前文《为什么 String 要设计成 final ,又如何设计一个不可变类呢?》留下了一个编码相关的问题,Java 中理论说是一个字符(汉字 字母)占用两个字节。但是在 UTF-8 的时候 new String("字").getBytes().length 返回的是3 表示3个字节,知道是为什么吗,Java 中 char 占多少字节?
在回答这个问题之前,让我们先学习一点基础知识吧。
什么是字符集? 什么是编码?
字符( Character )是文字与符号的总称,包括文字、图形符号、数学符号等。 一组抽象字符的集合就是字符集( Charset )。
之所以说“抽象”二字,是因为这里所提及的字符是不具任何具体形式的字符。例如“汉”这个字符,在文章中看到这个“汉”字,这其实是这个字符的一种具体表现形式,是它的图像表现形式,当人们读“汉”这个字的时候,他们使用的是另一个具体表现形式---声音。但是无论如何,这两个表现形式都是指这个“汉”字,同一个字符的表现形式可能有无数种(点阵法、矢量法、音频等),把每一种的表现形式下的同一个字符都纳入到字符集中,会使得集合过于庞大。因此抽象字符集中的字符,都是指唯一存在的抽象字符,而忽略了它的具体表现形式。在给定一个抽象字符集合中的每个字符都分配了一个整数编号之后,这个字符集就有了顺序,就成为了编码字符集。同时,这个编号,可以唯一确定到底指的是哪一个字符。对于同一个字符,不同的字符集编码系统所指定的整数编号也不尽相同。例如“儿”这个字,在 Unicode 中,它的编号是 0x513F,意思是它是 Unicode 这个编码字符集中的第 0X513F 个字符。而在另一种编码字符集中,这个字是 0xA449。
编码字符集,指的是这种被分配了整数编号的字符集合,但是编码字符集中字符被分配的整数编号,不一定就是该字符在计算机中存储时所使用的值,计算机中存储的字符到底使用什么二进制整数值来表示,由字符集编码决定。
字符集编码决定了如何将一个字符的整数编号对应到一个二进制的整数值。英文字符几乎所有的字符集编码中,英文字母的整数编号与其在计算机内部存储的二进制形式都一致。但是有的编码方式中,例如适用于 Unicode 字符集的 UTF-8 编码形式,就将很大一部分字符的整数编号作了变换后存储到计算机中。例如“汉”的 Unicode 值为 0x6C49, 但其编码格式为 UTF-8 格式后的值为 0xE6B189 (3个字节)。
编码字符集里的每一个字符,都对应到唯一的一个代码值,这些代码值叫做码点( code point ),可以看做是这个字符在编码字符集里的序号,字符在给定的编码方式下的二进制比特序列称为码元( code unit )。
注意:我们在这里引出了两个概念,码点和码元。
为什么要区分字符集与编码这两个概念?
在早期,字符集与编码是一对一的。有很多的字符编码方案,一个字符集只有唯一一个编码实现,两者是一一对应的。比如 GB2312,这种情况,无论你怎么去称呼它们,比如“GB2312编码”,“GB2312字符集”,说来说去其实都是一个东西,可能它本身就没有特意去做什么区分,所以无论怎么说都不会错。
到了 Unicode,变得不一样了,唯一的 Unicode 字符集对应了三种编码:UTF-8,UTF-16,UTF-32。字符集和编码等概念被彻底分离且模块化,其实是 Unicode 时代才得到广泛认同的。
1)charset 是 character set 的简写,即字符集。
2)encoding 是 charset encoding 的简写,即字符集编码,简称编码。
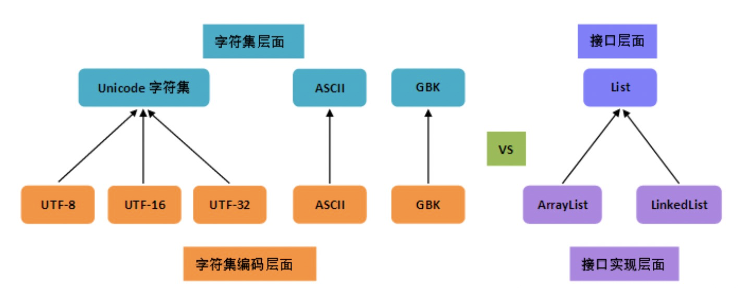
从上图可以很清楚地看到,
1、编码是依赖于字符集的,就像代码中的接口实现依赖于接口一样;
2、一个字符集可以有多个编码实现,就像一个接口可以有多个实现类一样。
为什么 Unicode 这么特殊?
搞出新的字符集标准,无外乎是旧的字符集里的字符不够用了。
Unicode 的目标是统一所有的字符集,囊括所有的字符,因此再去整什么新的字符集就没必要了。
但如果觉得它现有的编码方案不太好呢?在不能弄出新的字符集情况下,只能在编码方面做文章了,于是就有了多个实现,这样一来传统的一一对应关系就打破了。
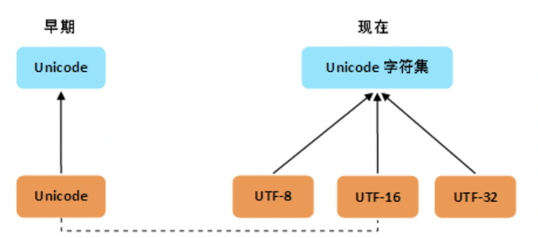
从上图可以看出,由于历史方面的原因,你还会在不少地方看到把 Unicode 和 UTF-8 混在一块的情况,这种情况下的 Unicode 通常就是 UTF-16 或者是更早的 UCS-2 编码。
我们现在说了不少 Unicode,由于各种原因,必须承认,在不同的语境下,“Unicode”这个词有着不同的含义。它可能指:
1)Unicode 标准
2)Unicode 字符集
3)Unicode 的抽象编码(编号),也即码点( code point )
4)Unicode 的一个具体编码实现,通常即为变长的 UTF-16,又或者是更早期的定长 16 位的 UCS-2。
这里重点介绍下 UTF-16 编码,UTF-16 把 Unicode 字符集的码点映射为 16 位长的整数(即码元, 长度为 2 Byte)的序列,用于数据存储或传递。Unicode 字符的码点,需要 1 个或者 2 个 16 位长的码元来表示,因此这是一个变长表示。
UTF-16 可看成是 UCS-2 的父集。在没有辅助平面字符(基本思想是用 2 个 16 位的编码表示一个字符,只对超过 65535 的字符这么做)前,UTF-16 与 UCS-2 指的是同一的意思。引入辅助平面字符后,就称为 UTF-16 了。
现在若有软件声称自己支持 UCS-2 编码,那其实是暗指它不能支持在 UTF-16 中超过 2 bytes 的字集。对于小于 0x10000 的 UCS 码,UTF-16 编码就等于 UCS 码。
为什么要重点介绍 UTF-16 编码,因为 Java 的内码使用的是 UTF-16 编码,也就是我们常说的 Unicode 编码。
没想到写了那么长,只是介绍了字符集以及编码的区别,看来是要分成两篇文章才能回答前文留下的问题,本文总结其实就是两句话:
编码字符集里的每一个字符规定的顺序,叫码点( code point ),而这个字符在编码字符集里的序号,在给定的编码方式下的二进制序列叫码元( code unit )。
在 Java 的世界里,我们更多接触的外码,即程序与外部交互时外部使用的字符编码,而你不知道的还有更多,期待下期我们正式进入 Java 的编码世界,最终去回答前文的那个问题。