提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
图处理以及分布式图处理框架
自2018年以来,无论是图处理还是图神经网络,他们的搜索趋势都在不断增长,已然成为热门领域。
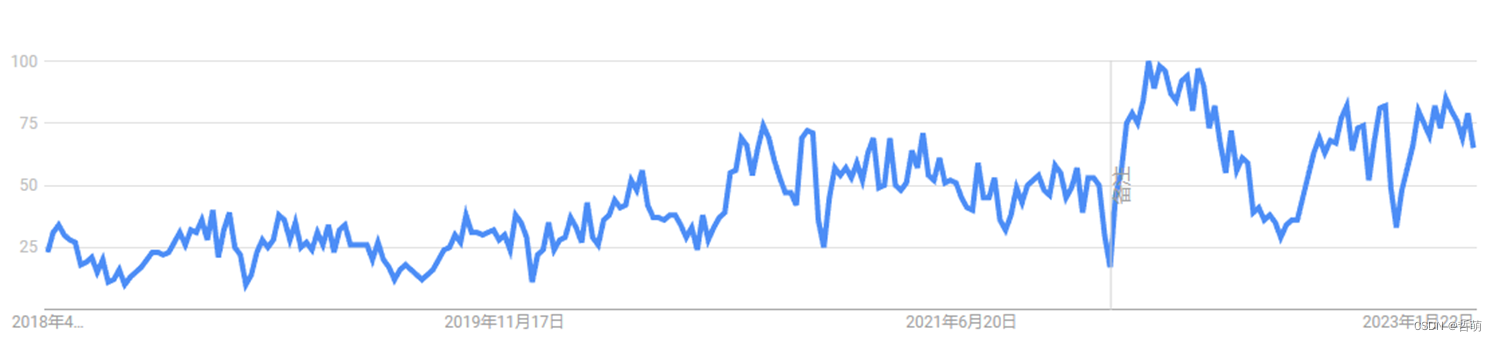
图处理搜索结果
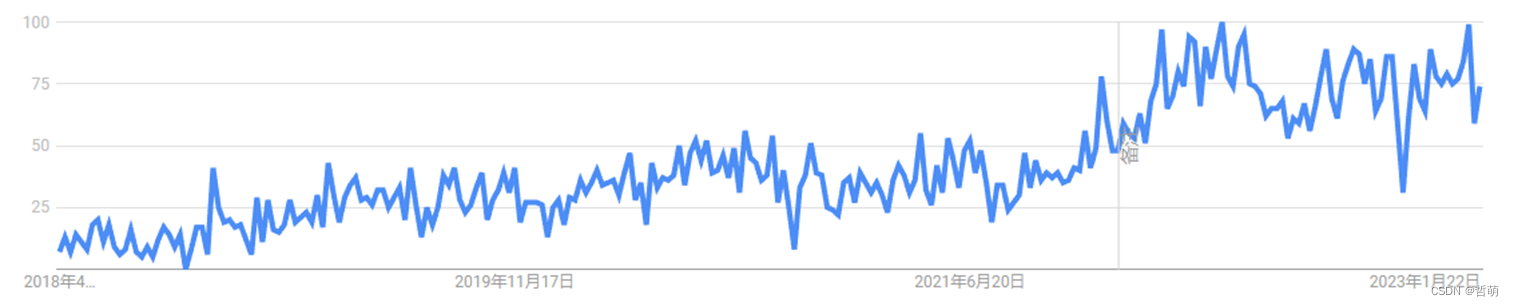
图神经网络搜索结果
一、图数据是什么?
数据项作为顶点,不同数据项间关系被抽象为边,这种可以被抽象成用图模式描述的数据。
图处理(Graph Processing)是基于图模式进行巨量、稀疏、超维关联的挖掘与分析过程。当前大数据的机器学习和深度学习都依赖于图计算,图处理已经成为大数据处理的主流模式之一。

二、单机图处理
单机图处理有很多种应用,其中应用较为广泛的可以分为图分析、图遍历(图搜索)、图聚类以及图学习,此外还包括图着色等为专门问题设计的算法。
1.PargeRank/图分析
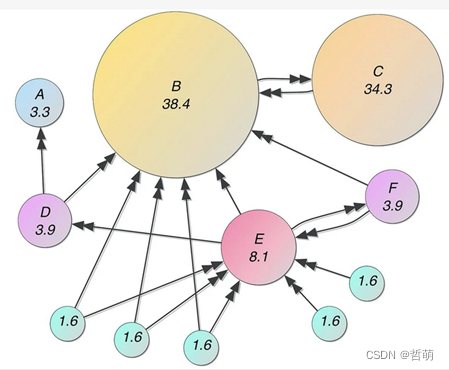
pagerank旨在根据所有链接到网站A的其他网站Ti的重要性得分进行加权平均得出网站A的重要性,进而将最重要的网页优先展示给用户。诸如此类的算法被称为图分析,图分析使用基于图的方法来分析连接的数据。我们可以:查询图数据,使用基本统计信息,可视化地探索图、展示图,或者将图信息预处理后合并到机器学习任务中。图的查询通常用于局部数据分析,而图计算通常涉及整张图和迭代分析。
2.单源最短路径 SSSP (Single Source Shortest Path)/图遍历
给定一个点 s ,SSSP算法算出在有向有权图中s节点到其余节点的最短距离(例如迪杰斯塔拉算法);DFS、BFS也属于图遍历,也称为图搜索算法。
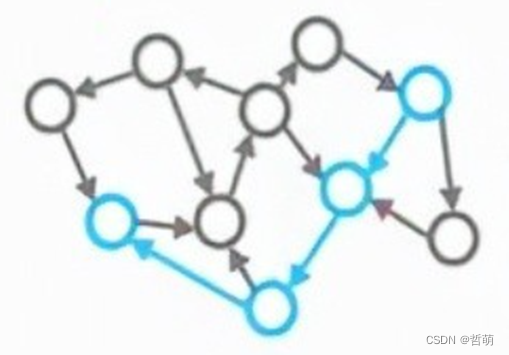
3.社区发现算法/图聚类
社区由一组顶点构成,内部顶点之间的关系(边)远多于与社区外部顶点之间的边。
