导读
前期在做一些机器学习的预研工作,对一篇迁移随机森林的论文进行了算法复现,其中需要对sklearn中的决策树进行继承和扩展API,这就要求理解决策树的底层是如何设计和实现的。本文围绕这一细节加以简单介绍和分享。
决策树是一种经典的机器学习算法,先后经历了ID3、C4.5和CART等几个主要版本迭代,sklearn中内置的决策树实现主要是对标CART树,但有部分原理细节上的差异,关于决策树的算法原理,可参考历史文章:畅快!5000字通俗讲透决策树基本原理。决策树既可用于分类也可实现回归,同时更是构成了众多集成算法的根基,所以在机器学习领域有着举重轻重的作用,关于集成算法,可参考历史文章:一张图介绍机器学习中的集成学习算法。
为了探究sklearn中决策树是如何设计和实现的,以分类决策树为例,首先看下决策树都内置了哪些属性和接口:通过dir属性查看一颗初始的决策树都包含了哪些属性(这里过滤掉了以"_"开头的属性,因为一般是内置私有属性),得到结果如下:
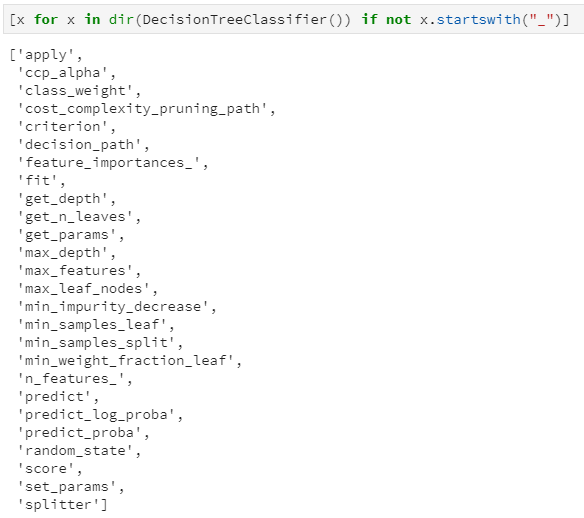
上述这些接口中,主要分为两类:属性和函数(这貌似说了句废话:了解编程语言中类的定义都知道,类主要是包括属性和函数的,其中属性对应取值,函数对应功能实现)。如果需要具体区分哪些是属性,哪些是函数,可以通过ipython解释器中的自动补全功能。
大致浏览上述结果,属性主要是决策树初始化时的参数,例如ccp_alpha:剪枝系数,class_weight:类的权重,criterion:分裂准则等;还有就是决策树实现的主要函数,例如fit:模型训练,predict:模型预测等等。
本文的重点是探究决策树中是如何保存训练后的"那颗树",所以我们进一步用鸢尾花数据集对决策树进行训练一下,而后再次调用dir函数,看看增加了哪些属性和接口:
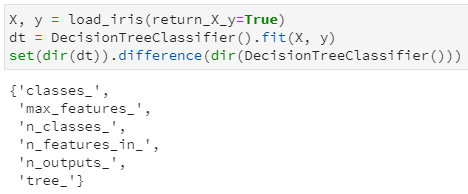
通过集合的差集,很明显看出训练前后的决策树主要是增加了6个属性(都是属性,而非函数功能),其中通过属性名字也很容易推断其含义:
classes_:分类标签的取值,即y的唯一值集合
max_features_:最大特征数
n_classes_:类别数,如2分类或多分类等,即classes_属性中的长度
n_features_in_:输入特征数量,等价于老版sklearn中的n_features_,现已弃用,并推荐n_features_in_
n_outputs:多输出的个数,即决策树不仅可以用于实现单一的分类问题,还可同时实现多个分类问题,例如给定一组人物特征,用于同时判断其是男/女、胖/瘦和高矮,这是3个分类问题,即3输出(需要区别理解多分类和多输出任务)
tree_:毫无疑问,这个tree_就是今天本文的重点,是在决策树训练之后新增的属性集,其中存储了决策树是如何存储的。
那我们对这个tree_属性做进一步探究,首先打印该tree_属性发现,这是一个Tree对象,并给出了在sklearn中的文件路径:

我们可以通过help方法查看Tree类的介绍:
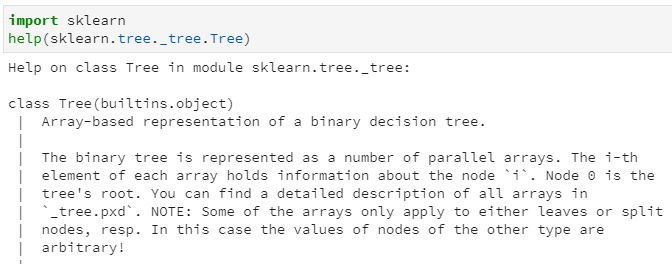
通过上述doc文档,其中第一句就很明确的对决策树做了如下描述:
Array-based representation of a binary decision tree.
即:基于数组表示的二分类决策树,也就是二叉树!进一步地,在这个二叉树中,数组的第i个元素代表了决策树的第i个节点的信息,节点0表示决策树的根节点。那么每个节点又都蕴含了什么信息呢?我们注意到上述文档中列出了节点的文件名:_tree.pxd,查看其中,很容易发现节点的定义如下:

