目录
1.JVM概念
JVM是Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。
JVM类似于在操作系统之上运行的虚拟机软件:它能识别.class 字节码文件(java程序通过javac命令后编译产生的二进制代码),并且能够解析它的指令,最终调用操作系统上的函数,最终成功运行java文件。
总结来说就是JVM 是java程序和操作系统之间的桥梁,它的中间接口就是字节码。得益于JVM,他可以使得java程序可以跨平台在各种操作系统上运行。
jre文件中包含JVM环境。
2.JVM基本结构
JVM的基本结构如下图所示,java程序经过javac命令变成class file后进入jvm中进行处理:
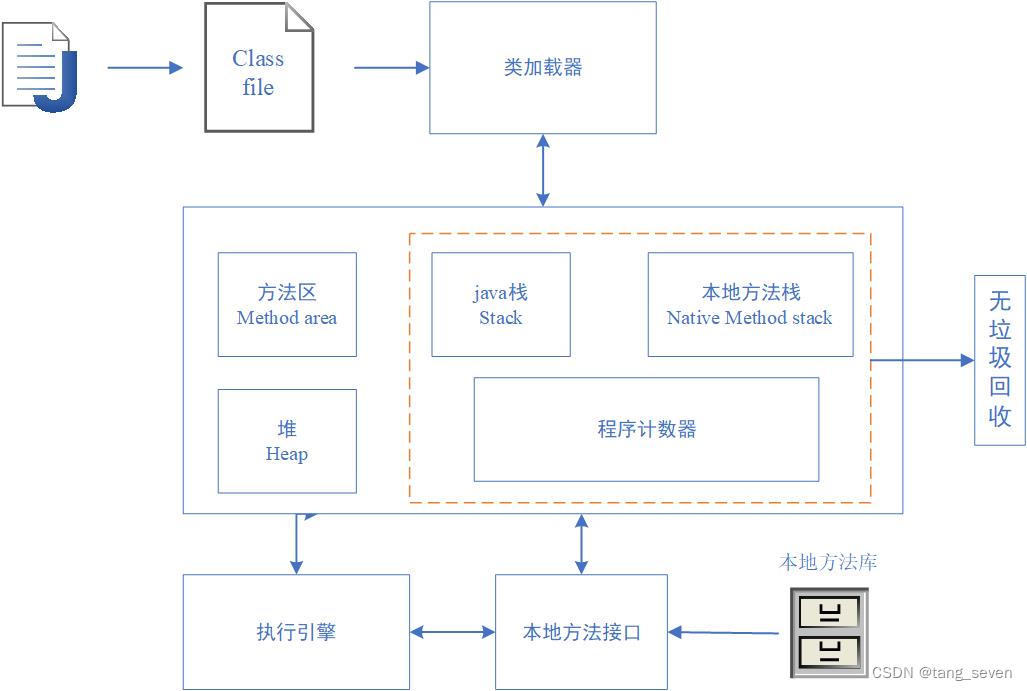
(1)类加载器:
用于加载class文件。其可以分为 AppClassLoader(应用类加载器)、ExtClassLoader(拓展类加载器)、(根加载器,java程序无法获取)、虚拟机自带的加载器。
双亲委派机制: 即类加载器收到请求后,会向上委托给父类加载器,一直向上委托,启动加载器检查是否能加载当前类:能加载,结束;否则抛出异常,通知子类加载。
简单来说就是到最大的根加载器中有无该类,只有当根、拓展加载器都无该类,才会执行当前应用程序加载器。
通过双亲委派机制阻止代码去干涉核心类,守护了被信任的类库边界;将代码归入保护域,确定了代码可以执行哪些操作。
(2)本地方法栈和本地方法接口(JNI):
拓展java的使用,融合不同的编程语言使用。
凡是带了native关键字修饰的方法(该类方法没有方法体),说明java的作用范围达不到了,会进入本地方法栈,登记该方法。然后调用本地方法接口。
(3)程序计数器:
每一个线程私有的,指向方法区中的方法字节码(即线程的编号1,2,3…),占用内存空间小,几乎可以忽略不计。
(4)方法区:
被所有线程贡献,所有定义的东西(静态变量(static)、常量(final)、类信息(Class)、运行时的常量池)都存在方法区中。
(5)栈:
主要存放8大基本类型(局部变量,即方法中的变量)+对象的引用+实例的方法。
栈是一种数据结构,先进后出、后进先出。main方法执行后会进入java栈,然后调用的其他方法陆续进入。由于先进后出,所以main方法最后结束。即先入栈先调用,程序正在执行的方法一定在栈的顶部。
栈主管程序的运行,线程结束,栈内存即释放。
StackOverflowError:栈溢出,即方法相互递归调用不终止,不断将方法存入栈中,导致栈空间不足;还有就是启动的线程过多导致内存不足,导致的栈空间不足溢出。
(6)堆:
一个JVM只有一个堆内存,其大小是可以调整的。主要存放类、实例成员变量、数组。
可以分为新生区(Eden、survivor from 、survivor to)、老年区、永久区。
新对象会首先分配在 Eden 中(如果新对象过大,会直接分配在老年代中)。
进行轻GC时,Eden区中所有存活的对象都会被复制到“To”,而在“From”区中,仍存活的对象会根据他们的年龄值(经过GC的次数)来决定去向。年龄达到阈值的对象会被移动到年老代中,没有达到阈值的对象会被复制到“To”区域。经过这次GC后,Eden区和From区已经被清空。这个时候,"From"和"To"会交换他们的角色,也就是新的“To”就是上次GC前的"From",新的"From"就是上次GC前的"To"。
当幸存者区中对象经历了足够次数的GC后(-XX:MaxTenuringThreshold中设定的进入老年区的次数),会被移动到老年代。

3.JVM存储数据案例
下面通过代码,简单看看数据如何存储在 JVM中。
有以下两个类:
public class Student {
private long id;
private String name;
private int age;
public Student(long id,String name,int age){
this.id = id;
this.name = name;
this.age = age;
}
}public class DataSave {
public static void main(String[] args) {
int num = 1;
DataSave dataSave = new DataSave();
dataSave.addOne(num);
Student student = new Student(1,"test",18);
}
public void addOne(int i){
i = i+1;
}
}上述定义消息都存于方法区中。
下面执行main程序:main线程入栈,开始执行。
(1)int num =1 ——> 局部变量,基础类型,引用和值都存在栈中。
(2)DataSave dataSave = new DataSave(); ——>新建对象dataSave ,对象dataSave 引用存在栈中,对象实例存在堆中。
(3)dataSave.addOne(num); ——> 方法 addOne()作为类的定义信息存于方法区中;调用addOne()方法,addOne()的栈帧(描述的是方法的一次执行瞬间,里面放的就是一些方法中的局部变量和方法的形参)入栈,开始执行。i为局部变量,引用和值存在栈中。当方法addOne()执行完成后,i就会从栈中消失。
(4)Student student = new Student(1,"test",18); ——>生成对象:student 为对象引用,存在栈中;对象new Student()存在堆中。
其中id, name, age为局部变量存储在栈中,且它们的类型为基础类型,因此它们的数据也存储在栈中;Student对象新建时调用构造函数获得的id, name, age为成员变量(即1, test,18),它们存储在堆中存储的new Student()对象里面;构造函数执行完毕,id, name, age从栈中消失。
(5)执行结束,num变量,DataSave,Student引用将从栈中消失;main线程出栈。

以上便是一次代码执行过程中数据在JVM中的存储过程。