源自:航空兵器
作者:高一博 杨传栋 陈栋 凌冲
摘 要
针对基于深度学习目标识别算法具有网络结构复杂、参数量大、计算延迟高等特点,难以直接应用于弹载任务的问题,对网络轻量化方法进行了归纳总结。介绍了已有的压缩方法和轻量化网络的优点及各自特点,并选择各个方面优秀的算法进行比较。最后,结合深度学习在目标检测领域中的发展,对轻量化弹载图像目标识别算法进行了展望。
关键词
网络模型压缩; 轻量化网络; 弹载图像; 深度学习模型; 算法移植
引言
精确制导武器是现代战争制胜的关键因素, 精确制导武器的核心部件是导引头[1]。制导过程中, 导引头行使着观测目标、 感知环境、 进行识别与跟踪的职责, 直到完成对目标的精确打击。然而导引头制导的效果取决于对目标位置判断的精度, 半主动制导的激光制导需要前哨站进行对目标的激光指引, 隐蔽性极差; 被动制导的雷达制导, 极易被空间各种信号干扰以及被敌人捕捉。图像制导使用CMOS(Complementary Metal Oxide Semiconductor)采集目标可见光信息, 抗电磁干扰能力强, 且不需架设前哨站[2]。与普通的移动终端所使用专用芯片ASIC(Application Specific Integrated Circuit)不同, 导引头中的弹载计算机核心处理单元架构主要包括DSP(Digital Signal Processing), DSP+FPGA(Field Programmable Gate Array), SoC(System on Chip)等。DSP资源较少, 无法满足目前的算法需求, 如今主流方式是使用DSP+FPGA的方式。FPGA具有接口丰富、 灵活性高的特点, 然而其具有高功耗性, 对于本就高消耗的深度学习算法是较难承受的。对此, 各大厂商提出SoC, 从而提高系统性能, 降低系统成本、 功耗以及重量和尺寸, 但开发周期较长, 研制费用较高, 不适用于需要快速应用的小型武器系统。嵌入SoC的芯片, 既有PL端的资源灵活性, 又有PS端的强大处理器功能, 适合深度学习算法的部署, 但其中参数量和网络结构的巨大是难以实用的难点之一。模型压缩与轻量化是设计的关键步骤, 既需要满足软件层面算法足够的精度, 又应保证移植硬件时参数量少、 速度快。内部空间小、 弹丸作用时间短、 嵌入式硬件平台处理速度要求高是限制在弹载平台上部署深度学习算法的关键因素[3]。因此, 很有必要研究压缩深度学习的算法。
1 面向弹载目标的跟踪算法
1.1 弹载目标特性
图像制导弹的成像特点包括以下几方面:
(1) 尺度变化大。弹体在空中飞行速度非常快, 平均速度可达200~300 m/s, 目标图像在视场内的尺度变化非常大, 如图1所示。当弹目距离较远时, 目标在视场中成像较小, 细节不清晰; 当弹目距离较近时, 目标在视场内的成像较大, 细节不断出现。因此, 弹载图像跟踪算法需要有尺度不变性。

(2) 目标旋转。由于弹体外形和气动特性影响, 图像制导弹在飞行时伴有连续旋转。虽然摄像机获取的图像经过了消旋处理, 但是由于弹体舵机控制和消旋精度的影响, 弹体仍会出现一定程度的旋转, 导致视场中目标图像的位置不断发生变化, 如图2所示。弹体的连续旋转导致目标图像连续旋转, 可以看出在不同时刻目标所在位置不同。因此, 弹载图像跟踪算法需要具有旋转不变性。

