应用场景
Pig并不适合所有的数据处理任务,和MapReduce一样,它是为数据批处理而设计的,如果想执行的查询只涉及一个大型数据集的一小部分数据,Pig的实现不会很好,因为它要扫描整个数据集或其中很大一部分。
随着新版本发布,Pig的表现和原生MapRedece程序差距越来越小,因为Pig的开发团队使用了复杂、精巧的算法来实现Pig的关系操作。除非你愿意花大量时间来优化Java MapReduce程序,否则使用Pig Latin来编写查询的确能帮你节约时间。
操作步骤
1 Pig介绍
Pig是yahoo捐献给apache的一个项目,使用SQL-like语言,是在MapReduce上构建的一种高级查询语言,把一些运算编译进MapReduce模型的Map和Reduce中。Pig 有两种运行模式:Local 模式和 MapReduce 模式。
- 本地模式:Pig运行于本地模式,只涉及到单独的一台计算机
- MapReduce模式:Pig运行于MapReduce模式,需要能访问一个Hadoop集群,并且需要装上HDFS
Pig的调用方式:
- Grunt shell方式:通过交互的方式,输入命令执行任务;
- Pig script方式:通过script脚本的方式来运行任务;
- 嵌入式方式:嵌入java源代码中,通过java调用来运行任务。
2 Pig使用
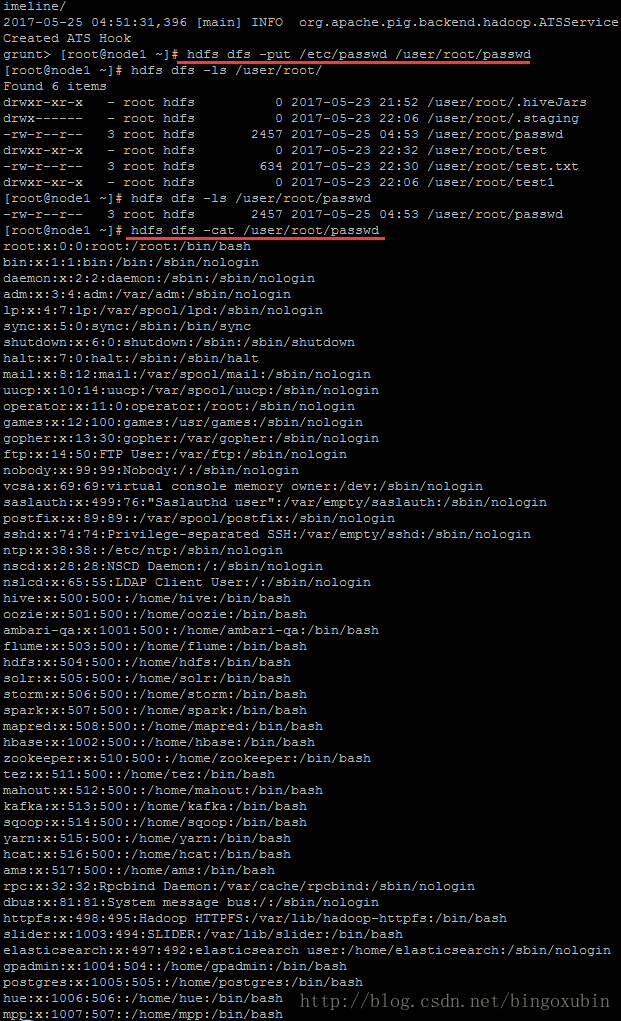
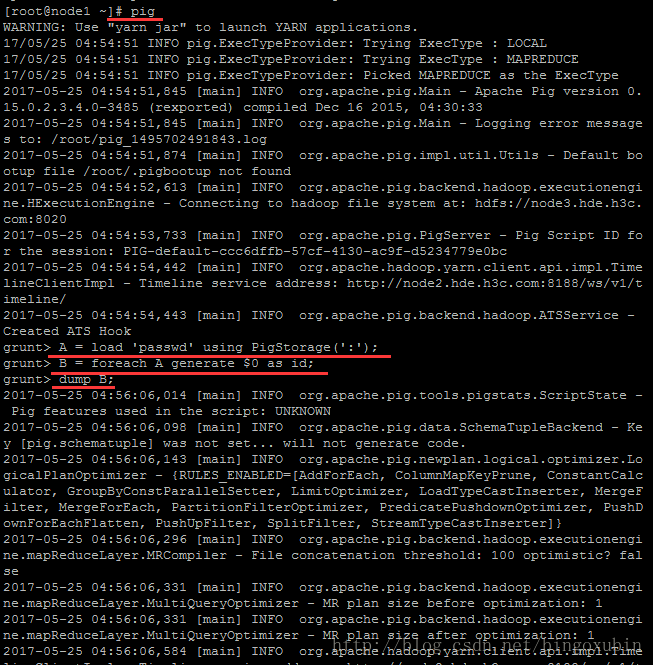
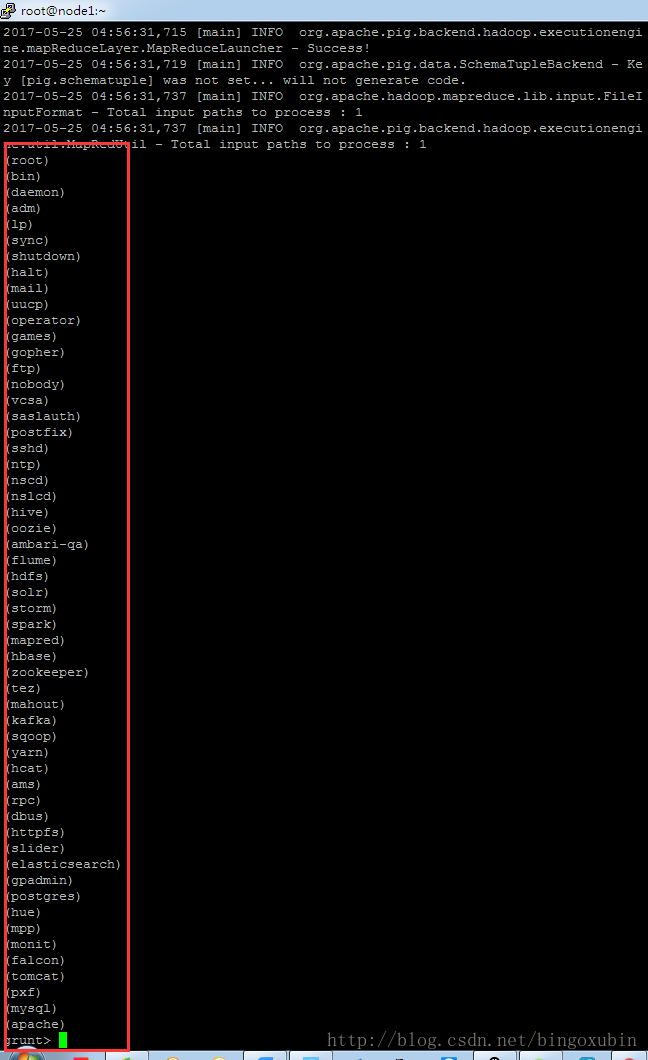
把/etc/passwd文件中的第一列取出来。
Pig的知识相对来说比较少,安装容易,使用方便,需要多学的就是pig latin这个脚本语言的熟练,更多的各种语法,会查会用即可。Pig一般很少用,项目中用不到。