背景
随着互联网的发展,今天的数据库系统往往非常庞大且复杂,针对数据库系统的运维工作需要监控大量数据指标来了解数据库的运行状况。数据库指标往往以时间序列的方式出现,当业务层面关键指标出现异常时,运维人员需要迅速定位异常情况的原因来相应制定解决方案。但是当指标数量很多的时候,筛选信息的工作量也会很庞大。
我们都知道某些数据库指标之间有关联性,通过有方向性的关联性算法,在异常发生时将同一时间段的指标进行比对,根据相关性的强弱将异常时间段内与关键指标相关的指标筛选出来,有助于帮助运维人员迅速定位问题以及减轻运维人员的工作量,有助于我们锁定问题的根因。
指标的关联性
如前文所述,不同监控指标数据之间是存在关联性的,下图展示两个不同指标之间的相关关系。
Pearson相关系数--最简单的相关性度量方法
要理解Pearson相关系数,首先要理解协方差(Covariance),协方差是一个反映两个随机变量相关程度的指标,如果一个变量跟随着另一个变量同时变大或者变小,那么这两个变量的协方差就是正值,反之相反,公式如下:
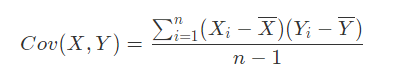
Pearson相关系数公式如下:
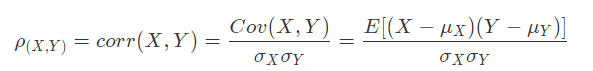