(3) 目标进出视场(目标进入或离开视场范围)。图像制导弹在高速飞行过程中伴随一定程度的章动, 导致目标频繁进出视场。当目标出视场后, 由于前后两帧中必定有相同的场景, 根据深度学习中前景与背景特征提取方法, 可以利用深度学习中掩膜激活, 或者特征关联方式预测下一帧目标出现的范围; 而对于半出视场或者部分出视场的目标, 基于深度学习的方法可以轻松进行识别跟踪。
1.2 各种跟踪算法对比
结合上述弹载目标独有的特征, 寻找跟踪算法, 各种算法的对比如表1所示。

由表1可以看出, 背景减除法只适合固定背景下目标的识别, 且易受环境光线的影响, 不适用于亮度不断变换的弹载图像。帧间差分法通过帧间图像的差别来区分目标区域, 但是由于弹体高速运动, 弹载图像间的帧间差别太大, 很难识别出有效的目标区域。光流法抗噪声能力差, 简单模板匹配法实时性差, 且此方法鲁棒性较差, 缺少模板更新, 而弹载图像的尺度处于不断变化当中, 准确度较低。SFIT算法对旋转、 尺度放缩、 亮度变化保持较高水平, 对视角变化、 仿射变化、 噪声的稳定性较差, 且不够实时。基于深度学习的算法由于各种目标都是训练出来的, 训练好的网络, 准确度高, 对尺度不变性和旋转不变性, 甚至遮挡出视场都有极强的适应能力。由于深度学习训练网络非常多, 故速度和准确度相互有所取舍, 其通病就是网络结构过大, 参数量多, 计算量大, 对弹载平台有着巨大的负荷。因此, 需要寻找各种压缩深度学习网络的方式使之符合弹载平台的承受力。
2 模型压缩方法
本节重点介绍当前主流的压缩方法和轻量化网络设计, 具体技术如表2所示。

2.1 参数量化与共享
大多数操作系统和编程语言默认为32位浮点数组成的单精度数, 对内存占用量较大, 尤其在深度学习网络模型中, 大量的权值、 激活值均需要占4 bit的内存。而在弹载环境中, 允许保证近似效果的情况下减少参数量。常用量化、 哈希、 改变计算形式等技术降低参数量, 减少冗余。
2.1.1 量化参数
量化网络过程常见的有1-bit二值网络, 2-bit 三值网络, 以及将32位浮点数降低为16位浮点数或16位、 8位的定点数。
Mohammad等[4]在二进制权重网络中, 将滤波器近似为二进制值, 结果可节省32×的内存。Guo等[5]提出一种基于二进制权值网络结构和深度优先搜索算法相结合的多类别图像分割模型, 将其应用于人脸识别领域, 取得较好效果。用二进制权重网络的Alex网络版本与完全准确的AlexNet版本一样准确。
Li等[6]引入了三元权值网络TWNs神经网络, 权值限制为+1, 0和-1。全精度权重利用欧氏距离最小原则转换为三值权值。另外, 对基于阈值的三元函数进行了优化, 获得一种快速、 简便的近似解, 并通过实验证明, 该算法在保持较高预测性能和压缩效率的情况下提高了图像质量; TWNs比最近提出的二进制精度对应物等网络更具有表达能力和有效性。同时, TWNs可实现16×或32×的模型压缩率, 且在较高维度下也具有良好的压缩效果。因此, TWNs是一个非常有潜力的基于深度学习的图像分类方法。来自MNIST, CIFAR-10和大型Image Net数据集的标准显示, TWNs只比全精度略低, 但比类似的二进制精度要好得多。
Krishnamoorthi[7]提出一种采用非线性量化的方法, 将权值和输入值都量化为unit8类型, 而激活函数中偏置量化为unit32位。该方法统计了每一层权值的范围分布, 非线性地对应每个量化后的权值, 同时还提供了一个权值量化训练网络, 以确保端到端的精度。
2.1.2 权值替代
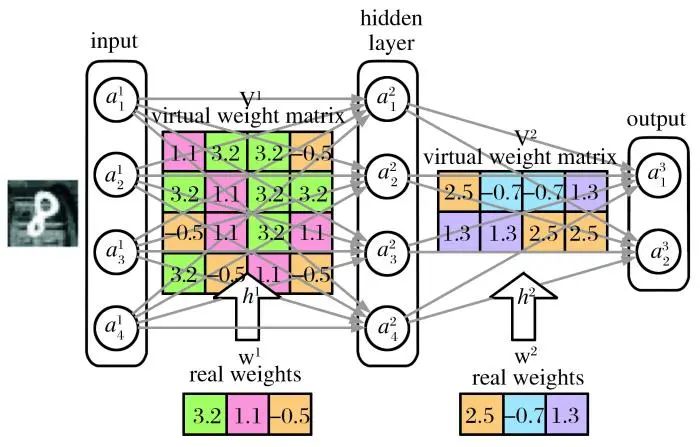
Han等[8]使用k-means聚类算法将权重分类, 并不断微调权值, 减少精度损失。根据调整后的权值进行分类, 得到各个中心, 然后使用所得的中心值替代该类其他值, 最后使用霍夫曼编码再次压缩。Chen [9]利用哈希函数, 建立HashNet, 其建议在训练前对网络权重进行量化和分组, 并在每个组内分享权重。HashNet的结构如图3所示。在这种方法下, 储存值就是哈希索引以及少量的权值, 减少了大量存储消耗。由于采用了一种新的算法来处理数据集的相似性度量问题, 也减少了对查询结果进行匹配所需的计算量。实验结果表明, 该系统能够取得很好的效果, 但是该技术无法节省运行时的内存和推理时间, 因为需要哈希映射找回共享的权值。
2.1.3 降低计算复杂度
与廉价的加法运算相比, 乘法运算的计算复杂度要高得多。而深度神经网络中广泛使用的卷积恰好是互相关的, 方便测量输入特征和卷积滤波器之间的相似性, 但是这涉及浮点值之间的大量乘法。Chen等[10]提出加法器网络(AdderNets), 来替换深度神经网络中的这些大规模乘法, 特别是卷积神经网络CNN(Convolutional Neural Network), 以获得更少的计算复杂度, 降低计算成本。AdderNets采用滤波器和输入特征之间的L1范数距离作为输出响应, 并提出一种自适应学习速率策略, 根据每个神经元梯度的幅度来增强AdderNets的训练过程。AdderNets可以在ImageNet数据集上使用ResNet-50实现74.9%Top-1精度和91.7%Top-5精度, 而不会在卷积层中进行任何乘法。
2.2 参数剪枝
弹载图像数据量多而复杂, 对于目标识别和分类网络是巨大的考验, 故需要强大鲁棒的网络, 而嵌入式网络部署工程要求网络更加轻量, 剪枝可以将原本鲁棒的网络减去大量连接和计算, 并维持相当的精度。剪枝模式如图4所示。
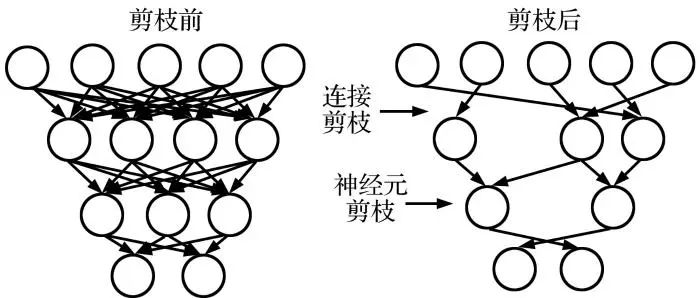
剪枝可分为非结构化剪枝和结构化剪枝。非结构化剪枝是细粒度剪枝, 即可以去除任意“冗余”的单独神经元权值, 以获得高压缩率, 实质是稀疏化卷积核矩阵。剪枝粒度示意图如图5所示。但裁剪后的网络结构混乱, 难以进行进一步操作, 例如移位代替卷积、 加法代替乘法等。结构化剪枝的最小单位是滤波器内的一组参数, 通过为滤波器或特征图设置评价因子, 甚至通过删除整个滤波器或某些通道, 网络“缩小”, 允许直接对现有的软件/硬件进行有效加速。但如果没有一个合适的优化算法, 则不能保证得到最优解。

2.2.1 非结构化剪枝
早期的一些方法基本都是基于非结构化的, 非结构化剪枝都是细粒度的。以LeCun等[11]提出的最优脑损伤(Optimal Brain Damage)和Hassibi等[12]提出的最优脑手术(Optimal Brain Surgeon)方法为代表, 该类方法基于损失函数的海森矩阵判断连接重要程度, 减少连接的数量。Neubeck等[13]提出逐层导数修建算法, 对每一层的参数计算损失, 找到损失最大的参数对其二阶导数进行独立剪枝, 修剪后经过再训练以恢复性能。
