目录
前言:
笔记来自《文老师软考数据库》教材精讲,精讲视频在b站,某宝都可以找到,个人感觉通俗易懂。
9.1 概述
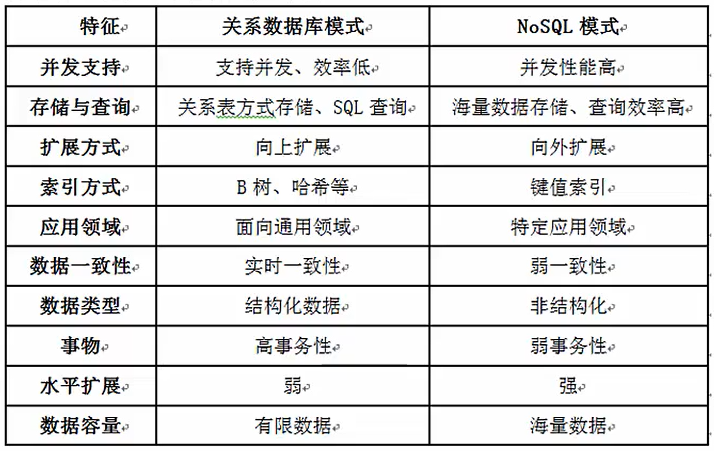
- 传统的关系数据库在应付Web 2.0网站,特别是超大规模和高并发的SNS类型的Web2.0纯动态网站方面已经显得力不从心,暴露了很多难以克服的问题,主要包括以下几个方面。
1)对数据库高并发读写的需求;
2)对海量数据的高效率存储和访问的需求;
3)对数据库的高可扩展性和高可用性的需求。
9.2 理论基础
- CAP原则又称CAP定理,指的是在一个分布式系统中,Consistency(一致性)、Availability (可用性)、Partition tolerance (分区容错性),三者最多只能得其二。
- 一致性(C): 在分布式系统中的所有数据备份,在同一时刻是否同样的值。 (等同于所有节点访问同一份最新的数据副本)
- 可用性 (A): 在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
- 分区容忍性(P):以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
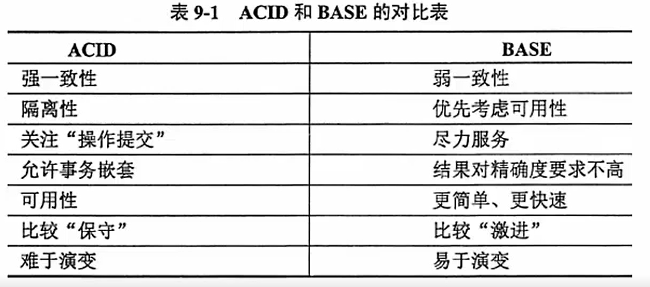
- 由于CAP 理论的存在,为了提高性能,出现了ACID 的一种变种BASE: Basically Available(基本可用),Soft state (软状态) 和 Eventually consistent (最终一致性)。
- Base理论核心思想是:既然无法做到强一致性,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性。
- 基本可用:系统出现了不可预知的故障,但相比较于正常系统还是能用的。
- 软状态:允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本存在数据延时。
- 最终一致性:系统能够保证在没有其他新的更新操作的情况下,数据最终一定能够达到一致的状态,因此所有客户端对系统的数据访问最终都能够获取到最新的值。
- 具体地说,如果选择了CP (一致性和分区容忍性),那么就要考虑ACID 理论如果选择了AP (可用性和分区容忍性)那么就要考虑BASE 系统。如果选择了CA(一致性和可用性),那么在网络发生分区的时候,将不能进行完整的操作。
9.3 分区方法
(1)内存缓存:缓存技术可以看成一种分区。内存中的数据库系统将使用频率最高的数据复制到缓存中,加快了数据给用户传递的速度,同时也大大减轻了数据库服务器的负担。
(2)集群:数据库服务器集群在为用户提供服务时的透明性(用户感觉数据像是在同一个地2是另外一个对数据进行分区的方法。
(3)读写分离: 指定一台或多台主服务器,所有或部分的写操作被送至此,同时再设一定数量的副本服务器用以满足读请求。
(4)范围分割技术/分片(sharding): 指对数据按照如下方式进行分区操作,即对数据的请求和更新在同一个结点上,并且对于分布在不同服务器上的数据存储和下载的量大致相同。
