系列文章目录
目录
前言
一、什么是分布式ID?
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。
如在金融、电商、支付、等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息,数据库的自增ID显然不能满足需求,此时一个能够生成全局唯一ID的系统是非常必要的。
二、分布式系统唯一ID的特点
- 唯一性:确保生成的ID是全网唯一的。
- 有序递增性:确保生成的ID是对于某个用户或者业务是按一定的数字有序递增的。
- 高可用性:确保任何时候都能正确的生成ID。
- 带时间:ID里面包含时间,一眼扫过去就知道哪天的交易。
同时除了对ID号码自身的要求,业务还对ID号生成系统的可用性要求极高,想象一下,如果ID生成系统瘫痪,这就会带来一场灾难。
三、分布式ID的实现方案
1.UUID方案
UUID(Universally Unique Identifier)的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,示例:550e8400-e29b-41d4-a716-446655440000,到目前为止业界一共有5种方式生成UUID,详情见IETF发布的UUID规范 A Universally Unique IDentifier (UUID) URN Namespace。
UUID优点:
- 性能非常高:本地生成,没有网络消耗。
UUID缺点:
- 不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,非常不适合做索引;
- 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露。
- UUID 的随机性对于 I/O 密集型的应用非常不友好!它会使得聚簇索引的插入变得完全随机,使得数据没有任何聚集特性。
- ID作为主键时在特定的环境会存在一些问题,比如做DB主键的场景下,UUID就非常不适用:
① MySQL官方有明确的建议主键要尽量越短越好[4],36个字符长度的UUID不符合要求。
All indexes other than the clustered index are known as secondary indexes. In InnoDB, each record in a secondary index contains the primary key columns for the row, as well as the columns specified for the secondary index. InnoDB uses this primary key value to search for the row in the clustered index.*** If the primary key is long, the secondary indexes use more space, so it is advantageous to have a short primary key***.
② 对MySQL索引不利:如果作为数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能。
UUID生成
@Test
public void uuid() {
// java.util.UUID
UUID uuid = UUID.randomUUID();
System.out.println(uuid);
cn.hutool.core.lang.UUID uuid2 = cn.hutool.core.lang.UUID.randomUUID();
System.out.println(uuid2);
}95cd2745-72c6-406c-ab96-bd5f4f40bd50
bd9a176d-f8d5-4eab-b13d-019ce9f9c62f2.数据库生成ID
以MySQL举例,利用给字段设置auto_increment_increment和auto_increment_offset来保证ID自增。
SHOW VARIABLES LIKE 'auto_increment%'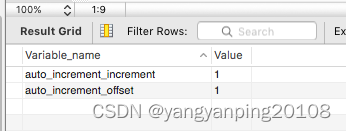
创建表
CREATE TABLE `id_table` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(45) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
replace into是每次删除原来相同的数据,同时加1条,就能保证我们每次得到的就是一个自增的ID 。
优点
数据库生成的ID绝对有序,高可用实现方式简单
缺点
需要独立部署数据库实例,成本高,ID发号性能瓶颈限制在单台MySQL的读写性能。
数据库方案扩容
如果单台数据库存在瓶颈问题,我们可以扩展多台数据库,如扩展到三台数据库,分别设置每台数据库的起始值和步长。
起始值好改,在定义表的时候就可以设置,步长我们可以通过修改这个配置实现:
set @@auto_increment_increment=3;既然 MySQL 可以修改自增的起始值和每次增长的步长,现在假设我有 db1、db2 和 db3,我就可以分别设置这三个库中表的自增起始值为 1、2、3,然后自增步长都是 3,这样就可以实现自增了。
| 数据库 | auto_increment_offset | auto_increment_increment | 生成的ID |
|---|---|---|---|
| db-1 | 1 | 3 | 1,4,7,10 |
| db-2 | 2 | 3 | 2,5,8,11 |
| db-3 | 3 | 3 | 3,6,9,12 |

但是很明显这种方式不够优雅,而且处理起来很麻烦,将来扩展也不方便,因此不推荐。
3.数据库批量生成ID
是对上面数据库自增ID的改进,一次按需批量生成多个ID,每次生成都需要访问数据库,将数据库修改为最大的ID值,并在内存中记录当前值及最大值。
创建sequence 表
CREATE TABLE `table_sequence` (
`name` varchar(64) CHARACTER SET latin1 NOT NULL COMMENT '表名称',
`value` bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '当前号段下的最大 id',
`step` int(11) unsigned NOT NULL DEFAULT '1' COMMENT '每次取号段的步长',
`description` varchar(128) NOT NULL COMMENT '描述信息',
`update_time` varchar(45) NOT NULL DEFAULT 'CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP' COMMENT '更新时间',
PRIMARY KEY (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='sequence 表';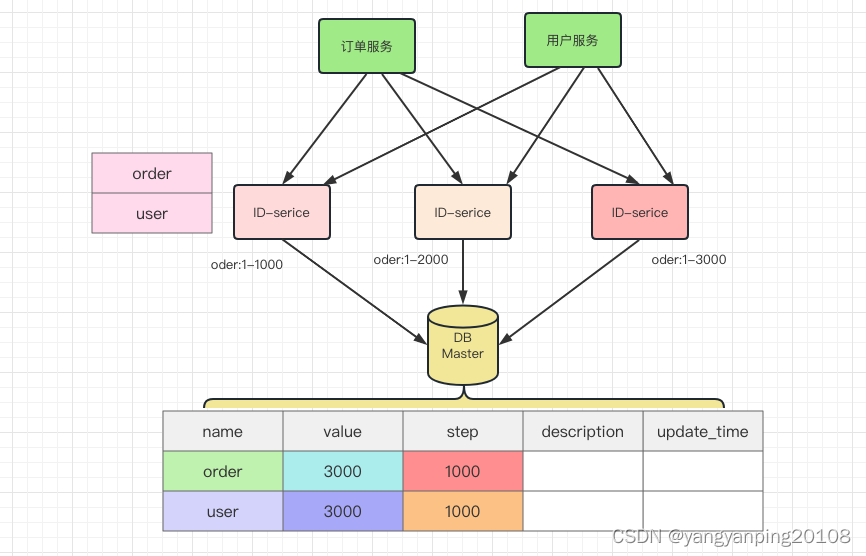
优点:避免了每次生成ID都要访问数据库并带来压力,提高性能
缺点:属于本地生成策略,存在单点故障,服务重启造成ID不连续
4.Redis生成ID
Redis的所有命令操作都是单线程的,本身提供像 incr 和 increby 这样的自增原子命令,所以能保证生成的 ID 肯定是唯一有序的。比较适合使用Redis来生成每天从0开始的流水号。比如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key,使用INCR进行累加。
优点
不依赖于数据库,灵活方便,且性能优于数据库;数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点
如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
考虑到单点的性能瓶颈,可以使用 Redis 集群来获取更高的吞吐量。假如一个集群中有5台Redis。可以初始化每台 Redis 的值分别是1, 2, 3, 4, 5,然后步长是 5。
5.利用zookeeper生成唯一ID
zookeeper主要通过其znode数据版本来生成序列号,可以生成32位和64位的数据版本号,客户端可以使用这个版本号来作为唯一的序列号。
很少会使用zookeeper来生成唯一ID。主要是由于需要依赖zookeeper,并且是多步调用API,如果在竞争较大的情况下,需要考虑使用分布式锁。因此,性能在高并发的分布式环境下,也不甚理想。
6.snowflake雪花算法生成ID
这种方案大致来说是一种以划分命名空间(UUID也算,由于比较常见,所以单独分析)来生成ID的一种算法,这种方案把64-bit分别划分成多段,分开来标示机器、时间等,比如在snowflake中的64-bit分别表示如下图(图片来自网络)所示:

- 符号位 (1bit)
预留的符号位,恒为零。
- 时间戳位 (41bit)
41 位的时间戳可以容纳的毫秒数是 2 的 41 次幂,一年所使用的毫秒数是:365 * 24 * 60 * 60 * 1000。通过计算可知:Math.pow(2, 41) / (365 * 24 * 60 * 60 * 1000L);结果约等于 69.73 年。
ShardingSphere 的雪花算法的时间纪元从 2016 年 11 月 1 日零点开始,可以使用到 2086 年,相信能满足绝大部分系统的要求。
- 工作进程位 (10bit)
该标志在 Java 进程内是唯一的,如果是分布式应用部署应保证每个工作进程的 id 是不同的。该值默认为 0,可通过属性设置。10-bit机器可以分别表示1024台机器。如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义。
- 序列号位 (12bit)
该序列是用来在同一个毫秒内生成不同的 ID。如果在这个毫秒内生成的数量超过 4096 (2 的 12 次幂),那么生成器会等待到下个毫秒继续生成。
雪花算法ID优点:
毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
可以根据自身业务特性分配bit位,非常灵活。
雪花算法ID缺点:
强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
分布式情况
在分布下使用,需要分配不同的workId,如果workId相同,可能会导致生成的id相同。
解决方案:
1、使用java环境变量,人为通过-D预先设置workId。这种方案简单,不会出现重复情况,但需要每个服务的启动脚本不同,适合于少量机器部署。
cd /home/www/user-soa
nohup java -jar -Dspring.profiles.active=prod -DworkId=1 -Xms4028M -Xmx4028M -XX:PermSize=512M -XX:MaxPermSize=512M /home/www/user-soa/user-soa-0.0.1-SNAPSHOT.jar &>> /home/www/logs 2>&1 &
直接使用 hutool 工具类中的雪花算法:
/**
* ID 生成器
*
* @author yangyanping
* @date 2023-06-14
*/
public class IdUtils {
/**
* 机器ID
*/
private static final Long workId = Long.valueOf(System.getProperty("workId"));
/**
* ❄️❄️❄️❄️❄️
*/
private static final Snowflake SNOWFLAKE = IdUtil.getSnowflake(workId, 1);
/**
* 获取ID
*/
public static Long getNextId() {
return SNOWFLAKE.nextId();
}
}2、使用sharding-jdbc中的算法,使用IP后几位来做workId,这种方案也很简单,不需要修改服务的启动脚本,但在某些情况下会出现生成重复ID的情况。
3、使用zk,在启动时给每个服务分配不同的workId。
缺点:多了依赖,需要zk。
优点:不会出现重复情况,且不需要修改服务的启动脚本。这个是我个人使用的方案,实现思路为,系统启动时创建一个永久性的结点(zookeeper保证原子性),然后在这个永久性的节点下,遍历workId去zookeeper创建临时结点,zookeeper会保证相同路径只会有一个可能创建成功,如果创建失败继续遍历即可。
生产环境部署:
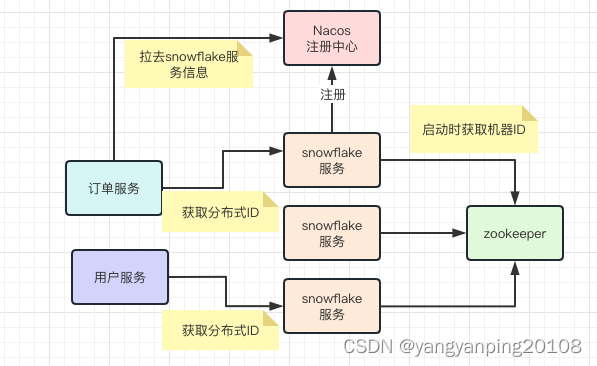
雪花算法的工具类
import java.lang.management.ManagementFactory;
import java.net.InetAddress;
import java.net.NetworkInterface;
public class IdWorker {
// 时间起始标记点,作为基准,一般取系统的最近时间(一旦确定不能变动)
private final static long twepoch = 1288834974657L;
//机器标识位数
private final static long workerIdBits = 5L;
// 数据中心标识位数
private final static long datacenterIdBits = 5L;
// 机器ID最大值
private final static long maxWorkerId = -1L ^ (-1L << workerIdBits);
// 数据中心ID最大值
private final static long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
// 毫秒内自增位
private final static long sequenceBits = 12L;
// 机器ID偏左移12位
private final static long workerIdShift = sequenceBits;
// 数据中心ID左移17位
private final static long datacenterIdShift = sequenceBits + workerIdBits;
// 时间毫秒左移22位
private final static long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
private final static long sequenceMask = -1L ^ (-1L << sequenceBits);
/* 上次生产id时间戳 */
private static long lastTimestamp = -1L;
// 0,并发控制
private long sequence = 0L;
private final long workerId;
// 数据标识id部分
private final long datacenterId;
public IdWorker() {
this.datacenterId = getDatacenterId(maxDatacenterId);
this.workerId = getMaxWorkerId(datacenterId, maxWorkerId);
}
/**
* @param workerId * 工作机器ID * @param datacenterId * 序列号
*/
public IdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* 获取下一个ID * * @return
*/
public synchronized long nextId() {
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
if (lastTimestamp == timestamp) {
// 当前毫秒内,则+1
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
// 当前毫秒内计数满了,则等待下一秒
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
// ID偏移组合生成最终的ID,并返回ID
long nextId = ((timestamp - twepoch) << timestampLeftShift) | (datacenterId << datacenterIdShift) | (workerId << workerIdShift) | sequence;
return nextId;
}
private long tilNextMillis(final long lastTimestamp) {
long timestamp = this.timeGen();
while (timestamp <= lastTimestamp) {
timestamp = this.timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
/**
* <p> * 获取 maxWorkerId * </p>
*/
protected static long getMaxWorkerId(long datacenterId, long maxWorkerId) {
StringBuffer mpid = new StringBuffer();
mpid.append(datacenterId);
String name = ManagementFactory.getRuntimeMXBean().getName();
if (!name.isEmpty()) { /* * GET jvmPid */
mpid.append(name.split("@")[0]);
} /* * MAC + PID 的 hashcode 获取16个低位 */
return (mpid.toString().hashCode() & 0xffff) % (maxWorkerId + 1);
}
/**
* <p> * 数据标识id部分 * </p>
*/
protected static long getDatacenterId(long maxDatacenterId) {
long id = 0L;
try {
InetAddress ip = InetAddress.getLocalHost();
NetworkInterface network = NetworkInterface.getByInetAddress(ip);
if (network == null) {
id = 1L;
} else {
byte[] mac = network.getHardwareAddress();
id = ((0x000000FF & (long) mac[mac.length - 1]) | (0x0000FF00 & (((long) mac[mac.length - 2]) << 8))) >> 6;
id = id % (maxDatacenterId + 1);
}
} catch (Exception e) {
System.out.println(" getDatacenterId: " + e.getMessage());
}
return id;
}
}用法如下:
public static void main(String[] args) {
IdWorker idWorker = new IdWorker(0, 0);
for (int i = 0; i < 1000; i++) {
System.out.println(idWorker.nextId());
}
}7 LEAF
Leaf 是美团开源的分布式 ID 生成系统,目前 LEAF 的使用有两种不同的思路,号段模式和 SNOWFLAKE 模式,你可以同时开启两种方式,也可以指定开启某种方式(默认两种方式为关闭状态)
号段模式
号段模式还是基于数据库,但是思路有些变化,如下:
- 利用 proxy server 从数据库中批量获取 id,每次获取一个 segment (step 决定其大小) 号段的值,用完之后再去数据库获取新的号段,可以大大的减轻数据库的压力。
- 各个业务不同的发号需求用 biz_tag 字段来区分,每个 biz-tag 的 ID 获取相互隔离,互不影响。
- 如果有新的业务需要扩区 ID,只需要增加表记录即可。
如果使用号段模式,我们首先需要创建一张数据表,脚本如下:
CREATE TABLE `leaf_alloc` (
`biz_tag` varchar(128) NOT NULL DEFAULT '',
`max_id` bigint(20) NOT NULL DEFAULT '1',
`step` int(11) NOT NULL,
`description` varchar(256) DEFAULT NULL,
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB DEFAULT CHARSET=utf-8;这张表中各项字段的含义如下:
- biz_tag:业务标记(不同业务可以有不同的号段序列)
- max_id:当前号段下的最大 id
- step:每次取号段的步长
- description:描述信息
- update_time:更新时间
配置完成后,启动项目,访问 http://localhost:8080/api/segment/get/leaf-segment-test 路径(路径最后面的 leaf-segment-test 是业务标记),即可拿到 ID。
可以通过如下地址访问到号段模式的监控页面 http://localhost:8080/cache。
号段模式优缺点:
优点
- Leaf 服务可以很方便的线性扩展,性能完全能够支撑大多数业务场景。
- ID 号码是趋势递增的 8byte 的 64 位数字,满足上述数据库存储的主键要求。
- 容灾性高:Leaf 服务内部有号段缓存,即使 DB 宕机,短时间内 Leaf 仍能正常对外提供服务。
- 可以自定义 max_id 的大小,非常方便业务从原有的 ID 方式上迁移过来。
缺点
- ID 号码不够随机,能够泄露发号数量的信息,不太安全。
- DB 宕机会造成整个系统不可用。
SNOWFLAKE 模式
SNOWFLAKE 模式需要配合 Zookeeper 一起,不过 SNOWFLAKE 对 Zookeeper 的依赖是弱依赖,把 Zookeeper 启动之后,我们可以在 SNOWFLAKE 中配置 Zookeeper 信息,如下:
leaf.snowflake.enable=true leaf.snowflake.zk.address=192.168.91.130 leaf.snowflake.port=2183
然后重新启动项目,启动成功后,通过如下地址可以访问到 ID:
http://localhost:8080/api/snowflake/get/test
参考
分布式ID详解(5种分布式ID生成方案)_mikechen的互联网架构的博客-CSDN博客