Cache多核同步
cache分为d-cache(可读写)和i-cache(只读)。这样区分主要是为了减少资源冲突,很多中间件也是采用类似的思想,比如innodb的undo段分为insert段和update段,也是为了区分事务对两种改动的不同可见性。icache是只读的,不同cpu之间不会出现数据不一致的情况,而dcache是可读写的,不同的cpu节点会出现数据不一致的情况。
当CPU更改了某条cache line中的数据,则该cache line中的数据比对应内存中的数据新,此时需要将这条cache line标记为modified,以便在cache缓存满了的情况下将cache line中的脏内容flush到内存。
在使用DMA的时候,外设(比如网卡)过来的数据会不经过CPU直接传送到内存,这时内存中的数据就比对应cache中的数据要新,同样需要使对应的cache无效(invalidate),这样CPU下次读取这条cache line里的数据的时候,才能知道这些数据不是最新的,从而从内存更新。
CPU从内存中读取数据到cache line的操作为load,将cache line中的数据写回到内存对应位置的操作为store。cache属于CPU的一部分,而CPU和内存之间是通过总线相连的,因此load和store操作需要经过总线传输。
当代处理器一般不止一个CPU核心,那么如何保证各个CPU对内存同一位置的store和load的操作是序列化的,也就是确保store和load的顺序和线程执行的顺序一致呢?处理器有两种方法实现:嗅探和点对点推送,类似网卡的混杂模式和直接模式。
嗅探
缓存的变动会通过总线广播,其他cpu上的过滤器只会接收处理自身缓存的cache line相关的变化。
点对点推送
一些芯片也会做一些优化,cpu对相关内存位置对应的修改,会只通知拥有相同内存位置cache的cpu,减少总线广播流量。这个机制需要cache line增加一个flag组存储额外信息,即同时操作该内存的cpu id,将同时操作该内存的cpu id对应的位置1,修改该cache时,只通知这些cpu节点。这种机制每次推送一致性广播前都要查询directory,会比直接广播时延高一些。
numa系统之间的cache一致性同步
numa模型里面不同node的CPU之间不再是通过共享的总线相连,而是通过高速消息网络相连,所以numa只能点对点通知,无法使用总线广播。
cache line写时更新
cache和内存保持一致性的写入方式有两种:直写和回写,其实所有的持久化如磁盘都是这两种方式。
CPU对共享变量有写操作之后立刻更新到内存的做法,称为直写。而更好的做法是在其他CPU(P2)对缓存变量有写操作之后,自身CPU(P1)将自己cache中对应的cache line标记为invalid/dirty的状态,这种实现方式为回写。
MSI协议
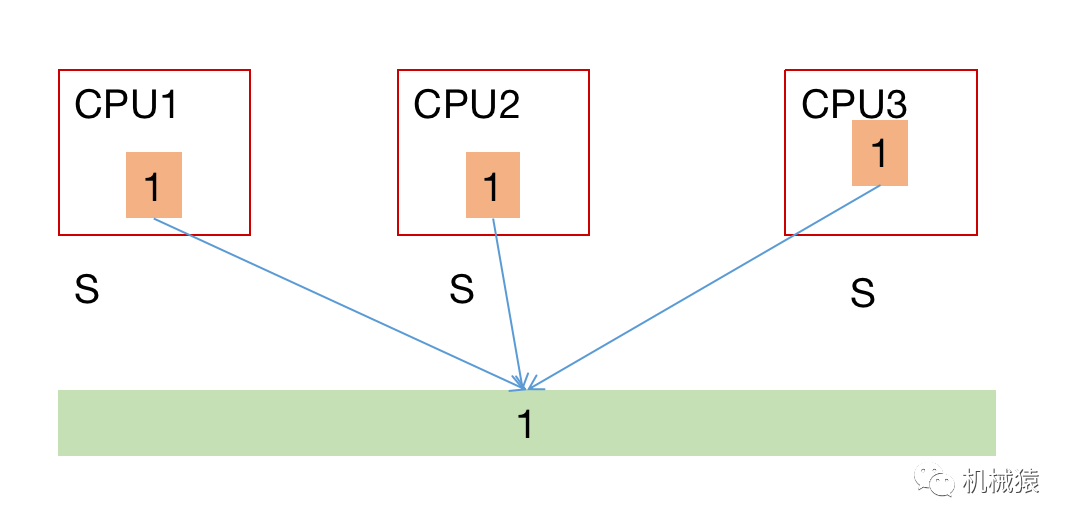
初始状态某内存变量为1,各CPU对应的cache line与内存值一致,此时cache line为shared(S)状态。
CPU2将自己cache line的数据更改为2,CPU2的这条cache line就变为modified状态(S-->M),其他CPU的cache line就变为invalid状态(S-->I),这个状态更新的实现就是前面的嗅探/点对点推送。除了这种场景,经过dma更新到内存的数据,对应的cacheline也会被标记为invalid状态,而这种情况下的状态更新需要依靠特定驱动来完成。此时CPU2并不一定会将最新值立即写入内存。
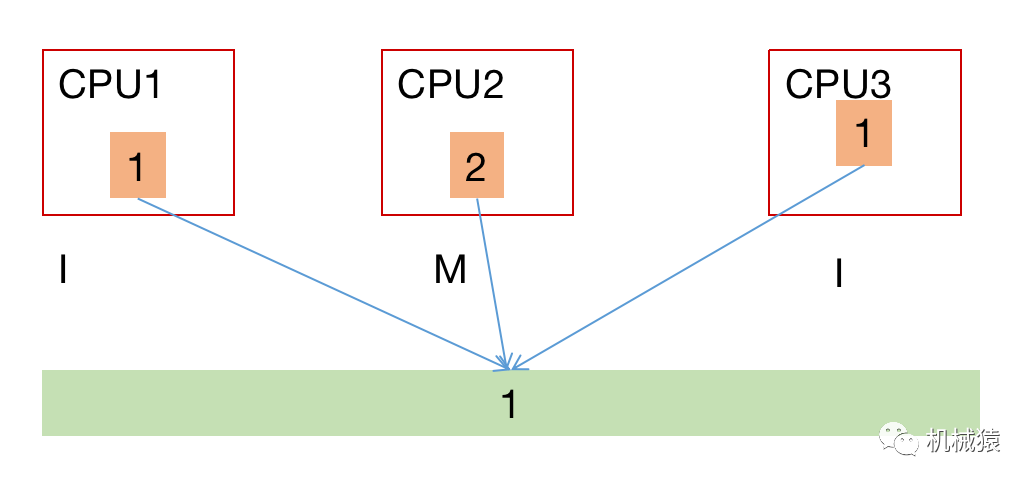
如果CPU1试图读取/写入这条cache line中的数据,由于是invalid状态,于是将触发cache miss(read miss),这个miss信号会被其他持有该缓存的cpu识别到,此时CPU2会把自己cache line的数据回写到内存,然后CPU1从内存读取。然后CPU1和CPU2的cache line都将更新到shared状态(I-->S, M-->S)。
编译器优化和CPU指令重排
编译器会根据自身的一些性能优化策略对代码执行指令重排,也就是编译生成的二进制(机器码)的顺序与源代码可能不同。比如有如下代码:
x++;
y++;虽然y++在x++之后,但是编译器可能会把y++放到x++之前。此外CPU内部也有指令重排,也就是,CPU执行指令的顺序,不一定完全严格按照机器码的顺序。现代CPU的IPC(每时钟执行指令数)一般都远大于1,也就是所谓的多发射,很多命令都是同时执行的。比如,一个CPU核心会有2套以上的整数ALU(加法器),2套以上的浮点ALU(加法器),以及独立的乘法器,独立的Load和Store执行器。Load和Store模块往往还有8个以上的队列,也就是可以同时进行8个以上缓存地址(cache line)的读写交换。
CPU数据读写原子性
了解了cache的一致性之后,再来看看CPU如何原子的改变一个变量的值,即原子操作的函数(API)。
1、单核系统(UP)的原子读/写
在UP系统中,如果CPU仅仅是从内存中读取(read/load)一个变量的值,或者仅仅是往内存中写入(write/store)一个变量的值,都是不可打断,也不可分割的。Linux中实现原子性的读一个变量与原子性的写一个变量的函数分别是atomic_read()和atomic_set()。
2、UP的原子RMW
如果CPU不是简单地读/写一个变量,而是需要修改一个变量的值,那么它首先需要将变量的值从内存读取到寄存器中(read),然后修改寄存器中变量的值(modify),最后将修改后的值写回到该变量所在的内存位置(write),即RMW。如何保证RMW操作的原子性呢?最简单的方法就是关闭中断。不过现代cpu的一些add增强指令能同时完成读和写,不需要关中断。
3、SMP系统的原子RMW
为保证SMP系统中单个CPU的RMW操作也是原子的,不同架构的处理器有不同的实现方式:锁总线、LL/SC指令。
锁总线 (linux)
linux处理器常用的做法是给总线上锁(bus lock),即仲裁器将与内存通信的总线完全分配给某核心,其余cpu核无法通过总线与内存通信。
除了外围设备的一些映射内存,普通的内存都是可以被cpu cache缓存的。对于这类内存,根据cache一致性原理,对应内存的同一位置,不能有2个及以上的CPU的cache line同时处于modified状态。那么只要获得了变量所在的cache line的排他性修改权,就相当于给cache上锁,对应相当于给该块内存上锁,就可以实现SMP系统的RMW原子操作。
所以,锁总线在具体实现时,总线和内存都不会被上锁,bus lock实际上是cache lock。但如果RMW操作的数据体超过一个cache line(64字节),那么这就不是一次cache line操作可以完成的了,cache lock就不够了,只能明确使用bus lock。
LL/SC (arm)
当用LL 指令从内存某个地址取出数据放到寄存器后,CPU会在寄存器中标记一个排他性bit位。在执行SC操作之前,CPU都会检查该标记,失败则重试。
Linux系统自旋锁实现方式
有了前面的铺垫,就可以理解spinlock的实现了。
linux里面有两种同步锁:spinlock与mutex,区别是spinlock不会引起系统睡眠或调度。自旋锁按演进方向有如下四种实现方式。
CAS
通用的无锁实现方式,称为比较并交换,实现方式如下:
function cas(p, old, new)
{
if *p ≠ old
null
else
*p ← new
}CAS实现简单,缺点是无法实现公平调度,没有办法确保在该锁上等待时间最长的那个CPU优先获得锁,也就是会造成系统延迟不确定的问题。
Ticket Spinlock
实现方式如下:
typedef struct spinlock
{
uint32_t head;
uint32_t tail;
} spinlock_t;类似银行的排队叫号系统:
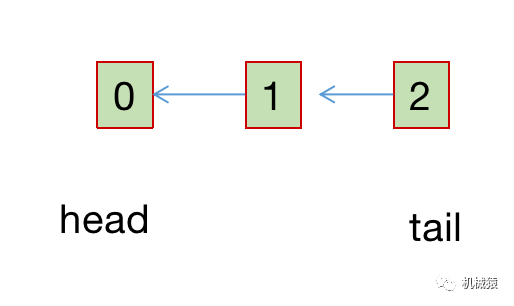
解锁流程:该自旋锁被拥有者将要释放前,该锁的head值会被owner通过原子inc指令加1。
抢锁流程:其他CPU在试图获取这个锁时,先通过原子指令将tail值保存在自己的寄存器中,然后将spinlock的tail值加1(也就是将自己加到了这个等待队列的尾部)。
然后就是指令循环比较,每当spinlock的head值出现变化时,所有试图获取这个spinlock的CPU都需要读取spinlock的内存,刷新该spinlock锁在自己对应的cache line,但最终只有一个CPU可以获得锁,争抢锁的CPU越多,无谓的性能损耗越大,造成惊群效应。
MCS Lock
这种实现方式下每个CPU不是等待同一个spinlock,而是每个CPU均会有一个spinlock变量,因此每个CPU只需要查询自己对应的这个锁变量所在的本地cache line,仅在这个本地CPU变量发生变化的时候,才读取内存和刷新这条cache line。查询的方式就是前面的MSI协议。
实现方式:
typedef struct mcs_spinlock
{
struct mcs_spinlock *next;
int locked;
}mcs_spinlock_t;locked的值为1表示该CPU是spinlock当前的持有者,为0则表示没有持有,next指针用于挂接新到的需要抢锁的CPU。
加锁:先将自身node节点挂接到尾部,然后等待自身locked变为1。
解锁:先将自身node从锁链里摘除,然后将下一节点的locked改写为1,这样下一节点对应的线程就会被唤醒。
使用Ticket Spinlock时所有线程均争抢同一内存值,而MCS lock只关注自身CPU持有的内存值。缺陷是MCS lock相对Ticket Spinlock多了一个指针,无法刷到同一条cache line里面。
Qspinlock
qspinlock继承了MCS lock的CPU争抢隔离和ticket spinlock的单变量优点,实现方式:
typedef struct qspinlock {
atomic_t val;
u16 locked_pending;
u16 tail;
}qspinlock_t;val为一个64bit的变量,分为如下四个部分:

locked值为1表示持有锁,pending为1表示有一个线程在等待持有锁的线程释放锁。
tail index为2bit,因为linux一共有4种上下文:task, softirq, hardirq和nmi,也就是一个CPU最多会试图获取四把自旋锁。
加锁:第一个获取锁的会将locked置为1,第二个获取锁的cpu会将pending置为1,第三个及以后的就需要使用链表等待了,也就是修改tail cpu的值。因为大部分场景只有一到两个CPU获取锁,不需要链表,因此一条cache line就能容纳该锁。
解锁:将locked置1即可。