Interpreter 其实就是整个项目的核心,代码运行都是在里面进行执行的,首先来看下Interpreter的抽象类
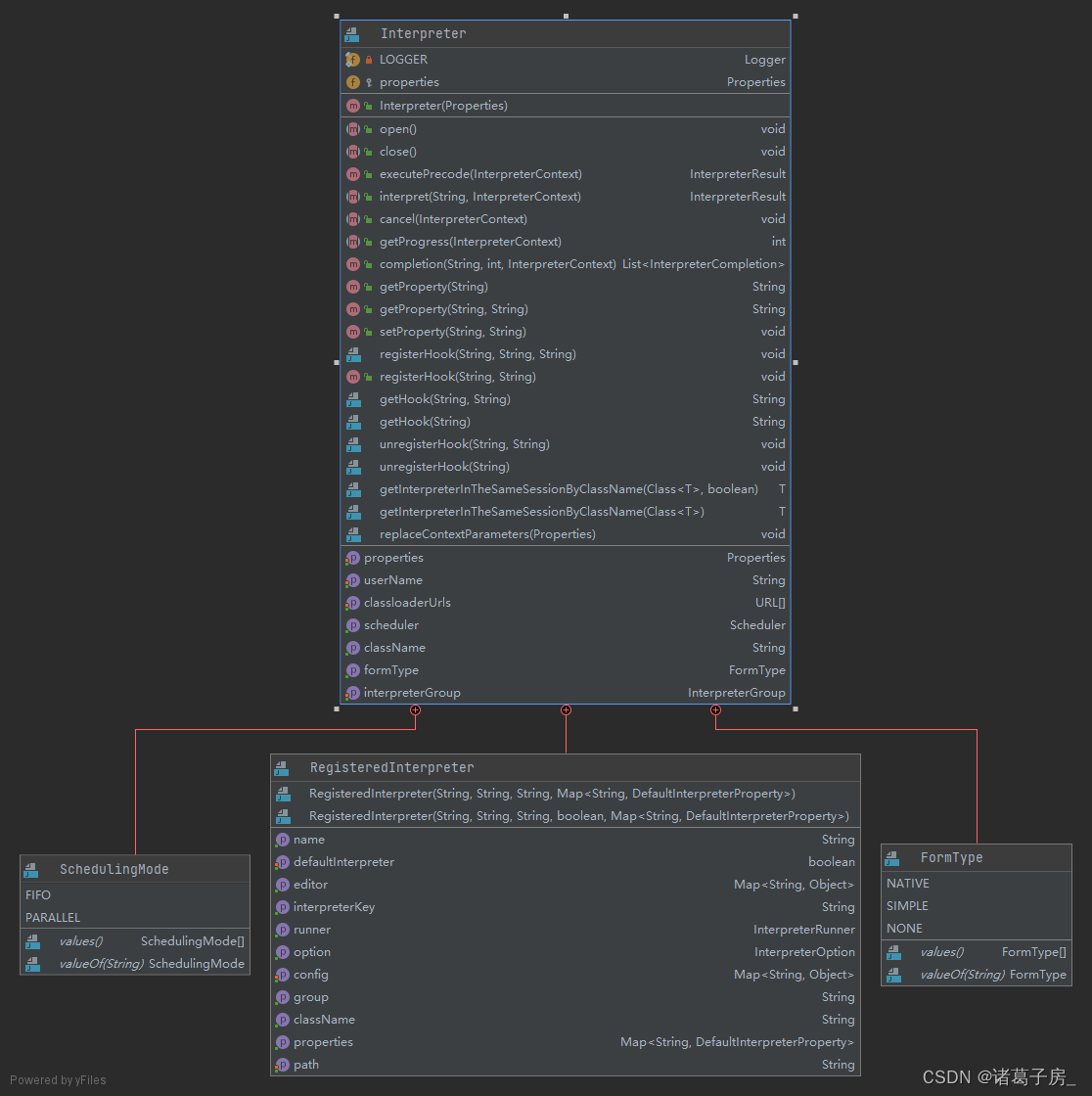
以jdbc-Interpreter为例,可以参考下测试代码(这个代码里面可以直接测试jdbc的sql执行过程和数据返回过程)

参数和介绍可以参考官方文档:Apache Zeppelin 0.10.1 Documentation: Generic JDBC Interpreter for Apache Zeppelin
@Test
public void testSelectQueryMaxResult() throws IOException, InterpreterException {
Properties properties = new Properties();
properties.setProperty("common.max_count", "1");
properties.setProperty("common.max_retry", "3");
properties.setProperty("default.driver", "org.h2.Driver");
properties.setProperty("default.url", getJdbcConnection());
properties.setProperty("default.user", "");
properties.setProperty("default.password", "");
JDBCInterpreter t = new JDBCInterpreter(properties);
t.open();
String sqlQuery = "select * from test_table";
InterpreterResult interpreterResult = t.interpret(sqlQuery, context);
assertEquals(InterpreterResult.Code.SUCCESS, interpreterResult.code());
List<InterpreterResultMessage> resultMessages = context.out.toInterpreterResultMessage();
assertEquals(InterpreterResult.Type.TABLE, resultMessages.get(0).getType());
assertEquals("ID\tNAME\na\ta_name\n", resultMessages.get(0).getData());
assertEquals(InterpreterResult.Type.HTML, resultMessages.get(1).getType());
assertTrue(resultMessages.get(1).getData().contains("Output is truncated"));
}JDBCInterpreter类internalInterpret执行流程主要是:
(1)执行sql
(2)结果处理:
getResults判断是否会超过设定行数,InterpreterOutput 里面context.out.write 按照字节进行写入同时判断是否超过字节数
(3)调用这个方法返回结果
List<InterpreterResultMessage> resultMessages = context.out.toInterpreterResultMessage();