社区发现算法用于发现社区中群体行为或者偏好,对顶点进行划分,同一社区内部的节点链接较为紧密,社区之间的节点链接较为稀疏。
4.图着色/着色问题
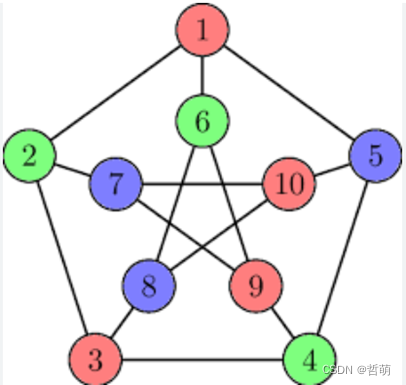
用于计算四色定理或五色定理。计算将一张图上的每个顶点染色,使得相邻的两个点颜色不同,最小需要的颜色数。可以用来解决不同时分配彼此依赖的相同资源的问题。
4.图学习
图学习,即基于图的机器学习与深度学习,旨在将图的结构信息整合到学习模型中。随着以深度学习为代表的人工智能技术广泛应用,且图结构具有更强的表达能力,图学习成为了一个热点话题,也在因果关系、可解释性方面带来了突破进展。主要可以用来:
- 研究拓扑结构和连接性
- 群体检测
- 识别中心节点
- 预测缺失的节点和边
- 预测节点值与边权值
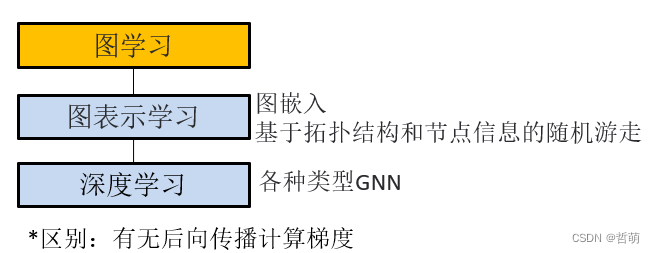
4.1图表示学习
图表示学习的主要目标就是:将节点编码为一个低维向量,包含它们的图位置和它们的局部图邻域结构。
——Hamilton W L. 《图表示学习》
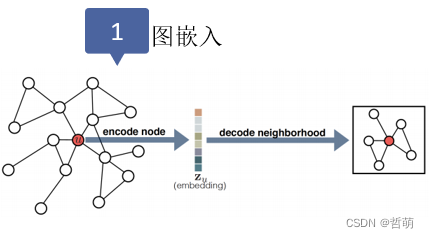
图嵌入目标是把原网络的节点投射到Embedding space后,u和v的embedding的相似性要尽可能接近原网络中的任意u, v节点的相似性。主流投影方法如下表所示:

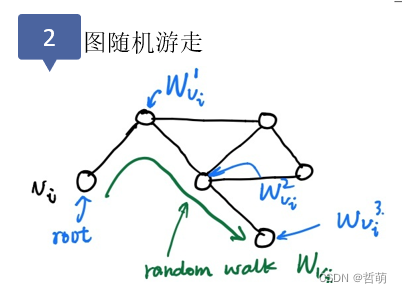
依据扩散现象提出的图表示学习方法,从一个或一系列顶点开始遍历一张图。
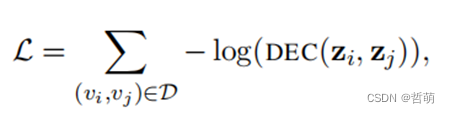

4.2图神经网络
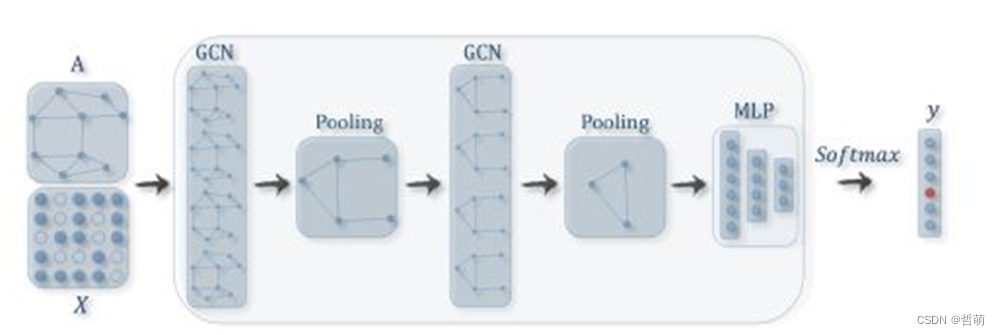
GNN与其他三者最大区别是有反向传播梯度计算过程(即其本质是DNN)
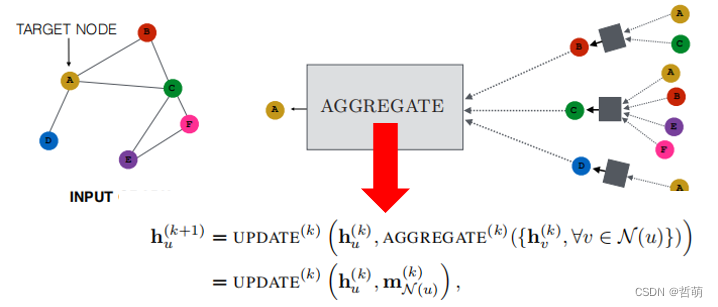

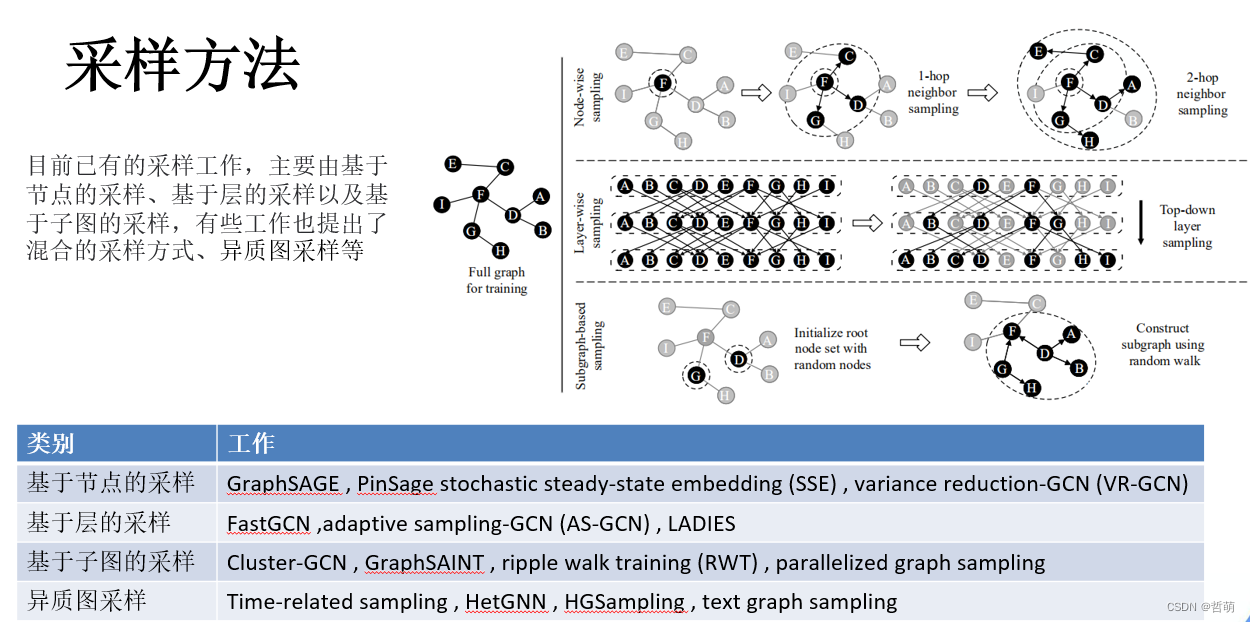
5.图采样
除了经典图计算和图学习外,对图的拓扑、节点进行变更的操作也是图处理的一个分支,其中图采样便是对图数据中的节点或者边,按照一定的规则进行筛选,生成新的子图数据。