由公式可知,Pearson相关系数是用协方差除以两个变量的标准差得到的,虽然协方差能反映两个随机变量的相关程度(协方差大于0的时候表示两者正相关,小于0的时候表示两者负相关),但是协方差的值的大小并不能很好地度量两个随机变量的关联程度。这是因为,二维空间中分布着一些数据,我们想知道数据点坐标X轴和Y轴的相关程度,如果X与Y的相关程度较小但是数据分布得比较离散,会导致求出的协方差值较大,用这个值来衡量相关程度是不合理的。
为了更好地度量两个随机变量的相关程度,Pearson相关系数在协方差的基础上除以两个随机变量的标准差,容易得出,Pearson相关系数是一个介于-1到1之间的值,当两个变量的线性关系增强时,相关系数趋于1或-1。它很直观,也很容易理解,
Pearson相关系数有以下特点:
- 使用最广泛,假定数据符合正态分布
- 受异常值的影响比较大
- 适用于线性关系
- 必须是成对数据,每对数据之间相互独立
- 样本>30
Person相关系数是对于绝大多数场景都是胜任的,但是它存在几个明显的约束条件,即受异常值影响很大、符合正态分布即线性相关。因此,openGauss的DBMind在进行分析时,并没有直接使用该方法,而是混合了一系列的算法进行取长补短。但是,其在指标关联性分析的问题解决上,思路是一致的。
指标压缩
很多时间序列之间本质上是等价的或者接近等价,相关性分析的结果中,相关性最高的结果往往是这类等价指标,为了减少运维人员的工作量,应该先通过相关性分析对冗余的指标进行合并,减少指标异常时相关性分析给出的结果数量。
