取过程
1. 请求到m3u8文件
2. 加载ts文件
3. 正常播放视频资源
m3u8文件简介
m3u8是一种视频播放标准,编码采用UTF-8,其格式如下:
#EXTM3U
#EXT-X-VERSION:3
#EXT-X-TARGETDURATION:4
#EXT-X-PLAYLIST-TYPE:VOD
#EXT-X-MEDIA-SEQUENCE:0
#EXTINF:2.667,
https://hey05.cjkypo.com/20220731/5TKw4kYs/1100kb/hls/F9HUFq1M.ts
#EXTINF:1.667,
https://hey05.cjkypo.com/20220731/5TKw4kYs/1100kb/hls/zHp9UZuq.ts
#EXTINF:1.667,
https://hey05.cjkypo.com/20220731/5TKw4kYs/1100kb/hls/fglNVIm5.ts
#EXTINF:3.333,
https://hey05.cjkypo.com/20220731/5TKw4kYs/1100kb/hls/1dLHM64b.ts
#EXTINF:1.633,
https://hey05.cjkypo.com/20220731/5TKw4kYs/1100kb/hls/cNwwlEiN.ts
.....
#EXT-X-ENDLIST
由此我们可以看到m3u8其实是将一个电影分解成一个个片段,记录每个片段的数据即上面所示的结尾是xxx.ts的url,记录时长的是#EXTINF后面的参数,至于文件头可以暂时不用管。就普遍理性而言,一个ts正常只占几秒钟,因此我们将所有的ts文件获取到,再进行拼接就可以获得一部完整的电影。
m3u8格式的好处在于在加载初期就可以直接先加载十几个或者几十个ts,先播放着,后续再边播放边加载后面的ts,是现在视频播放的一种很重要的格式。
网页分析
1. 拿到视频页面的源代码
2. 从源代码中找到iframe,提取iframe中的src(如果抓包中可以找到m3u8的url可以直接跳过1,2步,直接请求url获取结果)
3. 请求到src对应的页面源代码,解析出m3u8文件地址
4. 获取m3u8中的ts的url并获取到ts文件
5. 如果数据进行了加密的话需要对数据进行解密
7. 对ts文件进行合并,还原成mp4文件
网页请求
这里我们直接将requests请求获取数据的过程写成一个函数,这样之后涉及到请求网页的时候直接调用该函数即可,该函数如下:
# 获取url对应的内容
# param: url——所要请求网页的url
# pageContent——请求返回的网页内容
def Get_url_content(url):
resp = requests.get(url, header)
pageContent = resp.text
resp.close()
return pageContent
二、获取m3u8文件
简陋版:直接请求m3u8文件地址
我们直接按下f12的开发者工具,来到network选项,打开preview并点击左侧的包中查看请求返回给浏览器的结果,直到找到preview中显示是一个视频的m3u8文件格式的包,如下图所示:
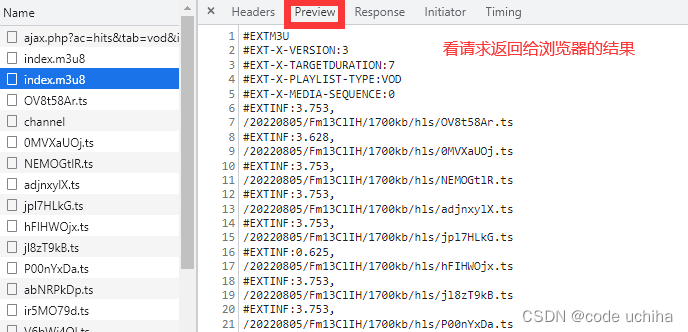
之后我们在这个包的headers中寻找request的url,请求方式以及各种请求头(主要是UA)

之后就是将获取的结果保存到本地的txt中,进行后面的ts文件url提取部分
使用该方法具体获取m3u8文件过程代码如下:
import os.path
import requests
url = "https://vod1.bdzybf7.com/20220805/Fm13ClIH/1700kb/hls/index.m3u8"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36"
}
resp = requests.get(url=url, headers=headers, verify=False)
filename = url.split("/")[-1] # m3u8文件名称
with open(filename, mode="w", encoding="utf-8") as f: # 写入文件
f.write(resp.text)
resp.close()
当然这只是你只想爬一部电影的情况下,你可以直接这么搞,甚至为了省事可以直接将preview中的结果直接ctrl+a全选,然后ctrl+cv到本地新建的txt文件中,一步到位。但以普遍理性而言,这种下载方式是不符合批量下载的要求的,而且这样做就太不爬虫了,因此下面从源代码出发,我们看看是否可以寻找一种方法进行批量下载电影。
正式版:从源码出发
在网页源码中,我们右击查看网页源代码,直接ctrl+f搜索m3u8即可在源代码中找到关于m3u8文件的url。至于为什么需要右击查看网页源代码,是因为在调试工具中的elements选项卡中是实时的html代码,其中有的代码是经过js渲染后的,而我们requests获取的只能是网页最初的源代码,因此我们需要网页源代码中的代码才是requests返回的源码。查找结果如下,可以看到源代码中有且只有一个地方有m3u8文件的url,

使用xpath解析就可以获取到该url。由于我们发现在源代码中包含url的标签iframe的上一层div标签的class值为唯一的,因此写xpath的时候就可以直接根据该div的class属性值向下找到iframe,进而找到其中的src属性值,提取到url,具体的xpath如下所指示:
"//div[@class='pbbox embed-responsive embed-responsive-16by9']/iframe/@src"
但是这个url不全,因此我们需要对其进行url补全,即在其最前端添加外层网页的url:https://v.wbdy.tv,这里直接使用urljoin函数就可以解决。之后我们对该url发送请求,获取该url的相应结果,相应的代码如下所示,为了防止一次请求失败,我在这里会重试10次。
def Get_m3u8_url(url):
print("开始获取m3u8地址")
for i in range(10):
try:
page_content = Get_url_content(url)
page_html = etree.HTML(page_content)
m3u8_url = page_html.xpath("//div[@class='pbbox embed-responsive embed-responsive-16by9']/iframe/@src")[0]
m3u8_url = urljoin(url, m3u8_url)
print("成功获取到m3u8地址")
return m3u8_url
except:
if i < 9:
print(f"获取m3u8地址失败,正在进行第{
i}次重试")
else:
print("获取m3u8失败,请稍后重试")
return
获取之后发现返回的结果是一个网页,可以播放电影,因此这还不是我们要找的m3u8文件。
接着我们打开开发者工具中的Elements选项卡后搜索m3u8,可以发现有一个xxx.m3u8藏在js代码中,我们简单通过request请求该网页url后看到返回结果中是有该m3u8的链接的,如下图所示。

由于其在js内,不再适合“靓汤”或者xpath了,但其归根结底还是个文本,因此我们确定可以直接使用正则表达式提取该js中隐藏的真m3u8文件。具体的代码如下,为了防止出错,依旧是访问了10次:
# 获取m3u8url的内容
# param: m3u8_url——m3u8的url地址
# m3u8_first_url——m3u8文件的url地址
def Get_first_m3u8(m3u8_url):
print("正在获取第一层m3u8_url")
for i in range(10):
try:
page_content = Get_url_content(m3u8_url)
obj = re.compile('url: "(?P<url>.*?)"') # 正则
m3u8_first_url = obj.search(page_content)["url"]
print("获取第一层m3u8_url成功")
return m3u8_first_url
except:
if i < 9:
print(f"获取第一层m3u8_url失败,正在进行第{
i}次重试")
else:
print("获取第一层m3u8_url失败,请稍后重试")
return
我们对该url发起请求后获得其响应,可以看到其中的m3u8文件的内容如下所示,里面摆放的又是一个m3u8地址,证明我们还需要再次对该m3u8的url发起请求获取数据,并且这个url还是不全的,需要继续使用urljoin函数将其与当前页面的url进行拼接。
#EXTM3U
#EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=1700000,RESOLUTION=1280x720
/20220805/Fm13ClIH/1700kb/hls/index.m3u8
