本文参考:
CTC Loss (一)_00000cj的博客-CSDN博客_ctcloss
CTC:Connectionist Temporal Classification,连接时序分类,它的优点是对没有对齐的数据进行自动对齐训练。
1、OCR大致流程
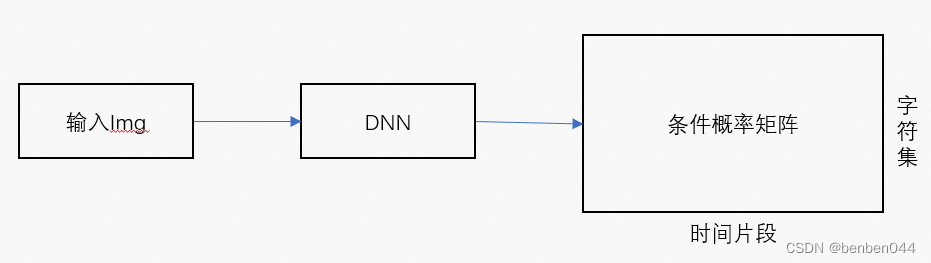
输入img后,经过DNN神经网络,得到M*T的条件概率矩阵。对于概率矩阵,其行向为OCR所有的字符集,列向为时间帧,矩阵每一列之和为1(softmax之和为1)。
2、OCR识别现有难点
(1)数据集非常耗时
用图像创建一个数据集,需要为图像的每个水平位置指定相应的字符。然后通过训练一个神经网络 输出每个水平位置的字符得分。但是在字符集标注数据集非常困难。

针对每个字符不同的样式和长度都需要逐一进行标记。
(2)获取最终字符处理复杂
假如我们得到了”ttooo”,因为”o”是一个宽字符,我们必须删除所有重复的”t”和”o”。但如果被认可的文本是”too”,删除所有重复的“o”会得到错误的结果。
CTC则允许每个图片只提供结果序列即可,即上面只需要提供”to”的label即可,CTC会自动进行对齐训练。
3、空格作用
针对OCR识别到字符后再处理困难的问题,通过增加blank进行解决。
在编码文本时,我们可以在任何位置插入任意多的blank,而在解码时将这些空格进行删除。
解码时删除重复项的规则是:
先删除两个blank中的重复项,然后再将blank去掉。
比如”-ttt-ooo-ooo-”和”-t-o-o-”都得到了”too”。
这样的好处是:针对不同的图片中存在的不同的写字风格,我们预测出了不同的字符串序列,最后通过解码规则都得到了同样的最终字符串序列。
4、CTC对齐训练目标
我们的目标不是每一帧的匹配,而是满足解码后序列和目标序列一致的所有序列的概率和最大。此时存在多种答案可以对应到目标文本,所以也就没法对网络输出和目标输出之间算交叉熵,因为我们没法确定要算网路输出和哪个正确答案之间的交叉熵。
用数据语言描述如下:
给定输入x,模型输出为l的概率为:
![]() ,
,![]() 表示所有经过
表示所有经过![]() 变换后是l的路径
变换后是l的路径![]() 。
。
其中,对于任意一条路径![]() 有:
有:
![]() ,这里
,这里![]() 中的
中的![]() ,下标t表示路径
,下标t表示路径![]() 中的每一个时刻。
中的每一个时刻。
Ctc训练目标:
因为x->DNN->y,所以通过 再链式求梯度
再链式求梯度![]() 从而调整模型权重w,使得
从而调整模型权重w,使得![]() 最大。
最大。
举例说明:
假如有N中路径可以变成state,对于其中的4条路径举例如下:

我们训练的目标是:出现”—stta-t---e”、”sst-aaa-tee-”等N条路径的概率和最大。
对于第一条路径,
![]()
而y值就是神经网络训练得到的概率矩阵。
存在问题:
在实际训练过程中,神经网络输出概率矩阵的大小少则几十多则几百,如果遍历每一条路径,复杂度是指数级的。假如识别的是汉字,字符集长度m为几千,序列长度T上百,那要遍历![]() 种选择,速度太慢。实际CTC采用了”前向-后向”算法来计算
种选择,速度太慢。实际CTC采用了”前向-后向”算法来计算![]() 。
。
5、前向-后向方式计算过程
(1)label预处理
在进行计算之前,需要对序列l做一些预处理,在序列l的开头与结尾分别加上空格,并且在字母与字母之间都添加上空格。如果原来序列l的长度为U,那么预处理之后,序列l’的长度为2U+1。
比如,label为“我爱你”,神经网络输出的概率矩阵如下:

预处理之后的新label为”-我-爱-你-”,对应的概率矩阵信息为:

(2)动态规划求解思路

如上图,我们的label为”炉石传说”,定义如下规则从t=1走到t=10:
- 必须从t=1时刻最上面的blank或者它下面的”炉”这两个位置出发;
- 每次只能往右一格、往右一格往下一格、或者往右一格往下两个;
- 如果当前位置对应的输出是blank,则不能往右一格往下两格,只能选择其他两种走法;
- 到达t=10时,最终位置必须在最下面的blank或者它上面的“说”这两个位置。
比如按照上面规则的如下走法:
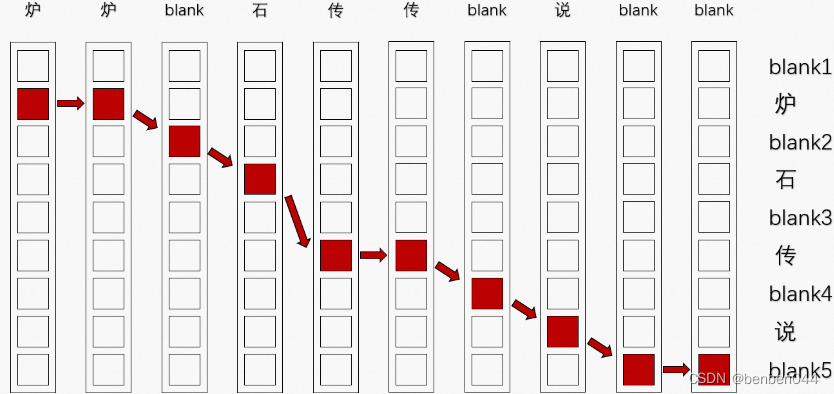
可以发现,如果把路径上每一个位置对应的文字连起来,然后去重去blank,就一定能够得到正确的目标文本“炉石传说”。
(3)![]() 求梯度
求梯度
定义所有经![]() 变化后结果是l且在t时刻结果为
变化后结果是l且在t时刻结果为![]() 的路径集和为
的路径集和为![]() ,求导:
,求导:
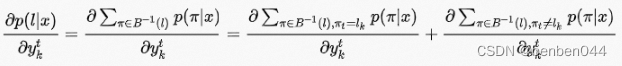
上式中第二项与![]() 无关,因此:
无关,因此:
 ,所以,
,所以,
![]() 就是恰好与概率
就是恰好与概率![]() 相关的路径,即t时刻都经过
相关的路径,即t时刻都经过![]() 。
。
对于刚才的路径:

它们在t=6时都经过了a。

如上图,蓝色路径和红色路径分别为上述的![]() 和
和![]() ,
,![]() 和
和![]() 可以表示为:
可以表示为:
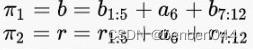
而![]() 和
和![]() 可以表示为:
可以表示为:
![]()
可以发现![]() 和
和![]() 就是
就是![]() 和
和![]() 前序后序的重新组合,于是:
前序后序的重新组合,于是:
A1OB1+A1OB2+A2OB1+A2OB2
=A1O(B1+B2)+A2O(B1+B2)
=(A1+A2)O(B1+B2)
令:

则:
![]()
推广之,

定义前向递推概率和:![]() ,它表示t时刻经过
,它表示t时刻经过![]() 的所有路径的1~t的概率和,即前向递推概率和。
的所有路径的1~t的概率和,即前向递推概率和。

当t=1时,路径只能从blank或l1开始,所以![]() 有如下性质:
有如下性质:

同理,定义后向递推概率和![]() ,它表示t时刻经过
,它表示t时刻经过![]() 的所有路径的t~T的概率和,即后向递推概率和。
的所有路径的t~T的概率和,即后向递推概率和。
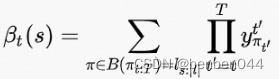
当t=T时,路径只能以blank或![]() 结束,所以
结束,所以![]() 有如下性质:
有如下性质:

对于递推loss有:

Forward和backward相乘有:
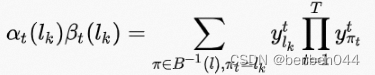
于是:

梯度为:

一般我们优化似然函数的对数,梯度如下:
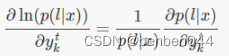
我们的目标就是通过极大似然对数,然后取负数后为求最小值,再通过梯度下降训练DNN的参数w。