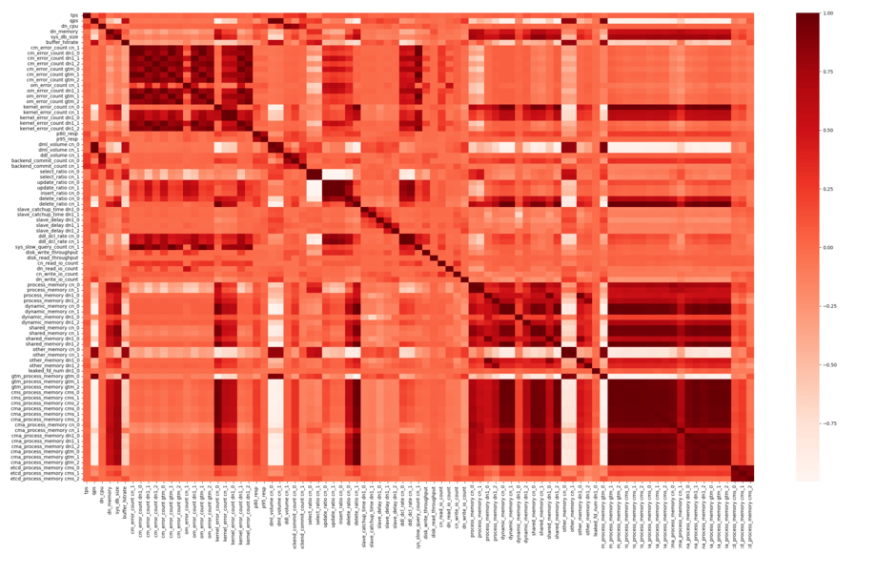
如下图所示,该两个指标之间高度相关,在进行指标关联的时候可以将高度相关的指标进行压缩,对相关性分析的结果进行压缩。
以实际场景为例,我们会发现相关性矩阵对角线上有深色色块,图中将同质化较强的指标聚集在一起,指出了指标中可能存在的指标冗余情况。
构建指标的因果关系链
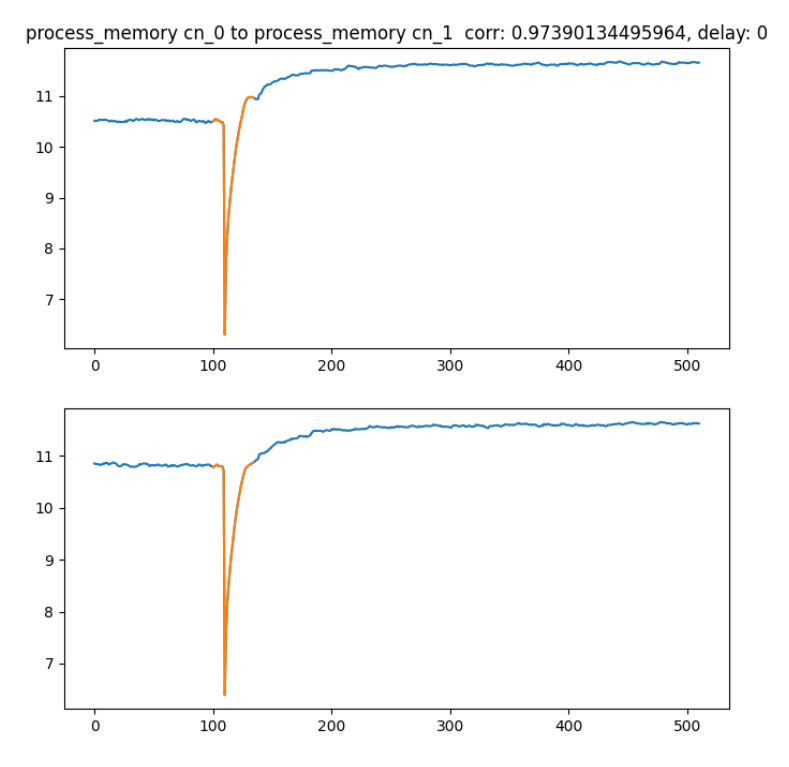
在计算指标之间的相关性的同时,通过将时间序列在时间轴上进行平移,找出相关性最强时的时间差,不仅可以得到告警之间是否存在相关性,还可以对先后顺序,波动顺序进行分析。如下图所示,sys_db_size向右平移获得了更大的相关性系数,表示sys_db_size的增长先于dn_memory发生,意味着数据库规模增长可能是内存异常波动的原因而非结果。
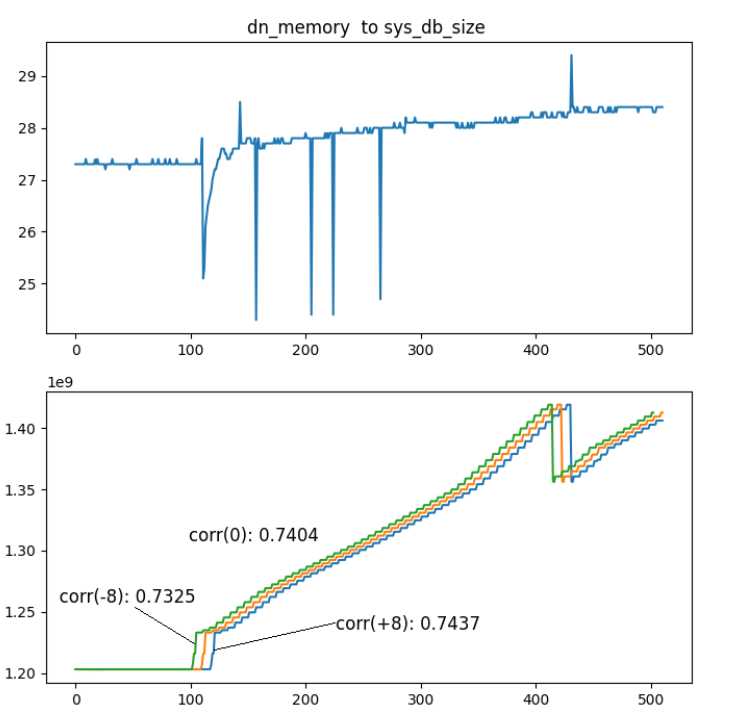
一般我们认为,更早发生异常的指标是更晚发生的异常的原因,通过时间的先后顺序推导出异常事件的因果关系,这对时间粒度要求比较细。
多指标关联性分析实战
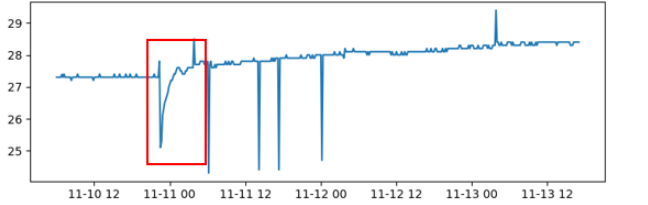
多指标关联性分析应该由异常检测功能来自动触发,检测到dn_memory在15:20~15:40之间出现spike异常,且之后开始持续增长:
