文章目录
集群中数据的走向— FULLNAT
从用户的客户端机器,到我们的负载均衡器,再到我们的后端真实机器这个过程中,数据是如何走向的呢?用一副图来为你详细介绍这个过程(我们从数据封装角度来看,考虑到数据的mac地址以及IP地址):

正如图片上分析的,因为我们的负载均衡器在这里做了一个fullnat,把进出数据的源IP和目的IP都给更改了,那么就会导致一个问题,后端的backend server只知道负载均衡器的IP地址,但是不知道客户端真正的源IP地址。
解决后端服务器不知道客户端IP地址的方法
方法一:在后端backend server上不使用realip模块
步骤1:在负载均衡器上修改http请求报文头部字段,添加一个X-Real-IP字段
将nginx内部的remote_addr这个变量的值,赋值给X-Real-IP这个变量,X-Real-IP这个变量会在http协议的请求报文里添加一个X-Real-IP的字段,后端的real server 服务器上的nginx就可以读取这个字段的值
X-Real-IP 这个变量名可以自己定义,随便取名,后面引用的时候,不区分大小写
修改后端负载均衡器的Nginx.conf配置文件:
server {
listen 80;
location / {
# root html;
# autoindex on;
proxy_pass http://scapp;
proxy_set_header X-Real-IP $remote_addr; #添加这行代码,将remote_addr变量赋值给X-Real-IP
index index.html index.htm;
}
步骤2:在后端backend server上使用X_Real_IP这个字段,
在主配置文件nginx.conf里的日志部分调用这个变量,获取X-Real-IP的值(在负载均衡器上要写X-Real-IP,在backend server上要写x_real_ip【重点不是大小写,而是使用下划线】)
backend server的配置文件更改前:

backend server的配置文件更改后:

步骤3:验证效果,查看backend server的日志文件
插入新字段前的日志文件:

插入新字段后的日志文件:

