Datawhale干货
作者:诸葛子房,Datawhale成员
从参与Apache开源项目,到凭借业务需求独自开发个人开源项目;从项目开源出来无人问津到至今500+star,多个企业级用户,在开源过程中,我也从走过低谷,一度想过放弃,但仍然选择坚持至今日。
这一路上,我遇到了什么样的困难,又收获了哪些呢?想借此来分享下在我开源dataCompare 的过程中遇到的坎坷和收获,莫让开源转角蹲着“拦路虎”。
为职业发展铺路,开源蓄力
首先来说说自己为什么要参与开源?
自从进入 IT 行业,行业里很多人认为“IT行业是青春饭”,35岁就会被裁员,之后就没有公司要了。先后也待过几家大厂,包括京东、BAT,也见过不少优秀的技术人员,一直在思考,难道 35 岁就要没公司要了吗?
也见过不少优秀的技术人才,有人进入快速发展的公司,跟随着公司的发展一路上升;也有人输出自己的技术知识(出书、写博客等等),成为某专业领域的佼佼者;还有参与开源项目而在业界取得巨大影响力而不愁工作,在40岁跳槽仍然是多家公司的香饽饽。
参与开源对于个人来说,无论是求职还是后续职业的发展都是一条非常不错的道路,说句实话,自己刚毕业的时候非常有幸参与一个 Apache 开源项目,并成为 contributor,后来无论是在求职还是面试中,都或多或少从其中受益。
因为各种历史原因以及快速迭代的业务需求,在公司里面都是频繁地应对各种需求,厌倦了crud、厌倦了 ”屎山“ 代码,想提升自己
dataCompare开源之路
前段时间因为公司里面的一个需求开发了一个简单工具,当时想着是否其他公司也有类似的需求,就试着开源出来了。
个人开源还是很难做的,相对于企业来说。由于自己是做大数据和后端,已经很久没有做过前端了,导致前端这方面已经忘记的差不多了。这次的开源项目也是借助网上的一些开源框架,避免了太多前端开发工作。所以就不得不去学全栈,不仅仅是会前端、后端、数据,有可能还要会运维。而这些在企业里基本上是一个团队协同参与的。
再就是如何去推广了,这也是一个老大难的问题。正常的一个公司的产品是由一个运营团队来支持的。但是作为个人开源来说,这些事情你都得87做。写产品和使用文档、写代码做运维、甚至包括产品推广运营。而这些工作在公司是有多个团队来支持的,至少也是有一个小团队来支持的吧。最后就是如何保证开源项目的持续更新和迭代,也就是保障项目的可持续性而不是不更新了。
说说我在开源的时候遇到这些问题是怎么解决的吧。
开发运维,这个可以借助网上的一些工具,比如说用docker快速搭建开发环境,借助一些网上现成的开源框架来规避一些不擅长的技术栈(就像我自己不擅长前端,但是借助开源框架还是完全能实现自己的产品)。
推广这方面主要是借助自己之前的一些积累,由于长期对于自己所做项目进行总结,在网上进行输出也积累一批粉丝,因此借助这些资源进行推广,同时身边也有不少人的技术开发者,也借助他们进行了一些,所以还算勉强能进行推广。
再就是撰写产品使用文档,这部分由于经常写博客、做总结,其实还算马马虎虎,写的文档别人能看懂,其后再根据一些使用用户的反馈完善文档中不太全面的地方,这样的话就能保证写出来的使用文档,其他人入手项目的时候无障碍。
最后一点也是最难的一点,就是一个人精力实在有限,况且还得在完成公司本职工作的情况下去做开源,如果说全职做的话,也许会好很多,希望更多的开发者能进来一起开发。
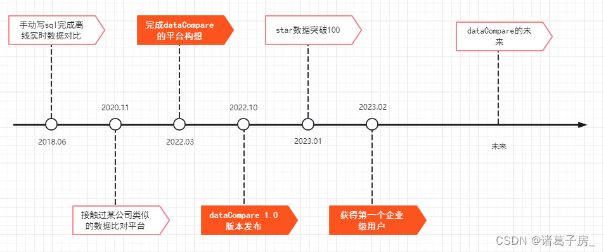
