计算机视觉
目标检测,语义分割,目标分类
自然语言处理NLP
数据结构
- 数据结构
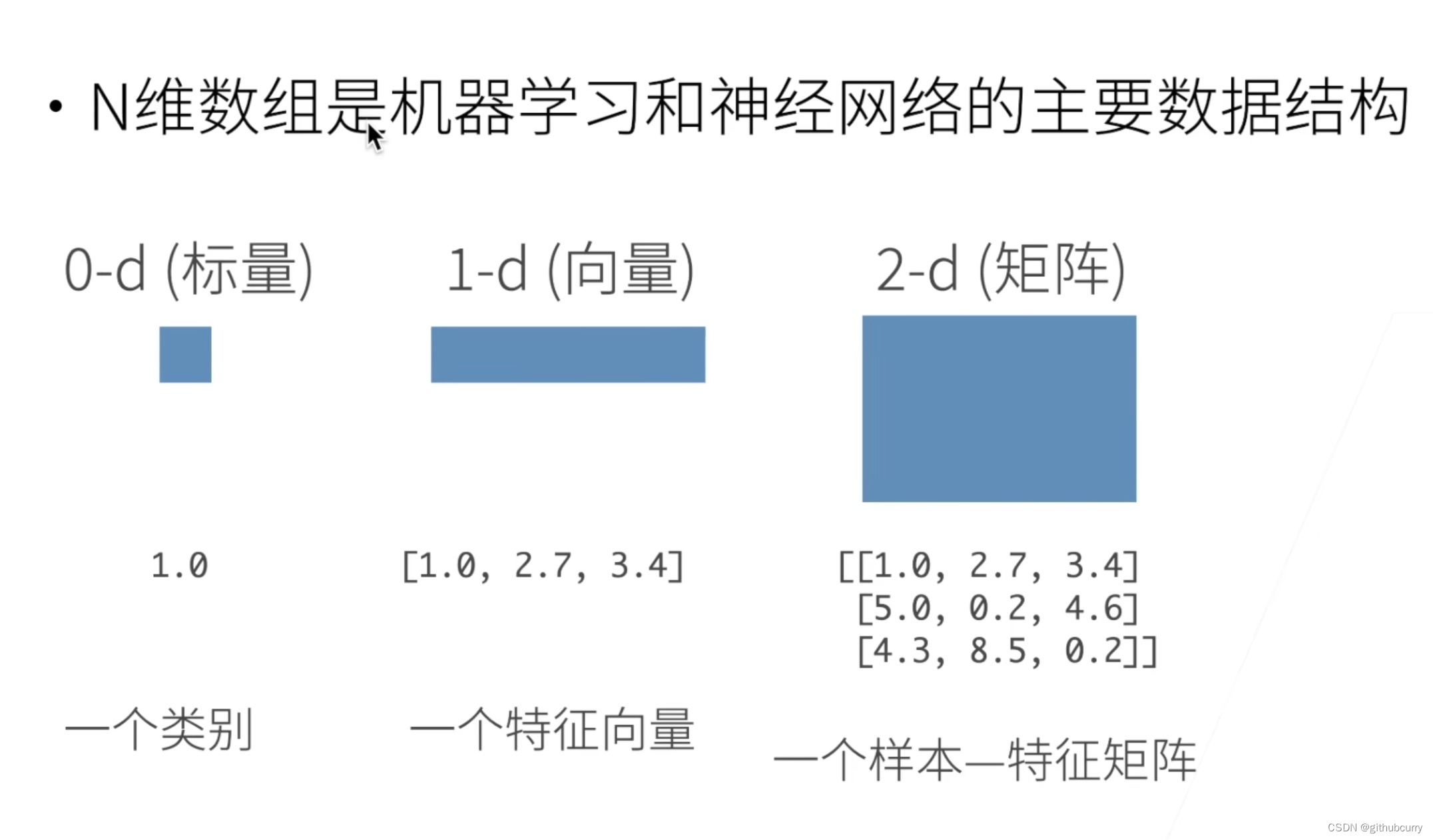
- 访问元素

线性回归
可以看成是一个单层的神经网络,有显式的解
优化算法
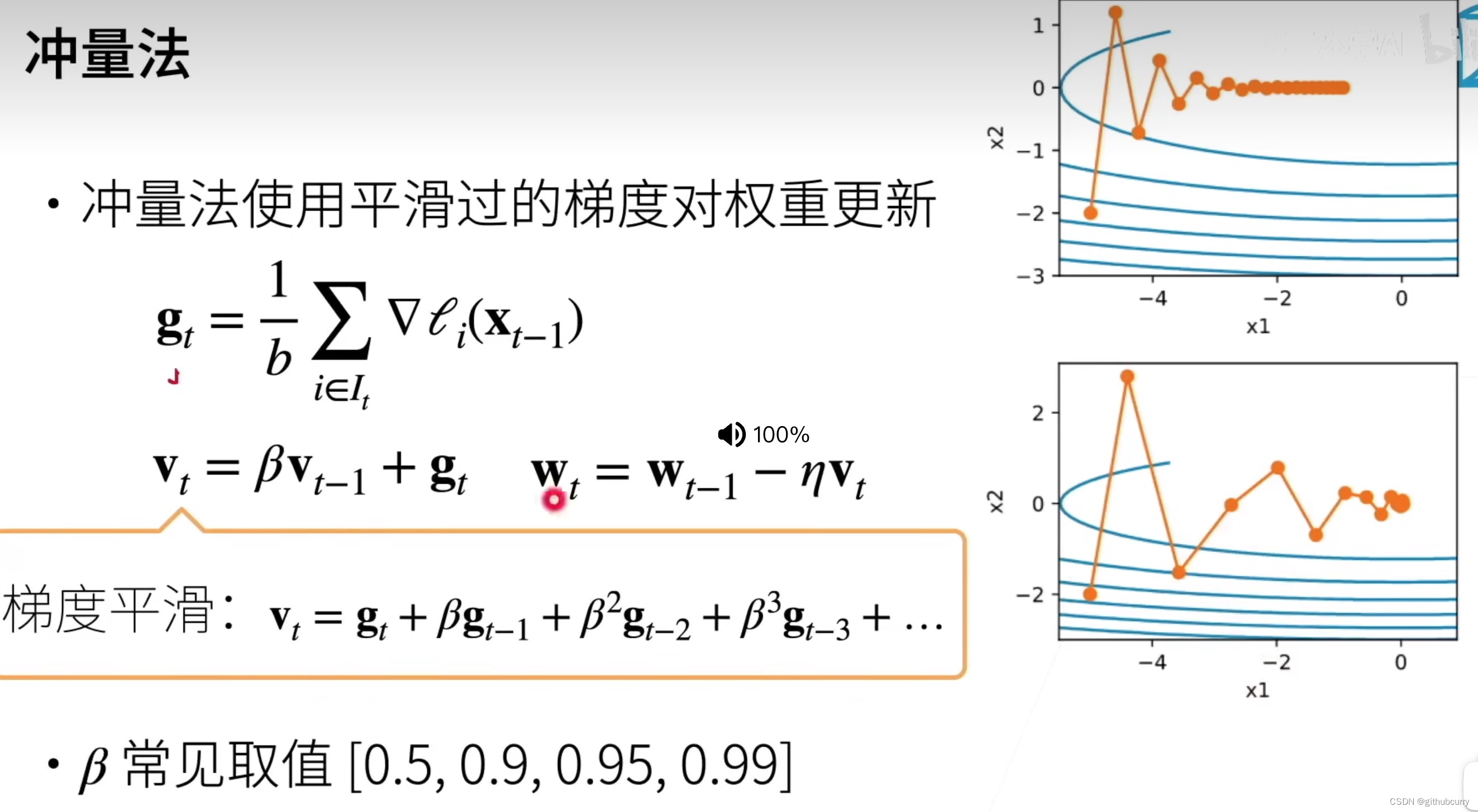
梯度下降,超参数:学习率、批量大小
分类回归
单层感知机,多层感知机
- 多层感知机使用隐藏层和激活函数来得到非线性模型,常用的激活函数有Sigmoid、Tanh、ReLU;
- Softmax来处理多分类问题
- 多层感知机的超参数:隐藏层数,每层隐藏层的大小
- 验证集数据和测试集数据不能混在一起,k-折交叉验证
过拟合欠拟合

模型容量:拟合各种函数的能力
