《C++Primer》中列举了标准库的8个关联容器,这8个容器间的不同体现在三个维度上:
1.或者是一个set,或者是一个map;
2.或者要求不重复的关键字,或者允许重复关键字;
3.按顺序保存,或无序保存。允许重复关键字的容器的名字中都包含单词multi;不保持关键字按顺序存储的容器的名字都以unordered开头。
类型map和multimap定义在头文件map中;set和multiset定义在头文件set中;无序容器定义在头文件unordered_map和unordered_set中。

我们介绍两个重要的关联容器map和set
map
map里边存的是一些key-value键值对,其中key起到索引的作用,value表示与索引相关联的数据。map类型也常被称作为关联数组。它和一般数组类似,可以认为key就是数字下标,value就是数组内容,只不过key不一定为整数。
用map来存储每种水果和它的次数,这里的key为string表示水果类型,value为int表示水果出现的次数。此时,每个map中的元素都是一个pair类型的对象,pair是一个模板类型,保存两个public成员first和second分别对应的是key和value。
string strs[] = { "香蕉", "西瓜", "苹果", "梨子" };
map<string, int> coutMap;
coutMap.insert(pair<string, int>("香蕉", 1));
coutMap.insert(pair<string, int>("西瓜", 1));
coutMap.insert(pair<string, int>("苹果", 3));
coutMap.insert(pair<string, int>("梨子", 1));
for (size_t i = 0; i < sizeof(strs) / sizeof(strs[0]);++i)
{
coutMap[strs[i]]++;
}
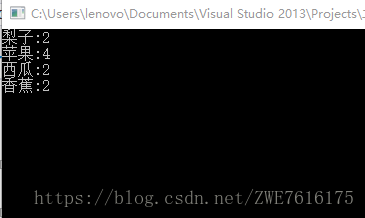
map<string, int>::iterator it = coutMap.begin();
while (it != coutMap.end())
{
cout <<(*it).first<<":"<<(*it).second << endl;
//cout << it->first << ":" << (*it).second << endl;
++it;
}输出结果:
set
set里面每个元素只存有一个key,它支持高效的关键字查询操作,例如检查一个关键字是否在set中或者在某些文本处理过程中可用set保存想要忽略的单词。
我们将代码改写为:
string strs[] = { "香蕉", "西瓜", "苹果", "梨子" };
map<string, int> coutMap;
set<string> ex = {"西瓜"};
coutMap.insert(pair<string, int>("香蕉", 1));
coutMap.insert(pair<string, int>("西瓜", 1));
coutMap.insert(pair<string, int>("苹果", 3));
coutMap.insert(pair<string, int>("梨子", 1));
for (size_t i = 0; i < sizeof(strs) / sizeof(strs[0]);++i)
{
if (ex.find(strs[i])==ex.end())
coutMap[strs[i]]++;
}
map<string, int>::iterator it = coutMap.begin();
while (it != coutMap.end())
{
cout <<(*it).first<<":"<<(*it).second << endl;
//cout << it->first << ":" << (*it).second << endl;
++it;
}输出结果:
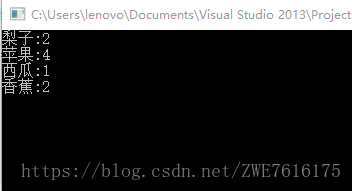
通过结果,我们可以看到,当插入key为”西瓜”的键值对的时候,没有插入进去,西瓜的个数还是一开始的1个。其实是set中保存了想要忽略的单词,我们调用了find函数,它返回一个迭代器,如果给定key在set中,则迭代器指向key,否则迭代器返回表示没有找到,只对不在set集合中的单词统计次数。
看到这里,相信大家对map和set都有了一定的了解,map是以key-value的形式存取,set以key的形式存取,底层都是红黑树,因此插入和删除的操作都在O(logn)时间内完成,可以实现高效的插入和删除。
由于底层是红黑树,因此在插入的时候会默认执行排序操作,且key都唯一,从这个角度可以看到,map和set可以实现过滤重复值和排序的功能。
我们再来仔细查看一下打印时候的顺序:
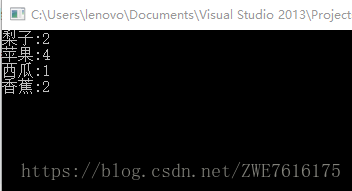
大家有没有发现,输出结果是按照ASCLL顺序升序输出的,因此,有的情况下,可以使用map/set排序。