我这边目前尝试的方式,先开发出项目的核心功能,以保证项目是可用的,然后进行推广获取第一批用户或者企业,这样根据使用者的反馈进行迭代。而不是一上来就开发出大而全的产品,毕竟人力还是有限。
作为个人开源,我觉得要集中力量做大事,即:花费时间在项目的核心点,这样的话,能保证项目有亮点、可用,才能吸引到用户,有了第一批用户之后我们就可以持续迭代了
现在回忆起来整个历程。如下三点才是一个开源项目的发展的关键:
能够解决用户的1-2个问题点,然后进行打磨,最好是结合工作中有的需求,然后尝试抽象开发出来,并且完善核心功能,在核心功能上进行打磨。
合适的推广和运营,“酒香也怕巷子深”,合适的推广运营,让项目能找到第一批用户,然后尝试和用户一起共同建设。通过参与一些开源社区和一些朋友的推荐,慢慢地项目会获得更多的人关注,打磨核心功能,找到第一批用户,这样项目的发展就可以构建出来一个良性循环。
长期的投入和坚持,通过推广和运营,会获取到一些用户的关注和反馈,这样也会更有动力持续做下去。
参与开源的收获和建议
首先就是对个人能力的提升,开源项目的代码质量非常高,对于自己的成长非常有益
作为顶级开源项目的参与者或者贡献者,在未来的求职面试也会非常加分
同时也会了解到一个大型项目是如何运作的,全自动化CI、CD
下面引用一篇文章对于参与开源项目的收获
"参与开源社区可以给个人带来很好的自我提升。如果不是参与开源系统,可能到现在也不会了解到Semantic Versioning 和 Linear Commit History 的重要性, 更不用说如何基于各种社区资源搭建全套工作流程。在 commit 代码的过程中,无论是 review 别人的代码,还是被别人 review 代码, 都可以帮助你纠正自己的很多认知误区,收获的其实是一对一的免费 coaching。而与社区开发者一起沟通 roadmap 的时候碰撞出的思路和想法也是闭门造车不可能产生的。参与开源社区可以获得日常工作比较难获得的高成就感,这种高成就感会形成正向反馈让你更加努力和严谨。当看到来自全球的近 30w 开发者使用着这个项目,来自数十个不同的国家和地区的开发者一起共同工作贡献代码的时候。"
如何挑选适合自己的开源项目呢?
(1)如何选择开源项目
a.选择和自己工作内容相关的领域项目,从自己熟悉的领域进行切入 b.选择活跃度高的开源项目,主要从代码的更新频率、issue修复情况、社区活跃情况来看
(2)如何参与?
首先从项目部署运行和试用开始,再尝试一些简单的问题修复,最后再一步步深入了解项目
(3)新的思路和想法
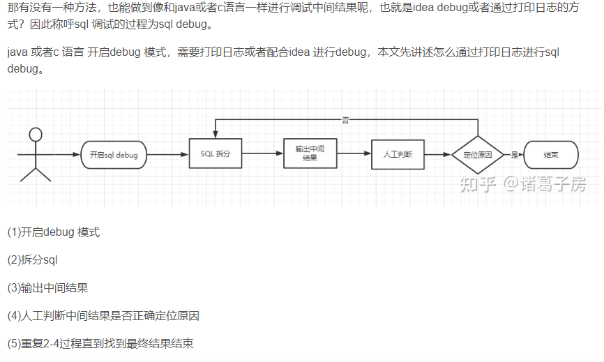
当我们有自己的想法之后就可以选择把自己功能集成到开源项目里面,下面是我思考的一个关于sql debug 的功能(根据自己的工作经验)
(4)个人开源项目经验分享
打磨核心功能、借助资源、打造个人影响力,反哺项目推广和运营、找到标杆用户,持续跟进优化
开源项目地址:
https://github.com/zhugezifang/dataCompare https://github.com/zhugezifang/dataService
作者介绍:
诸葛子房,先后就职于京东和BAT,在大数据领域有多年工作经验,Apache Griffin&&Apache Zeppelin Contributor,dataCompare和dataService作者,微信: zhugezifang001

干货学习,点赞三连↓