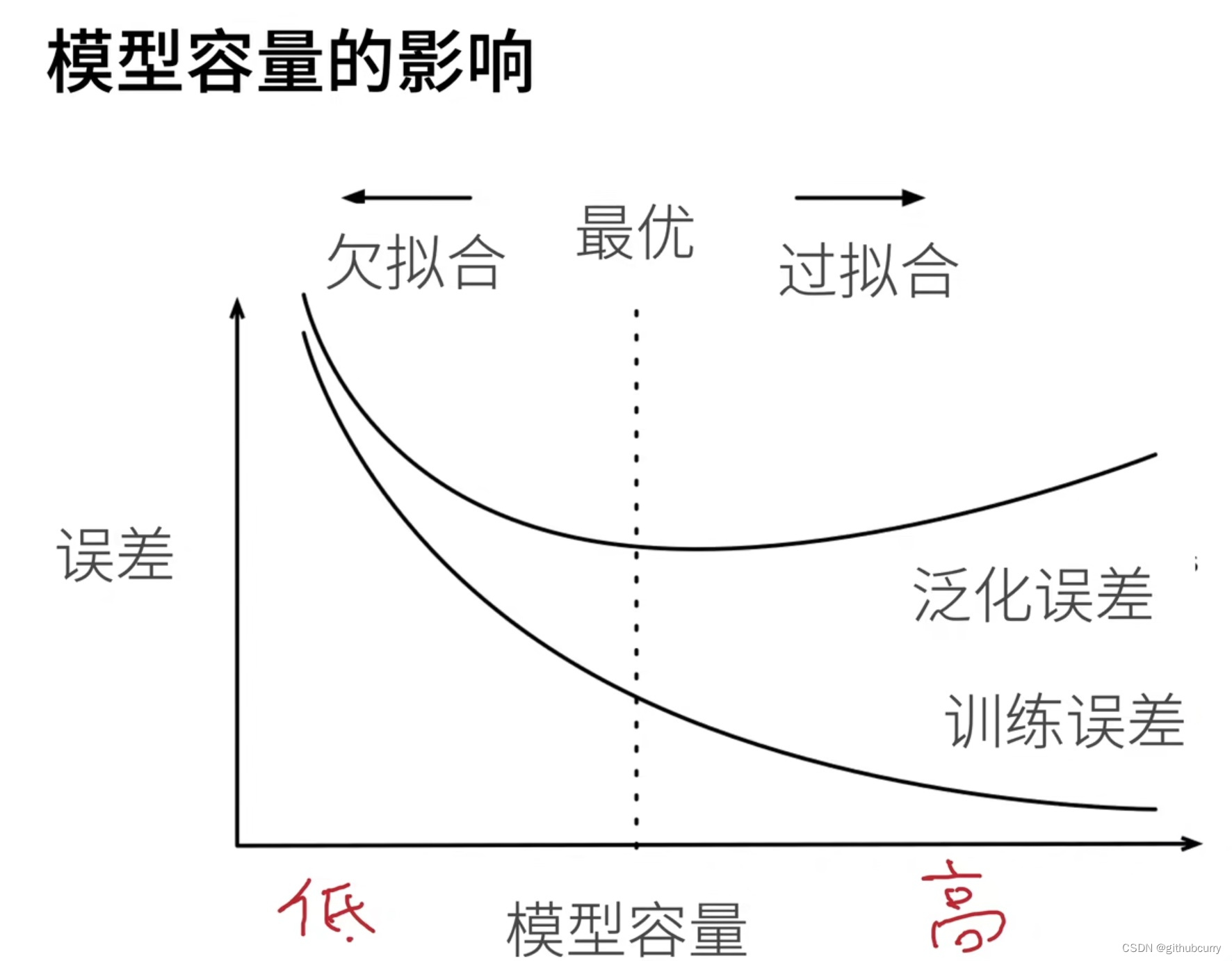
控制模型的复杂度:参数的个数、参数值的选择范围
权重衰退和Dropout
- 权重衰退是通过刚性的限制权重不超过某个值从而降低模型复杂度
- 丢弃法将一些输出项随机设置为0来控制模型复杂度,丢弃概率是控制模型复杂度的超参数
数值稳定性
- 梯度爆炸
- 梯度消失
- 保持训练稳定性:将乘法变加法,归一化(梯度归一化,梯度剪裁),合理的权重初始和激活函数
卷积层
每个输出通道可以识别特定模式,可以融合多通道
池化层
输入的通道等于输出的通道,缓解卷积层对位置的敏感性
正则化Regularization
规则化、规范化的意思,使得权重的值不要太大,避免一定的过拟合
批量归一化(Batch Normalization)
- 批量归一化固定小批量中的均值和方差,然后学习出适合的偏移和缩放
- 可以加速收敛速度,但一般不改变模型精度,可以使用大一点的学习率加快模型收敛
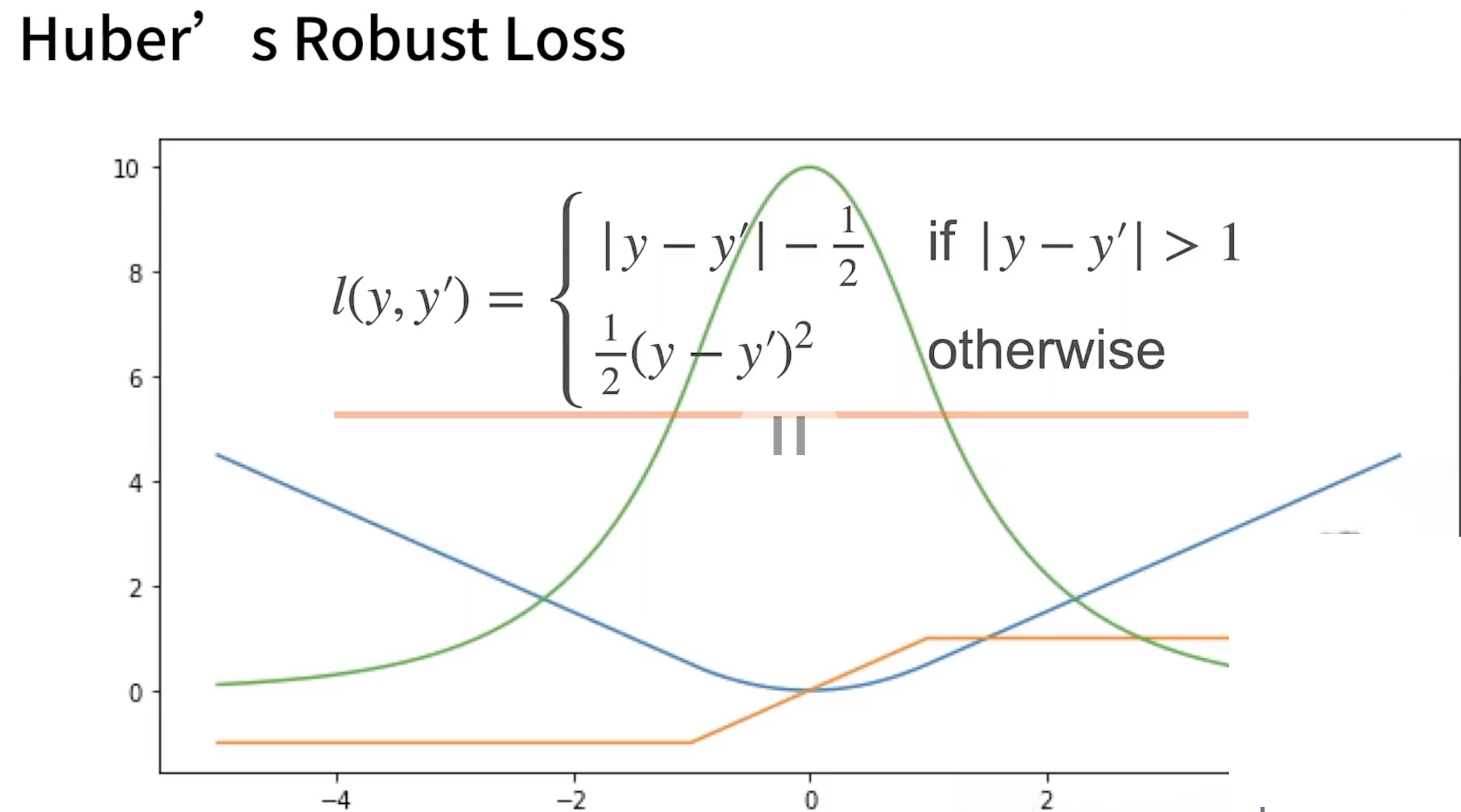
损失函数
-
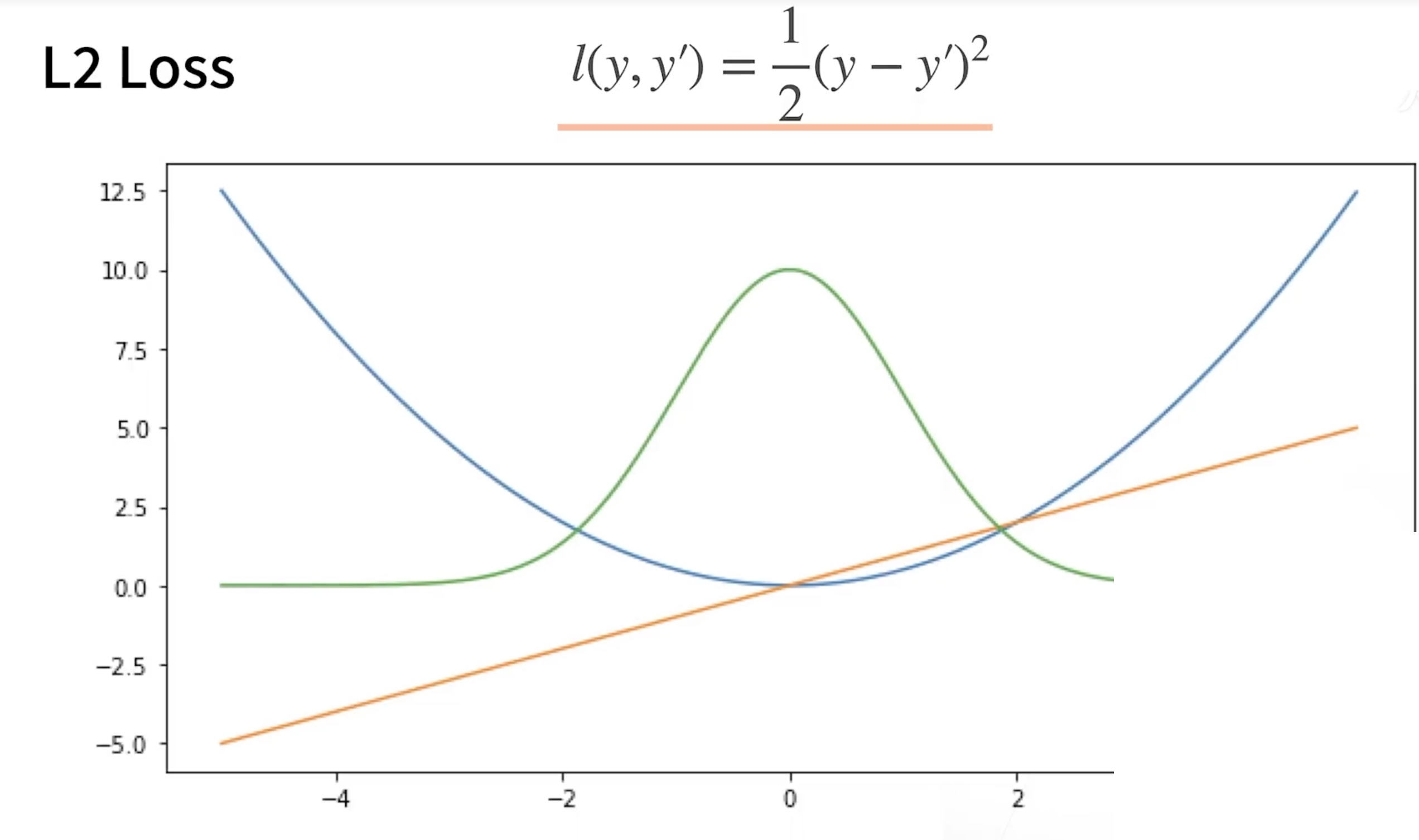
L2 Loss
-
L1 Loss

-
Huber Rubost Loss 鲁棒误差
残差网络ResNet
残差块使得很深的网络可以更加容易训练,可以有效的避免训练到后期,梯度太小训练的很慢,通过残差块,可以先训练,然后回过来更新梯度。
图像增广
- 在线生成图片,做随机增强,不会生成图像增强后的图片
- 数据增广通过变形数据来获得多样性从而使得模型泛化能力更好,常见的图片增广包括翻转切割变色
finetune(微调)
finetune属于迁移学习的一种,就是在一个较大的数据集上训练好的模型,将模型的结构参数等直接拿过来运用到小数据集上(两个数据集有一定的相似性),但是在最后的fc(分类或者回归问题)要随机初始化参数训练

锚框
- 边缘框(BordingBox)
首先生成大量锚框,并赋予标号,每一个锚框作为一个样本进行训练。在预测时使用NMS来去掉冗余的预测
目标检测
- R-cnn(区域卷积神经网络)
- Mask R-cnn:如果有像素级别的编号,使用fcn来利用这些信息
- faster rcnn
精度很高,但是处理速度很慢,不如yolo(you only look once) - ssd(单发多框检测)
不再维护和开发,用的比较少 - yolo
yolo将图片均匀分成SxS个锚框,每个锚框预测B个边缘框
语义分割
像素级别的分类,分为背景和其他类型

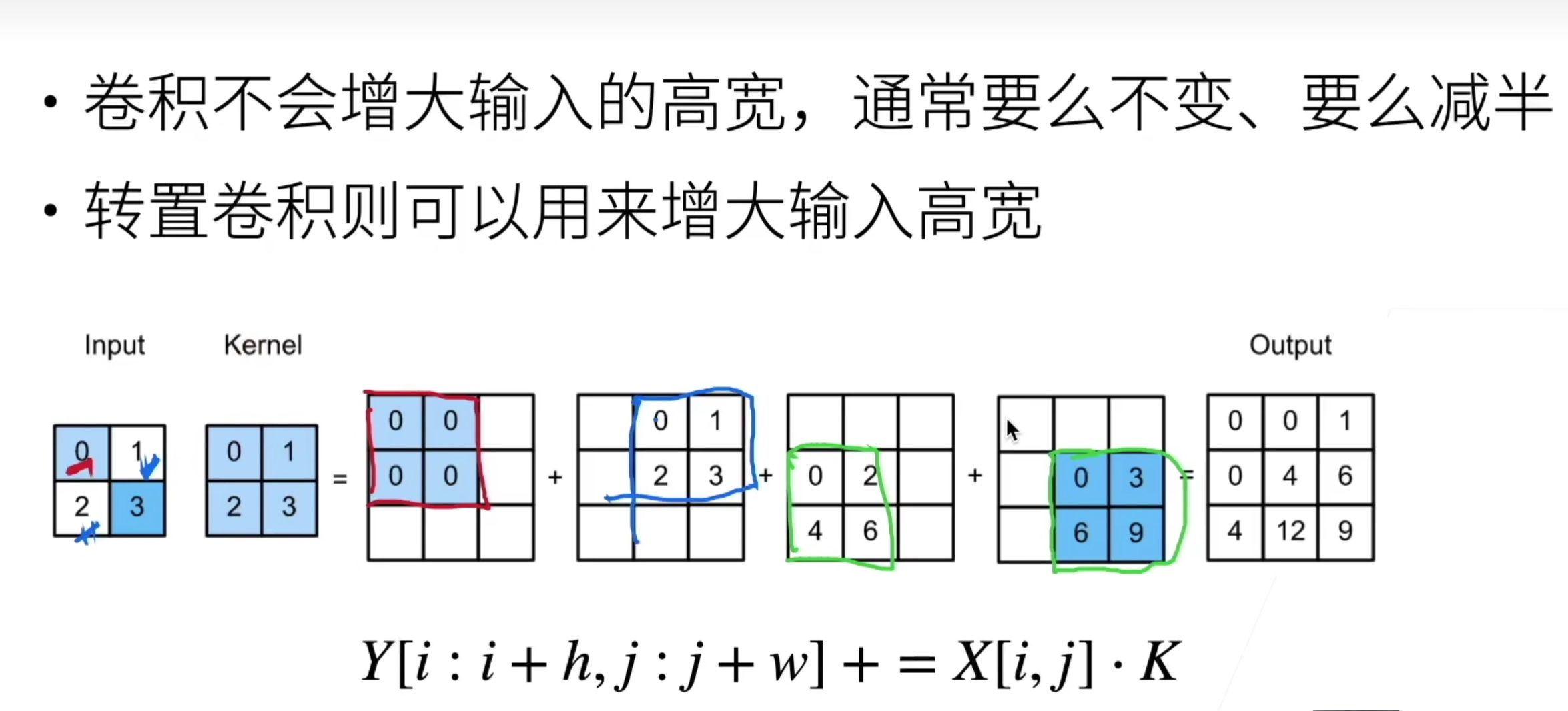
转置卷积
可以增大输入图片的高宽,可以简单地理解成反向卷积操作,得到的结果和卷积操作相反
- 全连接卷积神经网络 FCN

最后输出的通道数=类别数 - 样式迁移
分别求一个样式tensor和内容tensor,三个损失,样式、内容、噪点
硬件提升

序列模型
可以使用马尔科夫预测或者自回归预测
- 文本预处理
把句子中的一些词转换成能够处理的数据 - 语言模型
估计文本序列的联合概率,使用统计方法时常采用n元语法 - RNN(循环神经网络)
存储一个时序信息
一个预测时序类型模型的好坏可以看成一个分类问题,即下一个token索引的概率,可以使用平均交叉熵来衡量

- 梯度剪裁
rnn中经常使用梯度剪裁,有效的预防梯度爆炸
门控循环单元GRU
可以控制哪些重要,哪些不重要,能关注的机制(更新门);能遗忘的机制(遗忘门)
LSTM长短期记忆网络
- 忘记门:将值朝0减少
- 输入门:决定不是忽略掉输入数据
- 输出门:决定是不是使用隐状态
深层循环神经网络
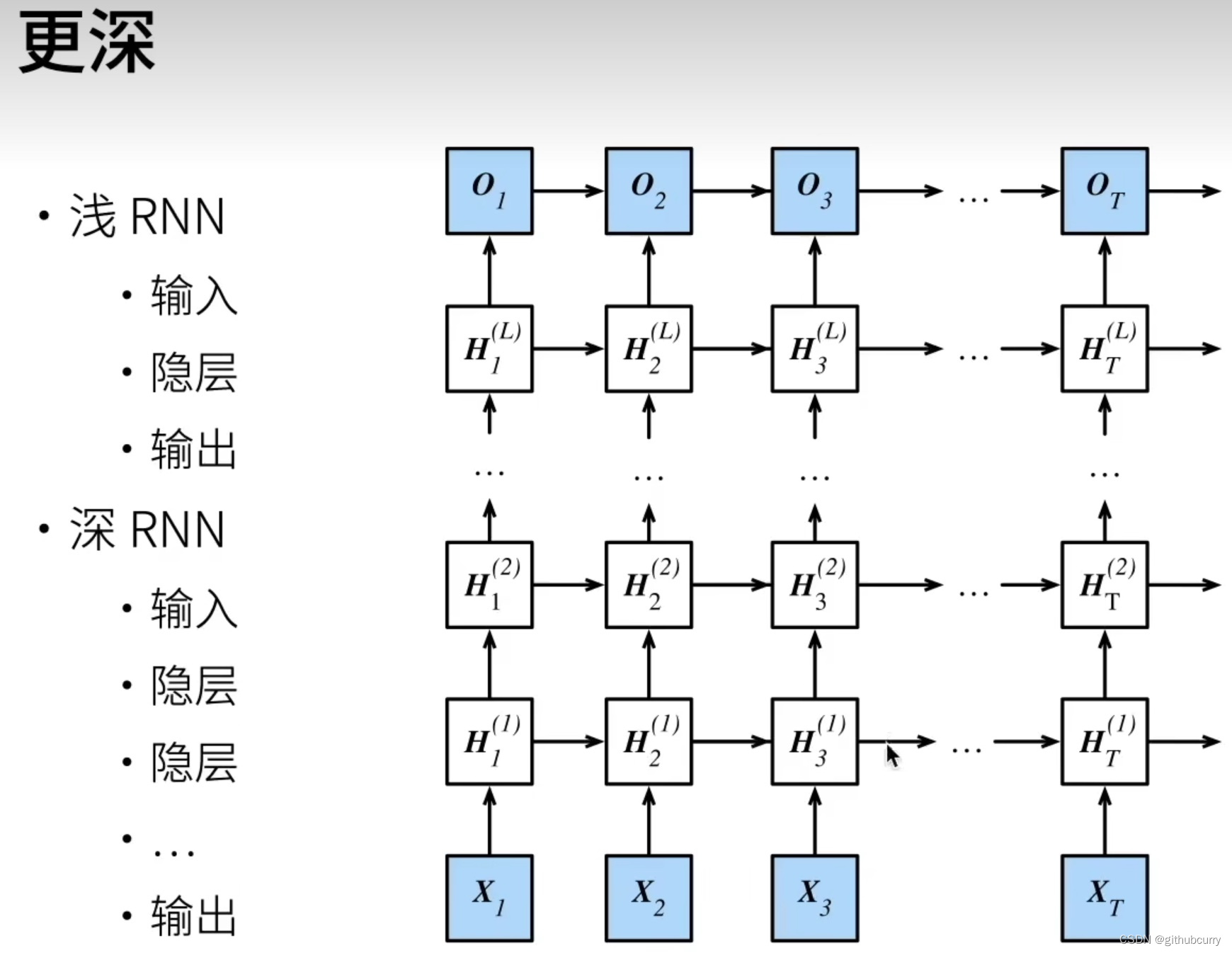
深度循环神经网络使用多个隐藏层来获得更多的非线性性
双向循环神经网络
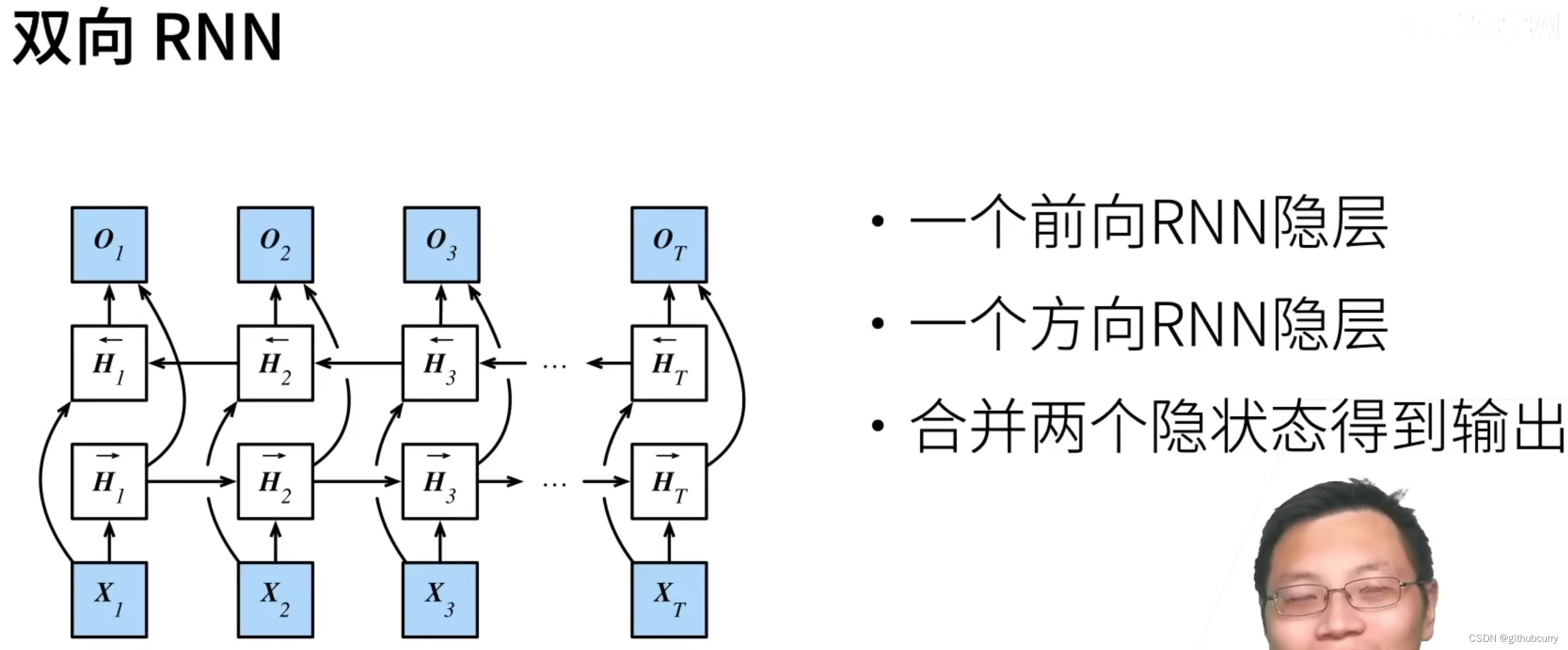
- 双向循环神经网络通过反向更新的隐藏层来利用方向时间信息
- 通常用来对序列抽取特征、填空,而不是预测未来
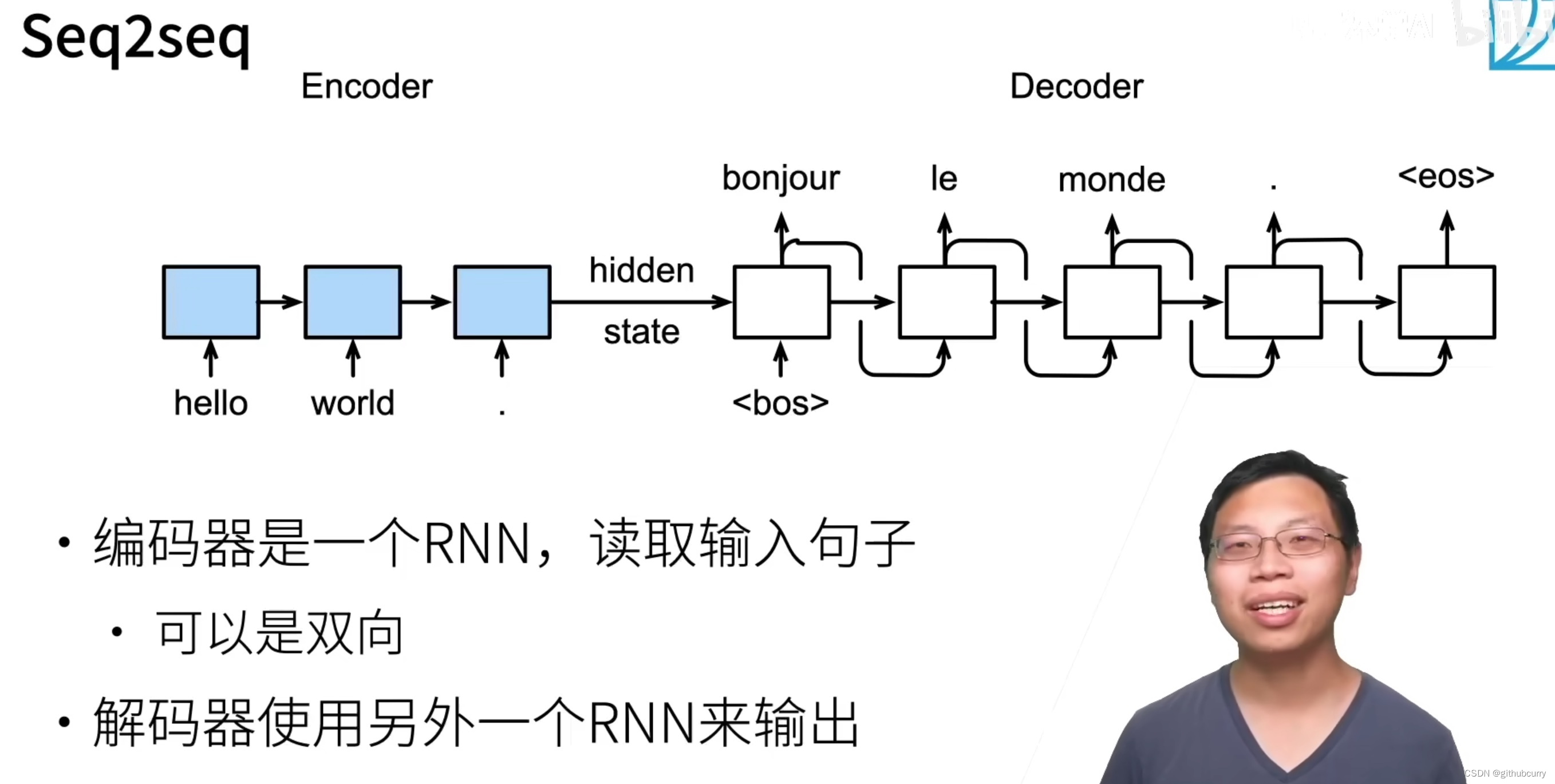
编码器-解码器
Seq2seq


Elmo预训练模型
前向后向预测,一词多义
- GPT单向语言模型
- BERT双向语言模型
束搜索
束搜索在每次搜索的时候保存k个最好的候选选项
- k=1时,是贪心搜索
- k=n时,是穷举搜索
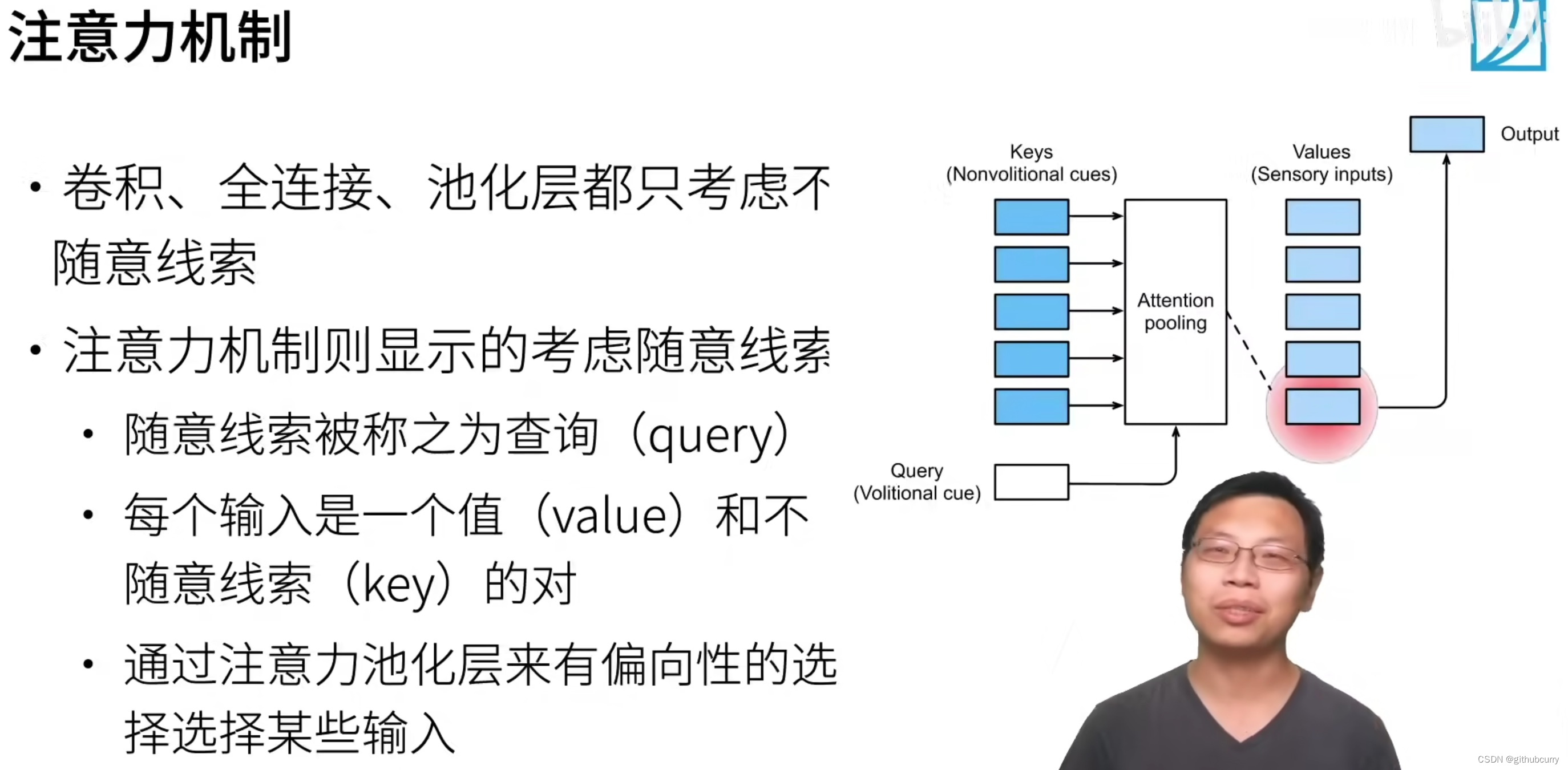
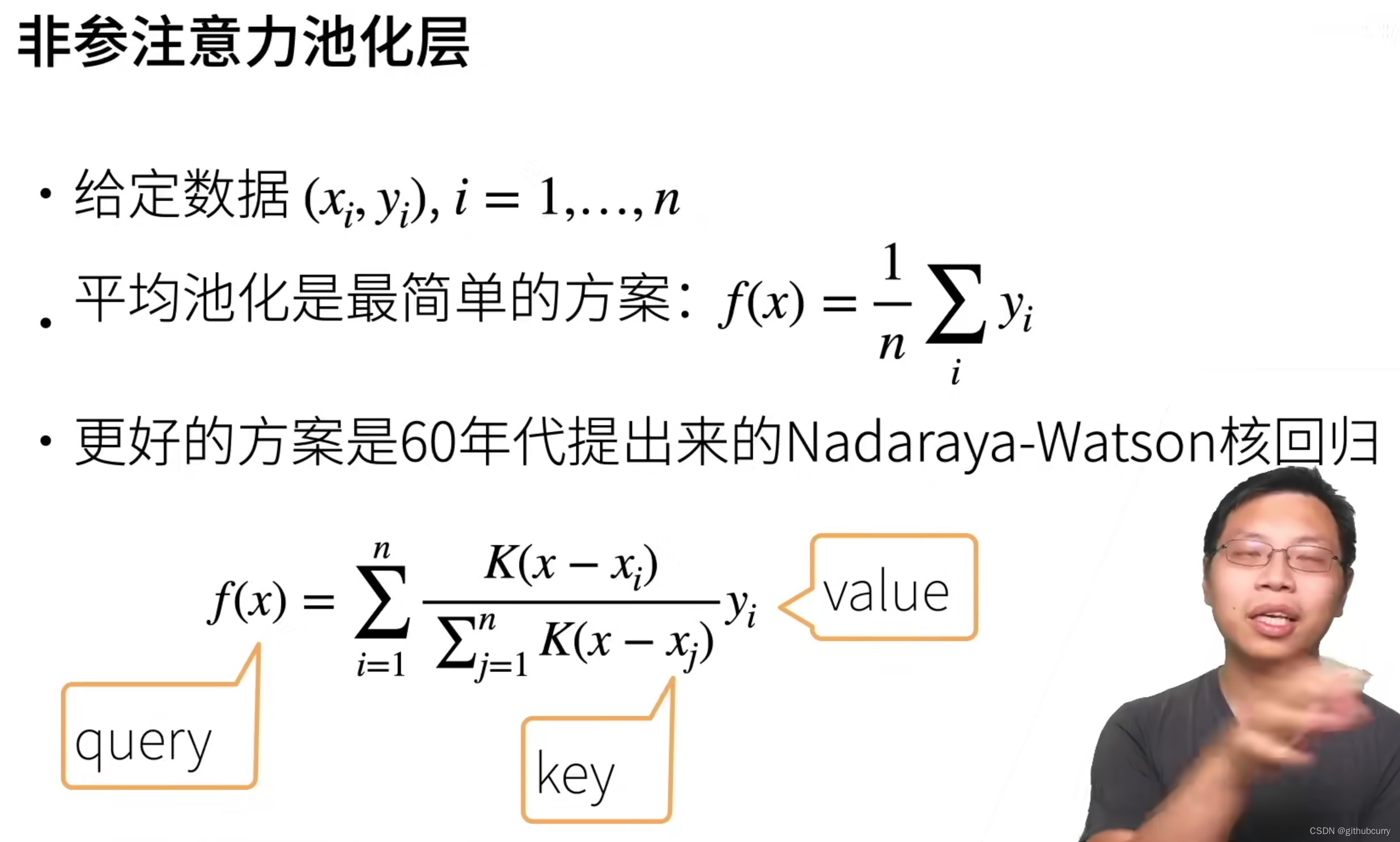
注意力机制

我们可以这样来看待Attention机制(参考图为上图):将Source中的构成元素想象成是由一系列的<Key,Value>数据对构成,此时给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到了最终的Attention数值。所以本质上Attention机制是对Source中元素的Value值进行加权求和,而Query和Key用来计算对应Value的权重系数。

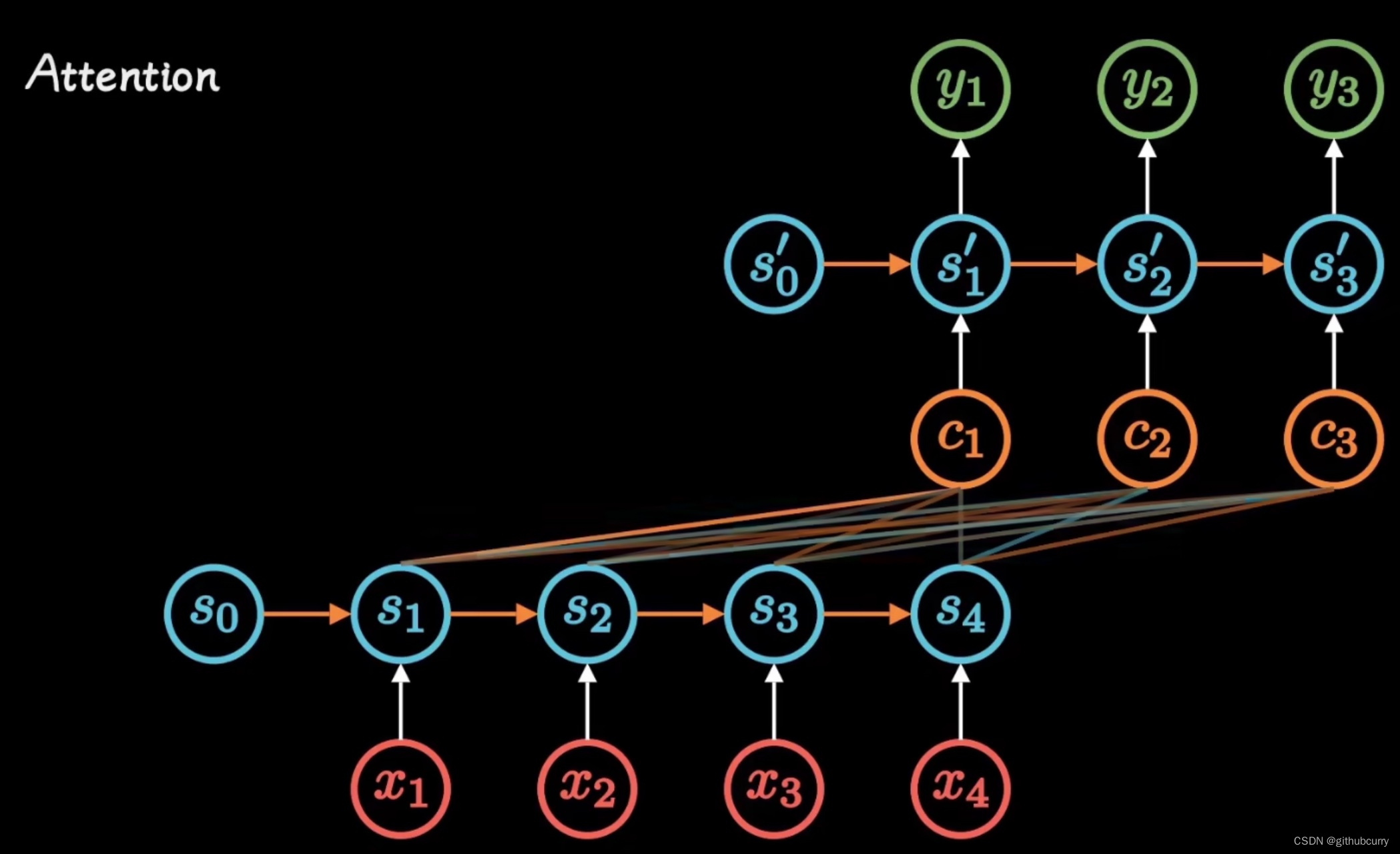
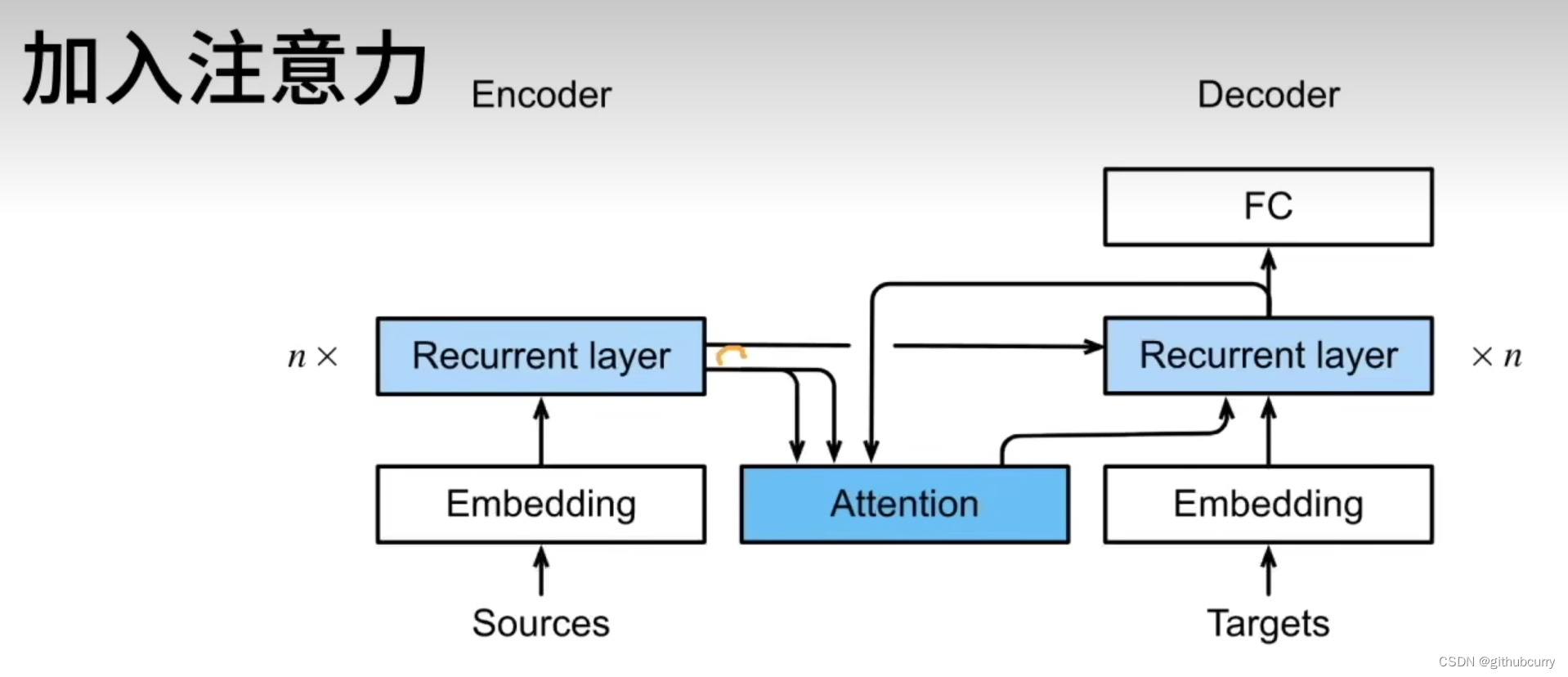
使用注意力机智的seq2seq

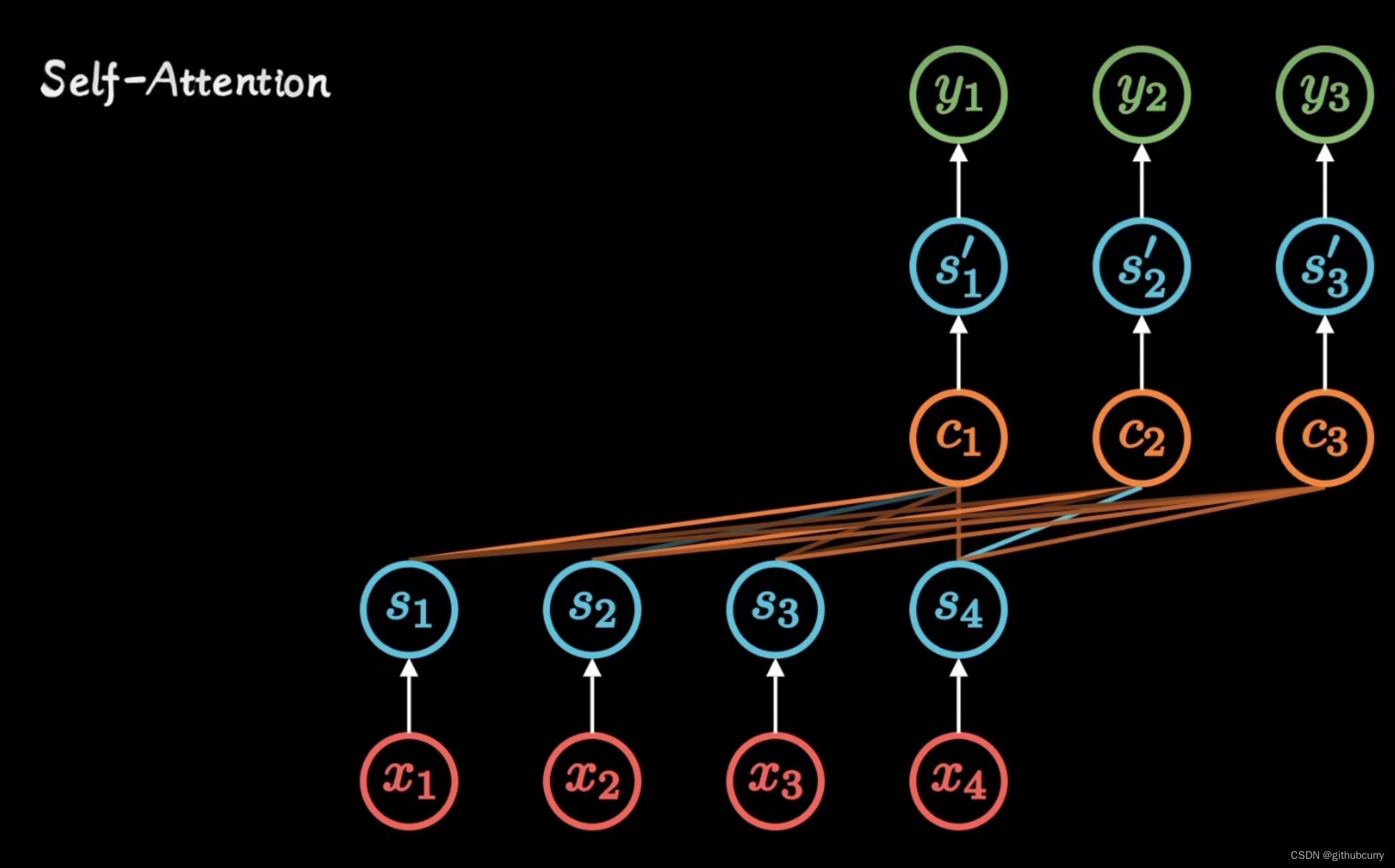
自注意力机制
自注意力机制模型擅长处理特别长的文本,但是计算成本特别高,需要上千个gpu同时计算,越长的文本越消耗资源,是平方的关系


优化算法