指标关联分析:基于关联分析工具,将关联性较强的指标进行输出(下面列出部分指标):
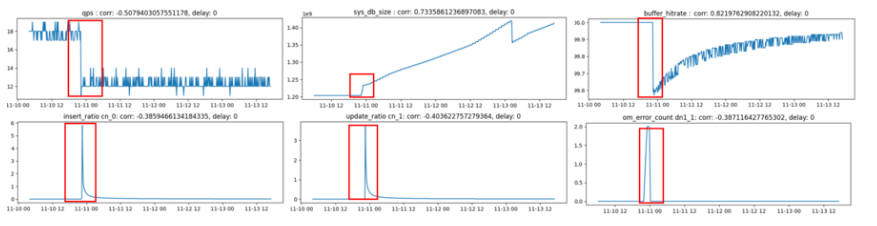
根因分析:insert语句和update语句从0%突增,批量更新和插入操作导致大量的脏页产生,进而导致block大量置换,buffer命中率下降。
DBMind关联性分析使用指导
由于openGauss的DBMind已经在5.0.0版本中上线了多指标关联分析特性,因此,用户可以直接通过DBMind进行多指标关联分析。下面为大家简单介绍如何使用DBMind的多指标关联分析。
1. 安装并部署DBMind, 将DBMind搭建起来后,可以进入到DBMind的后台管理系统;其中,DBMind的安装包可以在openGauss官网下载页面
(https://opengauss.org/zh/download/)或 DBMind的源码仓库(https://gitee.com/opengauss/openGauss-DBMind)中下载。
部署文档可以参考openGauss的官方指导手册或DBMind源码仓库的readme页面。
安装部署好之后,可以打开DBMind的后台管理系统,输入当前数据库的用户名和密码即可登录进去。
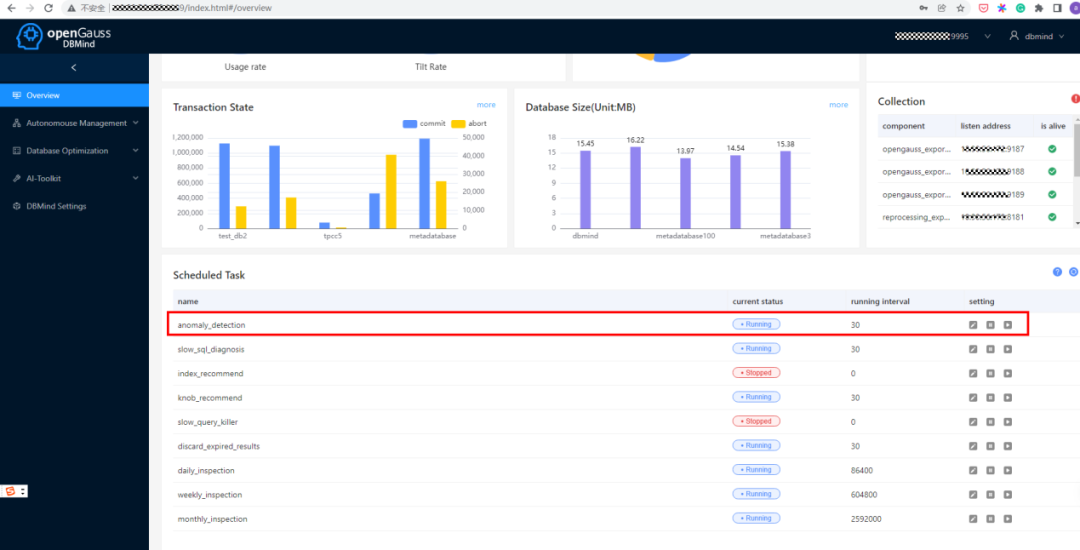
2. 在DBMind的后台管理系统中,我们能看到异常检测任务在后台处于开启状态:
3. 我们可以切换到Alarm页面,查看DBMind是否发现了数据库指标的异常波动
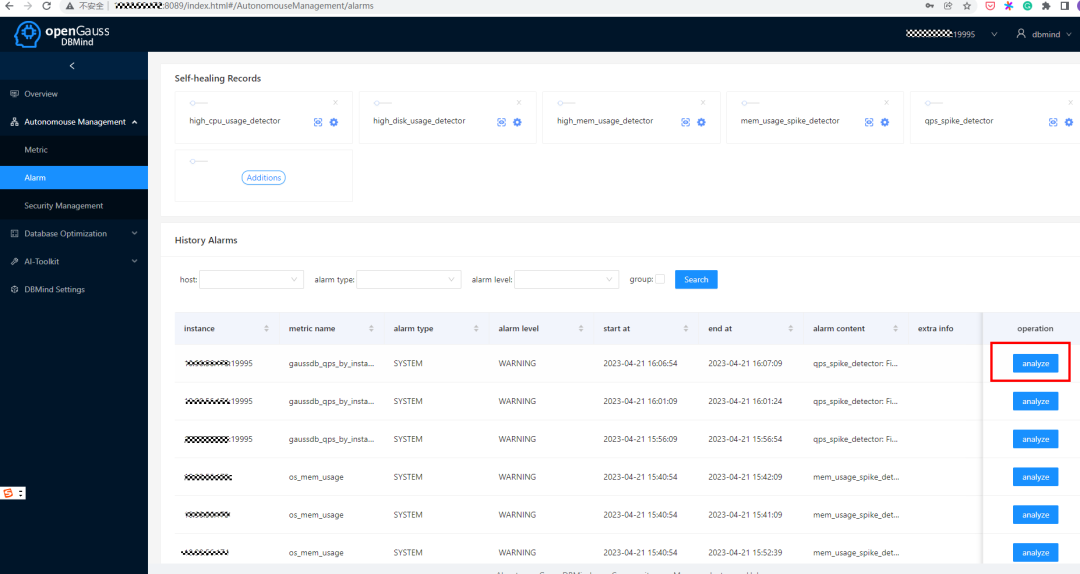
若发现波动,我们可以将 group 复选框去掉,查看具体详情,并点击对应的 analyze 按钮进行“多指标关联分析”;
4. 如下图所示,我们可以看到指标之间的关联波动情况,便于DBA和运维人员进行故障的协同定位:
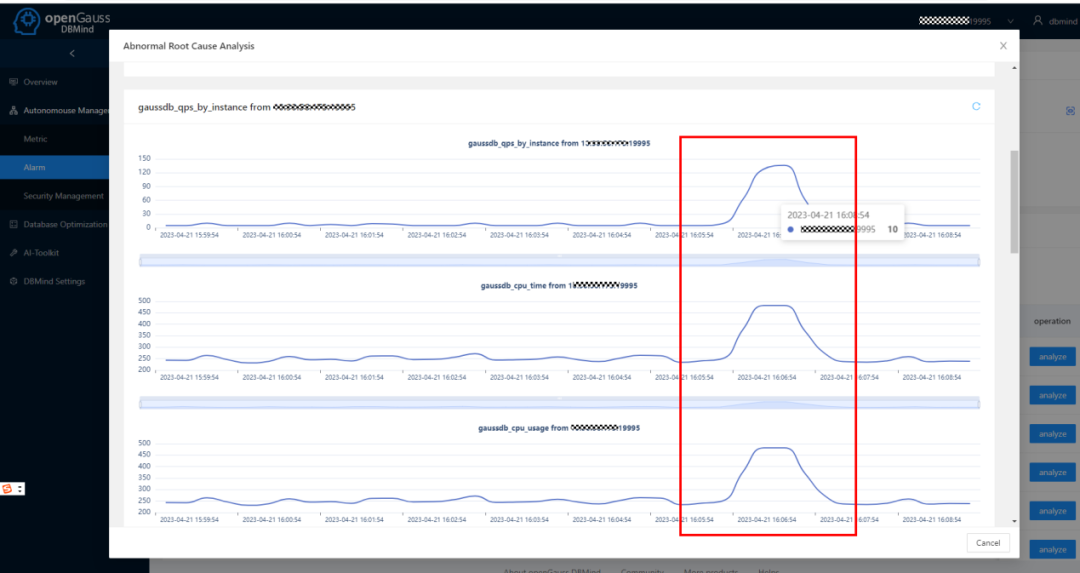
如上图所示,异常检测功能发现到TPS指标发生了突然上升,我们可以同步观察到与其同步发生的CPU和内存波动情况,以及幅度。运维人员可以根据波动幅度、波动同步情况、同步波动的指标进行故障的评估和分析。
功能演进说明
该功能目前只是进行多指标的关联分析和观测,并不具备前面所述的“指标压缩”和直接输出分析结论的功能。后面,我们会根据开源计划,开源根因库和指标关联特征库等相关功能。
欢迎大家关注
https://gitee.com/opengauss/openGauss-DBMind
https://github.com/opengauss-mirror/openGauss-DBMind
相关推荐
本文分享自微信公众号 - openGauss(openGauss)。
如有侵权,请联系 [email protected] 删除。
本文参与“ OSC源创计划 ”,欢迎正在阅读的你也加入,一起分享。