
GOPS 全球运维大会由高效运维社区(GreatOPS)、开放运维联盟(OOPSA)和 DevOps 时代社区联合主办,指导单位为云计算开源产业联盟、FinOps产业推进方阵。迄今为止,GOPS 已经举行了十九次,大会参会嘉宾累计突破7万人次,国内每一站均为本地区最大规模的高端运维盛会,满意度和推荐度高达97%以上。
第二十届 GOPS 全球运维大会已于2023年4月8日在深圳市南山区深圳湾万丽酒店落下帷幕,但其中的收获却装满了满满一行囊。比如今年大会分享的几个主题方向都很有代表性和讨论性——云原生、DevOps、AIOps、DevSecOps、BizDevOps等技术领域。还特设了如互联网大厂企业专场、银行/证券名企数字化转型案例专场、云原生架构专场、DevOps/AIOps最佳实践专场、可观测性技术实践专场等特色专场。

此次,复旦大学计算机科学技术学院教授、擎创科技首席数据科学家——王鹏,在Xops行业案例专场中进行了《智能运维中的数据管理与数据探索》的深度分享。本文就王教授的分享内容进行简化总结,详细内容请静待后续视频号的更新。

一、智能运维建设中的挑战
企业在进行智能运维的建设过程中,经常被各类数据问题扰的头疼,究其原因是走入了一些误区,如:
-
在建设期间,对AIOps的期望过于理想化,从而忽视了基础底座的重要性,既没有做好数据治理,也没有与经典规则融合,导致运维业务特征总结度不够,无法为运营提供帮助。
-
急于求成而导致过多的目标场景无法完善交付,已交付的场景效果良莠不齐,无法进行实际应用。
-
由于建设弯路造成的结果,使获得的数据质量不够稳定,系统经常出现误报,企业对算法、AIOps的能力逐渐变得不信任。
王教授表示,由以上这些误区引起的数据问题,带来了下述几种数据挑战:

1.数据无法深度关联:企业数据治理能力薄弱,异构数据的关联能力较弱,单类型数据过多无法统一。
例如:
将node、pod、服务、应用等信息做为标签添加到每条日志、指标、调用链数据中去,会发现出现大量的标签,存储压力猛增,同时由于浅层融合,各类型数据中的元数据普遍存在不一致。

2.数据管理不得当:数据存储效率低,缺少综合查询能力,离线实时数据割裂。
例如:
将指标(TSDB)、日志(ES)、调用链(RDB或GraphDB)等数据统一存储到数仓时,发现缺乏异构数据的关系代数或基于代价的查询优化技术等。

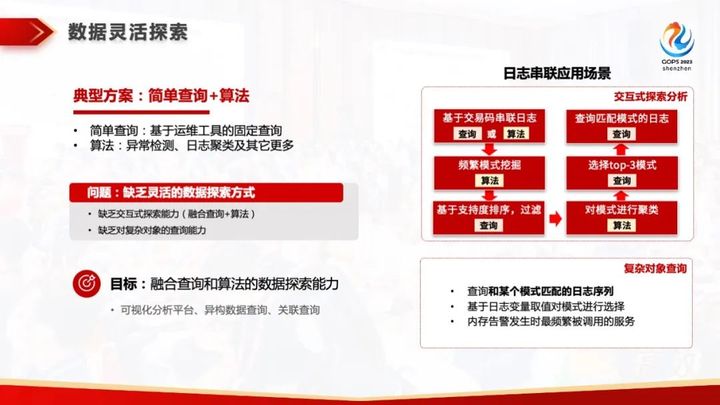
3.数据探索能力弱:数据探索能力被忽视,查询对象单一,不重视针对模型的反馈。
例如:
想要实现简单查询和算法功能时,发现缺乏融合查询+算法的交互式探索能力,缺少对复杂对象的查询能力,频繁对数据进行挖掘却不能获得价值反馈。
二、面向可观测性的数据处理解决方案
-
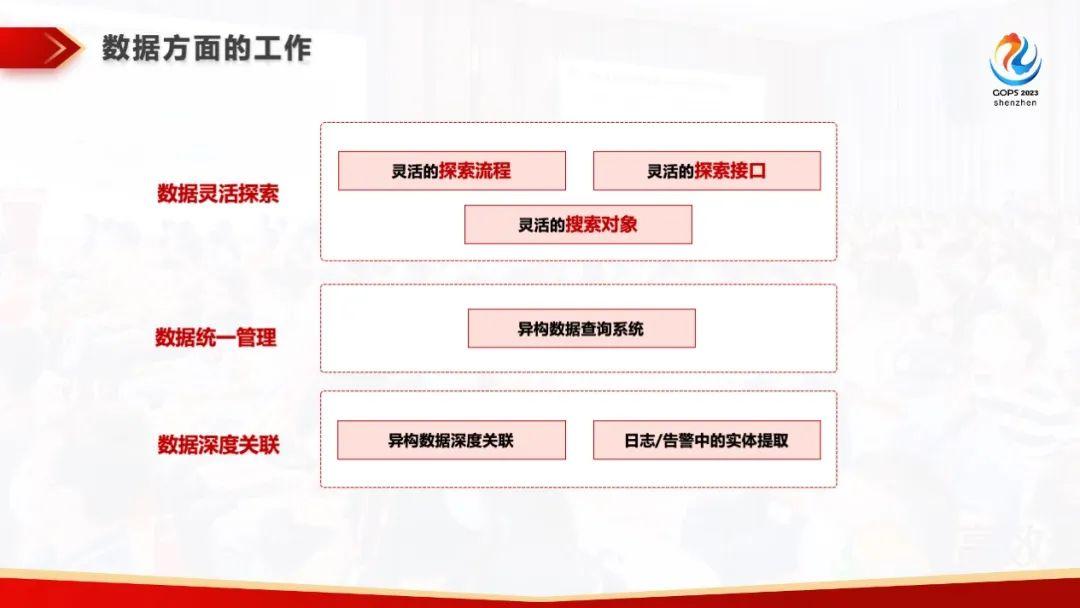
数据灵活探索:制定灵活的探索流程,打造灵活的探索接口、设定灵活的搜索对象
-
数据统一管理:建立异构数据查询系统
-
数据深度关联:实现异构数据深度关联以及日志/告警中的实体提取
关于王鹏教授的分享内容就到这里啦,感兴趣的朋友可以关注微信视频号-擎创夏洛克AIOps,一键了解更多精彩内容)

擎创科技,Gartner连续推荐的AIOps领域标杆供应商。公司致力于协助企业客户提升对运维数据的洞见能力,优化运维效率,充分体现科技运维对业务运营的影响力。
行业龙头客户的共同选择

了解更多运维干货与技术分享
可以右上角一键关注
我们是深耕智能运维领域近十年的
连续多年获Gartner推荐的AIOps标杆供应商
下期我们不见不散