请求该url后,我们终于获取到了真正的m3u8文件,具体代码如下所示:
# 下载m3u8文件
# param:m3u8_first_url——上一步从m3u8文件汇总获取的电影m3u8文件的url
def Download_m3u8(m3u8_first_url):
print("开始获取第二层m3u8_url")
for i in range(10):
try:
m3u8_url_content = Get_url_content(m3u8_first_url).split()[-1]
m3u8_url_content = urljoin(m3u8_first_url, m3u8_url_content)
print("获取第二层m3u8成功")
break
except:
if i < 9:
print(f"获取第二层m3u8_url失败,正在进行第{
i}次重试")
else:
print("获取第二层m3u8_url失败,请稍后重试")
return
print("开始获取m3u8文件内容")
for i in range(10):
try:
m3u8_content = Get_url_content(m3u8_url_content)
except:
if i < 9:
print(f"获取m3u8文件内容失败,正在进行第{
i}次重试")
else:
print("获取m3u8文件内容失败,请稍后重试")
with open("data/ColdJoke2.txt", 'w', encoding='utf-8') as f: # 此处在当前目录下有个data文件夹,需要创建一下,也可以如捡漏版代码一样用os创建文件夹,此处博主就不再修改
f.write(m3u8_content)
print("获取m3u8文件内容成功")
文件结果显示,我们获得了真正的包含电影的m3u8文件,因为其中包括了每个ts的url和每个ts的持续时间,且一共有几千个ts,如果不放心的话,各位可以将其中的时间信息提取出来做个加法,看看是否与电影时长相吻合。m3u8文件的部分如下所示:
#EXTM3U
#EXT-X-VERSION:3
#EXT-X-TARGETDURATION:7
#EXT-X-PLAYLIST-TYPE:VOD
#EXT-X-MEDIA-SEQUENCE:0
#EXTINF:3.753,
/20220805/Fm13ClIH/1700kb/hls/OV8t58Ar.ts
#EXTINF:3.628,
/20220805/Fm13ClIH/1700kb/hls/0MVXaUOj.ts
#EXTINF:3.753,
/20220805/Fm13ClIH/1700kb/hls/NEMOGtlR.ts
#EXTINF:3.753,
/20220805/Fm13ClIH/1700kb/hls/adjnxylX.ts
#EXTINF:3.753,
/20220805/Fm13ClIH/1700kb/hls/jpl7HLkG.ts
#EXTINF:0.625,
/20220805/Fm13ClIH/1700kb/hls/hFIHWOjx.ts
...
#EXT-X-ENDLIST
至此我们经历各种折腾,终于是获取到了完整的m3u8文件,将该文件保存下来作为我们下一步工作的输入,即提取所有的ts文件并将其合并成一部完整的电影。
三、获取一系列ts文件
无加密版
由于我们获取了装有ts文件url的m3u8文件,并将该文件保存到了本地,因此我们可以直接通过读取本地的文件,并将其中的每个ts的url提取出来,通过requests发送请求获取ts文件,由于文件数量多,请求时间长,因此我们可以将所有的ts保存进一个本地的文件夹,方便后续的拼接工作。
此外,由于文件数量众多,下载过程均为一致的,可以说是非常适合采用协程的方式进行爬取。至于文件顺序可以不用担心,我们可以稍微做个小处理。由于我们发现m3u8文件中是按顺序记录的ts文件的url地址,并且url最后的xxx.ts是没有重复的,因此我们可以考虑在将ts文件保存到本地的时候将xxx.ts作为文件的文件名,这样我们就可以在之后通过m3u8文件将正确的ts文件顺序拼接起来。
理论成立,来看实际操作。既然是协程,那我们就自然而然想到需要先写一个下载单个ts的函数。方法依旧是请求url,然后获取响应,将响应内容以二进制方式写入文件中。但是注意的是都要讲写法写成协程的方式,并且每次遇到读写都需要加上await。未学习协程的可以考虑先去补下基础,因为不使用协程的话爬取会很慢很慢此外还有一个注意点是需要加上semaphore,这个参数的意义在于限制并发量,不然超过并发量的话程序会直接报错,这是来自操作系统的限制。代码如下所示:
semaphore = asyncio.Semaphore(200) # 一次最多200个文件,个人体验是win下最好不要超过400,最多是500
# 下载一个ts文件
# param:url——ts文件的url
# semaphore——最大并发量
async def Download_one_ts(url, semaphore):
name = url.split("/")[-1].strip()
for i in range(10):
try:
async with semaphore: # 限制并发量
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
ts_content = await resp.content.read()
async with aiofiles.open("ts解码前/" + name, 'wb') as f: # 此处也需要现在路径下新建一个“ts解码前”这个文件夹
await f.write(ts_content)
print(f"{
url}获取成功")
except:
if i < 9:
print(f"获取失败 {
url}")
else:
print(f"获取失败{
url},请稍后重试")
常规电影中下载最难的地方解决了,下面就是写一个函数将下载ts文件串起来,当然也得是协程。此时我们面临一个最原始的问题,那就是我们如何从m3u8文件中获得url呢?这其实也很简单,python和m3u8文件的格式都给我们安排的明明白白的。那就是利用m3u8文件格式的特殊性,使用starwith函数检测每行是否是以#开头,如果是则跳过,不是则认为其实一个url,并使用urljoin函数将其与当前页面的url进行拼接。最后我们将其传入上面写完的下载ts的函数,并将其打包成任务放进任务列表里,具体实现如下:
semaphore = asyncio.Semaphore(200)
# 下载所有的ts
# param:semaphore——最大并行量
async def Download_all_ts(semaphore):
tasks = [] # 任务列表
with open("data/ColdJoke2.txt", 'r', encoding='utf-8') as f:
for line in f:
if line.startswith("#"):
continue
tasks.append(asyncio.create_task(Download_one_ts(line.strip(), semaphore))) # 将其放进任务列表
await asyncio.wait(tasks) # 将任务挂起
loop = asyncio.get_event_loop() # 启动协程
loop.run_until_complete(Download_all_ts(semaphore))
loop.close()
加密版
网吧电影中有的电影的数据是被加密过的,此处纯粹是我在找《十万个冷笑话2》过程中的偶然发现,居然有数据是加密过的。虽然里面也直接放了ts,但是ts文件的内容是加密过的,如果还是按照上面的方法的话,我们最后拼出来的文件是无法播放的。
我们一起来研究一下,首先前面的过程和上面的无加密版是如出一辙的,直到我们找到存放电影ts文件的m3u8中有所不同。我们一起来看一下加密后的m3u8文件:
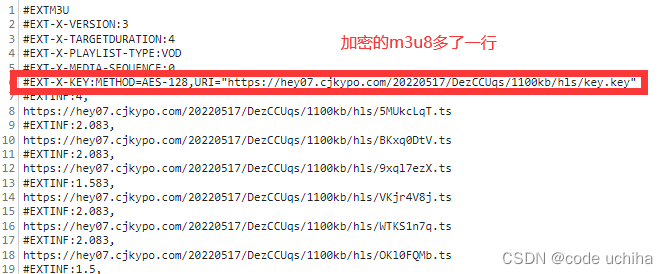
如上图所示,加密后的m3u8相较于未加密的文件多了红框中的一行。我们来简单看一下其中的内容,首先一个头部#EXT-X-KEY就告知我们里面加密了,并且有key,之后的信息解读如下:
METHOD=AES-128 # 说明其加密方式是AES-128
URI=“https://hey07.cjkypo.com/20220517/DezCCUqs/1100kb/hls/key.key” # 这句话表明加密的秘钥藏在这个url中
解读出来了我们就目标很明确了,直接先对这个url申请,看看里面藏着什么,大概率是我们加密解密需要用到的秘钥,提取的方法同时是正则,因为这是一个文本而不是html,不适合用“靓汤”或者xpath,获取过程如下,要注意的是需要对获取结果的秘钥重新encode成字节类型,因为加密的时候需要其为字节类型。
# 获取秘钥
# param:key——解密的秘钥
def getKey():
obj = re.compile('URI="(?P<key>.*?)"')