非结构剪枝常用正则化项作为损失函数的一种惩罚项, 用来限制某些参数, 因此, 利用正则化权重评价非必须参数并裁剪以达到压缩效果。但由于参数的L0范数不可微分, 难以参与优化, Louizos等[14]将权重值变为非负数, 并设置特定参数权值为0以变为可微问题。Tartaglione等[15]量化权重参数对输出的影响力, 并设计正则化项, 降低或减少影响力小的权重值。Li等[16]减去L1正则化影响小的卷积核。He等[17]使用L2正则化标准一边训练一边剪枝(即软剪枝)。
Lin等[18]定义BN(Batch Normalize)层系数和滤波器F-范数的乘积作为影响因子, 评价各个连接的重要性。Luo 等[19]提出一种基于熵的方法来评价滤波器的重要性。Chen等[20]引入硬件约束(例如延迟)后, 删除范数值低的权重并调整参数, 使任务精度最大化。Yang等[21]将能耗作为优化约束条件, 对卷积神经网络的能耗大小进行排序, 裁掉大能耗的滤波器。该方法与传统的卷积网络相比大大降低了能耗, 精度损失也在可接受范围内。He等[22]以给定的最大硬件资源数量作为约束的模型自动裁剪。
2.2.2 结构化剪枝
结构化剪枝的对象由单个神经变成了向量级、 通道级乃至整个滤波器级连接。结果表明, 结构化剪枝与非结构化剪枝具有相似的稀疏率, 且不损失准确性; 在相同的精度下, 结构化剪枝由于索引存储的原因可以获得比非结构化剪枝更好的压缩率; 更常规的稀疏性使得细化网络更适合于较快的硬件部署。因此, 结构化剪枝具有优势。
结构化剪枝又可进一步细分为通道级或滤波器级。通道裁剪是在网络中直接删除某层的一个或多个通道, 缺点是精度损失较大; 优点是不生成稀疏矩阵, 可以直接进行计算, 而且大大节省空间和时间。He等[23]提出将通道中所有权值的绝对值和列为通道的重要性指标, 然后剪枝不重要的通道, 缺点是需要花时间重训练。Molchanov等[24]直接考虑特征图有无对损失函数的影响, 并使用一阶泰勒展开近似删除不重要通道。滤波器级别剪枝是直接对整个三维滤波器进行裁剪, 能够保持网络的结构特性, 相当于变窄的原网络结构。
需要指出, 对于结构化剪枝, 经过往复训练得到的精度并不如将目标网络从头开始训练的精度高, 因此, 剪枝的目标网络的结构设计其实最为重要, 需要合理设计和选择。
2.3 知识蒸馏
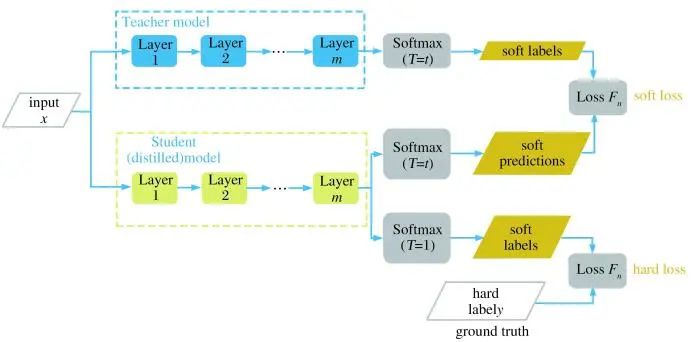
知识蒸馏是将“知识”从复杂模型传递给一个结构更简单、 运行速度更快的网络模型。Hinton等[25]首次提出知识蒸馏的概念, 将教师网络中学到的各个类别之间的关系作为学生网络学习的目标, 实现“知识”传递的过程, 如图6所示。该方法中, 总的loss函数是由两部分构成的, 一部分是由现实与学生网络自测的loss, 该部分为hard_loss; 另一部分为教师网络与学生网络升高同样的“温度”, 两者之间的loss, 该部分为soft_loss。总loss为两者之和。这样既能找到学生网络与现实的差距, 又可以学到教师网络中各类别之间联系。该方法适用于小型或者中型数据集上, 由于压缩后的学生模型学到了已有知识, 故在数据集不大时, 使用学生模型也能取得鲁棒的性能。
2.3.1 改进学生网络
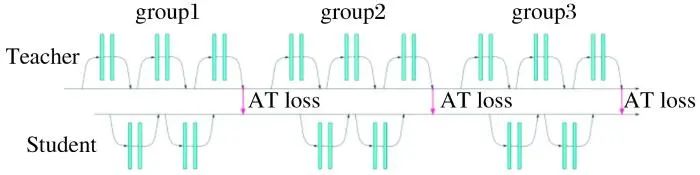
Sergey等[26]通过区域注意力机制找寻教师网络中注意力高的区域, 迫使学生网络模拟一个强大的教师网络的感兴趣的区域来显著提高其表现。Li等[27]提出转移注意力的新方法, 将教师网络的“知识”相关性和学生网络感兴趣的事务传给下次学习的学生网络, 如图7所示。其中, AT loss(Attention Loss)是将教师网络通过注意力机制学到的知识通过该loss传给学生网络。AT loss与该group中的teacher和student网络均相关, 故上个group的学生网络能影响下个教师网络传递知识的过程, 即影响AT loss, 是教学相长的过程。
Tian等[28]利用对比学习, 提出一个替代目标, 通过该目标, 训练学生在教师对数据的表示中捕获更多信息。Heo等[29]激活隐藏神经元使得学生网络和教师网络分类的区域边界最相近, 以提高学生网络分类精细度。
2.3.2 改进教师网络
教师网络的信息传递也是一大改进的方向。Xu[30]等提出一个新型自监督知识蒸馏模型, 利用自监督从教师网络中挖掘出更多的隐含信息。You等[31]提出通过平均多个教师网络的软化输入, 即“知识”, 并施加关于示例之间的差异性约束, 在中间层中再施加于学生网络。Ahn等[32]将针对相同或者类似的任务预先训练的教师网络转移到学生网络。
2.4 轻量化网络
在弹载嵌入式环境中对轻量化网络的需求很大, 然而对弹载环境中轻量化网络的应用较少。近年来, 宋泰年等[33]面向弹载环境开发了一种将空间、 通道注意力机制与MobileNetV2结合的模块, 说明轻量化网络有应用于弹载环境的巨大潜力。以下从不同结构级别设计综述轻量化网络的发展。
2.4.1 卷积核设计
Zhang等 [34] 在ShuffleNet V1中使用分组卷积大大降低了参数量分组卷积参数, 并提出通道混洗(Channel Shuffle)的方式, 使得各个组间、 通道之间相互交流, 避免近亲繁殖。Ma等[35]提出ShuffleNet V2, 并提出四个轻量化网络设计准则: (1)输入输出通道数相同时, 内存访问量MAC最小; (2)分组数过大的分组卷积会增加MAC; (3)碎片化操作对并行加速不友好; (4)逐元素操作(Element-wise)带来的内存和耗时不可忽略。Xception[36]是inception的最终版, 由GoogLeNet[37](inception V1)演变而来。GoogLeNet将卷积层并行拆分成不同的大小, 如3×3, 5×5, 7×7, 加上一个全连接层, 再加上1×1卷积的降维, 可以在不增加太多参数的条件下大大提高分类的细粒度。随后, inception V2和inception V3分别设计了depth-wise和point-wise, 将5×5和7×7分离为3×3卷积核, 并在不同条件下选择了1×3和3×1卷积核, 大大减少了参数量。该方法得到的结果是很好的, 且具有一定的可扩展性。Xception只包含了1×1和3×3个模块, 共享1×1个模块, 且每个3×3卷积只划分为第一层的一部分, 以区分不同卷积, 是深度可分类卷积。
2.4.2 层级别设计
Huang等[38]建议对ResNet等具有残差连接的网络进行随机深度训练, 随机删除block子集并使用残差连接绕过其每次训练。Dong等[39]为每个卷积层配备了轻量化的协同层LCCL(Low-Cost Collaborative Layer), 该协同层可以预测经过激活层后0的个数与来源, 并且删除了测试时的消耗。Li等[40]将网络层分为权重层和非权重层, 计算权重层参数, 忽略非权重层参数的计算。Prabhu等[41]设计了一种滤波器之间的稀疏连接。Wu等[42]用平移特征图、 特征向量取代卷积, 减少了计算量。Chen 等[43]使用稀疏移位层(SSL)代替原有卷积层构建网络。在此体系结构中, 基本块仅由1×1卷积层组成, 用来升维和降维, 并在中间特征图设计稀疏的移位操作。
