点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:机器之心
来自华南理工大学、新加坡国立大学、香港理工大学以及琶洲实验室的研究者们联合提出一种有趣的手写文字生成方法,仅需提供少量的参考样本即可临摹用户的书写风格,进而生成符合该风格的任意文字。
笔迹模仿 AI 的研究背景
俗话说,见字如面,字如其人。相比呆板的打印字体,手写体更能体现书写者的个人特点。相信很多人都曾设想过,拥有一套属于自己的手写字体,用在社交软件中,更好的展示自己的个人风格。
然而,不同于英文字母,汉字数量是极其庞大的,想要创造一套自己的专属字体代价十分高昂。例如,最新发布的国标GB18030-2022中文字符集包含8万多个汉字。有报道称,某视频网站博主花了18个小时写完了7000多个汉字,中间耗费了足足13支笔,手都写麻了!
上述问题引发了论文作者的思考,能否设计一个文字自动生成模型,帮助解决专属字体创造代价高的问题呢?为了解决这一问题,研究者设想提出一个会笔迹模仿的 AI,仅需用户提供少量的手写样本(大约 10 几张),就能提取笔迹中蕴含的书写风格(例如字符的大小、倾斜程度、横宽比、笔画的长短和曲率等),并且临摹该风格去合成更多的文字,从而为用户高效合成一套完整的手写字体。

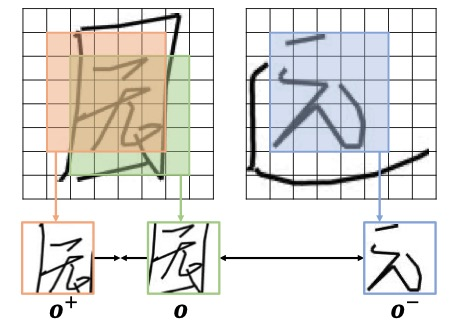
进一步地,论文作者从应用价值和用户体验两个角度出发,对该模型的输入和输出模态做了如下思考:1. 考虑到序列模态的在线字体 (online handwritings) 比图像模态的离线文字 (offline handwritings) 包含更丰富的信息(轨迹点的详细位置和书写顺序,如下图所示),将模型的输出模态设置为在线文字会有更广泛的应用前景,例如可以应用到机器人写字和书法教育上。2. 在日常生活中,相比通过平板和触摸笔等采集设备获取在线文字,人们利用手机拍照获取离线文字更加方便。因此,将生成模型的输入模态设为离线文字,用户使用起来会更加方便!
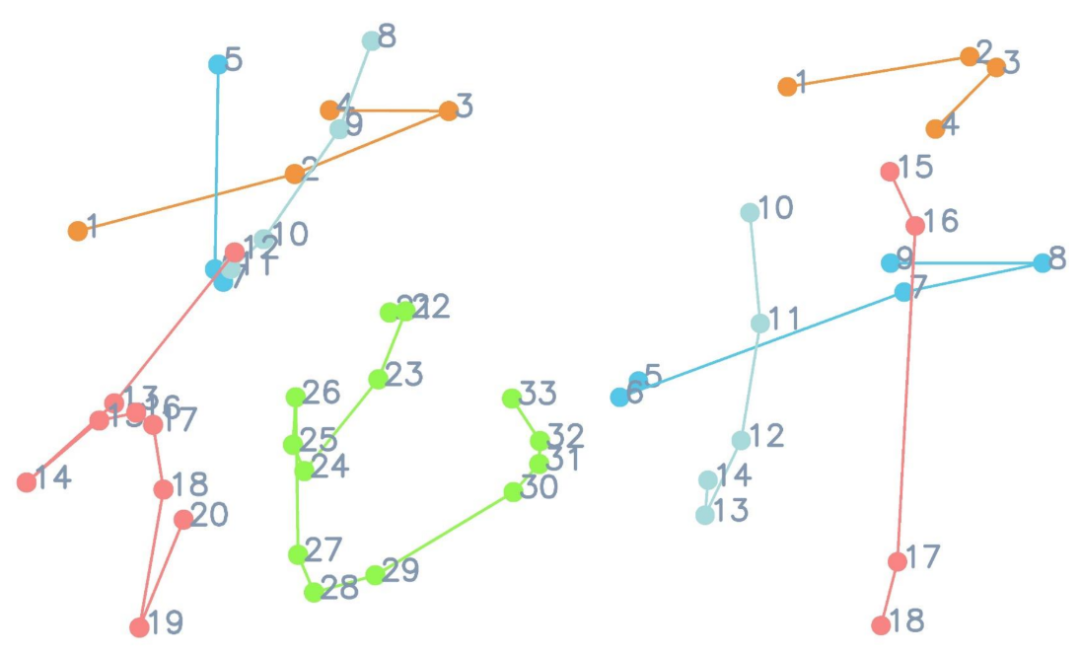
