文章目录
前言
在日常开展渗透测试工作的过程中,经常会看到有些站点的登陆或注册页面有图形验证码,它看上去明明是那么简单而纯粹,可以使用自动化识别工具识别出验证码的值,可是我手头上却没有一个趁手的工具能将它识别出来,从而导致错过了多个验证码设计缺陷漏洞。因此,为了给程序员多争取一些加班的机会,决定自己亲自动手写一个。
读者在充分理解本文代码和逻辑后,可以在此基础上进行改写,以开发出功能更加丰富的程序,比如burp验证码识别插件等。
对于本文的程序运行逻辑本人限于精力有限无法深度优化,如果有什么建议,期待读者能在评论区留下您宝贵的意见。
一、准备工作
(一)Tesseract-OCR工具下载和安装
先来一波名词扫盲:
OCR(Optical Character Recognition):光学字符识别,是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测内容中暗、亮的分布情况确定其形状,然后用预定的识别方法将形状翻译成对应字符的过程。
Tesseract:开源的OCR识别引擎,初期Tesseract引擎由HP实验室研发,后来贡献给了开源软件业,现由Google进行改进、修改、优化和发布。
该工具可以通过jTessBoxEditor工具进行针对性训练以提高识别的准确率,但就目前而言,我们可以采用简单的解决办法以避免繁琐的训练过程,就是通过编写代码多次调用这个工具去识别并对识别结果做一个校验。
Tesseract-OCR工具下载地址1:
https://github.com/tesseract-ocr/tesseract
Tesseract-OCR工具备用下载地址:
https://pan.baidu.com/s/11ToSFbsqRNrbVDH-EYW7zg?pwd=6hxp
提取码:6hxp
也可以百度自行查找下载,网上有很多。
该工具下载好以后,直接安装即可,但尽可能保证安装路径不要出现中文。
安装完毕后,会见到如下页面:
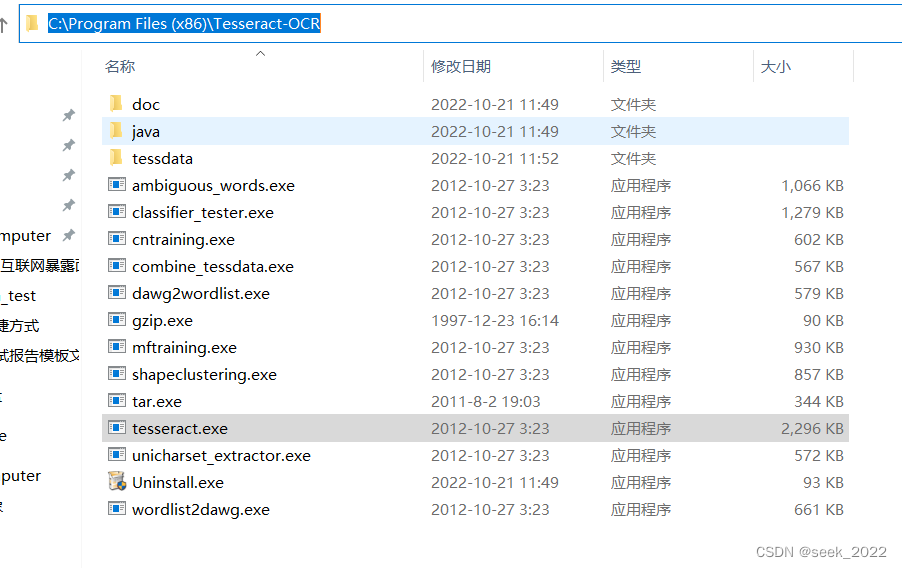
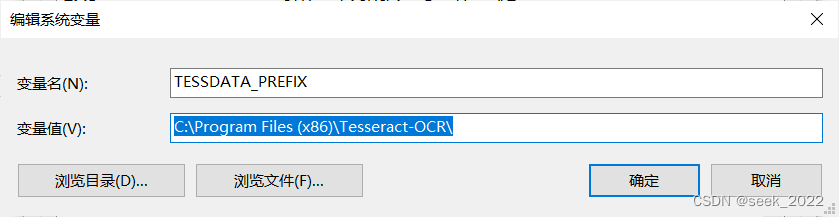
将该路径添加到环境变量中,可以加到PATH中,也可以自己新建一个,像这样(名字随便取,windows会自己去找):
(二)pip更换国内源
如果你已经更换过或者打算手动下载安装本文提到的库,那么这个步骤可以省略了。本文涉及的某些库比较大,不更换国内源的话,一来下载速度很慢,二是下载时容易中断,何必自找麻烦呢?直接更换国内源就可以了。
在命令行输入(这里使用的是清华源):
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
国内其他常用源:
阿里云:
http://mirrors.aliyun.com/pypi/simple/
豆瓣:
http://pypi.douban.com/simple/
中国科学技术大学:
http://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学:
http://pypi.hustunique.com/
(三)安装python第三方库
大家可能会觉得,第三方库嘛,给我个库名,随便pip安装就可以了,如果是这样,那你就陷入了惯性思维的误区。实际上很多时候第三方库也要看它的版本是否符合你的代码,有些库需要本地其他文件的支持,需要手动修改才能使用,盲目安装会出现各种莫名其妙的报错,解决起来非常棘手。
下面介绍一下各个库的安装和需要注意的点,新手对python的认识过于粗浅,一定会觉得,不就是装几个库吗,怎么啰里啰嗦,但随便一个细节不注意,就要debug半天,这正是在帮你提前规避可能出现的问题,老司机应该都懂的,嘻嘻嘻。
1、多版本python导致的pip命令冲突问题
如果电脑上安装了多个python版本,则首先需要明确你使用pip命令时是在给哪个版本的python安装,之后编辑器如果使用的不是相应版本的python,则会导致找不到这个库,而报错
如果有这种问题,可以参考我的情况:
我电脑上装了一个python3.10,python2.7另外还装了一个anaconda,python版本为3.9.7,因此执行pip命令时容易出问题,导致不知道用的是哪个python。
我的解决办法是,在python3.10.1的安装目录中,把python.exe改成python3.exe,在python2.7的安装目录中,将python.exe改为python2.exe,这样在命令行中使用python3即可访问到3.10版本的python,而直接输入python,则打开的是anaconda自带的python3.9.7。
这样直接使用pip命令就是在给anaconda装相应的库,要给python3.10.1装库的话,可以使用如下命令:
python3 -m pip install 库名
同理,python2安装库则使用如下命令(应该没什么人会给python装库吧?):
python2 -m pip install 库名
还有一种方法,直接利用windows读取环境变量时的特性也可以巧妙解决pip命令冲突的问题:
首先查看环境变量中PATH的值(系统变量还是用户变量,你具体打开看,有python相关的内容就可以):
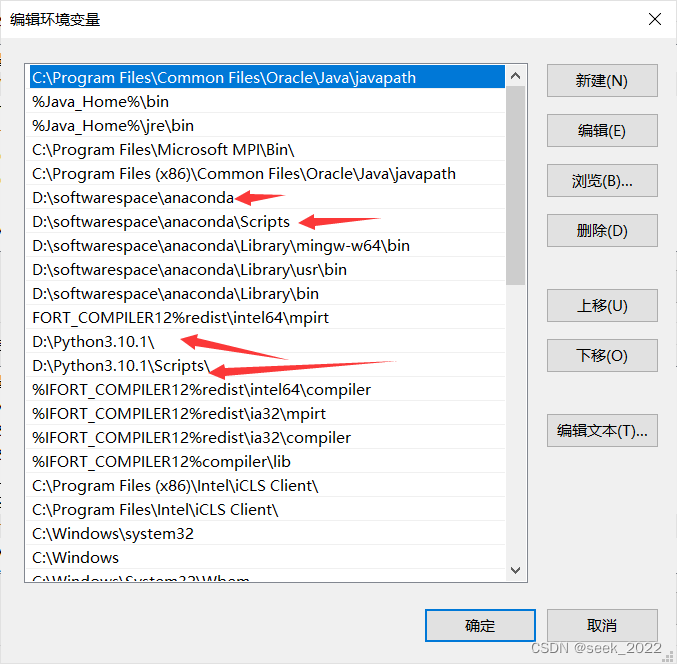
本地搜索pip.exe,可以看到如下内容:

看到pip.exe是在python安装目录下的Scripts目录,而该目录已经在环境变量中我们已经看到了。当我们在命令行输入pip时,系统就会在环境变量中按顺序从上到下去找,然后运行找到的第一个符合条件的文件,因此只要调整环境变量中,Scripts目录的相对位置(通过上移和下调改变该目录的位置),就可以在不修改任何python.exe文件名的情况下,随心所欲使用指定的pip.exe了。
2、selenium
selenium库目前最新应该是4.5版本了,使用selenium库一定要注意某些旧属性或者方法被弃用的问题。比如,find_element_by_xpath方法在新版本已经被弃用,旧版中使用时也会出现该方法即将被弃用的警告。具体从哪个版本开始弃用我也不清楚,经过测试,4.3和4.5版本肯定是用不了这个方法了。替代的写法是:
find_element(BY.XPATH,目标xpath值)
由于对新版selenium库相对旧版所做的改动不太清楚,因此保险起见,我使用了旧版的selenium,因此使用如下命令安装selenium:
pip install selenium==3.3.0
3、pillow
pillow模块是基于PIL模块进行二次开发的,因为PIL模块本身很早就停止开发了,但pillow库不是python内置的库,因此需要单独安装一下:
pip install pillow
这个库很重要,安装完后,最好检查一下,在命令行输入:
from PIL import Image
若无报错,则表示安装成功,如下所示:

4、cv2
CV2指的是OpenCV2(Open Source Computer Vision Library),是一个开源的计算机视觉库。它有很强大的图片处理功能,内置了很多图像处理和计算机视觉方面的通用算法。
注意:安装的时候要安装opencv_python,但在导入使用的时候使用cv2。
使用这个库需要注意版本的问题。截止2022年11月5日,最新版为4.6.0.66,通过测试会发现,以脚本方式运行时,最新版和python3.9.7兼容,但打包成exe文件后运行,出现各种报错,根据网上的文章尝试了各种解决办法,未果。最后看到有个大佬说该库需要根据相应的python版本来安装,于是我根据当前使用的python3.9.7版本,通过以下命令安装opencv-python(直接使用库名安装,会安装为最新版,所以直接指定版本):
pip install opencv-python==4.5.1.48
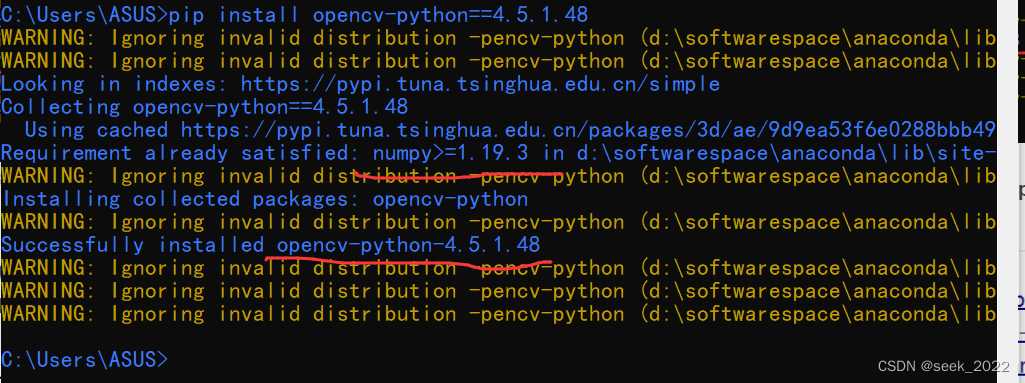
可以看到装这个库的同时也会自动下载numpy库,因此后面不需要单独再装这个库。
如果不知道自己的python需要使用哪个相应版本的opencv-python,可以访问下列链接:
https://www.lfd.uci.edu/~gohlke/pythonlibs/#opencv
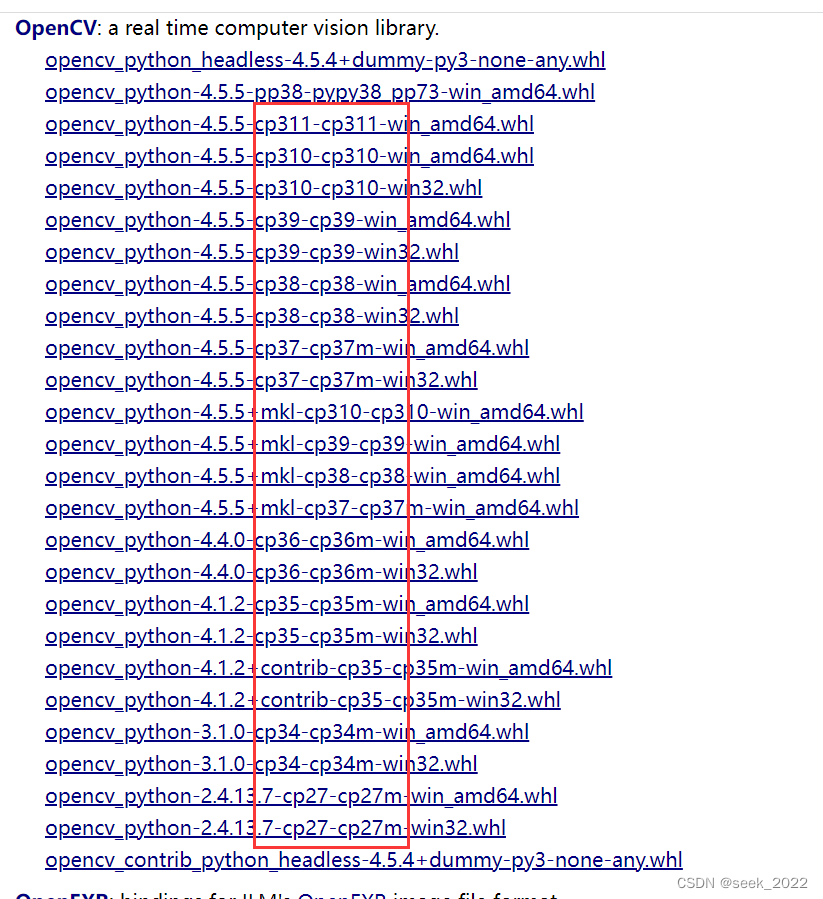
注意图中cp后面的两位数,表示python的版本,比如cp39就表示python3.9系列的版本,可以直接下载相应的whl文件,在本地进行安装,例如下载4.5.5版本的opencv-python,本地路径为:
E:\python_test\opencv_python-4.5.5-cp39-cp39-win_amd64.whl
则pip中安装命令为:
pip install "E:\python_test\opencv_python-4.5.5-cp39-cp39-win_amd64.whl"
安装完毕后在python的编辑器中输入:
import cv2
print(cv2.__version__)
看到版本信息即表示指定版本已经安装成功:

5、pytesseract
这个库的安装比较简单,直接输入:
pip install pytesseract
由于之前已经设置好环境变量,这里可以不用改任何配置,但是如果想要在别人的电脑上也能运行这个程序,可以采用两种解决办法:
- 第一种:目标电脑也安装Tesseract-OCR工具并也配置好环境变量(具体哪个安装目录都可以,最好不要出现中文路径);
- 第二种:把安装好的Tesseract-OCR工具直接整个文件夹放在程序的根目录下,然后在python的Lib\site-packages\pytesseract目录下找到pytesseract.py并打开:

在第30行代码处直接指定一个相对路径(切勿使用绝对路径,否则离开了本机的环境,程序就找不到该文件了):Tesseract-OCR\tesseract.exe:
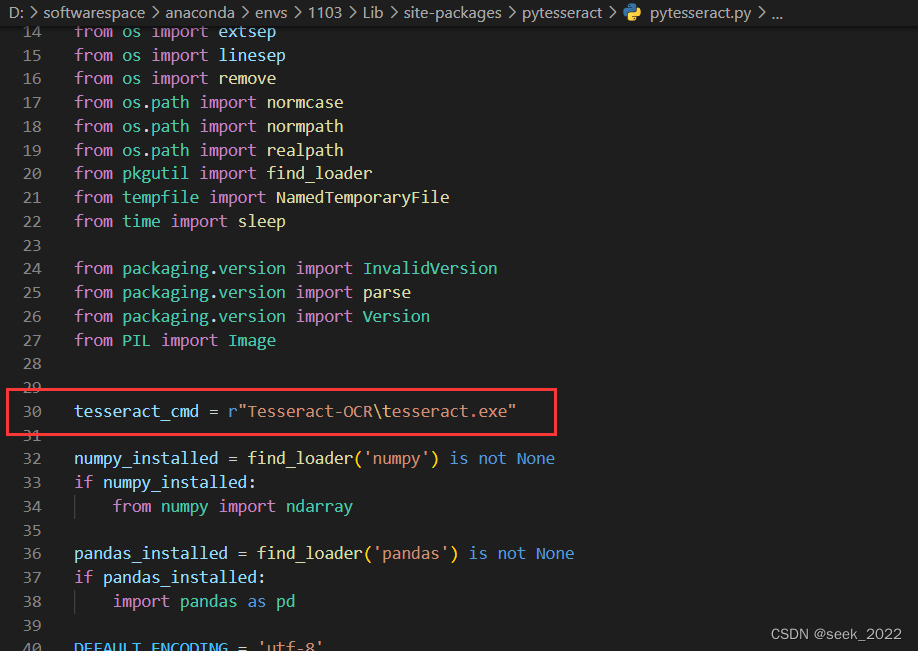
这样以后直接在打包后的dist文件夹里放入Tesseract-OCR文件夹。这样程序就不需要依赖环境变量了,直接在任意windows系统上都可以运行了。
6、PySimpleGUI
这个库直接使用pip命令安装最新版就可以:
pip install PySimpleGUI
(四)安装谷歌浏览器驱动
首先确定谷歌浏览器的版本:
打开Chrome 浏览器,依次点击浏览器右上角的 三个点 - 帮助 - 关于 Google Chrome

接着访问以下地址:https://registry.npmmirror.com/binary.html?path=chromedriver
里面有很多版本的驱动,其中可能没有准确对应我们浏览器版本的驱动,选择最接近的版本即可。
然后 Windows 系统下载里面的chromedriver_win32.zip 文件,MacOS 下载 chromedriver_mac64.zip
