ChatGPT狂飙160天,世界已经不是之前的样子。
新建了人工智能中文站https://ai.weoknow.com
每天给大家更新可用的国内可用chatGPT资源
今天分享下如何利用开源LLM大语言基座模型来管理自己本地的知识库,比如你电脑里的paper/学习资料等,打造属于自己的NewBing。
前言
ChatGPT等LLM大模型的知识延迟问题和幻想问题一直是两个非常难以解决的问题。而其背后的技术选型导致了这两个问题必然会存在。
-
知识延迟:由于大模型的知识来自于训练时喂给它的训练数据,且大模型很难做到实时更新,一般更新一次也得花上好几个月,所有它能接收到的数据必然是延迟的。
-
幻想问题:由于LLM采用的概率模型,即预测生成下一个字符概率是多少,所有或多或少的它在生成结果的时候都有定的可能出现错误。
那么如何解决这两个问题呢?目前比较好的方式就是利用大模型极强的语义理解能力,给大模型外挂一个知识库或者搜索引擎去解决这两个问题。如今的new_bing chat 则是采用这种技术路线,下图就是我问new_bing关于如何解决LLM知识延迟和幻想问题的相关截图:
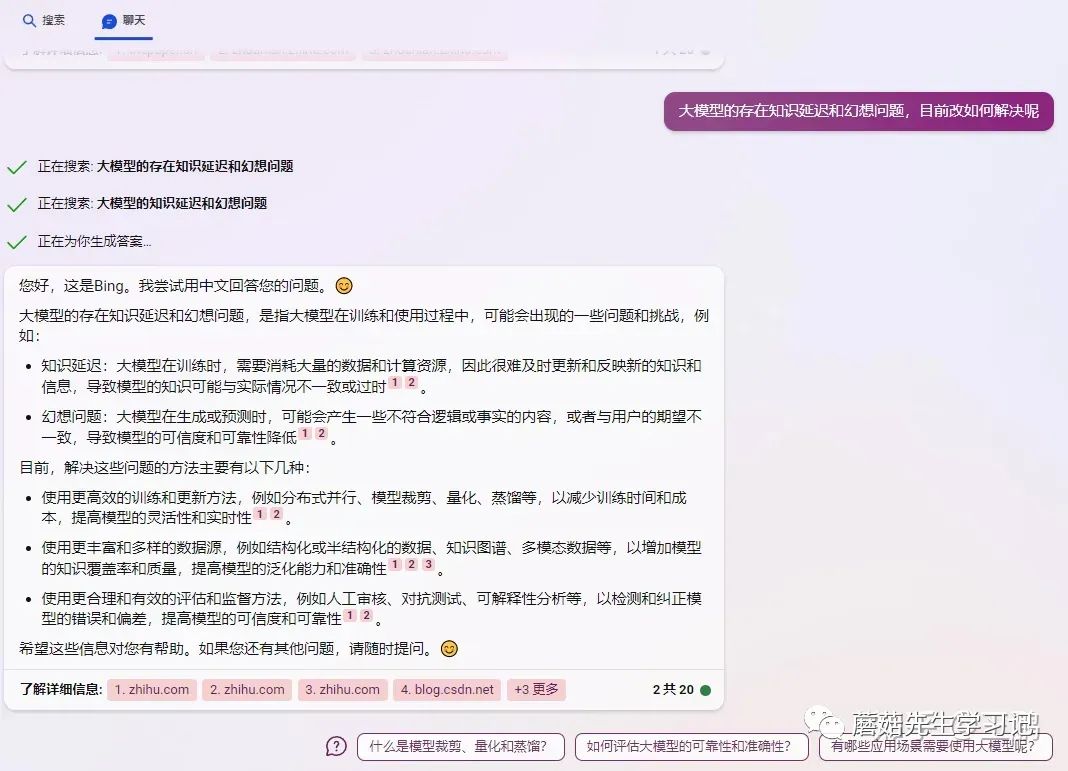
img
它的整个流程应该是:
-
1.利用bing去搜索和用户输入相关的文本。
-
2.采用合适的prompt + 上述步骤搜索到的文本 + 用户输入 ,一并输入给chatgpt
我猜是prompt是:利用上述资料回复用户问题(当然不可能这么简单)。
-
3.利用chatgpt的语义理解能力和内容总结能力生成的结果 。
其实解决大模型知识延迟和幻想的问题在我问newbing搜索结果的第二条给出了和上述流程比较契合的回答:
使用更丰富和多样的数据源,例如结构化或半结构化的数据、知识图谱、多模态数据等,以增加模型的知识覆盖率和质量,提高模型的泛化能力和准确性。
而今天笔者就介绍一下如何利用非结构化的文本知识库去减轻LLM的幻想问题。
基于知识库 + LLM的知识问答系统的流程和架构
具体的流程和上述new_bing chat的流程很像,但是多了一个步骤
1.将知识库的文本分块,并进行向量化;
2.用户的query向量化,并在知识库中进行检索,返回最相关的TOPN的文本块;
3.采用合适的prompt + 上述步骤搜索到的文本 一并输入给LLM;
4.利用LLM的语义理解能力和知识问答能力,生成问题的答案。
下图则是最近github上很火的一个基于chatGLM实现的一个基于知识库的问答系统的架构图:
https://github.com/imClumsyPanda/langchain-ChatGLM

原理图
基于知识库 + LLM的知识问答系统实战
本项目地址:https://github.com/wp931120/LongChainKBQA/tree/main其中,
-
1.文本分块模块:采用的是阿里开源nlp_bert_document-segmentation_chinese-base 语义分割模型对文本进行拆分;
-
2.文本向量化模块:采用的是text2vec-large-chinese 模型对文本向量化;
-
3.LLM模块:采用的是ChatYuan-large-v2 大语言模型;
-
4.整合模块:langchain可将上述模块轻松的进行整合,构建知识问答LLM。
1.文本分块和向量化模块
具体技细节就是利用nlp_bert_document-segmentation_chinese-base模型将文本分割后,利用text2vec-large-chinese向量化,最终构建一个faiss索引,并持久化。
from langchain.document_loaders import UnstructuredFileLoader, TextLoader, DirectoryLoader
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from config import Config
from utils.AliTextSplitter import AliTextSplitter
class DocumentService(object):
def __init__(self):
self.config = Config.vector_store_path
self.embeddings = HuggingFaceEmbeddings(model_name=Config.embedding_model_name)
self.docs_path = Config.docs_path
self.vector_store_path = Config.vector_store_path
self.vector_store = None
def init_source_vector(self):
"""
初始化本地知识库向量
:return:
"""
loader = DirectoryLoader(self.docs_path, glob="**/*.txt", loader_cls=TextLoader)
# 读取文本文件
documents = loader.load()
text_splitter = AliTextSplitter()
# 使用阿里的分段模型对文本进行分段
split_text = text_splitter.split_documents(documents)
# 采用embeding模型对文本进行向量化
self.vector_store = FAISS.from_documents(split_text, self.embeddings)
# 把结果存到faiss索引里面
self.vector_store.save_local(self.vector_store_path)
def load_vector_store(self):
self.vector_store = FAISS.load_local(self.vector_store_path, self.embeddings)
if __name__ == '__main__':
s = DocumentService()
###将文本分块向量化存储起来
s.init_source_vector()
2.LLM模块
加载ChatYuan-large-v2 大语言模型,当然也可以选择ChatGLM或者Moss等。
from typing import List, Optional
from langchain.llms.base import LLM
from langchain.llms.utils import enforce_stop_tokens
from transformers import AutoModel, AutoTokenizer
from config import Config
class LLMService(LLM):
max_token: int = 10000
temperature: float = 0.1
top_p = 0.9
history = []
tokenizer: object = None
model: object = None
def __init__(self):
super().__init__()
@property
def _llm_type(self) -> str:
return "LLM"
def _call(self,
prompt: str,
stop: Optional[List[str]] = None) -> str:
response, _ = self.model.chat(
self.tokenizer,
prompt,
history=self.history,
max_length=self.max_token,
temperature=self.temperature,
)
if stop is not None:
response = enforce_stop_tokens(response, stop)
self.history = self.history + [[None, response]]
return response
def load_model(self, model_name_or_path: str = "ClueAI/ChatYuan-large-v2"):
"""
加载大模型LLM
:return:
"""
self.tokenizer = AutoTokenizer.from_pretrained(
Config.llm_model_name,
trust_remote_code=True
)
self.model = AutoModel.from_pretrained(model_name_or_path, trust_remote_code=True)
self.model = self.model.eval()
if __name__ == '__main__':
chatLLM = LLMService()
chatLLM.load_model()
3.知识问答模块
from langchain.chains import RetrievalQA
from langchain.prompts.prompt import PromptTemplate
from config import Config
from document import DocumentService
from llm import LLMService
class LangChainApplication(object):
def __init__(self):
self.config = Config
self.llm_service = LLMService()
###加载llm和知识库向量
print("load llm model ")
self.llm_service.load_model(model_name_or_path=self.config.llm_model_name)
self.doc_service = DocumentService()
print("load documents")
self.doc_service.load_vector_store()
def get_knowledge_based_answer(self, query,
history_len=5,
temperature=0.1,
top_p=0.9,
top_k=1,
chat_history=[]):
#定义prompt
prompt_template = """基于以下已知信息,简洁和专业的来回答用户的问题。
如果无法从中得到答案,请说 "根据已知信息无法回答该问题" 或 "没有提供足够的相关信息",不允许在答案中添加编造成分,答案请使用中文。
已知内容:
{context}
问题:
{question}"""
prompt = PromptTemplate(template=prompt_template,
input_variables=["context", "question"])
self.llm_service.history = chat_history[-history_len:] if history_len > 0 else []
self.llm_service.temperature = temperature
self.llm_service.top_p = top_p
# 声明一个知识库问答llm,传入之前初始化好的llm和向量知识搜索服务
knowledge_chain = RetrievalQA.from_llm(
llm=self.llm_service,
retriever=self.doc_service.vector_store.as_retriever(
search_kwargs={"k": top_k}),
prompt=prompt)
knowledge_chain.combine_documents_chain.document_prompt = PromptTemplate(
input_variables=["page_content"], template="{page_content}")
knowledge_chain.return_source_documents = True
### 基于知识库的问答
result = knowledge_chain({"query": query})
return result
def get_llm_answer(self, query=''):
prompt_template = """请回答下列问题:
{}""".format(query)
### 基于大模型的问答
result = self.llm_service._call(prompt_template)
return result
if __name__ == '__main__':
application = LangChainApplication()
print("大模型自己回答的结果")
result = application.get_llm_answer('迪丽热巴的作品有什么')
print(result)
print("大模型+知识库后回答的结果")
result = application.get_knowledge_based_answer('迪丽热巴的作品有什么')
print(result)
最终上述代码运行的结果如下:加入知识库后结果比没加之前好了很多,而且也能给出参考的文档是哪一篇。
是不是和new_bing chat返回结果很像。

示例结果
当然如果知识库里面没有结果,问答系统还是很答非所问,甚至会乱拼接知识。
目前也没有特别好的方式去完全杜绝这个问题,唯一能做的就是微调大模型或者调整你的prompt,prompt的微调也是一个比较重要的课。
结语
至此本文介绍了一下:
-
如何利用 知识库+LLM去构建一个基于知识库的问答系统的基本架构,而其中很多模块都可以进行丰富和优化,比如文本分块模块,文本向量化模块,LLM模块都可以替换成其他的模型。
-
如何利用langchain整合这些模块,langchain现在在ai圈非常火,并且还在成长。大家可以关注一下这个开源库。
大模型现在还有很多问题待解决,而且其的应用之路还有很多地方可以去探索,希望大家借此文章了解一下大模型的缺陷以及一些应用方法。
参考
https://github.com/imClumsyPanda/langchain-ChatGLM
https://github.com/yanqiangmiff
ChatGPT狂飙160天,世界已经不是之前的样子。
新建了人工智能中文站https://ai.weoknow.com
每天给大家更新可用的国内可用chatGPT资源