总结起来,本文的研究目标是提出一个风格化的在线手写文字生成模型 (stylized online handwriting generation method)。该模型既能临摹用户提供的离线文字中所蕴含的书写风格,又能根据用户需要在线生成内容可控的手写笔迹。

论文地址:https://arxiv.org/abs/2303.14736
代码开源:https://github.com/dailenson/SDT
主要挑战
为了实现上述目标,研究者们分析了两个关键问题:1. 由于用户只能提供少量的字符样本,能否仅从这些少量的参考样本中学习用户独特的书写风格呢?换句话说,根据少量的参考样本临摹用户的书写风格是否可行?2. 本文的研究目标不仅需要满足生成的文字风格可控,还需要内容也可控。因此,在学习到用户的书写风格后,如何将该风格与文字内容高效的结合,从而生成满足用户期望的手写笔迹?接下来让我们看看这篇 CVPR 2023 提出的 SDT(style disentangled Transformer)方法是怎样解决这两个问题的吧。
解决方案
研究动机 研究者发现,个人笔迹中通常存在两种书写风格:1. 相同书写者的笔迹存在着一种整体上的风格共性,各个字符呈现出相似的倾斜程度和宽高比,且不同书写者的风格共性各不相同。由于这种特性可以用于区分出不同的书写者,研究者们称其为书写者风格。2. 除了整体上的风格共性,来自同一书写者的不同字符间存在着细节上的风格不一致。例如,对于 “黑” 和 “杰” 两个字符,二者在字符结构上具有相同的四点水部首,但该部首在不同的字符中存在微弱的书写差异,体现在笔画书写的长短、位置和曲率上。研究者们将这种字形上的细微的风格模式称为字形风格。受启发于上述观察,SDT 旨在从个人笔迹中解耦出书写者和字形风格,期望提升对用户笔迹的风格模仿能力。

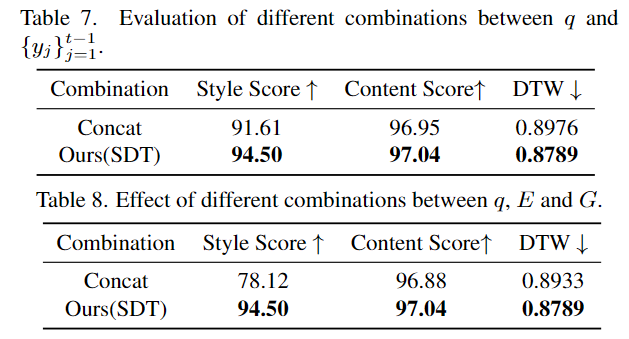
在学习到风格信息后,不同于以往的手写文字生成方法简单的将风格和内容特征进行简单的拼接,SDT 将内容特征作为查询向量,自适应的捕获风格信息,从而实现风格和内容的高效融合,生成符合用户预期的手写笔迹。
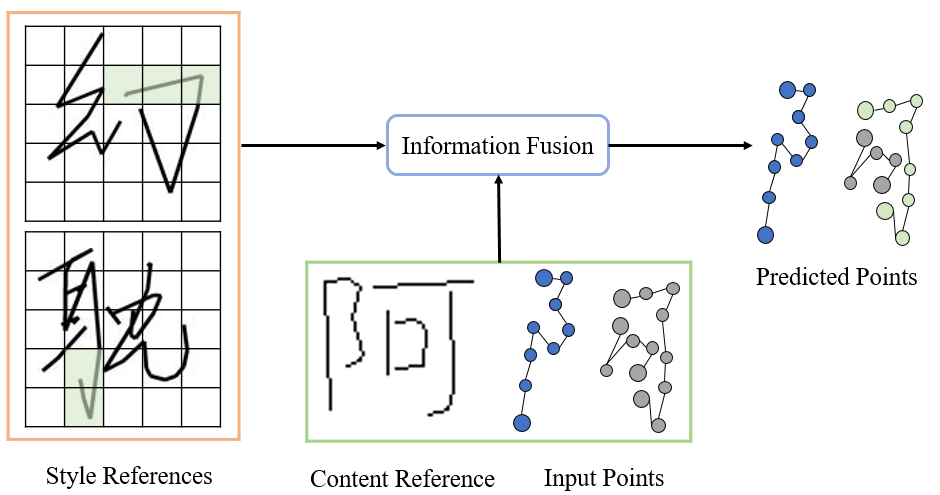