key_url = ""
with open("data/ColdJoke2.txt", "r", encoding='utf-8') as f:
key_url = obj.search(f.read())["key"]
key_str = Get_url_content(key_url)
key = key_str.encode("utf-8") # 变成字节
return key
现在离解密已经是唾手可得了,我们直接就新建一个AE对象(自己取的),秘钥是上面获取的秘钥,模式为CBC,iv就直接给b"0000000000000000",注意iv和key都得是字节类型,因此iv直接在前面加个b表示转为字节类型。
# 解密ts文件并保存
# param:filename——需要解密的文件名
# key——秘钥
# semaphore——最大并行量
async def Decode_ts_one(filename, key, semaphore):
print("开始解码" + filename)
aes = AES.new(key=key, IV=b"0000000000000000", mode=AES.MODE_CBC)
async with semaphore:
async with aiofiles.open("ts解码前/" + filename, 'rb') as fRead, aiofiles.open("ts解码后/" + filename, 'wb') as fWrite:
content = await fRead.read()
content_decode = aes.decrypt(content)
await fWrite.write(content_decode)
print(filename + "解码完成")
最后这里就和未加密版的最后是一样的,写一个函数将上面解密一个文件的包装成任务并添加进任务列表。
# 解密并保存所有ts文件
# param:key——秘钥
# semaphore——最大并行量
async def Decode_ts(semaphore, key):
tasks = []
key = getKey()
with open("data/ColdJoke2.txt", "r", encoding='utf-8') as f:
for line in f:
if line.startswith("#"):
continue
else:
name = line.split("/")[-1].strip()
tasks.append(asyncio.create_task(Decode_ts_one(name, key, semaphore)))
await asyncio.wait(tasks)
loop = asyncio.get_event_loop() # 启动协程
loop.run_until_complete(Decode_ts(semaphore, key))
loop.close()
四、合并ts文件
在上一大步骤中,我们已经将电影中的所有ts文件下载下来并保存进了文件夹中。因此我们现在的目标明确,任务简单,只需要将这些个ts文件按顺序拼接起来就能得到一部完整的电影啦。在windows中,拼接视频所用的命令如下:
copy /b 输入文件 输出文件
其中,输入文件之间用“+”连接。于是乎,我们只需要从我们的m3u8文件中,按顺序再读一次文件,并使用“+”将这些文件串联起来,最后再指定输出文件就大功告成了。这里再使用分治的思想,即将一个大任务分解成一个个小任务,这里由于有几千个ts文件,因此我们一条指令拼接100个ts文件,并按顺序给合并文件的名字命名为1.ts,2.ts,3.ts······,这样做是方便最后将这些拼接的ts按顺序合并成完整的视频。
值得注意的是,并不是ts数目可以被100整除,因此在循环过后会有残余的ts文件留下来,因此在训练后还需要再讲剩下所有的ts文件也合并为一个ts。
最后一部就是将所有的1.ts,2.ts,3.ts······合并成一部完整的电影,具体的代码如下所示:
# 合并ts文件
# param:name_list——需要合并的文件列表
def merge(name_list):
temp = []
n = 1
for i in range(len(name_list)):
name = name_list[i]
temp.append(name)
if i !=0 and i%100 == 0:
cmd_fileName = "+".join(temp)
os.system(f"copy /b {
cmd_fileName} {
n}.ts")
temp = []
n += 1
# 处理能被100整除的剩下的ts文件
cmd_fileName = "+".join(temp)
os.system(f"copy /b {
cmd_fileName} {
n}.ts")
temp = []
n += 1
for i in range(n):
temp.append(f"{
i+1}.ts")
cmd_fileName = "+".join(temp)
os.system(f"copy /b {
cmd_fileName} ColdJoke2.mp4")
需要注意的是拼接工作需要将路径转换至ts路径下,因此在进行上一步之前需要先将路径切换,在合并完之后还得切回来。至此爬取一部电影就大功告成
# 合并所有ts文件
# param:code_ornot——是否加密,用于选择ts所在的文件夹
def merge_ts(code_ornot):
name_list = []
with open("data/ColdJoke2.txt", "r", encoding='utf-8') as f:
for line in f:
if line.startswith("#"):
continue
