一、背景
最近公司采用Hbase scan 的方式,经常性会遇到任务跑不出来region 读取超时,由于scan 全量数据,合计行数10个亿,列数接近500。根据建议方案,改为Hbase 快照读方式,避免给region 造成过大压力
二、Hbase 快照原理
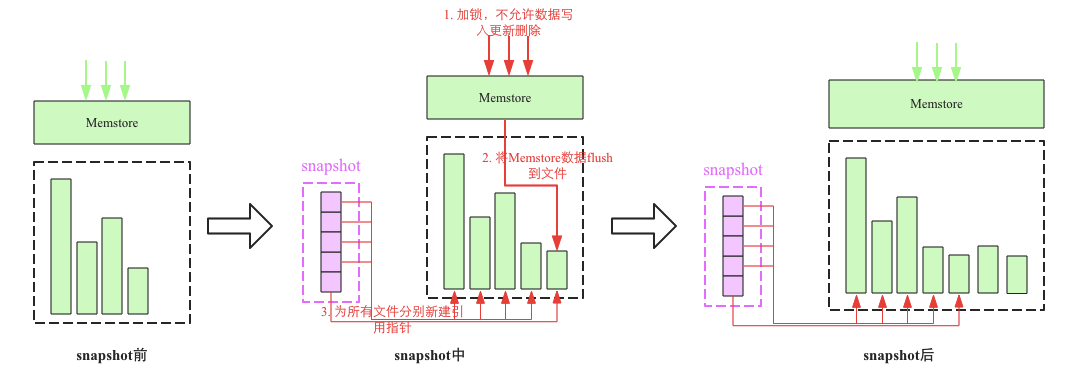
snapshot流程主要涉及3个步骤:
1. 加一把全局锁,此时不允许任何的数据写入更新以及删除
2. 将Memstore中的缓存数据flush到文件中(可选)
3. 为所有HFile文件分别新建引用指针,这些指针元数据就是snapshot
三、实际线上表现
改为快照方式扫描之后,提交的任务半天提交不起来,接近1小时,任务才能启起来。
一般遇到程序卡住不动,会想到使用jstack 查看程序的堆栈信息
(1)查看程序的进程pid(top 命令或者ps -ef|grep 命令)
(2)找到程序的pid,打印jstack 信息
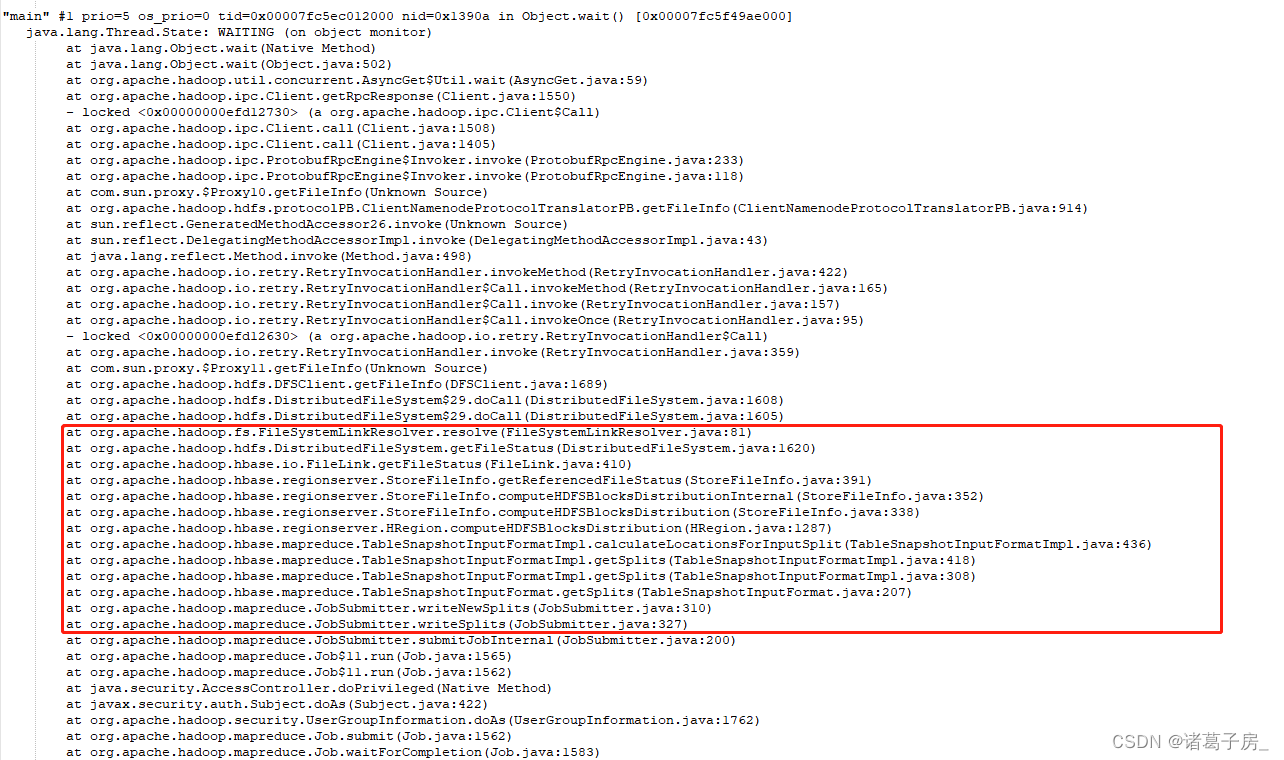
能看到程序一直卡在这个地方,一直计算block 信息,找到对应的Hbase 源码,查看对应的代码信息
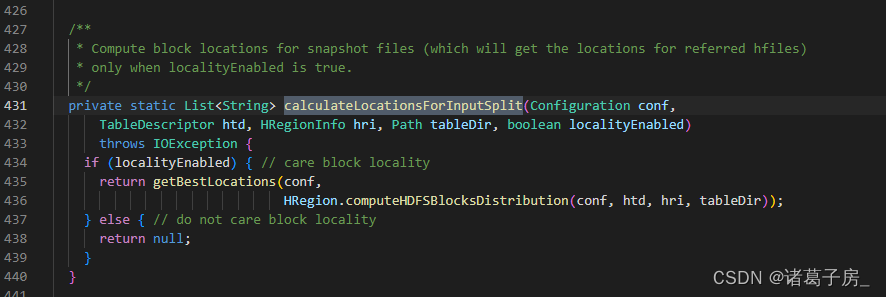
可以看到是由于计算block location信息,那什么是location 呢?
利用chatGPT查询hbase locality的含义,能发现其实就是数据本地性,而我们实际任务中是不需要计算这个本地性占比,因为只需要能拉到数据即可,无论是从本地还是远端

HBase locality的原理可以分为两个方面,即数据本地性和任务本地性。
数据本地性