子图采样既可以用于针对筛选节点的应用(如k近邻,邻居筛选),也可以用于优化图计算:即,用传统方法训练大规模图的GCN模型需要很高的计算和存储成本,这时可以采样出最重要的K个节点进行近似的计算,计算结果与全图计算差异不大。
采样可以用该公式表示:S N (v) = Sampling(k) (N (v))
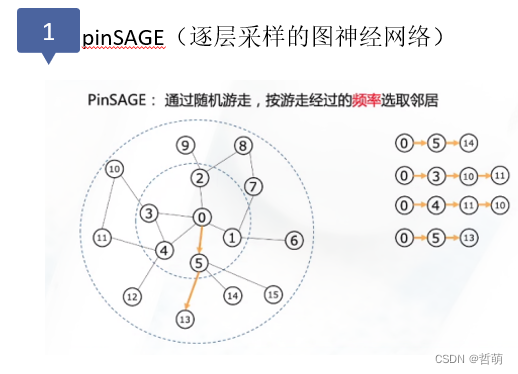
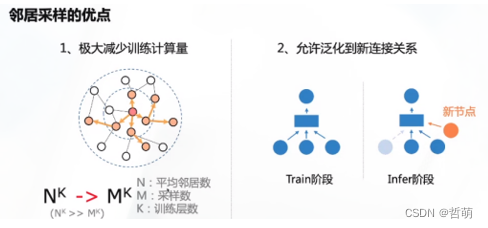
6.图划分
对一个大规模的图进行子图划分也是图处理的一个分支,被广泛应用于并行图计算、电网规划、地理分区规划、生物信息网络以及社交媒体等领域。
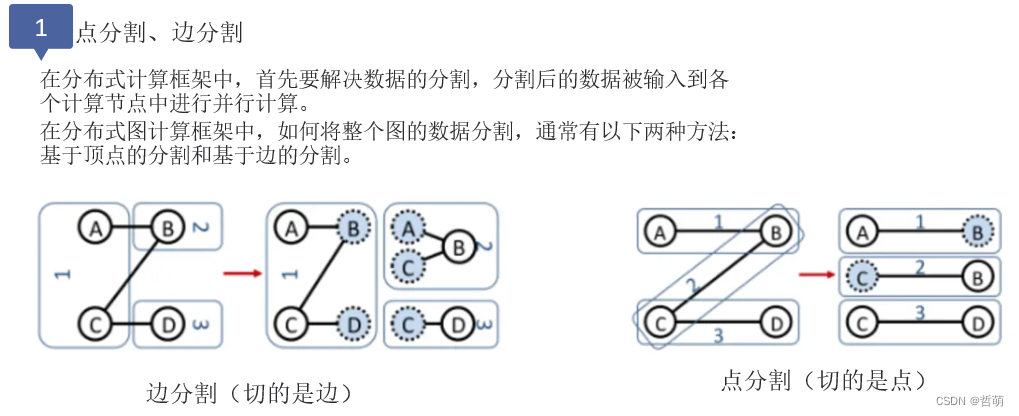
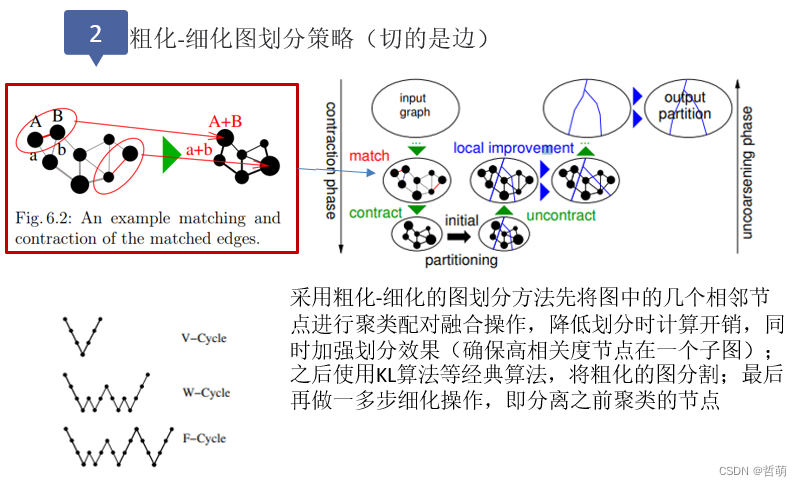
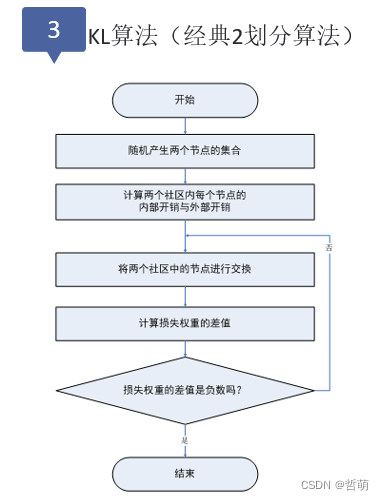
图划分的整体分类以及图划分的目标如下:
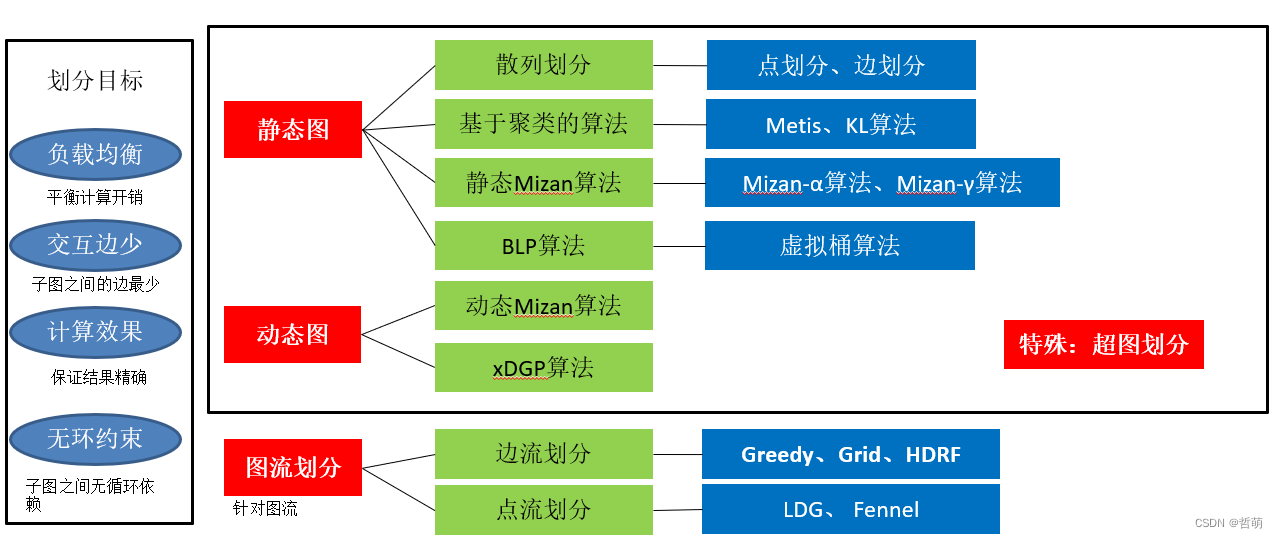
三、分布式图处理
处于1,、大规模图数据单机难以处理,比如针对社交网络的万亿边图,图上节点与边所携带的属性值会让显存与内存都难以承受;2、单机图处理运行速度慢,多个batch或者巨大规模的图需要单个机器非常长的处理时间,而多机器分别处理batch会大大加速。
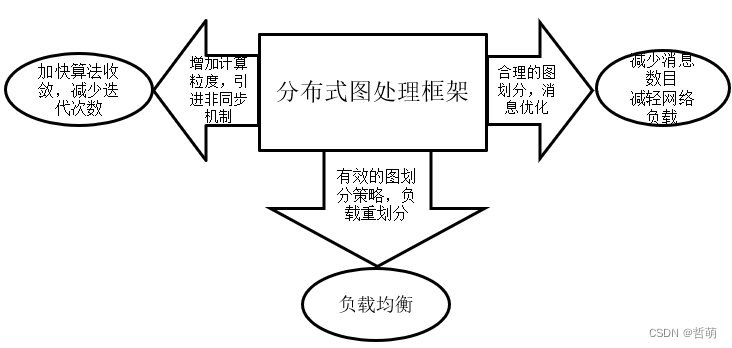
由于图数据具有依赖性强、不规则分布、结构多样等特点,导致传统的数据并行系统难以适用。因此需要按照一定的粒度切分(如每个机器算一定数量的节点或者边),通常来讲,分布式图计算有以下几个主要研究方向:
- -计算粒度:不同的计算粒度影响图算法的编程方式、任务划分以及通信方式。例如,以顶点为计算粒度的系统结构简单、易于实现且算法表达能力强,但是不利于算法收敛且网络负载较重;