9.4 存储分布
- 行存储和列存储:两者之间的主要区别在于,行存储将每条记录的所有字段的数据聚合存储而列存储将所有记录中相同字段的数据聚合存储。行存储主要适用于OLTP,或者更新操作,尤其是插入、删除操作频繁的场合: 而列存储主要适用于OLAP,数据仓库,数据挖掘等查询密集型应用。
- 带有局部性群组的列存储:是指根据需要将原来不存储在一起的数据,以列族为单位存储至单独的字表中。如用户对网站排名、语言等分析信息感兴趣,那么可以将这些列族放在单独的子表减少无用信息读取,改善存取效率。
- LSM-Tree:日志结构合并树,与前面介绍的存储结构有所不同,前面的存储结构在描述如何序列化逻辑数据结构,而LSM-Tree 描述的则是为了满足高效、高性能、安全地读写的要求,如何有效地利用内存和磁盘存储。主要用于解决日志记录索引的问题
9.5 查询模型
- 结合SQL 数据库:一个最直接的方式是通过将NOSQL 数据库拷贝到关系数据库或者文本数据库来提供查询能方。
- 分散/集合本地搜索:一些NOSQL数据库提供本地数据库内的索引和查询处理机制。在这种情况下,我们可以让查询处理器将查询广播到DHT(分散哈希表)中的所有节点,在每个节点上将会执行查询,并将结果送回到查询处理器,然后查询处理器将结果聚集成一个单一响应。
- 分布式B十树:其基本思路是为了定位B+树的根节点哈希要搜索的属性。根节点的“值”包含其孩子节点的ID。
- 前缀哈希表/分布式Trie:前缀哈希表 (Prefix Hash Table, PHT,又名分布式Trie) 目的是一个树形数据结构。在这个树形结构中,从根节点到叶子的每一条路径上均包含了键值的前缀,并且每个Trie中的节点都包含了它是谁的前缀的所有数据。
9.6 存储模式
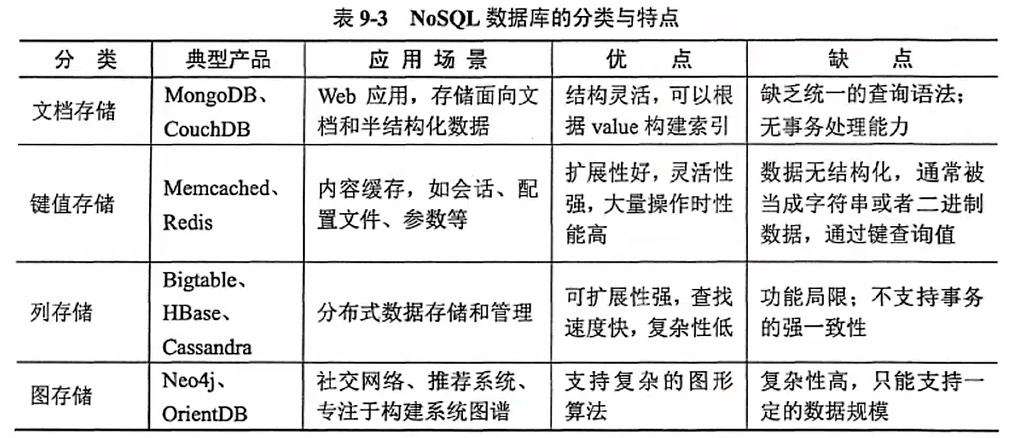
其他存储模式:
(1)多值数据库:是分布式数据库系统的重要分支。它速度快,体积小,比关系数据库便宜,很快得到了认可。它提供了一个通用的数据集成与访问平台,屏蔽了现有各数据库系统不同的访问方法和用户界面,给用户呈现出一个访问多种数据库的公共接口。多值数据库系统使用的多个异构的数据源之间可以共享它们相互依赖的数据,并具有相互操作的能力。常见的多值数据库有Rocket U2, Extensible Storage Engin (ESE/NT)、OpenInsight 和OpenQM等。
(2)时间序列与流数据库:时间序列数据库是指具有处理时间序列数据,能对时间数据数组建立索引的优化数据库系统。流数据库又被称为实时数据库,这是一种使用实时处理数据的方式来处理状态不断变化的数据库系统。对时间序列的数据库提出实时的处理要求,那么时间数据库就是流数据库。常见的时间序列数据库InfluxDB、OpenTSDBo。
(3)网格和云数据库:是基于网格计算或者云计算的数据库。
【软考数据库】第一章 计算机系统基础知识
【软考数据库】第二章 程序语言基础知识
【软考数据库】第三章 数据结构与算法
【软考数据库】第四章 操作系统知识
【软考数据库】第五章 计算机网络
【软考数据库】第六章 数据库技术基础
【软考数据库】第七章 关系数据库
【软考数据库】第八章 数据库SQL语言