目录
前面我们完成了《基础工具封装》、《原生HttpClient封装》和《Netty消息服务封装》,这仅仅是将工具准备完成,接下来我们来开始用这些工具来实现爬取我们的目标资源:《全国统计用区划代码和城乡划分代码(2021)》
宁静(Serenity)
首先,我们了解下爬虫原理:
1.模拟浏览器发送web请求,一般为GET请求或POST请求
2.获取远程服务器响应结果
3.解析响应结果
4.保存分析结果
当然,服务器为了防止爬虫攻击,也会做一些防范措施,比如使用cookies、session、token等进行安全验证,比如通过Referer验证请求来源等等,还有做请求转移和请求频次过滤等防范措施,总之攻击方法很多,防范措施更多,这里我们只是为了做基础知识分享,不做专题讨论。
有人说为什么要防范爬虫?呵呵,第一,数据是宝贵的,当然为了数据安全;第二,爬虫属于高频次访问,对服务器压力非常大,据统计,全国统计用区划代码和城乡划分代码(2021)就有663128条记录,涉及44715个页面访问,你说一个用户去爬,服务器就需要处理这么多次,大家都去爬,那服务器岂不是亚历山大?
好了,话不多说,我们进入正题。
java开发一个好的习惯就是建立MVC结构,这里我们先建立数据实体,以便数据持久化。
数据实体
Region.java
package com.vtarj.pythagoras.crawler.entity;
import lombok.Data;
import org.sagacity.sqltoy.config.annotation.Column;
import org.sagacity.sqltoy.config.annotation.Entity;
import org.sagacity.sqltoy.config.annotation.Id;
import org.springframework.util.ReflectionUtils;
import java.lang.reflect.Field;
import java.sql.Types;
/**
* @Author Vtarj
* @Description 行政区划
* @Time 2022/4/6 13:45
**/
@Data
@Entity(tableName = "SC_REGION",pk_constraint = "PRIMARY")
public class Region {
//数据库主键ID
@Id(strategy = "generator",generator = "org.sagacity.sqltoy.plugins.id.impl.DefaultIdGenerator")
@Column(name = "R_ID",type = Types.VARCHAR,nullable = false)
private String id;
//行政区划编码
@Column(name = "R_CODE",type = Types.VARCHAR,nullable = false)
private String code;
//行政区划类型
@Column(name = "R_TYPE",type = Types.VARCHAR,nullable = false)
private String type;
//行政区划名称
@Column(name = "R_NAME",type = Types.VARCHAR,nullable = false)
private String name;
//行政区划等级
@Column(name = "R_LEVEL",type = Types.INTEGER,nullable = false)
private int level;
//行政区划链接
@Column(name = "R_URL",type = Types.VARCHAR,nullable = false)
private String curl;
//上级行政区划编码
@Column(name = "P_CODE",type = Types.VARCHAR)
private String pcode;
//上级行政区划链接
@Column(name = "P_URL",type = Types.VARCHAR)
private String purl;
public Region() {
super();
}
public Region(String code, String type, String name, int level, String curl, String pcode, String purl) {
this.code = code;
this.type = type;
this.name = name;
this.level = level;
this.curl = curl;
this.pcode = pcode;
this.purl = purl;
}
@Override
public String toString() {
return "Region{" +
"code='" + code + '\'' +
", type='" + type + '\'' +
", name='" + name + '\'' +
", level=" + level +
", curl='" + curl + '\'' +
", pcode='" + pcode + '\'' +
", purl='" + purl + '\'' +
'}';
}
/**
* Region字符串转换为Region对象,字符串必须满足Region的toString()格式
* @param regionStr Region字符串
* @return Region对象
*/
public static Region stringToRegion(String regionStr){
Region region = null;
if (regionStr.startsWith("Region{")) {
regionStr = regionStr.substring(7,regionStr.length() - 1).replaceAll("\'","");
String[] ctxs = regionStr.split(",");
region = new Region();
for (String kv:
ctxs) {
String[] fieldArr = kv.split("=");
Field field = ReflectionUtils.findField(Region.class,fieldArr[0].trim());
assert field != null;
field.setAccessible(true);
if (field.getType().toString().equals("int")){
ReflectionUtils.setField(field,region,Integer.parseInt(fieldArr[1].trim()));
}else {
ReflectionUtils.setField(field,region,fieldArr[1].trim());
}
}
}
return region;
}
}
这里我做数据持久化使用的是SqlToy工具,所以会有一些SqlToy的注解标记,总之就是为了后面保存数据方便(想了解SqlToy工具的可以自行查找资源,这里不过多解释)。
持久化服务定义和实现
RegionService.java
package com.vtarj.pythagoras.crawler.service;
import java.util.List;
/**
* @Author Vtarj
* @Description 行政区划服务
* @Time 2022/4/8 10:44
**/
public interface RegionService<Region> {
/**
* 批量保存行政区划
* @param list 行政区划列表
* @return 保存数量
*/
public long save(List<Region> list);
}
RegionServiceImpl.java
package com.vtarj.pythagoras.crawler.service.impl;
import com.vtarj.pythagoras.crawler.service.RegionService;
import org.sagacity.sqltoy.dao.SqlToyLazyDao;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
/**
* @Author Vtarj
* @Description 行政区划采集API
* @Time 2022/4/8 10:46
**/
@Service
public class RegionServiceImpl implements RegionService {
@Autowired
private SqlToyLazyDao sqlToyLazyDao;
@Override
public long save(List list) {
return sqlToyLazyDao.saveAll(list);
}
}
好吧,看到上面基本就了解了SqlToy省去了写DAO层,直接调用sqltoy的SqlToyLazyDao就可以实现基本的增删改查操作,这就是我用这个工具的原因之一。
采集及处理
RegionApi.java
package com.vtarj.pythagoras.crawler.api;
import com.vtarj.pythagoras.crawler.entity.Region;
import com.vtarj.pythagoras.crawler.service.RegionService;
import com.vtarj.pythagoras.explore.HttpExplore;
import com.vtarj.pythagoras.explore.HttpResult;
import com.vtarj.pythagoras.message.NettyHelper;
import com.vtarj.pythagoras.tools.date.DateUtil;
import com.vtarj.pythagoras.tools.file.FileUtil;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.io.File;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.net.ProxySelector;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.Objects;
/**
* @Author Vtarj
* @Description 采集行政区划信息
* @Time 2022/4/6 11:58
**/
@RestController
@RequestMapping(value = "/api/region")
public class RegionApi {
//定义采集类型
private static final String[] grade = {"province","city","county","town","village"};
//定义采集结果
private final List<Region> regionList = new ArrayList<>();
//定义采集数量
private int count = 0;
//定义日志存放路径
private static final String LOG_PATH = "/temp/log/region/miss.log";
//定义采集开关
private boolean flag;
//定义代理地址,默认不使用代理,在发生异常时才使用代理
private InetSocketAddress address = null;
//定义请求配置锁,用于设置是否强制更新配置,true 不更新,false更新
private boolean reqConfigLocked = true;
//定义连续异常计数器,连续异常到5之后将启用代理模式
private int errCount = 0;
private final String startURI = "http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2021/index.html";
@Autowired
private RegionService<Region> regionService;
/**
* 启动采集器
*/
@RequestMapping(value = "/start")
public void start(){
Region top = new Region(null,null,"首页",0,startURI,null,null);
flag = true;
//从顶点开始采集
collect(top);
//数据补偿
compensation();
//保存采集的行政区划数据,实际仅保存尾部数据,每超过100条由记录器执行保存
regionService.save(regionList);
}
/**
* 关闭采集器
*/
@RequestMapping(value = "/stop")
public void stop(){
flag = false;
}
/**
* 采集该节点下的信息
* @param node 采集的节点
*/
private void collect(Region node){
if (!flag || node.getCurl() == null || node.getCurl().isEmpty()) return;
HttpResult<String> result;
//向客户端发送消息,提示正在采集内容
NettyHelper.send("admin","RegionCrawler",1,"正在采集:" + node);
try {
result = HttpExplore.builder()
.setRequestURI(node.getCurl())
.setHeader("Content-Type","text/html;charset=utf-8")
.setConnectTimeout(Duration.ofMinutes(1))
//设置代理请求
.setProxySelector(address == null ? null : ProxySelector.of(address))
//设置是否强制更新配置,true 不更新,false更新
.setLocked(reqConfigLocked)
.build()
.executeToString();
//请求正常,标识代理可用,下次则不再强制更新通道配置
reqConfigLocked = true;
} catch (IOException | InterruptedException e) {
//网络请求异常,记录日志
log(node.toString());
e.printStackTrace();
initProxy();
return;
}
//未采集到信息
if (result.getData().isEmpty()){
//将异常的链接登记到遗失日志中
log(node.toString());
return;
}
String ctx = result.getData();
String suffix = "tr";
String type = suffix;
int level = 0;
//确定爬取类型及层级
for (String key:
grade) {
level++;
if (ctx.indexOf("class=\"" + key + suffix + "\"") > 0) {
type = key;
break;
}
}
//无有效信息
if (type.equals(suffix)) {
//将异常的链接登记到遗失日志中
log(node.toString());
//若采集时服务器端请求转发,则等待5分钟后再执行,避免IP被封
if (result.getCode() == 302) {
try {
Thread.sleep(60000 * 5);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
return;
}
//提取有效信息
Document document = Jsoup.parse(ctx);
Elements es = document.getElementsByClass(type + suffix);
Elements ts = es.select("tr");
//处理信息
switch (Objects.requireNonNull(type)){
case "province" :
topHandler(type,level,node,ts);
break;
case "city" :
case "county" :
case "town" :
middleHandler(type,level,node,ts);
break;
case "village" :
bottomHandler(type,level,node,ts);
break;
default : {}
}
}
/**
* 顶层行政区划处理
* @param type 层级类型
* @param level 行政等级
* @param node 上级节点
* @param ts 当前节点
*/
private void topHandler(String type,int level,Region node, Elements ts) {
for (Element tr:
ts) {
for (Element td:
tr.select("td")) {
if (!td.text().isEmpty()){
String uri = td.select("a").attr("href").isEmpty() ? null : rebuildURI(node.getCurl(),td.select("a").attr("href"));
Region region = new Region(
getTopCodeWithURI(td.select("a").attr("href")),
type,
td.text(),
level,
uri,
node.getCode(),
node.getCurl()
);
//登记采集的节点
record(region);
//采集下级节点
collect(region);
}
}
}
}
/**
* 中层行政区划处理
* @param type 层级类型
* @param level 行政等级
* @param node 上级节点
* @param ts 当前节点
*/
private void middleHandler(String type,int level,Region node, Elements ts) {
for (Element tr:
ts) {
Elements tds = tr.select("td");
String uri = tds.select("a").attr("href").isEmpty() ? null : rebuildURI(node.getCurl(),tds.select("a").attr("href"));
Region region = new Region(
tds.get(0).text(),
type,
tds.get(1).text(),
level,
uri,
node.getCode(),
node.getCurl()
);
//登记采集的节点
record(region);
//采集下级节点
collect(region);
}
}
/**
* 底层行政区划处理
* @param type 层级类型
* @param level 行政等级
* @param node 上级节点
* @param ts 当前节点
*/
private void bottomHandler(String type,int level,Region node, Elements ts) {
for (Element tr:
ts) {
Elements tds = tr.select("td");
Region region = new Region(
tds.get(0).text(),
type,
tds.get(2).text(),
level,
null,
node.getCode(),
node.getCurl()
);
record(region);
}
}
/**
* 登记采集到的行政区划信息
* @param region 采集到的行政区划
*/
private void record(Region region) {
//采集到有效数据,清零连续异常计数器
errCount = 0;
regionList.add(region);
count++;
//每超过100条时后台自动保存数据,防止内存长期占用,同时提高保存效率,尾部数据由主程序保存
if (regionList.size() == 100) {
regionService.save(regionList);
regionList.clear();
}
//向regionPage用户发送采集到的信息
NettyHelper.send("admin","RegionCrawler",1,"第"+ count + "个行政区划:" + region.toString());
System.out.println("第"+ count + "个行政区划:" + region);
}
/**
* 获取顶层节点编码
* @param uri 节点URL
* @return 节点编码
*/
private String getTopCodeWithURI(String uri){
if (uri==null){
return null;
}
return uri.substring(0,uri.indexOf(".")) + "0000000000";
}
/**
* 重建完整访问地址
* @param purl 上级链接地址
* @param path 当前连接路径
* @return 当前完整访问地址
*/
private String rebuildURI(String purl,String path) {
return purl.substring(0,purl.lastIndexOf("/")) + "/" + path;
}
/**
* 记录日志,每次增加一行日期,以便后续追溯
* @param context 日志内容
*/
private void log(String context){
if (!context.isEmpty()) {
File file = FileUtil.build(LOG_PATH);
FileUtil.write(file, DateUtil.dateToString(new Date(),"yyyy-MM-dd HH:mm:ss"),true);
FileUtil.write(file,System.lineSeparator(),true);
FileUtil.write(file,context,true);
FileUtil.write(file,System.lineSeparator(),true);
FileUtil.write(file,System.lineSeparator(),true);
}
}
/**
* 解析遗失日志,获取遗失清单
* @return 遗失清单
*/
private List<Region> loadErr() {
//定义缺失的清单
List<Region> missList = new ArrayList<>();
//加载错误日志文件
File file = new File(LOG_PATH);
if (file.exists()) {
//从错误日志文件中加载异常内容
String ctx = FileUtil.read(file);
assert ctx != null;
if (!ctx.trim().isEmpty()){
//将原日志文件重命名
String newName = "miss_" + DateUtil.dateToString(new Date(),"yyyyMMddHHmmss") + "_已补偿";
FileUtil.rename(file,newName);
}
//解析日志内容
String[] lines = ctx.split(System.lineSeparator());
for (String line:
lines) {
if (!line.trim().isEmpty()) {
Region region = Region.stringToRegion(line);
if (region != null) {
missList.add(region);
}
}
}
}
return missList;
}
/**
* 数据补偿,补偿采集错误的数据
*/
private void compensation(){
List<Region> list = loadErr();
if (list.size() == 0) return;
for (Region region:
list) {
collect(region);
}
//递归补偿,防止遗漏
compensation();
}
/**
* 初始化代理
*/
private void initProxy(){
errCount++;
if (errCount < 5) return;
//设定代理测测试地址,不设置则不清除低性能代理
ProxyApi.target = startURI;
//代理通道异常,更换代理并将旧代理移出代理池
if (address != null) {
ProxyApi.removeProxy(String.valueOf(address.getAddress()),address.getPort());
} else {
System.out.println("===============启动代理程序支持===============");
}
address = ProxyApi.getProxy();
//更换代理,需强制更新(刷新)请求通道配置
reqConfigLocked = false;
}
}
工具封装好之后,请求就变得很简单,但是结果得解析就成了现在要关注得事情。每个页面不同,响应处理也不同,所以要抓住网页得节点特性,抓取对应得区域内容进行解析。
对了,为了防止服务器屏蔽我得IP(认为是恶意攻击可能会被封IP), 所以我又爬了个代理网站,在必要的时候启用代理,这里就不多解释了,看看上面得代码即可。
题外话:代理
ProxyApi.java
package com.vtarj.pythagoras.crawler.api;
import com.vtarj.pythagoras.explore.HttpExplore;
import com.vtarj.pythagoras.explore.HttpResult;
import com.vtarj.pythagoras.tools.date.DateUtil;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.net.ProxySelector;
import java.nio.charset.Charset;
import java.time.Duration;
import java.time.temporal.Temporal;
import java.util.*;
import java.util.stream.Collectors;
/**
* @Author Vtarj
* @Description 代理池管理工具
* @Time 2022/4/8 17:37
**/
public class ProxyApi {
//定义线程池
private static List<Proxy> pool = new ArrayList<>();
//定义低性能代理集合
private static final List<Proxy> shieldList = new ArrayList<>();
//目标地址
public static String target;
private static final List<String> URIs = new ArrayList<>(Arrays.asList(
"http://www.66ip.cn/areaindex_1/1.html",
"http://www.66ip.cn/areaindex_2/1.html",
"http://www.66ip.cn/areaindex_4/1.html",
"http://www.66ip.cn/areaindex_5/1.html",
"http://www.66ip.cn/areaindex_6/1.html",
"http://www.66ip.cn/areaindex_7/1.html",
"http://www.66ip.cn/areaindex_8/1.html",
"http://www.66ip.cn/areaindex_9/1.html",
"http://www.66ip.cn/areaindex_10/1.html",
"http://www.66ip.cn/areaindex_11/1.html",
"http://www.66ip.cn/areaindex_12/1.html",
"http://www.66ip.cn/areaindex_13/1.html",
"http://www.66ip.cn/areaindex_18/1.html"));
/**
* 随机加载一个地区的代理池
*/
private static void loadPool() {
if (URIs.size() == 0) return;
Random random = new Random();
String uri = URIs.get(random.nextInt(URIs.size()));
System.out.println(uri);
loadPool(uri);
//移除已采集地区
URIs.remove(uri);
}
/**
* 加载指定地区代理池
* @param uri 地址地区访问页面
*/
private static void loadPool(String uri){
try {
HttpResult<String> result = HttpExplore.builder()
.setRequestURI(uri)
.setReqCode(Charset.forName("GBK"))
.setResCode(Charset.forName("GBK"))
.setHeader("Content-Type","text/html;charset=gbk")
.setConnectTimeout(Duration.ofMinutes(1))
.build()
.executeToString();
String ctx = result.getData();
Document document = Jsoup.parse(ctx);
Elements es = document.getElementsByTag("table");
Elements ts = Objects.requireNonNull(es.last()).select("tr");
for (Element e:
ts) {
Elements tds = e.select("td");
if (tds.size() > 0) {
if (!tds.get(0).text().equals("ip")) {
Proxy proxy = new Proxy(tds.get(0).text(),Integer.parseInt(tds.get(1).text()));
pool.add(proxy);
}
}
}
//代理池去重
pool = pool.stream().distinct().collect(Collectors.toList());
//校验代理池,移除性能低的代理
verifyPool();
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}
}
/**
* 验证代理是否可用,自动去除无效或低效代理
*/
public static void verifyPool(){
System.out.println("开始检测代理性能:" + DateUtil.dateToString(new Date(),"yyyy-MM-dd HH:mm:ss"));
if (target != null) {
Thread[] threads = new Thread[pool.size()];
for (int i = 0;i < pool.size();i++) {
Proxy proxy = pool.get(i);
threads[i] = new Thread(
() -> {
try {
HttpResult<String> result = HttpExplore.builder()
.setProxySelector(ProxySelector.of(new InetSocketAddress(proxy.ip, proxy.port)))
.setConnectTimeout(Duration.ofMinutes(1))
.setLocked(false)
.setRequestURI(target)
.build()
.executeToString();
if (result.getOptions() != null) {
System.out.println("检测代理:" + proxy
+ ",总耗时:"
+ Duration.between((Temporal) result.getOptions().get("startime"), (Temporal) result.getOptions().get("endtime")).toMillis()
+ "ms");
}
} catch (IOException | InterruptedException e) {
shieldList.add(proxy);
}
}
);
threads[i].start();
}
//聚合线程,确保所有线程执行完成
for (Thread thread : threads) {
try {
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//移除低性能代理
pool.removeAll(shieldList);
System.out.println(pool.toString());
}
System.out.println("检测代理性能结束:" + DateUtil.dateToString(new Date(),"yyyy-MM-dd HH:mm:ss"));
}
/**
* 获取一个代理
* @return 返回代理
*/
public static InetSocketAddress getProxy() {
while (URIs.size() > 0 && pool.size() == 0) {
loadPool();
}
if (pool.size() > 0) {
Random random = new Random();
Proxy proxy = pool.get(random.nextInt(pool.size()));
return new InetSocketAddress(proxy.ip, proxy.port);
}
return null;
}
/**
* 删除一个代理
* @param ip 代理IP
* @param port 代理端口
*/
public static void removeProxy(String ip,int port) {
if (pool.isEmpty()) {
loadPool();
}
pool.removeIf(proxy -> proxy.ip.equals(ip) && proxy.port == port);
}
static class Proxy {
private final String ip;
private final int port;
public Proxy(String ip, int port) {
this.ip = ip;
this.port = port;
}
@Override
public String toString() {
return "Proxy{" +
"ip='" + ip + '\'' +
", port=" + port +
'}';
}
}
}
好了,核心功能都完成了,剩下得就是在前端显示了。
前端跟踪
前面我们已经从开始建项目到最后得站点内容抓取,后台代码已经编辑好了,唯独缺少一个前台按钮去触发它,所以我们现在需要做得,就是打开一个页面,写一个按钮,然后接收后台处理得数据即可。
定义路由
IndexController.java
package com.vtarj.pythagoras.crawler.controller;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
/**
* @Author Vtarj
* @Description 爬虫导航视窗
* @Time 2022/4/6 11:40
**/
@Controller
@RequestMapping(value = "/crawler")
public class IndexController {
/**
* 行政区划爬取
* @return 进入行政区划爬取页面,跳转至/views/page/region.html
*/
@RequestMapping(value = "region")
public String regionCrawler(){
return "region";
}
}
这里我们用到了Thymeleaf模板引擎,使用它来管理我们得页面。
定义页面
region.html
<!DOCTYPE html>
<html lang="zh">
<head>
<meta charset="UTF-8">
<script type="text/javascript" src="../js/jquery-3.6.0.min.js"></script>
<script type="text/javascript" src="../js/message.js"></script>
<title>行政区划爬取</title>
</head>
<body>
<div><input type="button" id="btn" onclick="opSwitch()" value="开始采集"/></div>
<div id="title" style="width: 100%;height: 60px;background: aqua"></div>
<div id="info" style="width: 100%;"></div>
</body>
<script type="text/javascript">
MsgAdapter.user = "RegionCrawler";
let count = 0;
MsgAdapter.receive = (d) => {
let o = $.parseJSON(d);
if (o["message"].indexOf("正在采集") === 0) {
$("#title").html(o["message"]);
} else {
count++;
//消息大于1000条后,清理历史消息,避免页面数据量太大造成页面卡死
if(count > 1000) {
count = 0;
$("#info").empty();
}
$("#info").prepend(o["message"] + "<br>");
}
}
function opSwitch(){
let uri;
if($("#btn").val() == "开始采集"){
$("#title").empty();
$("#info").empty();
uri = "/api/region/start";
$("#btn").attr("value","停止采集")
} else {
uri = "/api/region/stop";
$("#btn").attr("value","开始采集")
}
$.ajax({
type : "POST",
url : uri,
dataType : "json",
data : {},
success : function() {}
});
}
</script>
</html>至此,我们的实战就此完成了(记得自己去引入jquery组件哦),看看效果!
开始操作
访问:http://127.0.0.1:8000/crawler/region,点击开始按钮即可。
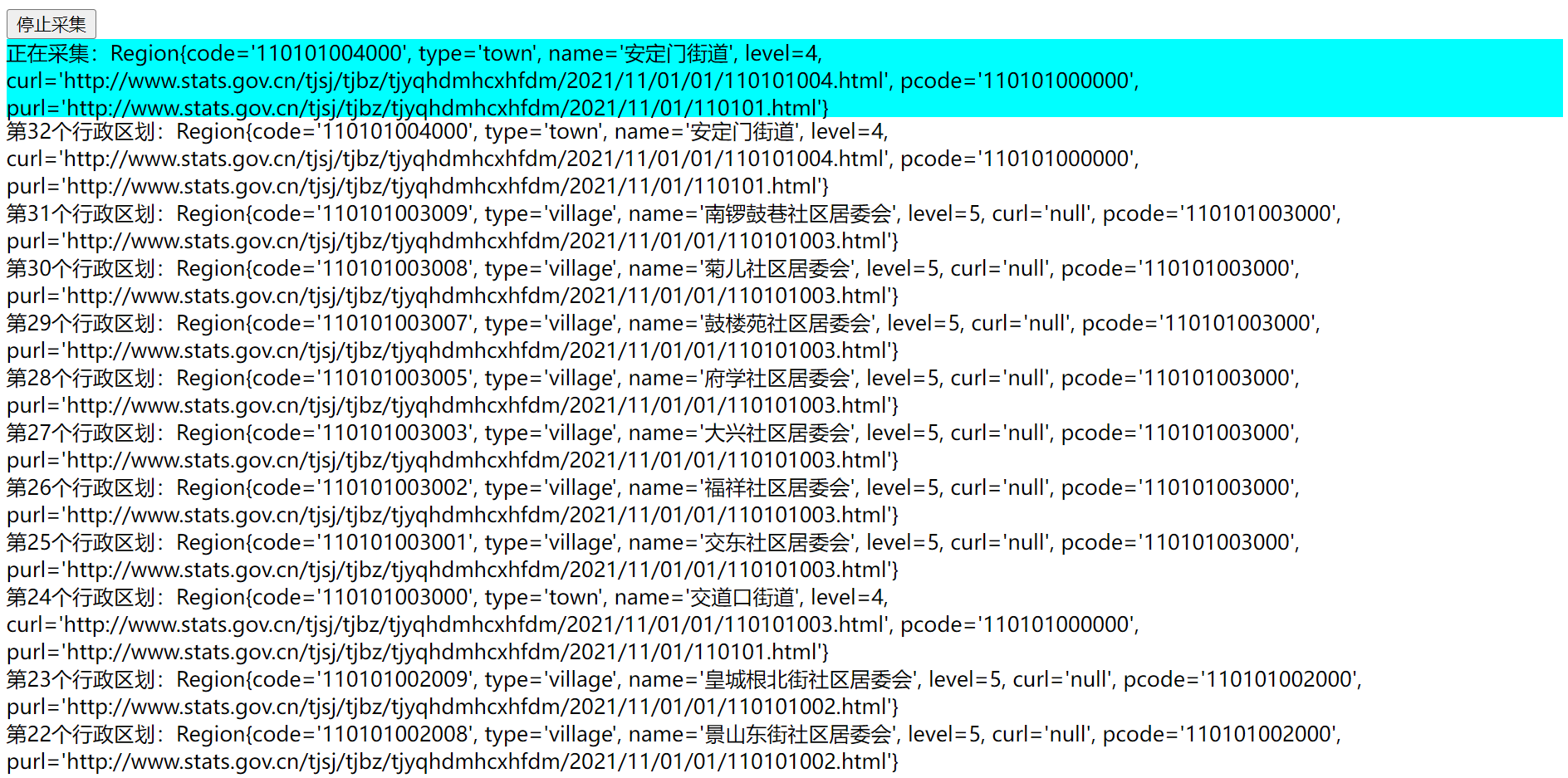
完结!!!