方法框架 SDT 的整体框架如下图所示,包含双分支风格编码器、内容编码器和 transformer 解码器三部分。首先,本文提出两个互补的对比学习目标来引导风格编码器的书写者分支和字形分支分别学习对应的风格提取。然后,SDT 利用 transformer 的注意力机制 (multi-head attention) 对风格特征和内容编码器提取到的内容特征进行动态融合,渐进式的合成在线手写文字。

(a) 书写者风格对比学习 SDT 提出面向书写者风格提取的有监督对比学习目标(WriterNCE),将属于相同书写者的字符样本聚集在一起,推远属于不同书写者的手写样本,显示地引导书写者分支关注个人笔迹中的风格共性。
(b) 字形风格对比学习 为了学习更加细节的字形风格,SDT 提出无监督的对比学习目标 (GlyphNCE),用于最大化相同字符不同视角间的互信息,鼓励字形分支专注学习字符中的细节模式。具体如下图所示,首先对同一张手写字符做两次独立的采样,获取一对含有笔画细节信息的正样本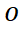 和
和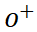 ,然后从其他字符中采样得到负样本
,然后从其他字符中采样得到负样本 。每次采样时,随机选择少量样本块作为包含原始样本细节的新视角。样本块的采样服从均匀分布,避免字符的某些区域被过度采样。为了更好的引导字形分支,采样过程直接作用于字形分支输出的特征序列上。
。每次采样时,随机选择少量样本块作为包含原始样本细节的新视角。样本块的采样服从均匀分布,避免字符的某些区域被过度采样。为了更好的引导字形分支,采样过程直接作用于字形分支输出的特征序列上。
(c) 风格和内容信息的融合策略 获取了两种风格特征后,如何将其与内容编码器学习到的内容编码进行高效融合呢?为了解决这一问题,在任意的解码时刻 t,SDT 将内容特征视作初始点,然后结合 q 和 t 时刻之前输出的轨迹点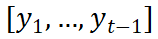 形成新的内容上下文
形成新的内容上下文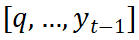 。接着,内容上下文被视为 query 向量,风格信息作为 key & value 向量。在交叉注意力机制的融合下,内容上下文与两种风格信息依次完成动态聚合。