虽然是cython的定义语法,但也不难推断其各属性字段的类型和含义,例如:
left_child:size类型(无符号整型),代表了当前节点的左子节点的索引
right_child:类似于left_child
feature:size类型,代表了当前节点用于分裂的特征索引,即在训练集中用第几列特征进行分裂
threshold:double类型,代表了当前节点选用相应特征时的分裂阈值,一般是≤该阈值时进入左子节点,否则进入右子节点
n_node_samples:size类型,代表了训练时落入到该节点的样本总数。显然,父节点的n_node_samples将等于其左右子节点的n_node_samples之和。
至此,决策树中单个节点的属性定义和实现基本推断完毕,那么整个决策树又是如何将所有节点串起来的呢?我们再次诉诸于训练后决策树的tree_属性,看看它都哪些接口,仍然过滤掉内置私有属性,得到如下结果:

当然,也可通过ipython解释器的自动补全功能,进一步查看各接口是属性还是函数:
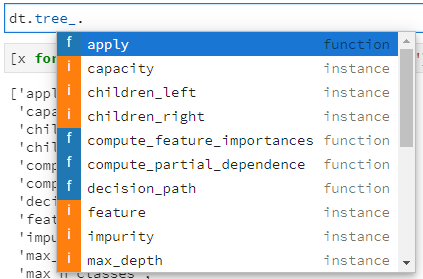
其中很多属性在前述解释节点定义时已有提及,这里需重点关注如下几个属性值:
node_count:该决策树中节点总数
children_left:每个节点的左子节点数组
children_right:每个节点的右子节点数组
feature:每个节点选用分裂的特征索引数组
threshold:每个节点选用分裂的特征阈值数组
value:落入每个节点的各类样本数量统计
n_leaves:叶子节点总数
大概比较重要的就是这些了!为了进一步理解各属性中的数据是如何存储的,我们仍以鸢尾花数据集为例,训练一个max_depth=2的决策树(根节点对应depth=0),并查看如下取值:
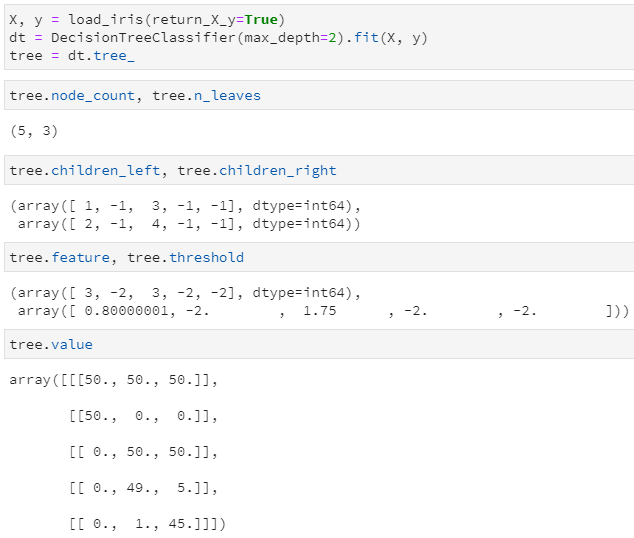
可知:
训练后的决策树共包含5个节点,其中3个叶子节点
通过children_left和children_right两个属性,可以知道第0个节点(也就是根节点)的左子节点索引为1,右子节点索引为2,;第1个节点的左右子节点均为-1,意味着该节点即为叶子节点;第2个节点的左右子节点分别为3和4,说明它是一个内部节点,并做了进一步分裂
通过feature和threshold两个属性,可以知道第0个节点(根节点)使用索引为3的特征(对应第4列特征)进行分裂,且其最优分割阈值为0.8;第1个节点因为是叶子节点,所以不再分裂,其对应feature和threshold字段均为-2
通过value属性,可以查看落入每个节点的各类样本数量,由于鸢尾花数据集是一个三分类问题,且该决策树共有5个节点,所以value的取值为一个5×3的二维数组,例如第一行代表落入根节点的样本计数为[50, 50, 50],第二行代表落入左子节点的样本计数为[50, 0, 0],由于已经是纯的了,所以不再继续分裂。
另外,tree中实际上并未直接标出各叶节点所对应的标签值,但完全可通过value属性来得到,即各叶子节点中落入样本最多的类别即为相应标签。甚至说,不仅可知道对应标签,还可通过计算数量之比得到相应的概率!
拿鸢尾花数据集手动验证一下上述猜想,以根节点的分裂特征3和阈值0.8进行分裂,得到落入左子节点的样本计数结果如下,发现确实是分裂后只剩下50个第一类样本,也即样本计数为[50, 0, 0],完全一致。

另外,通过children_left和children_right两个属性的子节点对应关系,其实我们还可以推断出该二叉树的遍历方式为前序遍历,即按照根-左-右的顺序,对于上述决策树其分裂后对应二叉树示意图如下:
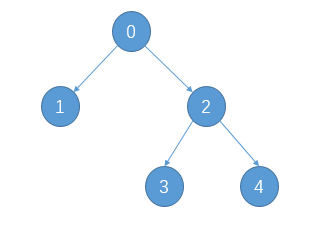

相关阅读: