第三百二十五节,web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
标签选择器对象
HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象
需要导入模块:from scrapy.selector import HtmlXPathSelector
select()标签选择器方法,是HtmlXPathSelector里的一个方法,参数接收选择器规则,返回列表元素是一个标签对象
extract()获取到选择器过滤后的内容,返回列表元素是内容
选择器规则
//x 表示向下查找n层指定标签,如://div 表示查找所有div标签
/x 表示向下查找一层指定的标签
/@x 表示查找指定属性,可以连缀如:@id @src
[@class=“class名称”] 表示查找指定属性等于指定值的标签,可以连缀 ,查找class名称等于指定名称的标签
/text() 获取标签文本类容
[x] 通过索引获取集合里的指定一个元素
获取指定的标签对象
# -*- coding: utf-8 -*-
import scrapy #导入爬虫模块
from scrapy.selector import HtmlXPathSelector #导入HtmlXPathSelector模块
from urllib import request #导入request模块
import os
class AdcSpider(scrapy.Spider):
name = 'adc' #设置爬虫名称
allowed_domains = ['www.shaimn.com']
start_urls = ['http://www.shaimn.com/xinggan/']
def parse(self, response):
hxs = HtmlXPathSelector(response) #创建HtmlXPathSelector对象,将页面返回对象传进去
items = hxs.select('//div[@class="showlist"]/li') #标签选择器,表示获取所有class等于showlist的div,下面的li标签
print(items) #返回标签对象
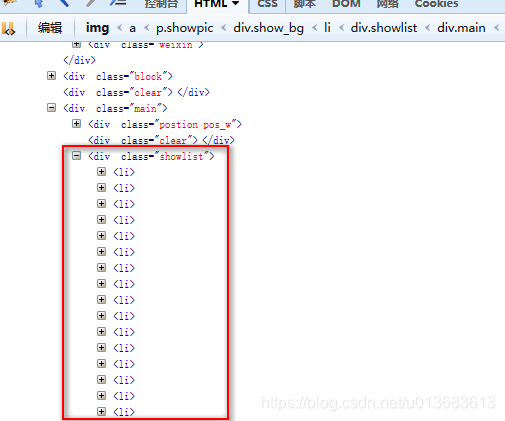

循环获取到每个li标签里的子标签,以及各种属性或者文本
# -*- coding: utf-8 -*-
import scrapy #导入爬虫模块
from scrapy.selector import HtmlXPathSelector #导入HtmlXPathSelector模块
from urllib import request #导入request模块
import os
class AdcSpider(scrapy.Spider):
name = 'adc' #设置爬虫名称
allowed_domains = ['www.shaimn.com']
start_urls = ['http://www.shaimn.com/xinggan/']
def parse(self, response):
hxs = HtmlXPathSelector(response) #创建HtmlXPathSelector对象,将页面返回对象传进去
items = hxs.select('//div[@class="showlist"]/li') #标签选择器,表示获取所有class等于showlist的div,下面的li标签
# print(items) #返回标签对象
for i in range(len(items)): #根据li标签的长度循环次数
title = hxs.select('//div[@class="showlist"]/li[%d]//img/@alt' % i).extract() #根据循环的次数作为下标获取到当前li标签,下的img标签的alt属性内容
src = hxs.select('//div[@class="showlist"]/li[%d]//img/@src' % i).extract() #根据循环的次数作为下标获取到当前li标签,下的img标签的src属性内容
if title and src:
print(title,src) #返回类容列表
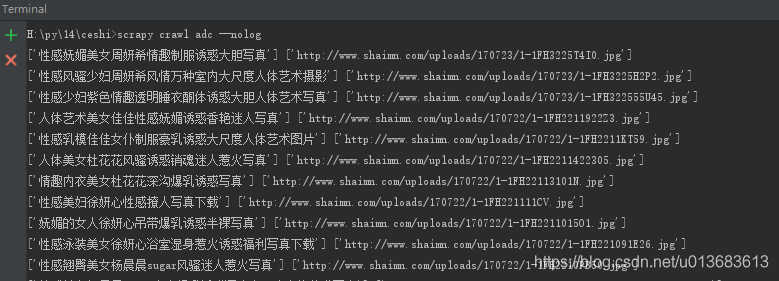
将获取到的图片下载到本地
urlretrieve()将文件保存到本地,参数1要保存文件的src,参数2保存路径
urlretrieve是urllib下request模块的一个方法,需要导入from urllib import request
# -*- coding: utf-8 -*-
import scrapy #导入爬虫模块
from scrapy.selector import HtmlXPathSelector #导入HtmlXPathSelector模块
from urllib import request #导入request模块
import os
class AdcSpider(scrapy.Spider):
name = 'adc' #设置爬虫名称
allowed_domains = ['www.shaimn.com']
start_urls = ['http://www.shaimn.com/xinggan/']
def parse(self, response):
hxs = HtmlXPathSelector(response) #创建HtmlXPathSelector对象,将页面返回对象传进去
items = hxs.select('//div[@class="showlist"]/li') #标签选择器,表示获取所有class等于showlist的div,下面的li标签
# print(items) #返回标签对象
for i in range(len(items)): #根据li标签的长度循环次数