将下载好的 chromedriver 解压缩,Windows 系统得到 chromedriver.exe,MacOS 得到 chromedriver,这个就是我们需要的浏览器驱动。直接将它放到 Python 所在安装目录里即可。
二、思路梳理和各模块源码
大家常常会觉得,编写程序代码层面是最难的,其实我觉得代码层面根本提不到什么难字的,真正难的都是在逻辑思维层面,也就是一个问题该如何解决,解决的具体步骤是什么。思路理清楚了以后,最后才是到写代码的层面,因此梳理思路是最重要的一个步骤。
卡耐基梅隆大学计算机教授 Jeannette Wing 曾经提出 编程思维(Computational Thinking)的概念,可以总结为如下四点:
- 问题分解: 把现实生活中的复杂问题,逐步拆分成容易解决的小问题;
- 模式识别: 根据已有的知识和经验,找出新问题和以前解决过的问题的相似性;
- 抽象思维: 将问题里涉及的数据抽象到数据结构(变量、列表、字典等),把数据处理过程可重复执行部分抽象成函数;
- 算法设计: 根据前三步的分析成果,设计步骤,写出算法,从而解决问题。
在我们这个程序里,首先需要将功能分解为几个大的部分,明确每个部分解决什么问题,然后
先找到系统的核心功能(验证码识别),作为编程的入手点,满足最基本的需求,然后再逐步迭代优化,让程序变得越来越智能,越来越完整,最后加入图形化界面,进而实现程序的打包和发布。
(一)辅助模块一(vcodeIden)
验证码识别是整个程序的核心,需要单独放在一个模块中。
这里我画了一个思维导图:

源码如下:
import cv2
import numpy as np
import pytesseract
from PIL import Image
import time
import os
def convert_to_bw(image_path):
'''将验证码由彩色图片变成黑白图片,bw分别表示black和white,调用时需要传参验证码图片的路径'''
# imread()有三个参数,其中0表示以灰度模式加载图片,1表示以彩色模式加载图片,-1表示透明度通道,一般用不到
image = cv2.imread(image_path, 0)
# 图片二值化,127为阀值,255为最大值,1表示这里采用什么类型的算法,该算法规定了当前坐标点的像素值大于阈值时,设置为0,也就是黑色,否则设置为最大值,也就是这里的255,对应的是白色。
#注意这里的算法类型1如果改为0,则表示当前坐标点像素值大于阈值时,将该点像素设置为这里的最大值255,否则设置为0。
ret, image = cv2.threshold(image, 127, 255, 0)
#关于接下去如何返回需要的图片对象,有两种写法,先看第一种(cv2库保存图片的语法为:cv2.imwrite(filename, image对象)):
# t = int(time.time())
# image_path=rf"{folder}\{t}.png"
# cv2.imwrite(image_path, image)
# img = Image.open(image_path)
#再看第二种写法(也是我个人推荐的写法,这样可以减少一次对磁盘的读写,且不占用额外的磁盘空间):
img= Image.fromarray(np.uint8(image))
return img
def clear_noise(img):
'''此函数完成图片降噪操作,调用时传参应为Image类型的图片对象'''
x, y = img.width, img.height
for i in range(x):
for j in range(y):
#注意图片对象一共只有两种颜色,非黑即白,降噪是为了去除孤立的黑点
#计算每个点和周边点像素值之和的平均值,如果是接近黑色,保持不变,如果接近白色,就改为白色
if sum_9_region(img, i, j) >127:
# 改变像素点颜色,白色
img.putpixel((i, j), 255)
return img
def sum_9_region(img, x, y):
"""
单坐标点田字格周边降噪处理,代码量较大,单独拉出来重构
具体处理思路:
1、函数接收一个图片对象和一个坐标点,将本点和周边紧挨着的坐标点的RGB值求和并取平均值;
2、函数不参与任何判断,只返回计算结果;
"""
# 获取当前像素点的颜色值
cur_pixel = img.getpixel((x, y))
width = img.width
height = img.height
if cur_pixel == 255: # 如果当前点为白色点,则直接返回255
return 255
if y == 0: # 第一行
if x == 0: # 第一行的左上顶点,3个邻近点
# 附近3个点
sum_top_left = cur_pixel + img.getpixel((x, y + 1)) + img.getpixel((x + 1, y)) + img.getpixel((x + 1, y + 1))
return sum_top_left / 255
elif x == width - 1: # 右上顶点,有3个邻近点
sum_top_right = cur_pixel + img.getpixel((x, y + 1)) + img.getpixel((x - 1, y)) + img.getpixel((x - 1, y + 1))
return sum_top_right / 255
else: # 最上非顶点,5个邻近点
