翻译自:NICKZENG
介绍
这篇文章的目的是总结各种流行竞赛采用的一些常见的对象检测指标。这篇文章主要关注指标的定义。
热门比赛和指标
此任务包含以下竞赛和指标:
- PASCAL VOC挑战赛 (Everingham等,2010)
- COCO目标检测挑战 (Lin et al.2014)
- Open Images挑战赛 (Kuznetsova 2018)
上面的链接指向描述评估指标的网站。简单来说:
- 所有这三个挑战都使用mAP作为评估对象检测器的主要指标。但是,定义和实现会有一些变化。
- COCO对象检测挑战还包括平均召回率作为检测指标。
一些概念
在深入研究竞争指标之前,让我们首先回顾一些基本概念。
置信度分数是定位框包含对象的概率。通常由分类器预测。
IoU定义为交集面积除以预测边界框的并集面积:

置信度得分和IoU均用作确定检测是真阳性还是假阳性的标准。下面的伪代码显示了如何:
for each detection that has a confidence score > threshold:
among the ground-truths, choose one that belongs to the same class and has the highest IoU with the detection
if no ground-truth can be chosen or IoU < threshold (e.g., 0.5):
the detection is a false positive
else:
the detection is a true positive
如伪代码所示,仅当检测满足以下三个条件时,才将其视为真阳性(TP):置信度得分>阈值;预测的类别与基本事实的类别匹配;预测的边界框的IoU大于地面真实值的阈值(例如0.5)。违反后两个条件中的任何一个都会导致假阳性(FP)。值得一提的是,PASCAL VOC挑战赛还包含一些其他规则,用于定义正确/错误肯定。如果多个预测对应于相同的真实性,则只有置信度得分最高的预测才算是真实阳性,而其余的则被认为是假阳性。
当应该检测到地面真相的检测的置信度得分低于阈值时,该检测就算假阴性(FN)。您可能想知道如何计算误报的数量,以便计算以下指标。但是,正如将要显示的那样,我们并不需要真正数得出结果。
当不应该检测任何东西的检测的置信度得分低于阈值时,该检测就算作真阴性(TN)。但是,在对象检测中,我们通常不关心此类检测。
精度(Precision) 定义为真实肯定的数量除以真实肯定和错误肯定的总和:

召回率(Recall) 定义为真阳性的数量除以真阳性和假阴性的总和:

通过将置信度分数的阈值设置在不同级别,我们可以获得不同的精确度和召回率。在x轴上具有查全率,在y轴上具有查准率,我们可以绘制一条精确的查全率曲线,该曲线表示两个指标之间的关联,下图显示了一个模拟图。

请注意,随着置信度分数阈值的降低,召回率单调增加;精度可以上升和下降,但总体趋势是下降。
除了精确召回曲线外,还有另一种称为召回-IoU曲线的曲线。传统上,该曲线用于评估检测框的有效性(Hosang等人,2016年),但它也是称为mAR的指标的基础,该指标将在下一部分中介绍。
通过将IoU的阈值设置为不同的级别,检测器将相应地实现不同的召回级别。利用这些值,我们可以绘制召回率-IoU曲线

曲线显示召回率随着IoU的增加而降低。
各种指标的定义
本节介绍以下指标:平均精度(AP),类别平均精度(mAP),平均召回率(AR)和类别平均召回率(mAR)。
平均精度(AP)
尽管可以使用精确调用曲线来评估检测器的性能,但是当曲线彼此相交时,在不同检测器之间进行比较并不容易。如果我们有一个可以直接用于比较的数值指标,那就更好了。这就是基于精度调用曲线的**平均精度(AP)**发挥作用的地方。本质上,AP是所有唯一召回级别的平均精度。
需要注意的是,为了减少曲线上的摆动的影响,在实际计算AP之前,我们首先在多个召回级别内插精度。这里,有两种方法可以选择召回级别,传统的方式是选择11个等距的召回级别(即0.0、0.1、0.2,…1.0);而PASCAL VOC挑战采用的新标准将选择数据显示的所有唯一召回级别。新标准具有更高的精度,可以测量低AP的方法之间的差异。图3显示了使用新标准如何在原始曲线上获得内插的精确调用曲线。

然后可以将AP定义为插值的精确调用曲线下的面积,可以使用以下公式计算:

类别平均精度(mAP)
AP的计算仅涉及一类。但是,在物体检测中,通常有ķ个类。**平均平均精度(mAP)**定义为ķ类AP的平均值:

平均召回率(AR)
像AP一样,**平均召回率(AR)**也是可用于比较检测器性能的数值指标。本质上,AR是可以计算为召回-IoU曲线下面积的两倍:

类别平均召回率(mAR)
平均召回率定义为所有k类的AR平均值:

指标之间的差异
Pascal VOC挑战的mAP度量标准可以看作是评估对象检测器性能的标准度量标准。其他两个比赛采用的主要指标可以视为上述指标的变体。
COCO挑战的变体
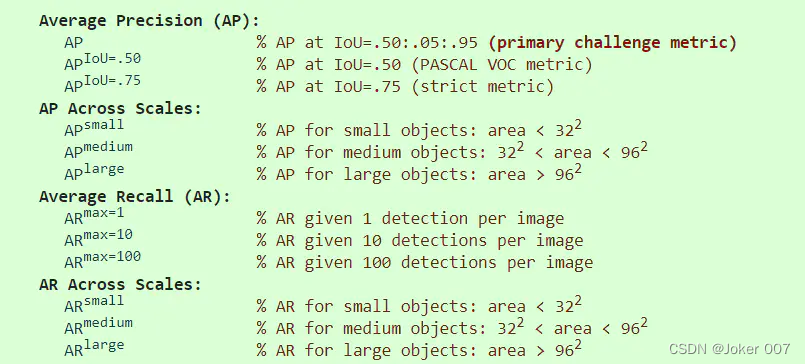
回想一下,Pascal VOC挑战使用单个IoU阈值0.5定义了mAP指标。但是,COCO挑战使用不同的阈值定义了多个mAP指标,包括:
除了不同的IoU阈值外,还可以跨不同的对象尺度计算出mAP。这些mAP变体均在10 IoU阈值(即0.50、0.55、0.60,…,0.95)上取平均值:
Open Images挑战的变体
Open Images挑战的对象检测度量标准是PASCAL VOC挑战的mAP度量标准的变体,它对应于数据集的三个关键特征,这些特征影响对正误的判断方式:
- 非详尽的图像级标签;
- 类的语义层次;
- 某些真相框可能包含对象组,并且单个对象在组内的确切位置是未知的。
在官方网站上提供了有关如何处理这些案件更详细的说明。
实现
所述Tensorflow目标检测API提供的各种度量的实施方式。
还有另一个开源项目,该项目实现了尊重比赛规范的各种指标,具有统一输入格式的优势。