方法二:后端backend server使用realip模块
前提条件:需要在backend server编译安装nginx的时候,需要接–with-http_realip_module,开启realip这个功能
步骤1:跟方法一的步骤1相同
将nginx内部的remote_addr这个变量的值,赋值给X-Real-IP这个变量,X-Real-IP这个变量会在http协议的请求报文里添加一个X-Real-IP的字段,后端的real server 服务器上的nginx就可以读取这个字段的值
步骤2:在backend server上使用set_real_ip_form 192.168.2.43;
server{
listen 80;
set_real_ip_from 192.168.2.43; #IP地址是你负载均衡器的IP地址
}
set_real_ip_from 192.168.2.43是告诉本机的nginx,192.168.2.43是负载均衡器,不是真正的client
然后realip模块会自动到负载均衡器的http头部中取定义的X-Real-IP字段,其实跟方法一差不多,只不过一个是后端机器自动获取到,一个是修改配置文件获得到
集群中保障数据一致性问题-- NFS
集群中使用nfs,让backend服务器都到nfs服务器里获取数据,这样就可以达到数据一致性,随便访问哪台后端服务器看到的内容都是一样的
nfs是什么?
网络文件系统,英文Network File System(NFS),是由SUN公司研制的UNIX表示层协议(presentation layer protocol),能使使用者访问网络上别处的文件就像在使用自己的计算机一样。
nfs解决了什么问题?
数据同源: 到同一个地方去拿数据,保障数据的一致性
nfs的优点和缺点
优点: 随便一台linux服务器都可以搭建,成本非常低,构建非常容易
缺点: 读取速度有限,跟网络质量,磁盘IO,cpu,内存等因素有关,在传统的tcp/ip网络上传输的
实现步骤
1.搭建nfs服务器
[root@nfs ~]# yum install nfs-utils -y
[root@nfs ~]# service nfs start
Redirecting to /bin/systemctl start nfs.service
[root@nfs ~]# mkdir /data
mkdir: 无法创建目录"/data": 文件已存在
[root@nfs ~]# vim /etc/exports
[root@nfs ~]# cat /etc/exports
/data 192.168.2.0/24(rw,no_root_squash,no_all_squash,sync)
[root@nfs ~]# exportfs -r
#建议关闭防火墙和selinux
[root@nfs ~]# service firewalld stop
Redirecting to /bin/systemctl stop firewalld.service
[root@nfs ~]# systemctl disable firewalld
[root@nfs ~]# getenforce
Disabled
/data 是我们共享的文件夹的路径–》使用绝对路径 --》需要自己新建
192.168.2.0/24 允许过来访问的客户机的ip地址网段
(rw,all_squash,sync) 表示权限的限制
rw 表示可读可写 read and write
ro 表示只能读 read-only
all_squash :任何客户机上的用户过来访问的时候,都把它认为是普通的用户
root_squash 当NFS客户端以root管理员访问时,映射为NFS服务器匿名用户
no_root_squash 当NFS客户端以root管理员访问时,映射为NFS服务器的root管理员
sync 同时将数据写入到内存与硬盘中,保证不丢失数据
async 优先将数据保存到内存,然后再写入硬盘,效率更高,但可能丢失数据
2.backend服务器挂载到nfs共享的目录取数据
语法: mount nfs服务器的目录 本地的目录
这样,backend服务器的/usr/share/nginx/html/目录就挂载到了nfs服务器的/data目录下了,如果要从backend的/usr/share/nginx/html/目录下取数据,就会自动去nfs服务器的/data下取数据,由此保障了数据的一致性
[root@web1 nginx]# yum install nfs-utils -y
[root@web1 nginx]# mount 192.168.2.35:/data /usr/share/nginx/html/
[root@web1 nginx]# df -Th
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/mapper/centos-root xfs 17G 2.5G 15G 15% /
devtmpfs devtmpfs 475M 0 475M 0% /dev
tmpfs tmpfs 487M 0 487M 0% /dev/shm
tmpfs tmpfs 487M 14M 473M 3% /run
tmpfs tmpfs 487M 0 487M 0% /sys/fs/cgroup
/dev/sda1 xfs 1014M 133M 882M 14% /boot
tmpfs tmpfs 98M 0 98M 0% /run/user/0
192.168.2.35:/data nfs4 8.0G 2.4G 5.7G 30% /usr/share/nginx/html
NFS是实现数据一致性的好方法吗?
看到使用nfs服务器来实现数据的一致性,你肯定会觉得很low,的确,使用nfs来解决数据一致性确实不是一个最佳答案,但是使用nfs,你只需要一台廉价的服务器(或者虚拟机)以及一个免费的nfs-utils软件就能实现,这虽然不是最佳答案,但也是我们学生最便捷、经济的方式了。
如果你认为nfs比较差,以及你不差钱,那么我推荐你使用一下方式:
1.SAN:存储区域网络 (Storage Area Network, SAN) 是企业最常用的存储网络架构,要求高吞吐量和低延迟的业务关键型业务往往采用这类架构运行。
2.NAS(Network Attached Storage)网络存储基于标准网络协议实现数据传输,为网络中的Windows / Linux / Mac OS 等各种不同操作系统的计算机提供文件共享和数据备份。也就是比较便宜的使用tcp/ip网络协议,在日常的生活和工作里使用,例如:可以将所有手机,电脑里的图片集中存储。是一个小型带系统的存储设备
3.云存储,像戴尔等产商,有专门的做那种存储数据的服务器或者云存储服务器,这都不失为一个好的选择
NFS的工作原理
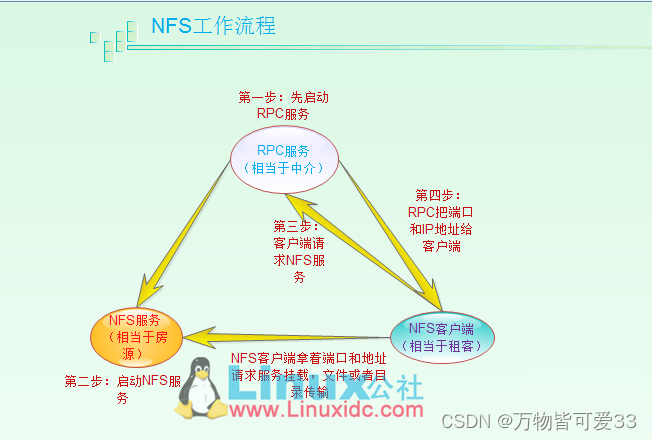
NFS是通过网络来进行服务器端和客户端之间的数据传输,那么两者之间要传输数据就要有想对应的网络端口,NFS服务器到底使用哪个端口来进行数据传输呢?
基本上NFS这个服务器的端口开在2049,但由于文件系统非常复杂。因此NFS还有其他的程序去启动额外的端口,这些额外的用来传输数据的端口是随机选择的,是小于1024的端口;既然是随机的那么客户端又是如何知道NFS服务器端到底使用的是哪个端口呢?这时就需要通过远程过程调用(Remote Procedure Call,RPC)协议来实现了!
因为NFS支持的功能相当多,而不同的功能都会使用不同的程序来启动,每启动一个功能就会启用一些端口来传输数据,因此NFS的功能对应的端口并不固定,客户端要知道NFS服务器端的相关端口才能建立连接进行数据传输,而RPC就是用来统一管理NFS端口的服务,并且统一对外的端口是111,RPC会记录NFS端口的信息,如此我们就能够通过RPC实现服务端和客户端沟通端口信息。PRC最主要的功能就是指定每个NFS功能所对应的port number,并且通知客户端,记客户端可以连接到正常端口上去。
那么RPC又是如何知道每个NFS功能的端口呢?
首先当NFS启动后,就会随机的使用一些端口,然后NFS就会向RPC去注册这些端口,RPC就会记录下这些端口,并且RPC会开启111端口,等待客户端RPC的请求,如果客户端有请求,那么服务器端的RPC就会将之前记录的NFS端口信息告知客户端。如此客户端就会获取NFS服务器端的端口信息,就会以实际端口进行数据的传输了。
提示:在启动NFS SERVER之前,首先要启动RPC服务(即portmap服务,下同)否则NFS SERVER就无法向RPC服务区注册,另外,如果RPC服务重新启动,原来已经注册好的NFS端口数据就会全部丢失。因此此时RPC服务管理的NFS程序也要重新启动以重新向RPC注册。特别注意:一般修改NFS配置文档后,是不需要重启NFS的,直接在命令执行/etc/init.d/nfs reload或exportfs –rv即可使修改的/etc/exports生效。
NFS服务器端和NFS客户端的通讯过程:
1)首先服务器端启动RPC服务,并开启111端口
2)服务器端启动NFS服务,并向RPC注册端口信息
3)客户端启动RPC(portmap服务),向服务端的RPC(portmap)服务请求服务端的NFS端口
4)服务端的RPC(portmap)服务反馈NFS端口信息给客户端。
5)客户端通过获取的NFS端口来建立和服务端的NFS连接并进行数据的传输。
NFS工作原理参考博客:添加链接描述