在HBase中,数据是以Region的形式存储的,一个Region包含了一段连续的行键范围。每个Region都会被分配到一个RegionServer上进行管理,并在该RegionServer上存储它所包含的所有数据。
当客户端访问HBase中的数据时,它会首先向HBase的Master节点请求获取对应数据所在的RegionServer的信息,然后再从该RegionServer上获取所需的数据。如果客户端所在的节点与该数据所在的RegionServer节点相同,就可以直接在该节点上获取数据,避免了网络传输的延迟,从而提高了数据访问的效率。
任务本地性
HBase中的任务包括数据写入和数据查询两种类型。在HBase中,数据写入是通过向表中的RegionServer发送写请求来完成的。如果客户端所在的节点与该RegionServer节点相同,那么写请求可以直接发送到该节点上,从而实现本地写入。
另一方面,数据查询任务是由HBase的RegionServer节点完成的。当RegionServer节点接收到查询请求时,它会首先检查所需数据所在的Region是否已经在该节点上加载到内存中,如果是,则可以直接在该节点上执行查询操作,否则需要从其他节点上获取数据,这将导致额外的网络延迟和资源开销。
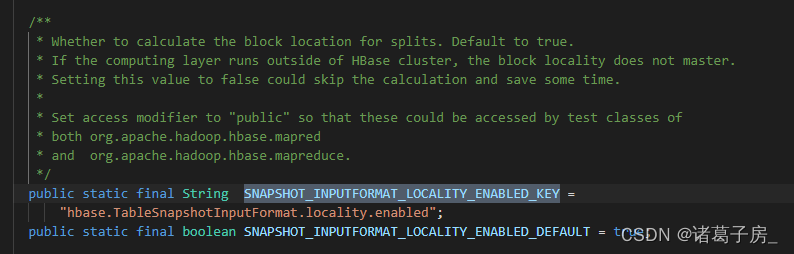
因此,为了最大化任务本地性,HBase通常会将数据分布在多个Region中,并将这些Region分配到尽可能多的节点上进行管理,从而最大化数据和任务之间的本地性。此外,HBase还提供了一些机制来管理Region的负载均衡和RegionServer节点的故障转移,以保证系统的高可用性和稳定性。最终只需要在提交任务的地方设置 hbase.TableSnapshotInputFormat.locality.enabled 为false 即可,任务提交就非常快了。
参考: