由于大创的分工,简单熟悉了一下爬虫便开始爬取数据
本篇博客爬取的数据网址为天气后报
一、思路介绍
首先说一下爬虫的思路:
- 获取网页的url
- 获取网页的html
- 对其进行数据解析,由于博主对xpath的理解能力所限,此处既使用了靓汤又使用了xpath
- 将数据持久化存储,即存进csv文件中
再来说说本次项目的思路:
- 获取所有的城市名称与url地址并存放进一个字典类型中
- 根据对应的城市所显示的页面获取2020年1月至2020年12月的数据url地址
- 根据每个城市各个月份的url地址获取其中的表格数据
- 将数据写入csv文件中持久化存储
二、准备工作
import requests
from lxml import etree
from bs4 import BeautifulSoup
import csv
import os
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
使用requests访问网页并获取网页源码
使用etree的xpath以及BeautifulSoup对数据解析,获取想要的数据
使用csv库调用相关函数存储数据进csv文件
使用os库创建文件夹
headers为访问网页时所用的User-Agent,进行UA伪装
三、获取城市名称及url
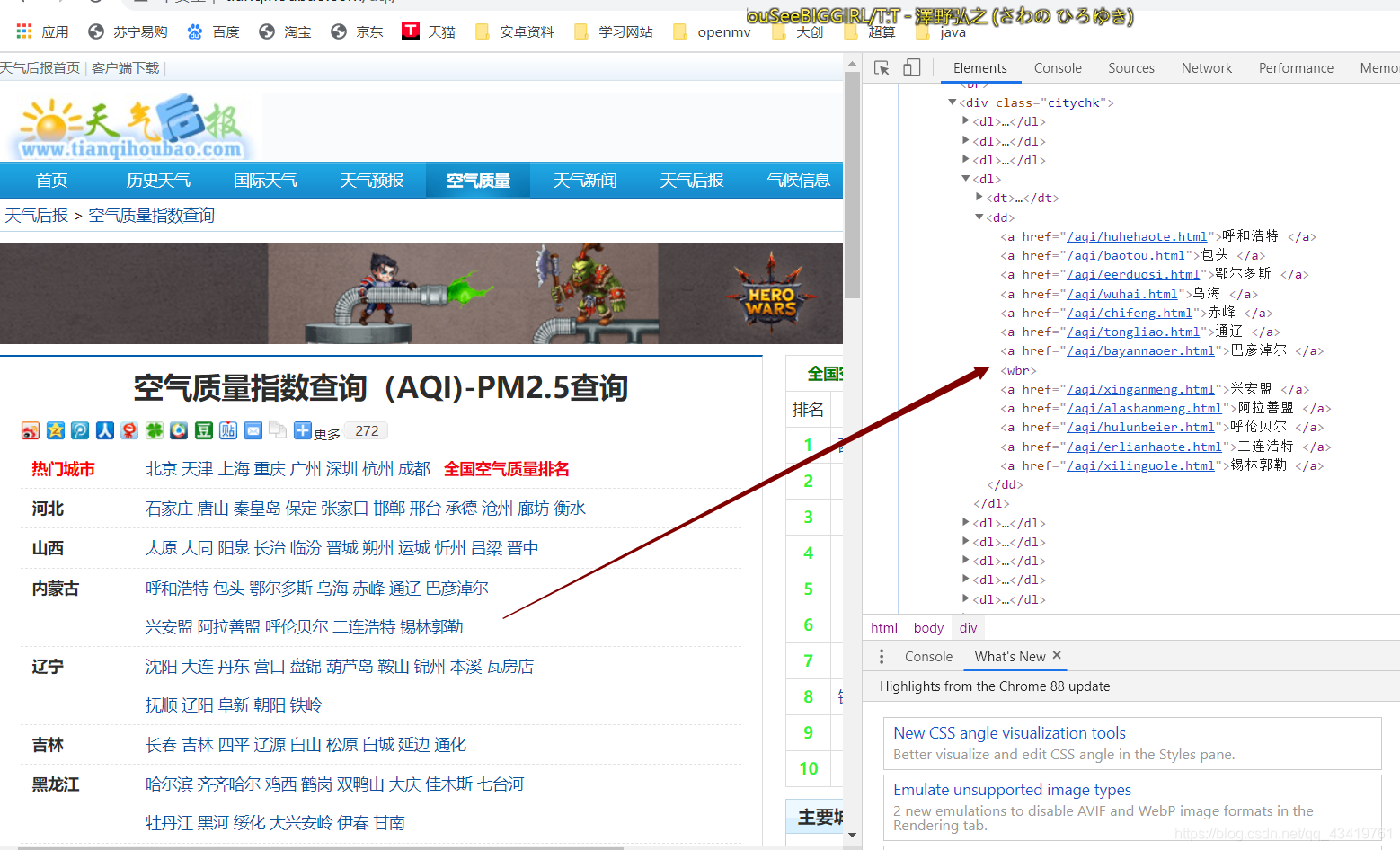
注意点1:如下图所示,在一开始使用xpath爬取的时候爬取到如内蒙古省的时候只能爬取到第一行的城市,后来细看发现城市排布超过一行的省都会包含一个<wbr>标签,阻碍了后面数据的获取,由于没想到好的办法直接使用了BeautifulSoup的find_all和select来获取所有的<a>标签中的href和文本
注意点2:如下图,百色市的连接出现了断裂,在获取后的文本为http://www.tianqihoubao.com/aqi/baise\r\n.html,多了\r\n,因此无法正确访问该城市的网页,因此可以直接在代码中加个特殊判断

注意点3:<a>标签中每个城市的文本之后都有一个空格,如上如百色市<a>中文本为
“百色 ”,此处有一个空格,若不想要该空格可以在获取文本时使用strip函数除去
代码展示如下:
############################################################
# 函数功能:获取各个城市的名字及对应的url
# 传入参数:无
# 输出参数:citys_name,字典类型,城市名称为键,对应的url为值
# 修改时间:2020/1/23
# 修改理由:暂无
############################################################
def get_city():
url = r'http://www.tianqihoubao.com/aqi/'
response = requests.get(url=url, headers=headers).text
soup = BeautifulSoup(response, 'lxml') # 用靓汤解析网页源码获取class为citychk的标签
tables = soup.find_all(class_="citychk")
citys_name = dict()
for table in tables:
citys_url = table.select("a") # 挑选出其中的a标签并抽取其中的文本以及href
for city in citys_url:
city_name = city.text.strip() # 城市名称,使用strip去除尾部的空格
city_name = city_name.encode('iso-8859-1').decode('gbk') # 对中文乱码重新编码
city_urls = city.attrs.get("href").strip() # 城市的url
if city_name == "全国空气质量排名": # 忽略网页中禹城市无关的文本
continue
# 百色需要特殊处理——html源码中的地址爬取后为http://www.tianqihoubao.com/aqi/baise\r\n.html
# 由于噪声字符不是位于字符串的头和尾,因此需要额外加个特判
if city_name == "百色":
citys_name[city_name] = "http://www.tianqihoubao.com/aqi/baise.html"
continue
citys_name[city_name] = "http://www.tianqihoubao.com" + city_urls # 添加字典,格式为:城市名称——对应url
return citys_name
四、获取各月份的url
此处使用的xpath解析数据,xpath的编写使用了逻辑或串起来,需要修改直接修改 li 的下标值即可,添加也是直接或上新的xpath值,返回的months中是各个月的url地址
代码展示如下:
############################################################
# 函数功能:根据城市的url获取历史大气数据页面的url
# 传入参数:city_url,字符串类型,表示城市的url地址
# 输出参数:months,列表类型,表示该城市一年各月份数据的url
# 修改时间:2020/1/23
# 修改理由:暂无
############################################################
def get_month(city_url):
months = list()
response = requests.get(url=city_url, headers=headers).text
tree = etree.HTML(response) # 使用etree解析网页源码,下面为xpath
month_list = tree.xpath('//div[@class="box p"]//li[2]/a/@href | //div[@class="box p"]//li[3]/a/@href'
'| //div[@class="box p"]//li[4]/a/@href | //div[@class="box p"]//li[5]/a/@href'
'| //div[@class="box p"]//li[6]/a/@href | //div[@class="box p"]//li[7]/a/@href'
'| //div[@class="box p"]//li[8]/a/@href | //div[@class="box p"]//li[9]/a/@href'
'| //div[@class="box p"]//li[10]/a/@href | //div[@class="box p"]//li[11]/a/@href'
'| //div[@class="box p"]//li[12]/a/@href | //div[@class="box p"]//li[13]/a/@href')
for month in month_list:
month = r'http://www.tianqihoubao.com' + month # 某城市每个月的url
months.append(month)
return months
五、获取各项数值
存储数据的为表格,因此直接两层循环解析即可,外层循环解析行(<tr>),内层循环解析列(<td>),将每一天的保存为列表,再将该列表保存进一个大列表用于存放一个月中每一天的数据
注意点:爬取的数据中可能会在头尾含有空格或\r\n之类的,因此直接用strip()函数去掉,保留下有效数据
代码展示如下:
############################################################
# 获取历史数据
# 输入参数:month_url, 字符串类型,对应月份的url地址
# 输出参数:data_list, 列表,元素也为列表,12个月份的数据
# 修改时间:2020/1/23
# 修改理由:暂无
############################################################
def get_record(month_url):
response = requests.get(url=month_url, headers=headers).text
tree = etree.HTML(response)
tr_list = tree.xpath('//div[@class="api_month_list"]/table//tr')
data_list = list()
for tr in tr_list[1:]: # 定位到行,除去表头
td_list = tr.xpath('./td/text()')
data = list()
for td in td_list: # 定位到具体列
data.append(td.strip()) # 使用strip函数出去原来数据头和尾的\r\n以及空格
data_list.append(data)
return data_list
六、main函数编写
获取个城市的名称以及url,再获取每个月的url,之后获取数据并保存进指定路径
代码展示如下:
def main():
if not os.path.exists(r"./AQIoneMonth"): # 创建文件夹
os.mkdir(r"./AQIoneMonth")
citys_name = get_city() # 获取城市名称及url
for city in citys_name: # city为字符串,表示城市名称
print("开始爬取%s的历史大气数据" % city)
city_url = citys_name[city]
months = get_month(city_url) # 该城市对应的12个月的连接
index = 0
for month_url in months:
index = index + 1
data_list = get_record(month_url) # 获取每个月的数据
with open('./AQIoneMonth/' + city + '.csv', 'a', newline="", encoding="utf-8") as f:
writer = csv.writer(f)
if index == 1: # 写入表头,只写入一次
writer.writerow(
["日期", '质量等级', 'AQI指数', '当天AQI排名', 'PM2.5', 'PM10', 'SO2', 'NO2', 'CO', 'O3'])
writer.writerows(data_list) # 写入数据
print("第%d个月已经爬取完成" % index)
print()
注意:爬取时间比较长,在爬取较长时间后会出现卡死,此时可以终止程序的运行,在最外层循环设置i变量,控制第二次开始时开始的城市的位置,至于i的值可以看已经爬取的文件夹中已经包含文件的个数,据此来改变i的值重新运行继续捕获,示例代码如下:
def main():
if not os.path.exists(r"./AQI"): # 创建文件夹
os.mkdir(r"./AQI")
citys_name = get_city() # 获取城市名称及url
print(citys_name)
i = 0
for city in citys_name: # city为字符串,表示城市名称
i = i + 1
if i > 168:
print("开始爬取%s的历史大气数据" % city)
city_url = citys_name[city] # 获取每个城市的url
months = get_month(city_url) # 获取该城市对应的12个月的url
index = 0
for month_url in months:
index = index + 1
data_list = get_record(month_url) # 获取每个月的数据
with open('./AQI/' + city + '.csv', 'a', newline="", encoding="utf-8") as f:
writer = csv.writer(f)
if index == 1: # 写入表头,只写入一次
writer.writerow(
["日期", '质量等级', 'AQI指数', '当天AQI排名', 'PM2.5', 'PM10', 'SO2', 'NO2', 'CO', 'O3'])
writer.writerows(data_list) # 写入数据
print("第%d个月已经爬取完成" % index)
print()
还有一个注意点是:思茅市、巢湖市、二连浩特市、莱芜市、伊犁哈萨克州没有数据,因此该网站爬取不到以上城市的数据,此外那曲市只有2020年5月以及之前的数据,之后的数据也没有,无法爬取。
七、完整代码
# -*- coding = utf-8 -*-
import requests
from lxml import etree
from bs4 import BeautifulSoup
import csv
import os
# UA伪装所使用的User-Agent
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
############################################################
# 函数功能:获取各个城市的名字及对应的url
# 传入参数:无
# 输出参数:citys_name,字典类型,城市名称为键,对应的url为值
# 修改时间:2020/1/23
# 修改理由:暂无
############################################################
def get_city():
url = r'http://www.tianqihoubao.com/aqi/'
response = requests.get(url=url, headers=headers).text
soup = BeautifulSoup(response, 'lxml') # 用靓汤解析网页源码获取class为citychk的标签
tables = soup.find_all(class_="citychk")
citys_name = dict()
for table in tables:
citys_url = table.select("a") # 挑选出其中的a标签并抽取其中的文本以及href
for city in citys_url:
city_name = city.text.strip() # 城市名称,使用strip去除尾部的空格
city_name = city_name.encode('iso-8859-1').decode('gbk') # 对中文乱码重新编码
city_urls = city.attrs.get("href").strip() # 城市的url
if city_name == "全国空气质量排名": # 忽略网页中禹城市无关的文本
continue
# 百色需要特殊处理——html源码中的地址爬取后为http://www.tianqihoubao.com/aqi/baise\r\n.html
# 由于噪声字符不是位于字符串的头和尾,因此需要额外加个特判
if city_name == "百色":
citys_name[city_name] = "http://www.tianqihoubao.com/aqi/baise.html"
continue
citys_name[city_name] = "http://www.tianqihoubao.com" + city_urls # 添加字典,格式为:城市名称——对应url
return citys_name
############################################################
# 函数功能:根据城市的url获取历史大气数据页面的url
# 传入参数:city_url,字符串类型,表示城市的url地址
# 输出参数:months,列表类型,表示该城市一年各月份数据的url
# 修改时间:2020/1/23
# 修改理由:暂无
############################################################
def get_month(city_url):
months = list()
response = requests.get(url=city_url, headers=headers).text
tree = etree.HTML(response) # 使用etree解析网页源码,下面为xpath
month_list = tree.xpath('//div[@class="box p"]//li[2]/a/@href | //div[@class="box p"]//li[3]/a/@href'
'| //div[@class="box p"]//li[4]/a/@href | //div[@class="box p"]//li[5]/a/@href'
'| //div[@class="box p"]//li[6]/a/@href | //div[@class="box p"]//li[7]/a/@href'
'| //div[@class="box p"]//li[8]/a/@href | //div[@class="box p"]//li[9]/a/@href'
'| //div[@class="box p"]//li[10]/a/@href | //div[@class="box p"]//li[11]/a/@href'
'| //div[@class="box p"]//li[12]/a/@href | //div[@class="box p"]//li[13]/a/@href')
for month in month_list:
month = r'http://www.tianqihoubao.com' + month # 某城市每个月的url
months.append(month)
return months
############################################################
# 获取历史数据
# 输入参数:month_url, 字符串类型,对应月份的url地址
# 输出参数:data_list, 列表,元素也为列表,12个月份的数据
# 修改时间:2020/1/23
# 修改理由:暂无
############################################################
def get_record(month_url):
response = requests.get(url=month_url, headers=headers).text
tree = etree.HTML(response)
tr_list = tree.xpath('//div[@class="api_month_list"]/table//tr')
data_list = list()
for tr in tr_list[1:]: # 定位到行,除去表头
td_list = tr.xpath('./td/text()')
data = list()
for td in td_list: # 定位到具体列
data.append(td.strip()) # 使用strip函数出去原来数据头和尾的\r\n以及空格
data_list.append(data)
return data_list
############################################################
# main函数
# 修改时间:2020/1/23
# 修改理由:暂无
############################################################
def main():
if not os.path.exists(r"./AQI"): # 创建文件夹
os.mkdir(r"./AQI")
citys_name = get_city() # 获取城市名称及url
for city in citys_name: # city为字符串,表示城市名称
print("开始爬取%s的历史大气数据" % city)
city_url = citys_name[city] # 获取每个城市的url
months = get_month(city_url) # 获取该城市对应的12个月的url
index = 0
for month_url in months:
index = index + 1
data_list = get_record(month_url) # 获取每个月的数据
with open('./AQI/' + city + '.csv', 'a', newline="", encoding="utf-8") as f:
writer = csv.writer(f)
if index == 1: # 写入表头,只写入一次
writer.writerow(
["日期", '质量等级', 'AQI指数', '当天AQI排名', 'PM2.5', 'PM10', 'SO2', 'NO2', 'CO', 'O3'])
writer.writerows(data_list) # 写入数据
print("第%d个月已经爬取完成" % index)
print()
if __name__ == '__main__':
main()