以边作为计算粒度可以减少对边的随机访问率,提高图遍历算法的性能,但是在分布式环境下缺少有效的实践 - 同步机制:任务同步机制决定并行作业的运行模式以及调度策略(如同步更新或异步更新)。根据图迭代计算过程中每个超步之间是否有明确界限,或者说不同超步之间是否交错运行,可以将分布式图处理系统所采用的调度模式分为 3 种:同步调度模式、异步模调度模式和混合调度模式。
- 通信方式:在分布式图处理系统中, 存在很多节点消息传输或同步通信。当图数据规模巨大且执行通信密集的图计算时,计算节点之间的通信量会明显上升.如果没有高效的通信机制,网络通信会成为整个系统的瓶颈。
- 图划分:图数据划分是进行分布式图处理的基础,划分结果的好坏严重影响着分布式图处理系统的性能。一个有效的图划分策略能够在使整个系统达到负载均衡的同时,尽可能地减少网络开销。
- 存储方式:图存储结构决定了图数据的计算方式与存储空间。优化的存储结构(例如CSR方法)可降低程序的时间复杂度 ,提高求解效率,甚至可以加快图划分、采样的速度。
1.分布式图处理—以PageRank为例
1.1 Pregel
2010年Malewicz等人为分布式图计算设计了成熟的计算框架Pregel,采用BSP并行模式,每一轮计算都需要同步。
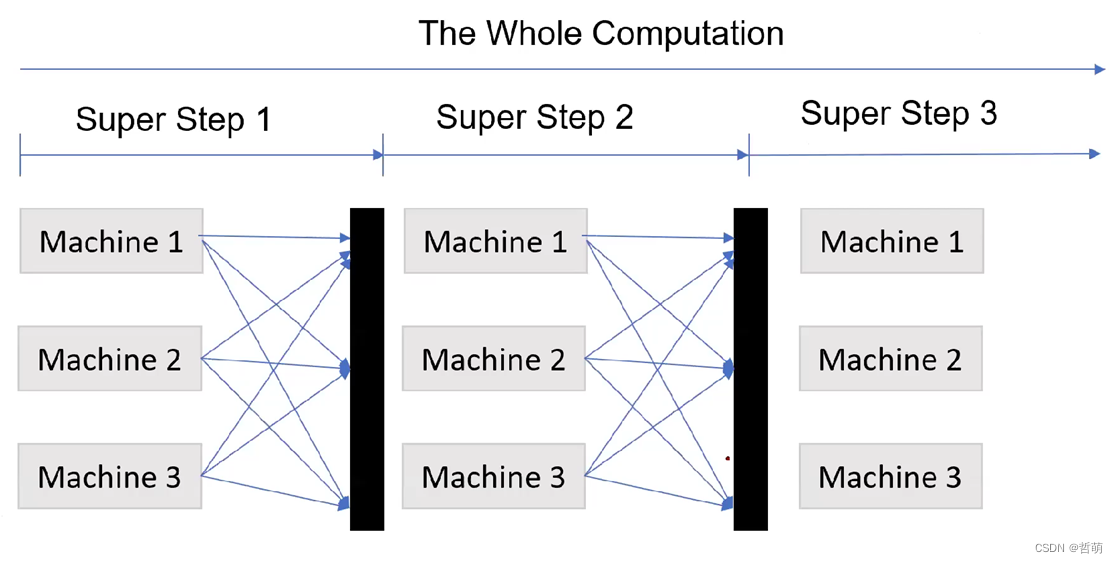
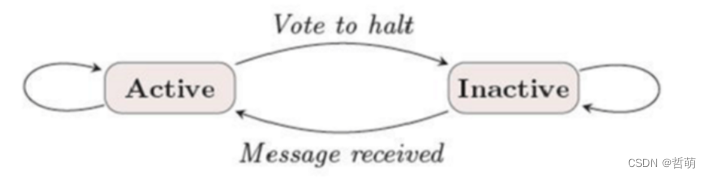
每个节点都有两个状态,活跃与不活跃。
任务分为超步,每个超步内多个节点并发执行,并最终同步。同步过程可以使用parameter server或者all-reduce同步方法
计算过程
Pregel中的计算分为一个个“superstep”,这些”superstep”中执行流程如下:
- 首先输入图数据,并进行初始化,都将自己设置为活跃。
- 将每个节点均设置为活跃状态。每个节点根据预先定义好的send函数,以及方向(边的正向、反向或者双向)向周围的节点发送信息。
- 每个节点接收信息如果发现需要计算则根据预先定义好的计算函数对接收到的信息进行处理,这个过程可能会更新自己的信息。如果接收到消息但是不需要计算则将自己状态设置为不活跃。