sum_top_middle = img.getpixel((x - 1, y)) + img.getpixel((x - 1, y + 1)) + cur_pixel + img.getpixel((x, y + 1)) + img.getpixel((x + 1, y)) + img.getpixel((x + 1, y + 1))
return sum_top_middle / 255
elif y == height - 1: # 最下面一行
if x == 0: # 左下顶点
# 有3个邻近点
sum_botton_left = cur_pixel + img.getpixel((x + 1, y)) + img.getpixel((x + 1, y - 1)) + img.getpixel((x, y - 1))
return sum_botton_left / 255
elif x == width - 1: # 右下顶点,有3个邻近点
sum_botton_right = cur_pixel + img.getpixel((x, y - 1)) + img.getpixel((x - 1, y)) + img.getpixel((x - 1, y - 1))
return sum_botton_right / 255
else: # 最下非顶点,5个邻近点
sum_botton_middle = cur_pixel + img.getpixel((x - 1, y)) + img.getpixel((x + 1, y)) + img.getpixel((x, y - 1)) + img.getpixel((x - 1, y - 1)) + img.getpixel((x + 1, y - 1))
return sum_botton_middle / 255
else: # y不在边界
if x == 0: # 左边非顶点
sum_left_middle = img.getpixel((x, y - 1)) + cur_pixel + img.getpixel((x, y + 1)) + img.getpixel((x + 1, y - 1)) + img.getpixel((x + 1, y)) + img.getpixel((x + 1, y + 1))
return sum_left_middle / 255
elif x == width - 1: # 右边非顶点
sum_right_middle = img.getpixel((x, y - 1)) + cur_pixel + img.getpixel((x, y + 1)) + img.getpixel((x - 1, y - 1)) + img.getpixel((x - 1, y)) + img.getpixel((x - 1, y + 1))
return sum_right_middle / 255
else: # 不在矩形四个角、不在边界线上的所有坐标点都有8个邻近点
sum_middle = img.getpixel((x - 1, y - 1)) + img.getpixel((x - 1, y)) + img.getpixel((x - 1, y + 1)) + img.getpixel((x, y - 1)) + cur_pixel + img.getpixel((x, y + 1)) + img.getpixel((x + 1, y - 1)) + img.getpixel((x + 1, y)) + img.getpixel((x + 1, y + 1))
return sum_middle / 255
def rec_vcode(path):
'''此模块的主函数,传参内容应为验证码图片所处的路径'''
#将验证码图片转为黑白图片
img = convert_to_bw(path)
#去除图片中的干扰点
img=clear_noise(img)
#识别验证码,并将首尾多余的空格去除
text = pytesseract.image_to_string(img).strip()
time.sleep(1)
t=int(time.time())
#保存图片。用os模块获取验证码所在的文件夹名称,返回的结果是一个列表,由文件夹和文件名组成,第一个就是文件夹,其次是文件名,取第一个作为目录
img.save(rf'{
os.path.split(path)[0]}\t.png')
return text
为什么不能直接返回cv2的图片对象呢,单独解释一下:
Image.open()得到的img数据类型是一个Image对象,并不是普通的列表,而cv2.imread()得到的img数据类型是np.array()类型,如果用print把该对象输出,可以看到一个列表,因此不具有高度和宽度的属性,而后面我们降噪处理时需要遍历所有的像素点,这就需要知道图片的长度和宽度用来控制循环的上限,因此需要先将np.array()类型的图片保存并以Image库来打开该图片,或者将cv2库读取的图片转化为Image对象。
把numpy.ndarray对象转化为Image对象的两种方法:
第一种:
img = cv2.imread(path)
img_Image = Image.fromarray(np.uint8(img))
第二种:
直接保存numpy.ndarray图片对象,再用 Image.open() 去打开,例如:
image = cv2.imread(image_path, 0)
cv2.imwrite(save_path, image)
image = Image.open(save_path)
反过来也是可以的,把Image对象转化为np.adarray对象:
第一种方法:
img = Image.open(path)
img_array = np.array(img)
第二种方法:
img = Image.open(path)
img.save(save_path)
image = cv2.imread(image_path, 0)
(二)辅助模块2(CodeDemo)
这个模块采用面向对象编程,画了一个思维导图如下:

源代码:
import time
from selenium import webdriver
from PIL import Image
import vcodeIden
class Recognition:
'''初始化程序基本设置,为了保证程序编译一次可长期使用,应通过传参的形式对某些变量进行赋值'''
def __init__(self,save_path,image_xpath,url,count,vcode_length,text_list):
#验证码保存路径
self.save_path=save_path
#验证码xpath定位
self.image_xpath=image_xpath
#目标网址
self.url=url
#初始化浏览器,将窗口最大化
self.browser=webdriver.Chrome()
self.browser.get(self.url)
self.browser.maximize_window()
#验证码识别失败时的重复尝试次数
self.count=int(count)
#验证码的合理长度
self.vcode_length=int(vcode_length)
#验证码内容的合理范围
self.text_list=text_list
#设置一个存储验证码的全局变量
self.text=''
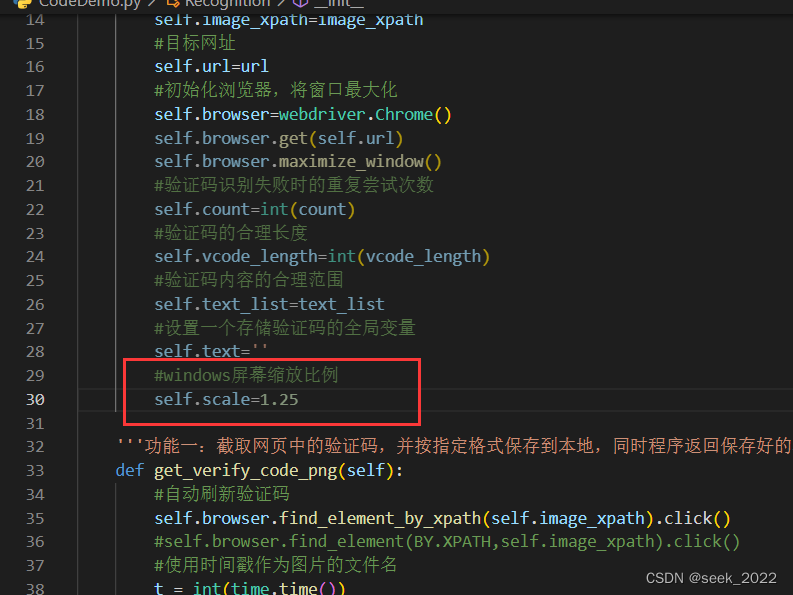
#windows屏幕缩放比例
self.scale=1.25
'''功能一:截取网页中的验证码,并按指定格式保存到本地,同时程序返回保存好的验证码图片路径'''
def get_verify_code_png(self):
#自动刷新验证码
self.browser.find_element_by_xpath(self.image_xpath).click()
#也可以这么写:self.browser.find_element(BY.XPATH,self.image_xpath).click()
#使用时间戳作为图片的文件名
t = int(time.time())
time.sleep(1)
self.save_screenshot_path=rf"{
self.save_path}\{
t}.png"
#网页截图
self.browser.save_screenshot(self.save_screenshot_path)
image_location=self.browser.find_element_by_xpath(self.image_xpath)
location= image_location.location
size = image_location.size
#根据windows缩放比例修改坐标值
coderange=(
int(location['x']*self.scale),
int(location['y']*self.scale),
int((location['x']+size['width'])*self.scale),
int((location['y']+size['height'])*self.scale)
)
image= Image.open(self.save_screenshot_path)
#按验证码所处的范围截取指定区域
im=image.crop(coderange)
t = int(time.time())
verify_code_path=rf"{
self.save_path}\{
t}.png"
im.save(verify_code_path)
return verify_code_path
'''功能二、识别验证码'''
def get_vcode(self):
vcode_path=self.get_verify_code_png()
text=vcodeIden.rec_vcode(vcode_path)
return text
'''功能三、判断验证码是否识别成功'''
def judge_vcode(self,result):
while True:
self.count-=1
if self.count <=0:
break
else:
self.text=self.get_vcode()
if self.text=='':
continue
else:
text_update=self.text
self.text=''
for i in text_update:
if i in self.text_list:
self.text+=i
if len(self.text)==self.vcode_length:
result=True
break
else:
continue
return result
'''功能四、验证码识别主函数'''
def main(self):
result=False
result=self.judge_vcode(result)
#根据结果判断验证码识别是否成功
if result:
print(f'验证码识别成功,为:{
self.text}')
else:
self.text='验证码识别失败!'
self.browser.quit()
return self.text
这个模块的代码相对简单,大家直接看注释就可以了,需要提一下的是,windows缩放比例会影响浏览器打开页面后的内容,元素的坐标也会有变化,如不处理会导致坐标错乱。可以在设置中查看windows的缩放比例,比如:
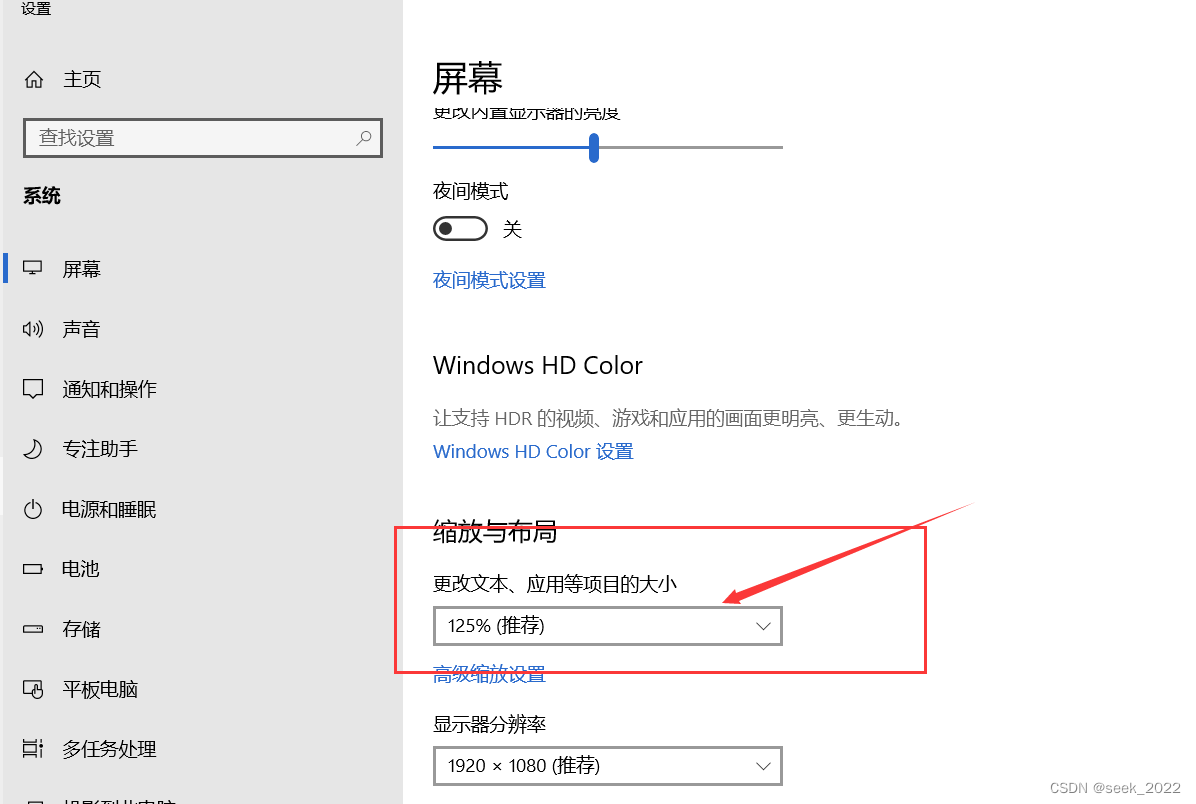
那么我在程序中就需要设置self.scale的值为1.25
(三)UI界面(程序入口)
这个模块实际上叫什么名都可以,因为只有它调用别人,没人调用它。但是名字还是尽量起的有意义一点,让人一看就懂,我给它起名为GUI。
画了个思维导图如下:

这里用的库是PySimpleGUI,具体用哪个库可以随你们喜好,UI库的用法我就不多写了,文末会附上该库的参考文章。
源码如下:
import PySimpleGUI as sg
from CodeDemo import Recognition
import time
# sg.change_look_and_feel('LightBlue6')
layout = [
[sg.Text("目标URL:",font=('宋体',15),text_color='#000000'),sg.InputText("",key='url',size=(60,5),font=('宋体',15))],
[sg.Text('验证码保存路径:',font=('宋体',15),text_color='#000000'),sg.InputText(r"E:\python_test\verification_code",key='save_path',size=(52,5),font=('宋体',15))],
[sg.Text('验证码定位(xpath):',font=('宋体',15),text_color='#000000'),sg.InputText("",key='xpath',size=(52,5),font=('宋体',15))],
[sg.Text('验证码的长度(默认为4):',font=('宋体',15),text_color='#000000'),sg.InputText("4",key='length',size=(5,5),font=('宋体',15))]+
[sg.Text('识别失败时的重试次数:',font=('宋体',15),text_color='#000000'),sg.InputText("10",key='try',size=(5,5),font=('宋体',15))],
[sg.Text('识别结果的合理范围:',font=('宋体',15),text_color='#000000'),sg.InputText('0123456789',key='content',size=(30,5),font=('宋体',15)),sg.Button('纯数字',key='number',font=('宋体',15))]+
[sg.Button('数字+字母',key='number_letter',font=('宋体',15))],
[sg.Button('开始识别',key='begin',font=('宋体',20)),sg.Text('识别结果:',font=('宋体',20),text_color='#000000'),sg.Text('',key='result_code', tooltip='识别结果',font=('宋体',20),text_color='#FF0000')]+
[sg.Button('退出',key='exit',font=('宋体',20))]
]
#保持窗口最前
gui=sg.Window("网页图形验证码本地识别工具",layout,keep_on_top=True)
while True:
event,values=gui.read()
if event == None:
break
if event=='number':
gui['content'].update('0123456789')
if event=='number_letter':
gui['content'].update('0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ')
if event=='begin':
save_path=values['save_path']
image_xpath=values['xpath']
url=values['url']
count=values['try']
vcode_length=values['length']
text_list=values['content']
#所有的值都不应为空,否则不应实例化Recognition()
if save_path=='' or image_xpath=='' or url=='' or count=='' or vcode_length=='' or text_list=='':
sg.popup('所有的值都必须填写!否则无法开始识别!',title='有信息未填写!',non_blocking=True)
else:
try:
main=Recognition(save_path,image_xpath,url,count,vcode_length,text_list)
code=main.main()
gui['result_code'].update(code)
except:
gui['result_code'].update('识别过程意外中止了!')