2.4.3 网络结构级别设计
Kim等[44]提出SplitNet, 其自动学会将网络的各个层分为多个组, 从而形成根节点, 每个子节点共享根节点权值。Gordon等[45]提出通过裁剪和扩张来循环优化网络的方法: 在裁剪阶段, 使用正则化损失判断权值, 去除影响小的权值; 在扩展阶段, 利用旁边节点扩展同倍的所有层的大小, 因此, 重要节点越多的层最终越宽, 对应资源越多。但这些方法都存在一定问题: 需要大量计算时间; 对节点进行遍历操作导致局部最优解无法搜索到全局最好结果。Kim等[46]提出嵌套稀疏网络, 每层由多层次网络组成, 其中, 高层次网络和低层次网络以网络的形式共享参数: 低层次网络感受野小, 学习知识粗略, 仅学习表面特征; 高层次网络感受野大, 可以看到内部关联, 用来学习精细知识。
2.4.4 神经网络架构搜索
EfficientDet[47]的高性能主要得益于两个方面: 强大的特征提取器和BiFPN。其中对BiFPN的研究与轻量化无关, 而特征提取器EfficientNet[48]使用一种全新的网络设计模式, 即网络结构搜索NAS(Neural Architecture Search)[49]。NAS是一种搜索网络框架的网络设计模式, 在图像识别、 图像分类等领域中得到广泛应用, 并取得一些有意义的成果。
NAS的设计思路为: 在特定的搜索空间利用高效搜索策略进行与实际应用相关性更大的神经网络搜索。很多轻量网络都使用了NAS架构搜索, 如 NASNet[50]和MobileNetv3[51]。而EfficientNet的搜索空间主要有常见的skip网络、 卷积网络、 池化网络、 全连接网络及轻量网络中常用的深度卷积, 评价策略为输入尺度、 网络深度、 网络宽度, 搜索出了一套轻量级、 高性能的卷积网络。
2016年, MIT提出MetaQNN[52]用强化学习的方式, 学习每一个CNN层的类型、 参数, 生成网络结构, 并形成损失函数, 用来参与强化训练。MetaQNN使用马尔可夫决策过程搜索网络架构, 利用RL(Ruturn Loss)方法生成CNN架构。Zoph[53]采用RNN(Recurrent Neural Network)网络作为控制器, 对网络结构的语义进行采样和生成, 然后利用REINFORCE算法理解网络结构(早期的RL方法), 从而达到较高的准确度。通过采用800GPU, 最终在CIFAR-10数据集中以类似的网络架构击败了人工设计模型, 并发现了比LSTM(Long-Short-Time Memory)更好的结构。
Real等[54]首先将基于进化算法(Evolutionary Algorithm)的思想融入到NAS问题, 利用CIFAR-10数据集证明了算法的高精度。首先, 将网络结构当作DNA(Deoxyribo Nucleic Acid)并进行编码。在不断变异进化的过程中, 网络模型会不断增加, 每次进化后判断其精度, 淘汰其中差的。将另一个模型作为父节点, 子节点是由变异形成的(即在某些预先确定的网络结构变更操作中的随机选择)。对子节点进行训练和验证, 以便将其放置在集合中。文献[55]中, 去除种群中年龄最大的节点, 使进化向更年轻方向发展, 这有助于更好地探索。以此找出的最优网络结构称为AmoebaNet。此外, 通过对三个算法的比较, 发现强化学习算法和进化算法更准确。进化算法搜索速度快于强化学习(特别是在早期), 并产生较小的模型。
基于梯度的搜索算法有卡内基梅隆大学(Carnegie Mellon University, CMU)和Google的研究人员提出的DARTS(Differentiable Architecture Search)方法[56], 该方法寻求最优结构的单元是包含N个有序结点的有向无环图。文中利用隐马尔科夫模型对局部区域进行描述, 并把这种描述应用于求解多分类问题。结点表示隐式表征(如特征图), 运算符表示运算符的向边联接。在DARTS方法中, 关键的技巧是使用softmax函数混合候选, 通过计算每个子区域内所有操作与该区域中心之间的距离来决定结点是否需要添加或删除。对于每一种新出现的子域, 反馈时也应该更新其值以使之保持不变, 形成可微函数。通过这种方法, 可以利用基于梯度搜索的方法找到最优结构。最后, 选取权重最高的参数形成网络。此外, 文献[57]中还提出另一种搜索效率更高的方法。该方法是将网络结构嵌入到搜索空间中, 使用点表示各个区域网路, 可以在这个空间中定义精度的预测值。通过基于梯度搜索的方法, 找到一种合适的嵌入式网络结构表示方法, 优化后, 将此表示嵌入到网络结构中。
3 压缩效果比较
为了测试各种算法对弹载图像的指导意义, 使用Xilinx的四核arm cortex-A53的zynq Ultrascale+ MPSOC ZCU104进行测试。Xilinx官方有成熟的深度学习算法IP, 例如LeNet, AlexNet, ResNet等, 对于参数量化共享、 参数剪枝、 知识蒸馏等网络有着方便的植入。使用常见数据集ImageNet[58]和自制的舰船目标数据集, 对AlexNet和ResNet进行参数量减少和准确度变化的测试。定义Δaccuracy=压缩后Top-1准确率-压缩前Top-1准确率, #Param为压缩后参数量/压缩前参数量, #FLOPs为压缩后浮点计算量/压缩前浮点计算量。知识蒸馏压缩前代表teacher网络, 压缩后代表student网络。不同压缩方法在AlexNet on ImageNet上的压缩效果如表3所示。

由表3可以看出, 这四类压缩方法的结果差别是十分巨大的。权值量化[4]的参数量化有着很大的优势, 对参数量和计算量的压缩都十分可观, 且精度下降在可接受的范围内。而观察并非顶级轻量化网络SplitNet[44]的结果可知, 轻量化网络也具有很强的压缩能力, 但缺点是各种轻量化网络层出不穷, 想将其部署到弹载平台上有着较长的周期; 另一方面, 可以将更多更优的网络部署于平台, 达到更优更快的结果, 这也是轻量化网络的潜力所在。参数剪枝与知识蒸馏并没有过于惊人的表现, 但优势是可以与其他方法结合使用, 构成更优的性能。
对于炮弹来说, 装甲类目标更加真实。为了对比压缩效果, 自制一个装甲目标数据集。该数据集利用无人机航拍500张各种装甲类目标图片, 拍摄高度为2 500~3 000 m, 是末制导炮弹图像制导阶段的高度。拍摄倾角为30°~40°, 是炮弹末端制导的俯仰角度。通过对每张图片进行随机1.1~1.5的亮度增强, 加上每张图片的间隔90°的旋转及每张图片的反转, 将数据集扩大到3 000张目标图像, 其中包括2 400张训练集、 200张验证集、 400张测试集, 分辨率均为500×500, 包括自行火炮、 坦克、 远程火箭炮三个种类。原本500张图片中, 自行火炮占180张, 坦克占180张, 远程火箭炮占140张。使用AlexNet对装甲目标数据集进行压缩效果测试, 结果如表4所示。