- 每个活跃节点按照send函数向周围节点发送消息。
- 下一个superstep开始,像步骤3一样继续计算,直到所有节点都变成不活跃状态,整个计算过程结束。
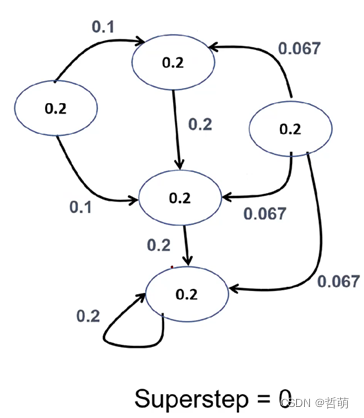
第一步中,每个节点都是活跃的,发送自己的数值/出度给邻居
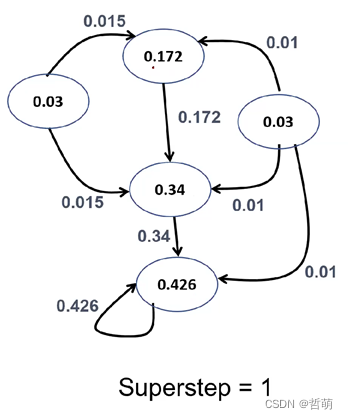
第二步, 每个节点按照0.15/5+(1-0.15)*(总共接收到的数值)进行计算
这样第二个超级步以后,某些节点完成了计算
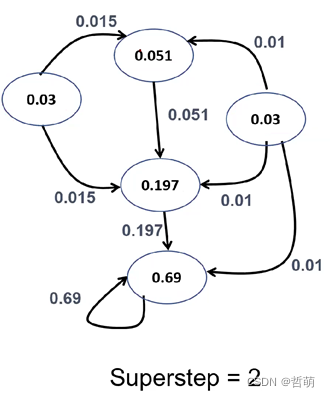
第三步,有些节点(比如那个0.03)已经完成了计算,以此类推
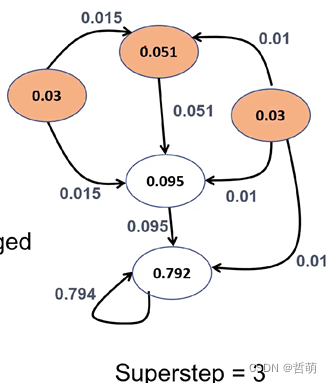
一些迭代以后,某些节点就变成了不活跃状态
1.2PowerGraph
PowerGraph GAS(Gather Apply Scatter)三阶段模型
首先将大图按点割(vertex-cut)的方法发送给各个计算机器
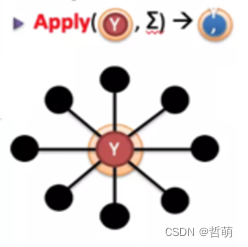
Gather:在各个计算机器上,搜集这个图数据中某个顶点的相邻边和顶点的数据进行计算(例如在PageRank算法中计算某个顶点相邻的顶点的数量)

Apply:将各个机器计算得到的数据统一发送到某一个计算机器(例如在PageRank算法中各计算节点计算出来的同一顶点的相邻顶点数),由这个中心机器对图的节点的数据进行汇总求和计算,这样就得到这个图顶点的所有相邻节点总数。
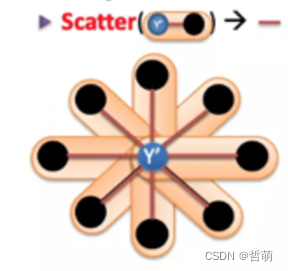
Scatter:将中心计算节点计算的图顶点的所有相邻节点总数发送更新给各个计算节点,这些收到更新信息的节点将会更新本计算节点中与这个图顶点相邻的顶点以及边的相关数据。
2.分布式图处理框架
由于各种图处理任务计算过程完全不一样,所以单一的框架不足以支撑分布式图处理的发展。除了2010年Malewicz等人为分布式图计算设计的Pregel框架,还陆续出现了PowerGraph(OSDI2012)、GraphX(OSDI2014)等针对不同应用的计算框架。这些分布式框架包含了不同的图划分策略,同步或者异步的更新策略,存储方式等