if event == 'exit':
break
time.sleep(0.1)
#跳出循环后关闭界面
gui.close()
程序界面:
这里不方便公布测试网址来测试,大家自行测试了哈。请看测试结果:
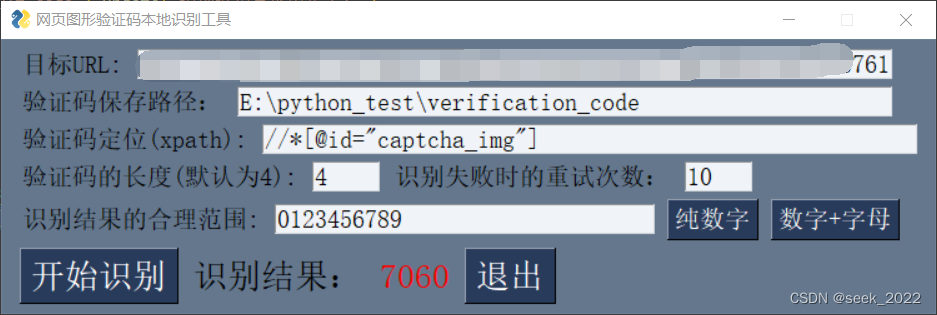
验证码原始图片:

处理结果:

可以看到程序已经成功识别目标验证码。
三、程序打包与发布
当上述源码在本地运行调试完毕后,就可以打包发布了。
首先检查工作目录下三个模块是否都在一起:
然后找到Tesseract-OCR工具的安装目录,将整个文件夹复制到工作目录中:
尽管我们只使用了几个模块,但打包时,程序会自动将所有模块(包括自带和第三方全部模块)统统打包,因此直接打包的话,文件会很大。为了避免出现这个问题,首先在开始菜单中找到AnacondaPrompt(anaconda) 选项,接着在打开的命令行窗口中依次执行以下命令:
#创建虚拟环境,指定虚拟环境的名字和python版本
conda create -n 1103 python==3.9
#激活虚拟环境
conda activate 1103
#只安装当前python程序涉及的模块
pip install PySimpleGUI
pip install pyinstaller
pip install selenium==3.3.0
pip install pytesseract
pip install opencv-python==4.5.1.48
pip install pillow
#先关闭虚拟环境
conda deactivate
现在,在anaconda的根目录中,依次展开以下文件夹:
envs\1103\Lib\site-packages\pytesseract
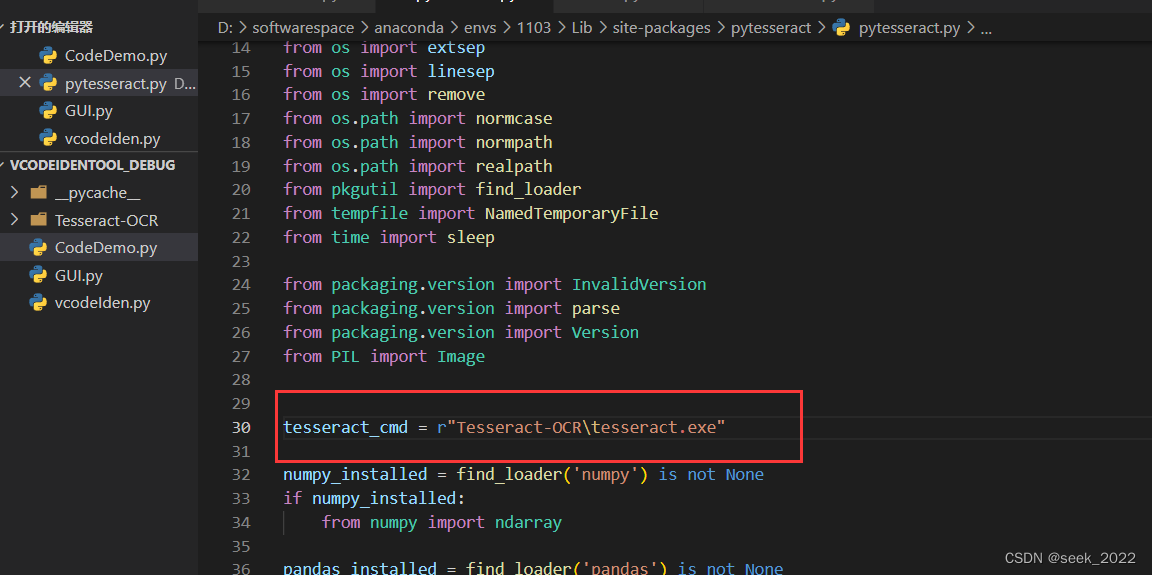
打开pytesseract.py文件,定位到第30行代码:
用这行代码替换掉原始代码
tesseract_cmd = r"Tesseract-OCR\tesseract.exe"
如图所示:
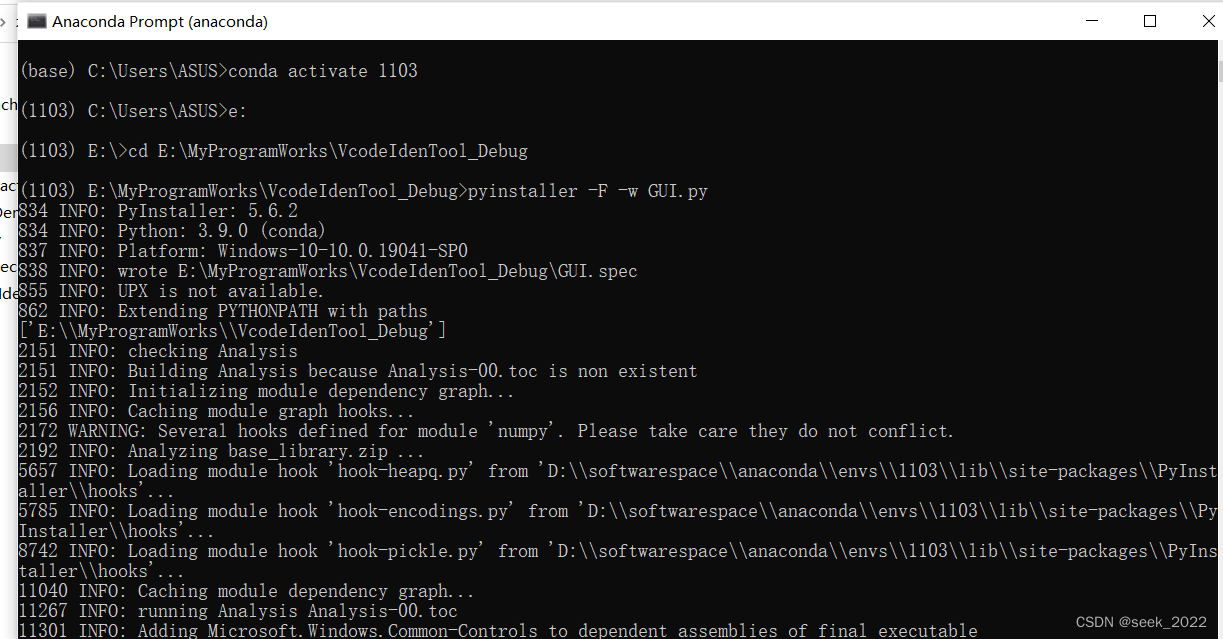
接着继续在开始菜单中找到**AnacondaPrompt(anaconda)**选项,打开,并依次输入如下命令:
conda activate 1103
#切换文件目录(我的目录是E:\MyProgramWorks\VcodeIdenTool_Debug)
e:
cd E:\MyProgramWorks\VcodeIdenTool_Debug
#使用pyinstaller进行打包,w是小写,不显示命令行窗口,程序打包为一个文件
pyinstaller -F -w GUI.py
#最后退出虚拟环境
conda deactivate 1103
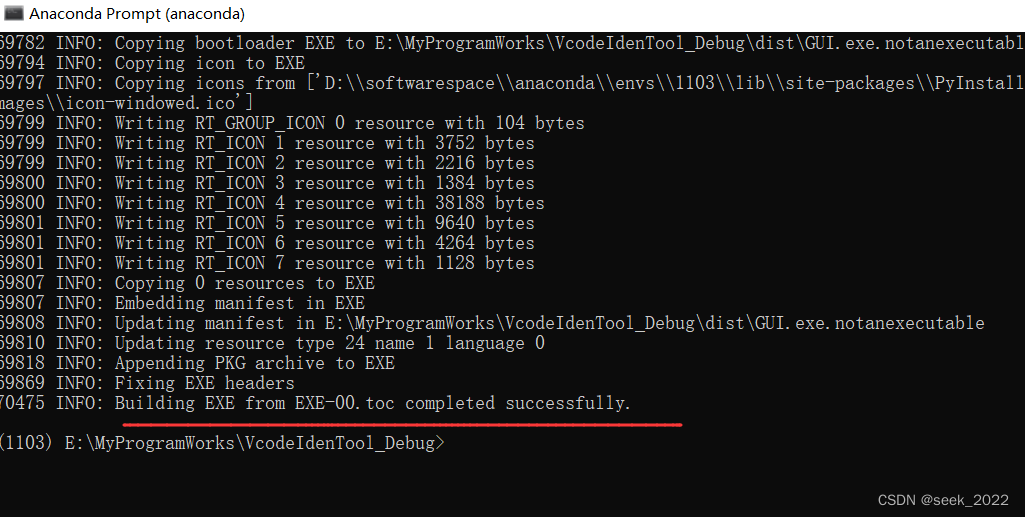
完毕:
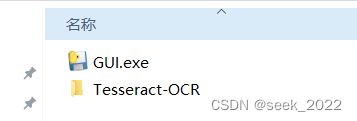
打包完成后,在dist文件夹里会生成一个GUI.exe文件,此时把Tesseract-OCR复制到这个文件夹中:
接着修改一下图标,你们用什么工具都可以,我这里用Restorator 2018来改,该工具的下载地址为:
https://pan.baidu.com/s/1hVAwsUHIgJVrh6TR0TFOyA?pwd=c6dy
提取码:c6dy
这个工具的使用也比较简单,我就不多说了,给你们看最终的效果:

到此,此工具的开发和打包发布的流程已经全部结束,现在这个工具已经可以摆脱本机的环境,在其他windows上独立运行了。
本程序目前还没有经过大量的测试,对于可能出现的bug,大家可以自行测试,有问题可在评论区与我交流,谢谢!
四、本文参考链接
Tesseract-OCR相关名词解释:https://www.jianshu.com/p/3326c7216696
cv2库介绍:https://blog.csdn.net/cnds123/article/details/126547307
PySimpleGUI库介绍:https://blog.csdn.net/W295723987/article/details/126611877?spm=1001.2014.3001.5506
pytesseract使用问题解决方案:https://blog.csdn.net/weixin_41644725/article/details/95344924?spm=1001.2014.3001.5506