name_list.append(line.split("/")[-1].strip()) # 按顺序获取ts文件名称并加进名字列表中
nowDir = os.getcwd() # 获取当前路径,方便后面切回
if code_ornot == 1: # 切换进ts文件夹
os.chdir("ts解码后")
else:
os.chdir("ts解码前")
merge(name_list)
os.chdir(nowDir) # 切回项目路径
print("下载完成")
五、总结
本项目综合而言涉及的点较多,较适合学完协程的做一个综合性训练。全部的完整代码可以从下面获取,但是因为涉及到解密的原因,代码有点混乱,各位大佬可自行调整源码,在下就先不肝了,实在肝不动了。
import requests
import re
import asyncio
import aiohttp
import aiofiles
import os
from lxml import etree
from urllib.parse import urljoin
from Crypto.Cipher import AES
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
# 获取url对应的内容
def Get_url_content(url):
resp = requests.get(url, header)
pageContent = resp.text
resp.close()
return pageContent
# 获得m3u8地址
def Get_m3u8_url(url):
print("开始获取m3u8地址")
for i in range(10):
try:
page_content = Get_url_content(url)
page_html = etree.HTML(page_content)
m3u8_url = page_html.xpath("//div[@class='pbbox embed-responsive embed-responsive-16by9']/iframe/@src")[0]
m3u8_url = urljoin(url, m3u8_url)
print("成功获取到m3u8地址")
return m3u8_url
except:
if i < 9:
print(f"获取m3u8地址失败,正在进行第{
i}次重试")
else:
print("获取m3u8失败,请稍后重试")
return
# 获取第一层m3u8地址
def Get_first_m3u8(m3u8_url):
print("正在获取第一层m3u8_url")
for i in range(10):
try:
page_content = Get_url_content(m3u8_url)
obj = re.compile('url: "(?P<url>.*?)"')
m3u8_first_url = obj.search(page_content)["url"]
print("获取第一层m3u8_url成功")
return m3u8_first_url
except:
if i < 9:
print(f"获取第一层m3u8_url失败,正在进行第{
i}次重试")
else:
print("获取第一层m3u8_url失败,请稍后重试")
return
# 获取第二层m3u8地址并下载m3u8文件
def Download_m3u8(m3u8_first_url):
print("开始获取第二层m3u8_url")
for i in range(10):
try:
m3u8_url_content = Get_url_content(m3u8_first_url).split()[-1]
m3u8_url_content = urljoin(m3u8_first_url, m3u8_url_content)
print("获取第二层m3u8成功")
break
except:
if i < 9:
print(f"获取第二层m3u8_url失败,正在进行第{
i}次重试")
else:
print("获取第二层m3u8_url失败,请稍后重试")
return
print("开始获取m3u8文件内容")
for i in range(10):
try:
m3u8_content = Get_url_content(m3u8_url_content)
except:
if i < 9:
print(f"获取m3u8文件内容失败,正在进行第{
i}次重试")
else:
print("获取m3u8文件内容失败,请稍后重试")
with open("data/ColdJoke2.txt", 'w', encoding='utf-8') as f:
f.write(m3u8_content)
print("获取m3u8文件内容成功")
# 协程下载ts文件
async def Download_one_ts(url, semaphore):
name = url.split("/")[-1].strip()
for i in range(10):
try:
async with semaphore:
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
ts_content = await resp.content.read()
async with aiofiles.open("ts解码前/" + name, 'wb') as f:
await f.write(ts_content)
print(f"{
url}获取成功")
except:
if i < 9:
print(f"获取失败 {
url}")
else:
print(f"获取失败{
url},请稍后重试")
async def Download_all_ts(semaphore):
tasks = []
with open("data/ColdJoke2.txt", 'r', encoding='utf-8') as f:
for line in f:
if line.startswith("#"):
continue
tasks.append(asyncio.create_task(Download_one_ts(line.strip(), semaphore)))
await asyncio.wait(tasks)
# 合并ts文件
def merge(name_list):
temp = []
n = 1
for i in range(len(name_list)):
name = name_list[i]
temp.append(name)
if i !=0 and i%100 == 0:
cmd_fileName = "+".join(temp)
os.system(f"copy /b {
cmd_fileName} {
n}.ts")
temp = []
n += 1
# 处理能被100整除的剩下的ts文件
cmd_fileName = "+".join(temp)
os.system(f"copy /b {
cmd_fileName} {
n}.ts")
temp = []
n += 1
for i in range(n):
temp.append(f"{
i+1}.ts")
cmd_fileName = "+".join(temp)
os.system(f"copy /b {
cmd_fileName} ColdJoke2.mp4")
def merge_ts(code_ornot):
name_list = []
with open("data/ColdJoke2.txt", "r", encoding='utf-8') as f:
for line in f:
if line.startswith("#"):
continue
name_list.append(line.split("/")[-1].strip())
nowDir = os.getcwd()
if code_ornot == 1:
os.chdir("ts解码后")
else:
os.chdir("ts解码前")
merge(name_list)
os.chdir(nowDir)
print("下载完成")
def getKey():
obj = re.compile('URI="(?P<key>.*?)"')
key_url = ""
with open("data/ColdJoke2.txt", "r", encoding='utf-8') as f:
key_url = obj.search(f.read())["key"]
key_str = Get_url_content(key_url)
key = key_str.encode("utf-8") # 变成字节
return key
async def Decode_ts_one(filename, key, semaphore):
print("开始解码" + filename)
aes = AES.new(key=key, IV=b"0000000000000000", mode=AES.MODE_CBC)
async with semaphore:
async with aiofiles.open("ts解码前/" + filename, 'rb') as fRead, aiofiles.open("ts解码后/" + filename, 'wb') as fWrite:
content = await fRead.read()
content_decode = aes.decrypt(content)
await fWrite.write(content_decode)
print(filename + "解码完成")
# ts文件解码
async def Decode_ts(semaphore, key):
tasks = []
key = getKey()
with open("data/ColdJoke2.txt", "r", encoding='utf-8') as f:
for line in f:
if line.startswith("#"):
continue
else:
name = line.split("/")[-1].strip()
tasks.append(asyncio.create_task(Decode_ts_one(name, key, semaphore)))
await asyncio.wait(tasks)
def main():
semaphore = asyncio.Semaphore(200)
# 获取电影的m3u8文件
# url = 'https://www.wbdy.tv/play/44801_2_1.html'
# m3u8_url = Get_m3u8_url(url)
# m3u8_first_url = Get_first_m3u8(m3u8_url)
# Download_m3u8(m3u8_first_url)
# 下载ts
# loop = asyncio.get_event_loop()
# loop.run_until_complete(Download_all_ts(semaphore))
# loop.close()
# 解码ts
# key = getKey()
# if len(key) != 0:
# loop = asyncio.get_event_loop()
# loop.run_until_complete(Decode_ts(semaphore, key))
# loop.close()
# code_ornot = 1
# else:
# code_ornot = 0
code_ornot = 0
# 合并ts
merge_ts(code_ornot)
if __name__ == '__main__':
main()