3.分布式图处理框架优化目标

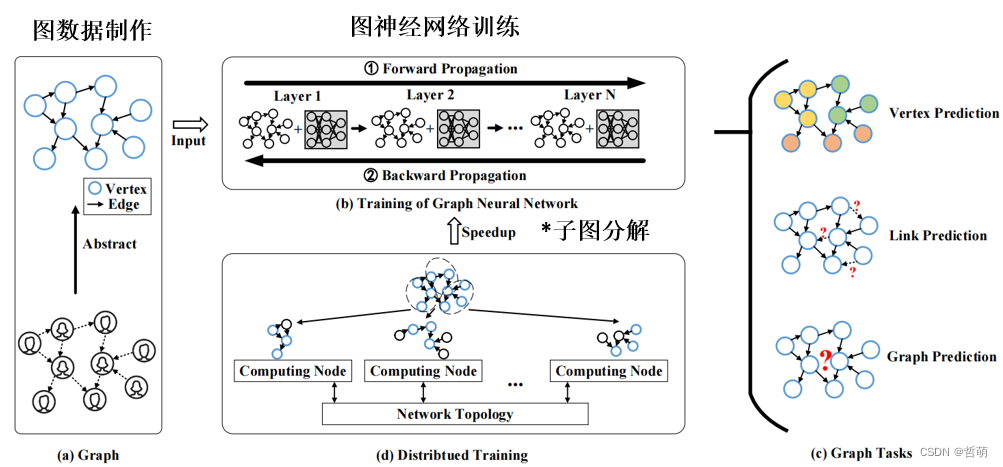
4.分布式图神经网络
训练大规模图神经网络的计算、存储复杂度高. 真实世界中的尺寸都非常大, 而且由于顶点之间具有复杂的依赖性, 随着图神经网络层数的增加, 计算成本和内存空间需求呈指数级增长.
4.1全图输入的分布式图神经网络
每个worker都使用不切割的全图进行训练,该方法可以提高整体使用的batch_size大小,使loss曲线下降更加平滑
(一般全图训练大多会配合采样)
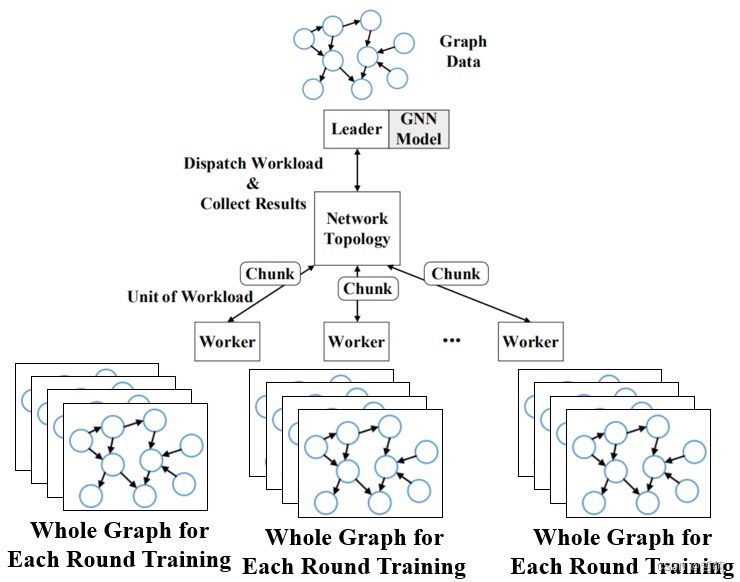
4.2子图输入的分布式图神经网络
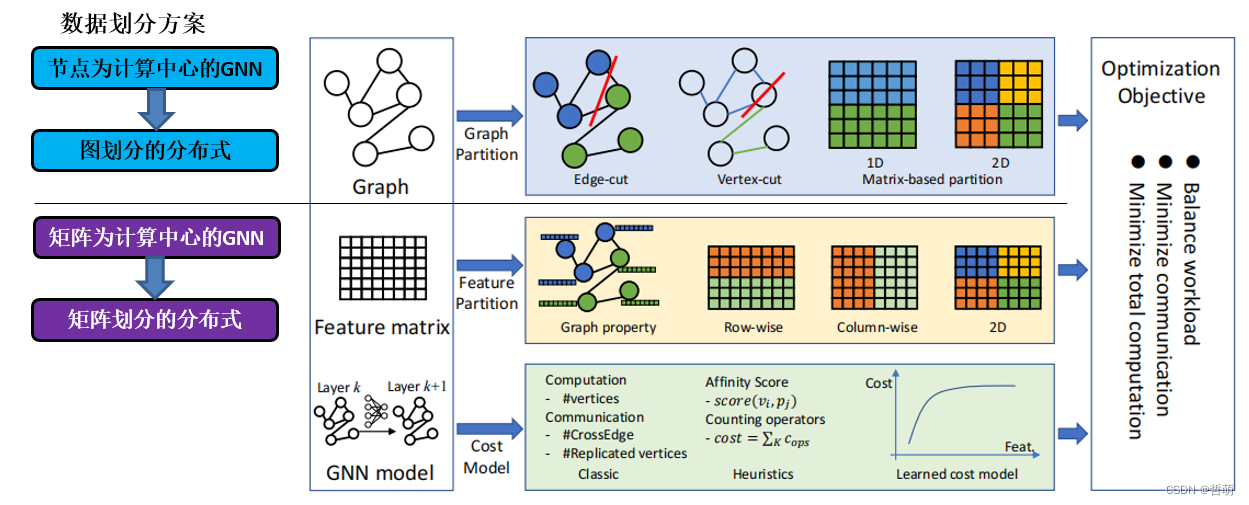
目前有两种子图划分思路
一种是以节点为对象进行划分,这种方法对应了GNN以节点邻居加法为主的算法
另一种是按照矩阵划分,这种方法对应了GNN以矩阵计算为主的算法
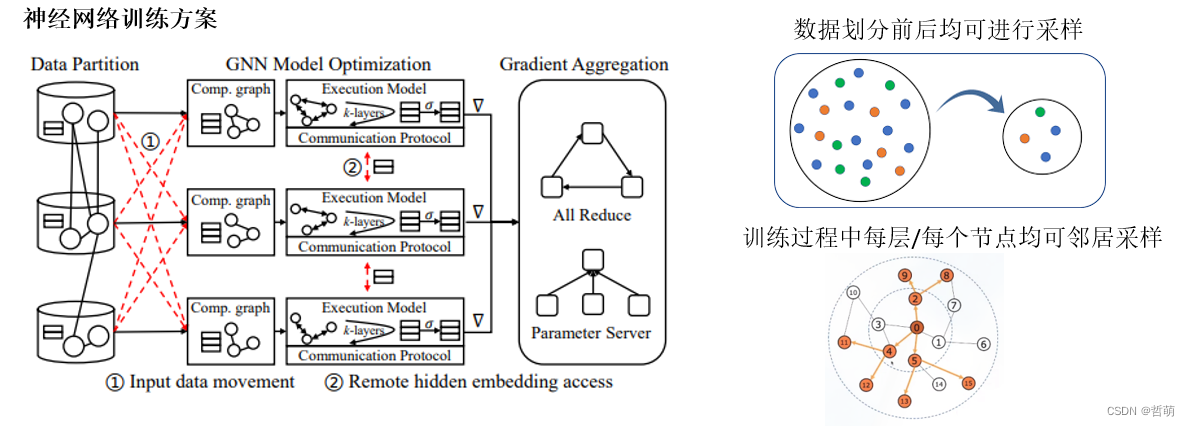
4.3梯度聚合过程
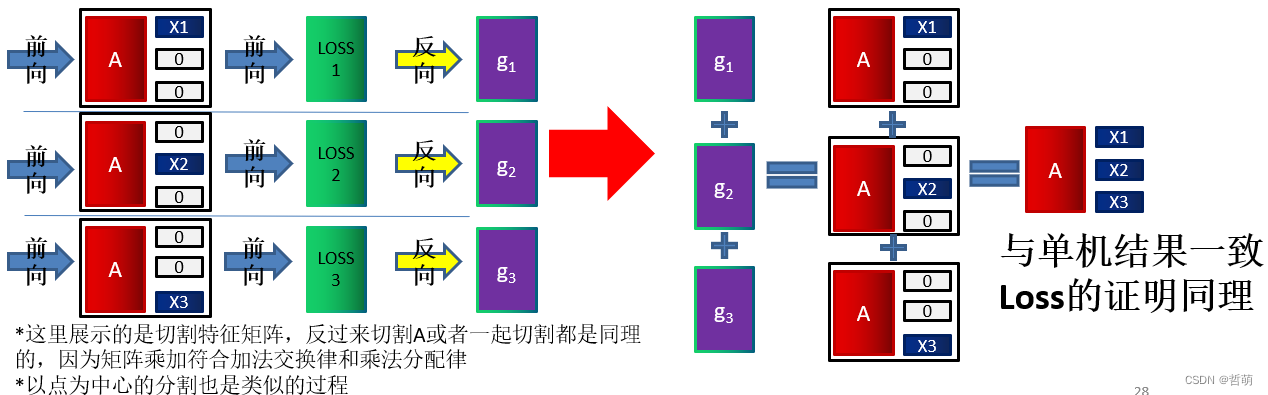
划分图的分布式GNN中每个worker会计算出对应子图的梯度,已证明:将各个子图训练出来的梯度求和,即是整体大图训练得到的梯度。因为每个子图学习的结果相当于原本整体大图计算中的整体矩阵乘法的一部分,所以分布式计算的过程相当于是并行的矩阵计算,而梯度值正相关于每个矩阵的并行乘法结果,因此多个子图的分布式GNN计算逻辑与并行矩阵乘法计算逻辑相同;所有子图计算的loss或梯度求和就是原loss或梯度。
证明过程如下:设邻接矩阵A,输入特征 X = [ X 1 , X 2 , X 3 ] T X=[X1,X2,X3]^T X=[X1,X2,X3]T相当于将特征矩阵按行划分为3份(1D划分)
梯度 g i = ∂ l o s s ∂ H ∂ W A X i ∂ W = ∂ l o s s ∂ H A X i g_i=\frac{\partial loss}{\partial H}\frac{\partial WAX_i}{\partial W}=\frac{\partial loss}{\partial H}AX_i gi=∂H∂loss∂W∂WAXi=∂H∂lossAXi,损失函数 L o s s = 1 n b a t c h s i z e ∑ b a t c h s i z e H ( A X i ) Loss=\frac{1}{n_{batch_size}}\sum_{batch_size}H(AX_i) Loss=nbatchsize1∑batchsizeH(AXi) 都和 A X i AX_i AXi成正比
4.4基于采样的分布式GNN
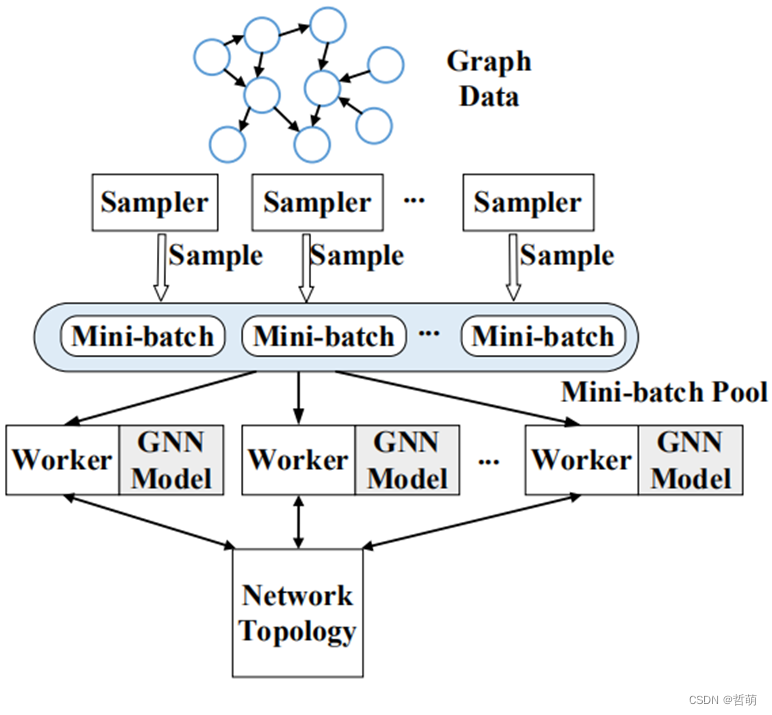
训练前采样(individual-sample-based )是指:只在训练开始前对全图采样出各自worker的mini-batch,不考虑后续训练过程中的采样节点间通信。
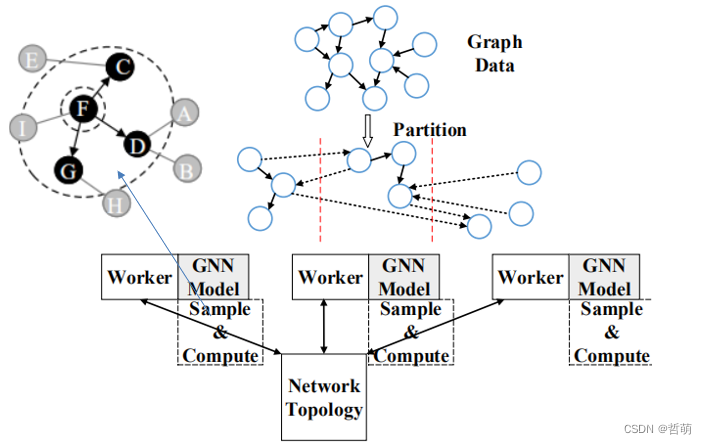
训练间连续(joint-sample-based)是指:在预处理过程中,每个worker对自己的子图进行采样以生成mini-batch,并在mini-batch上进行正向传播和反向传播以获得梯度。然后,它们通过与其他worker通信同步更新模型。
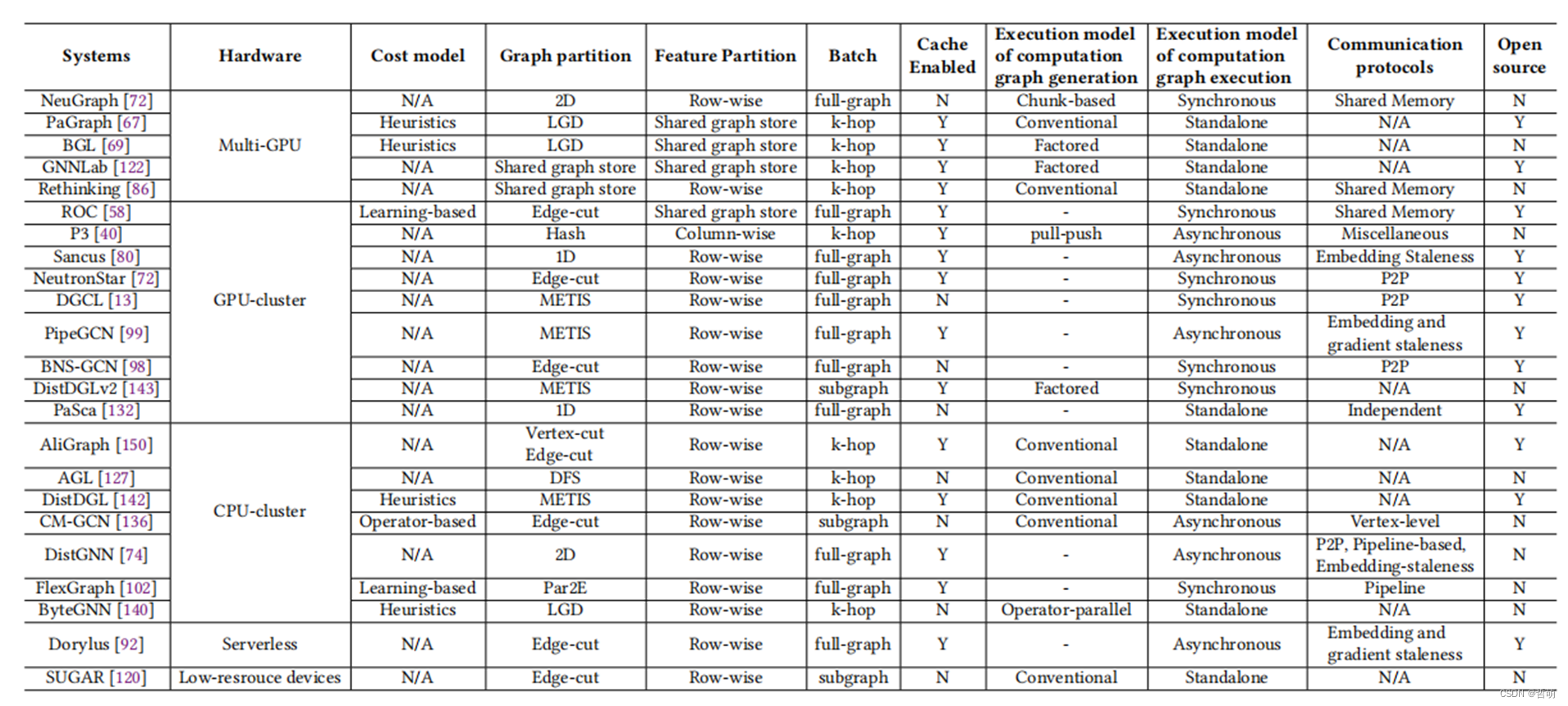
4.5目前已有分布式GNN框架总结
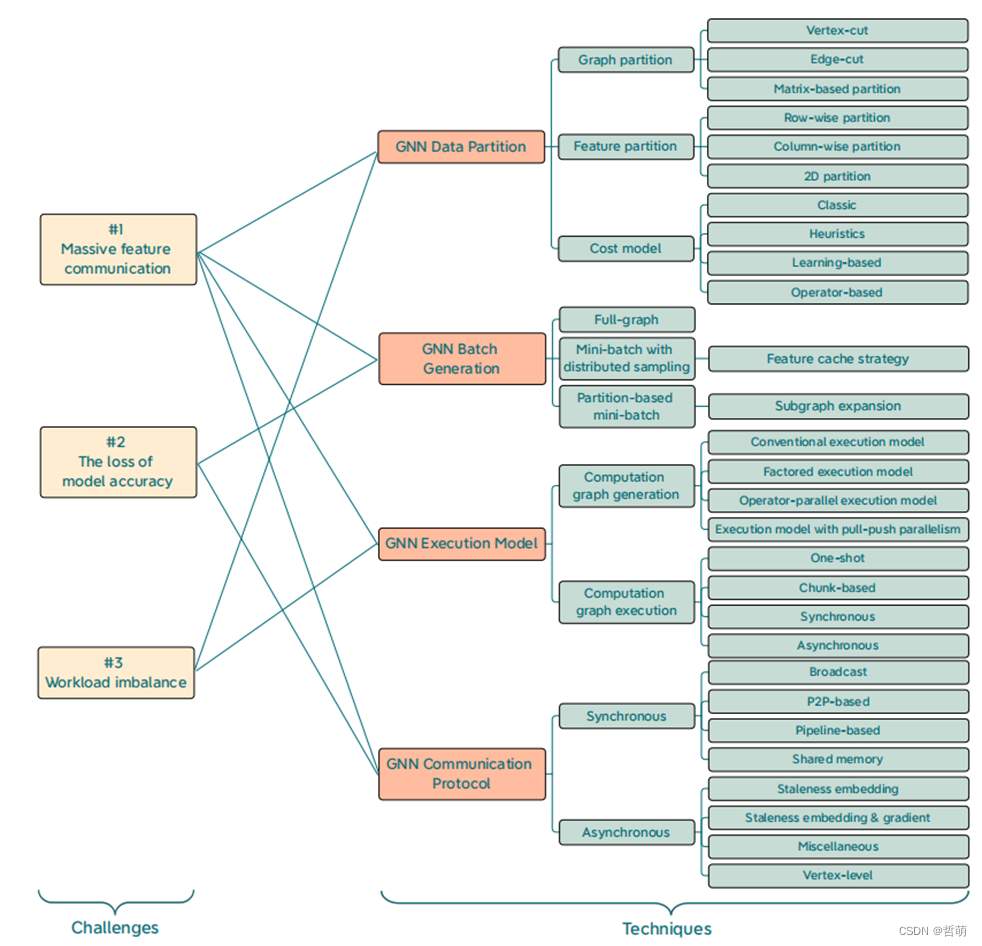
4.6已有的一些优化总结
4.6.1计算粒度优化
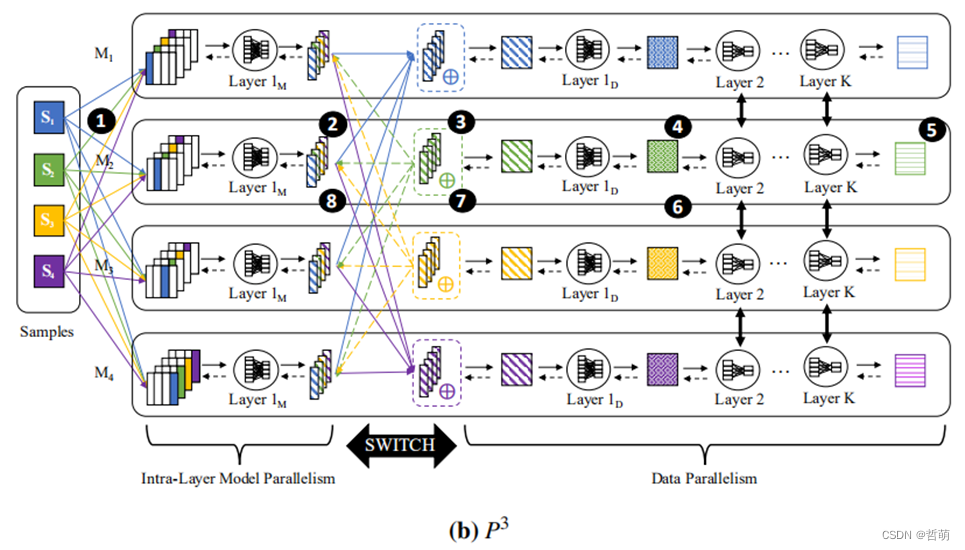
代表工作1:Gandhi S, Iyer A P. P3: Distributed Deep Graph Learning at Scale[C]//OSDI. 2021: 551-568.
在特征维度不大且显存瓶颈在特征时使用,每个机器计算所有节点的某一维度特征,既能做到输入数据的切分,又避免了多个子图间的通信。
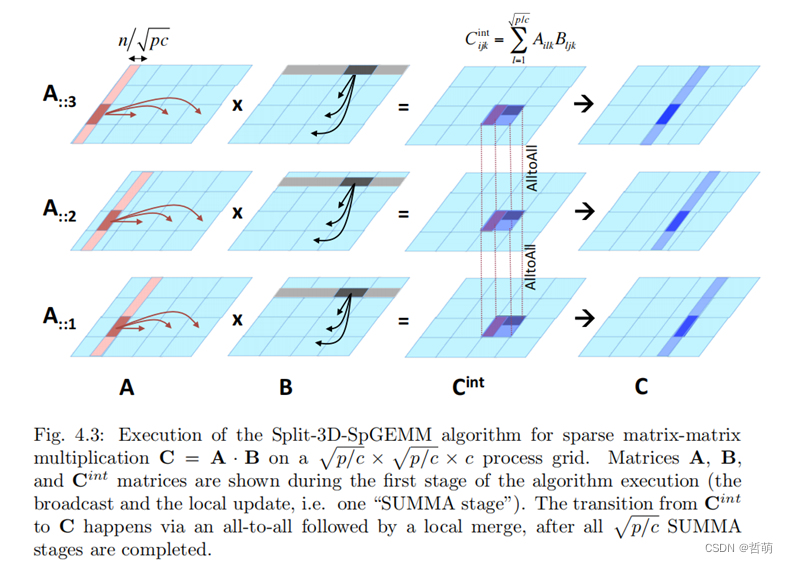
代表工作2: Tripathy A, Yelick K, Buluç A. Reducing communication in graph neural network training[C]//SC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2020: 1-14.
将特征矩阵按节点划分子图矩阵后再划分各个子图矩阵的特征,实现3维切割,计算时各个机器对应节点特征执行all-to-all操作完成乘法计算
可以进一步节省存储空间,但将加大通信代价
4.6.2通信优化

代表工作1:Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks[J]. ACM, 2019.
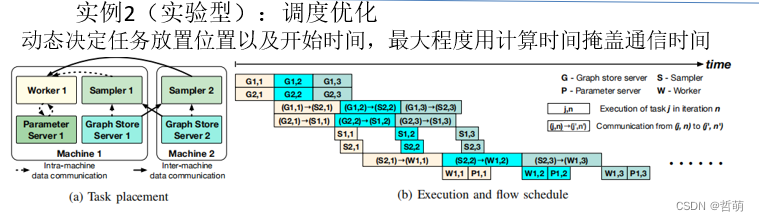
代表工作2:Luo Z, Bao Y, Wu C. Optimizing task placement and online scheduling for distributed GNN training acceleration[C]//IEEE INFOCOM 2022-IEEE Conference on Computer Communications. IEEE, 2022: 890-899.
调度的优化工作
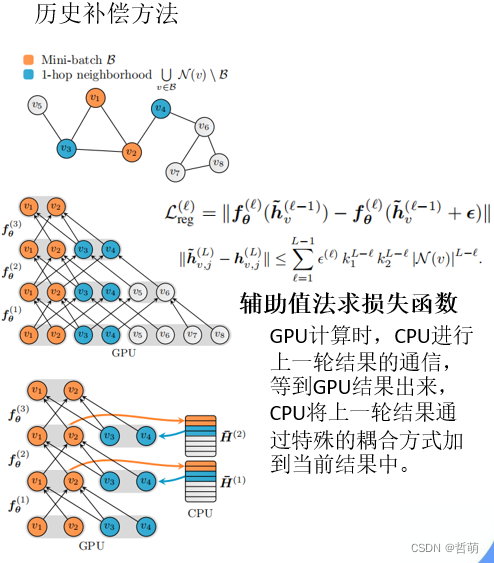
将上一轮的结果存入CPU,下一轮使用上一轮邻居的嵌入来计算
代表工作:[3] Chen J , Ma T , Xiao C . FastGCN: Fast Learning with Graph Convolutional Networks via Importance Sampling[J]. arXiv e-prints, 2018.1.
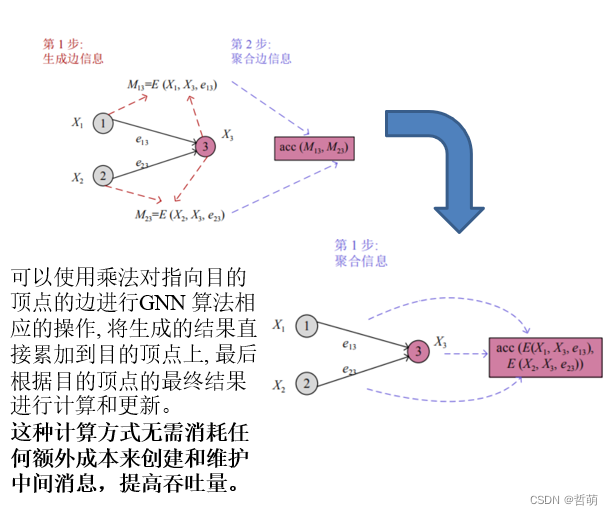
代表工作:Hang Su and Haoyu Chen. Experiments on parallel training of deep neural network using model averaging. arXiv preprint arXiv:1507.01239, 2015.
4.6.3采样工作
这里仅列出已有的采样工作
总结
这两年系统结构的顶会SC、PPoPP等已经涌现越来越多的分布式GNN的作品,并且做的工作越来越底层,虽然可以说是有些卷起来了,换句话说这个领域虽然热门,但是已经渐渐步入后期,除非有什么组做出了新高度,否则能做的点只会越来越少。未来有新的工作可能会再搜罗一下给大家分享。