。接着,内容上下文被视为 query 向量,风格信息作为 key & value 向量。在交叉注意力机制的融合下,内容上下文与两种风格信息依次完成动态聚合。
实验
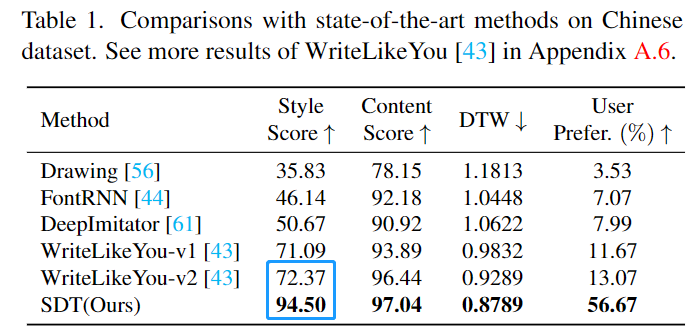
定量评价 SDT 在中文、日文、印度文和英文数据集上都取得了最优异的性能,尤其是在风格分数指标上,相比之前的 SOTA 方法,SDT 取得了较大突破。
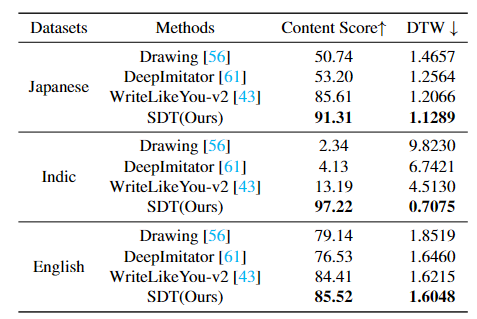
定性评价 在中文生成方面,相比以前的方法,SDT 生成的手写字符既能避免字符的崩坏又能很好的临摹用户的书写风格。得益于字形风格学习,SDT 在字符的笔画细节生成方面也能做的很好。

在其他语言上 SDT 也表现良好。尤其在印度文生成方面,现有主流方法很容易生成崩溃的字符,而我们的 SDT 依旧能够维持字符内容的正确性。
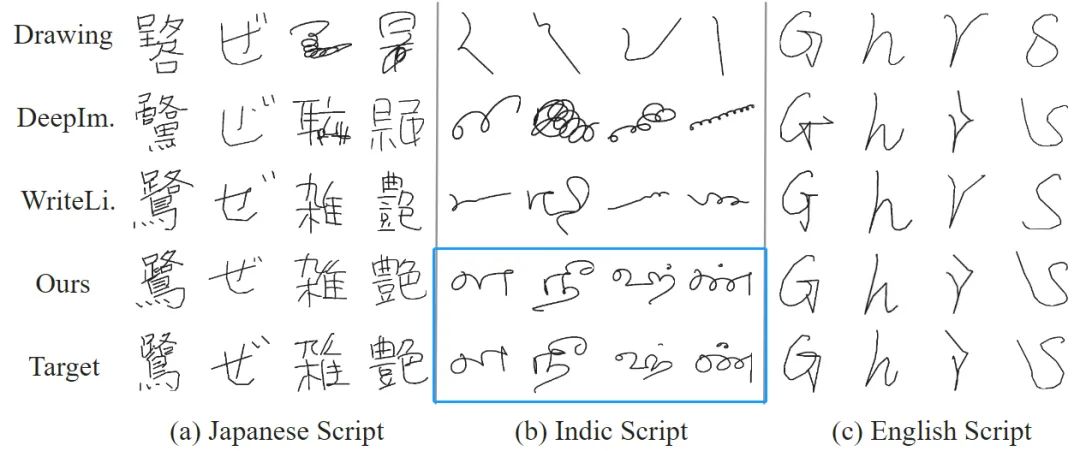
不同模块对算法性能的影响 如下表所示,本文提出的各个模块具有协同作用,有效提升了对用户笔迹的临摹性能。具体来说,书写者风格的加入提升了 SDT 对字符整体风格的模仿,例如字符的倾斜程度和长宽比等,而字形风格的加入改善了生成字符的笔画细节。相比已有方法简单的融合策略,在各项指标上 SDT 的自适应动态融合策略全面增强了字符的生成性能。
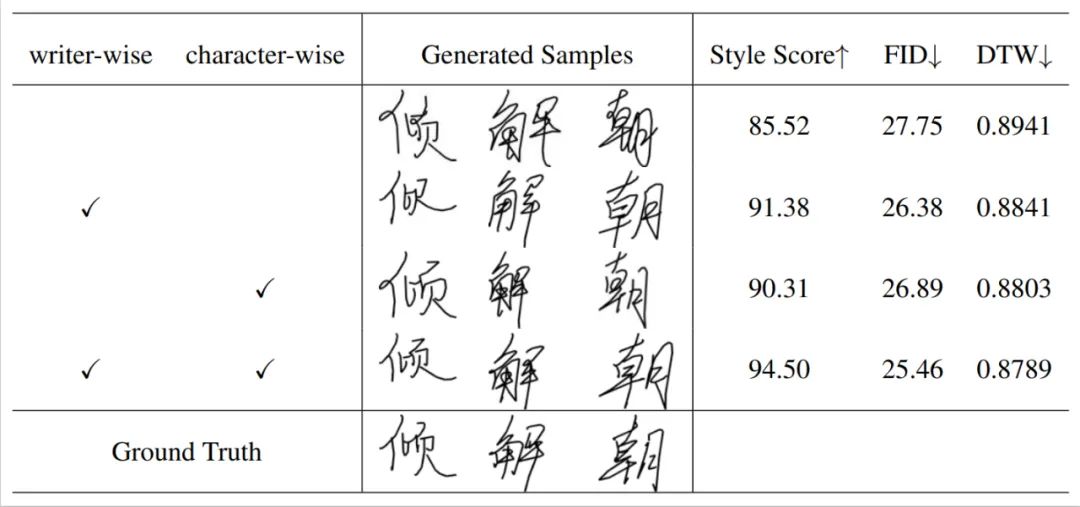
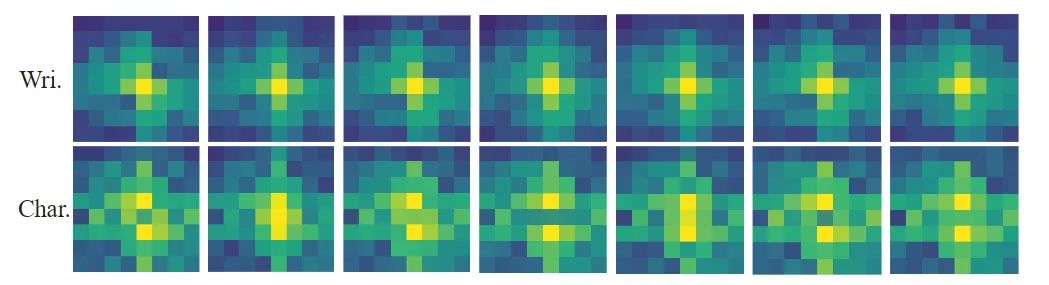
两种风格的可视化分析 对两种风格特征进行傅里叶变换得到如下的频谱图,从图中观察到,书写者风格包含更多的低频成分,而字形风格主要关注高频成分。事实上,低频成分包含目标的整体轮廓,高频成分则更加关注物体的细节。这一发现进一步验证和解释了解耦书写风格的有效性。
展望
大家可以通过笔迹 AI 创造自己的专属字体,在社交平台上更好的表达自我!
最新CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者ransformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()