现在的各种嵌入式语言有着例如int8和int16的参数定义, 使得研究者在部署过程中直接使用量化后的参数进行运算, 表4中的结果也反映出参数量化的优越性。而轻量化网络仍然有着超强的压缩能力以及较高的准确度。从剪枝的随机性推测剪枝降低了网络损失的过拟合, 根据学生网络的指向性, 推测知识蒸馏的专项能力有所提升, 所以参数剪枝与知识蒸馏对准确率均有提升。
从上述测试可看出轻量化网络的巨大潜力, 但由于不同轻量化网络结构差距较大且指向性不同, 难以部署。在GPU为NVIDIA RTX 3080显卡、 CPU为AMD 5000的计算机上对各个算法在ImageNet上进行测试, 为下一步将各种轻量化网络部署到弹载平台上提供一定的指向。Top-1精度与FLOPs(Floating Point Operations)的关系以及使用参数量大小如图8所示。

由图8可以看出, ResNeXt-101精度高, 然而消耗的计算量巨大, 参数量将近64M, 若想部署则必须进行压缩; 而AmoebaNet有着更高的准确度, 以及小的计算量和参数量, 此性能十分适合部署, 但由于这是在GPU空间上搜索出的算法, 对于FPGA等弹载平台是否适配还需进一步验证; ResNeXt-50网络不仅是手工设计网络, 而且准确率很高, 计算量也适中, 适合压缩后部署进行工作。
选取ResNeXt-50作为主干网络, 使用Yolo V3的特征提取网络CSPNet作为检测头, 训练100次进行一次验证, 针对弹载目标特性训练得到跟踪结果。 图9为每隔5帧抽取的视频结果。

参数量已经大大减少的ResNeXt-50的主干网络经过训练, 可以解决图片旋转、 尺度变化和目标进出视场等问题。
综上所述, 各种深度学习网络的潜力巨大, 选择合适的压缩方法, 可以保证较高的准确性及合适的参数计算量, 满足弹上硬件需求。
4 展望
对于将识别算法移植嵌入式平台, 压缩网络应该从各个方面进行评估和分析, 结合本文综述的各类算法特点的研究以及弹载平台对于算法的特殊要求, 对识别算法在弹载平台的实现方式作如下展望:
-
(1) 优化模块提升轻量化网络性能。现阶段的很多轻量化网络中都是优化模块提升轻量化网络算力, 例如Xception最终的inception模块, 加入该模块可以提高速度以及减少参数。而NAS又为寻找这种模块提供了新的可能, 根据弹载嵌入式环境设计的NAS搜寻网络, 更易发现合适轻量化模块以插入到目标算法中, 为算法在弹载平台的实现提供了新思路。
-
(2) 合理利用DSP和Mac(Multiplying Accumulator)模块。在芯片或边缘计算设备有更多的DSP模块和Mac模块, 卷积模块可以改进乘加模块, 以便更充分、 有效地利用弹上资源。例如FPGA有大量的并行Mac模块, 将算法改进后部署到设备上, 不但可以在弹上大放光彩, 在普通的智能移动终端上也会有更快的速度以及更高的性能。
-
(3) 采用直接压缩方式。例如常用的剪枝、 知识蒸馏一类压缩现有模型的算法, 均可以用作改进现有模型, 可以在损失精度较小甚至不损失精度的情况下成功实现网络的轻量化, 与其他方法结合使用, 可以在弹载平台保证其鲁棒性。
声明:公众号转载的文章及图片出于非商业性的教育和科研目的供大家参考和探讨,并不意味着支持其观点或证实其内容的真实性。版权归原作者所有,如转载稿涉及版权等问题,请立即联系我们删除。