title = hxs.select('//div[@class="showlist"]/li[%d]//img/@alt' % i).extract() #根据循环的次数作为下标获取到当前li标签,下的img标签的alt属性内容
src = hxs.select('//div[@class="showlist"]/li[%d]//img/@src' % i).extract() #根据循环的次数作为下标获取到当前li标签,下的img标签的src属性内容
if title and src:
# print(title[0],src[0]) #通过下标获取到字符串内容
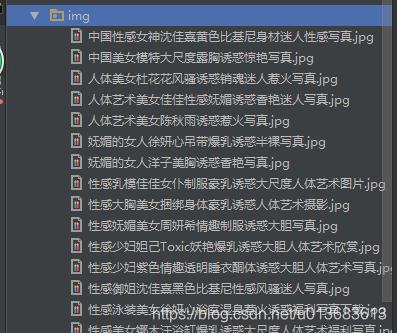
file_path = os.path.join(os.getcwd() + '/img/', title[0] + '.jpg') #拼接图片保存路径
request.urlretrieve(src[0], file_path) #将图片保存到本地,参数1获取到的src,参数2保存路径
xpath()标签选择器,是Selector类里的一个方法,参数是选择规则【推荐】
选择器规则同上
selector()创建选择器类,需要接受html对象
需要导入:from scrapy.selector import Selector
# -*- coding: utf-8 -*-
import scrapy #导入爬虫模块
from scrapy.selector import HtmlXPathSelector #导入HtmlXPathSelector模块
from scrapy.selector import Selector
class AdcSpider(scrapy.Spider):
name = 'adc' #设置爬虫名称
allowed_domains = ['www.shaimn.com']
start_urls = ['http://www.shaimn.com/xinggan/']
def parse(self, response):
items = Selector(response=response).xpath('//div[@class="showlist"]/li').extract()
# print(items) #返回标签对象
for i in range(len(items)):
title = Selector(response=response).xpath('//div[@class="showlist"]/li[%d]//img/@alt' % i).extract()
src = Selector(response=response).xpath('//div[@class="showlist"]/li[%d]//img/@src' % i).extract()
print(title,src)
正则表达式的应用
正则表达式是弥补,选择器规则无法满足过滤情况时使用的,
分为两种正则使用方式
1、将选择器规则过滤出来的结果进行正则匹配
2、在选择器规则里应用正则进行过滤
1、将选择器规则过滤出来的结果进行正则匹配,用正则取最终内容
最后.re(‘正则’)
# -*- coding: utf-8 -*-
import scrapy #导入爬虫模块
from scrapy.selector import HtmlXPathSelector #导入HtmlXPathSelector模块
from scrapy.selector import Selector
class AdcSpider(scrapy.Spider):
name = 'adc' #设置爬虫名称
allowed_domains = ['www.shaimn.com']
start_urls = ['http://www.shaimn.com/xinggan/']
def parse(self, response):
items = Selector(response=response).xpath('//div[@class="showlist"]/li//img')[0].extract()
print(items) #返回标签对象
items2 = Selector(response=response).xpath('//div[@class="showlist"]/li//img')[0].re('alt="(\w+)')
print(items2)
# <img src="http://www.shaimn.com/uploads/170724/1-1FH4221056141.jpg" alt="人体艺术mmSunny前凸后翘性感诱惑写真">
# ['人体艺术mmSunny前凸后翘性感诱惑写真']
2、在选择器规则里应用正则进行过滤
[re:正则规则]
# -*- coding: utf-8 -*-
import scrapy #导入爬虫模块
from scrapy.selector import HtmlXPathSelector #导入HtmlXPathSelector模块
from scrapy.selector import Selector
class AdcSpider(scrapy.Spider):
name = 'adc' #设置爬虫名称
allowed_domains = ['www.shaimn.com']
start_urls = ['http://www.shaimn.com/xinggan/']
def parse(self, response):
items = Selector(response=response).xpath('//div').extract()
# print(items) #返回标签对象
items2 = Selector(response=response).xpath('//div[re:test(@class, "showlist")]').extract() #正则找到div的class等于showlist的元素
print(items2)
