基于文法模型的中文纠错系统

徐明 编译
论文地址:http://www.anthology.aclweb.org/W/W14/W14-6827.pdf
相关开源项目:https://github.com/shibing624/pycorrector
摘要
本文介绍了我们的系统在SIGHAN-8 Bake-Off 中的中文拼写检查(Chinese spelling check,CSC)任务。给定一个句子,我们的系统被设计用来检测和纠正拼写错误。正如我们所知,CSC仍然是一个热门话题今天,这是一个尚未解决的问题。N-gram语言建模(LM)由于其简单性和强大性,在CSC中得到了广泛的应用。我们提出了一种联合二元、三元文法和中文分词的模型。此外,我们使用动态规划来提高效率,使用平滑技术来处理训练数据中的N元文法数据的稀疏性。评价结果表明了我们的CSC系统具有很好的实用性。
1. 介绍
拼写检查是每种书面语言的共同任务,它可以用于自动检测和纠正人类的拼写错误(Wu等人,2013)。自动拼写校正早在20世纪60年代就开始了(Kukic,1992)。拼写检查系统应该具有错误检测和错误纠正两种能力。错误检测是指检测在文本中拼写错误的各种类型,错误纠正是指进一步改正检测到的错误字符。
近几十年来,汉语作为外语正在蓬勃发展。未来几年汉语作为外语(Chinese as a foreign language,CFL)的学习者的数量将会越来越大(Xiong等人,2014)。汉语自动拼写检查已成为当今的一项重要任务。为此,在SIGHAN Bake-off组织了中文拼写检查(CSC)任务,为比较和研究中文自动拼写检查系统提供了一个平台。然而,与英语或其他字母语言不同,汉语是音调音节和字符组成的语言,其中每个字符的发音都是音调音节共同组成(Chen等人,2013)。在汉语中,词之间没有分隔符或边界,每个汉语“词”的长度非常短,在大多数情况下可能只有两个或三个字符。此外,拼写错误的类型比其他语言多,因为许多汉字的形状相似或发音相同,甚至有些字符在形状和发音上都相似(吴等人,2010;刘等人,2011)。
到目前为止,大量的研究正在进行中。例如,基于规则的模型(Jiang等人,2012;Chiu等人,2013)、n元文法模型(Wu等人,2010;Wang等人,2013;Chen等人,2013;Huang等人,2014)、图论(Bao等人,2011;Jia等人,2013;Xin等人,2014)、统计学习方法(Han和Chang,2013;Xiong等人,2014)等。
语言模型(LM)在CSC中得到了广泛的应用,迄今为止应用最广泛、实践最成熟的语言模型是N元文法语言模型(Jelinek,1999),因为它简单并且好理解。我们也继续使用N元文法语言模型,并且提出了一种联合二元和三元文法的拼写错误检测和纠正模型。我们在预处理阶段进行了分词,在一定程度上提高了系统性能。另外,为了减少程序的运行时间,采用了动态规划的方法,并采用加法平滑的方法来解决训练集中的数据稀疏问题。
本文的其余部分结构如下:在第2节中,我们简要介绍了我们的CSC系统、混淆集和N元文法中N的选择;第3节详细介绍了我们的中文语言模型;评估结果在第4节中给出;最后一部分对本文进行了总结,并对今后的工作进行了展望。
2. 系统介绍
2.1 系统概览
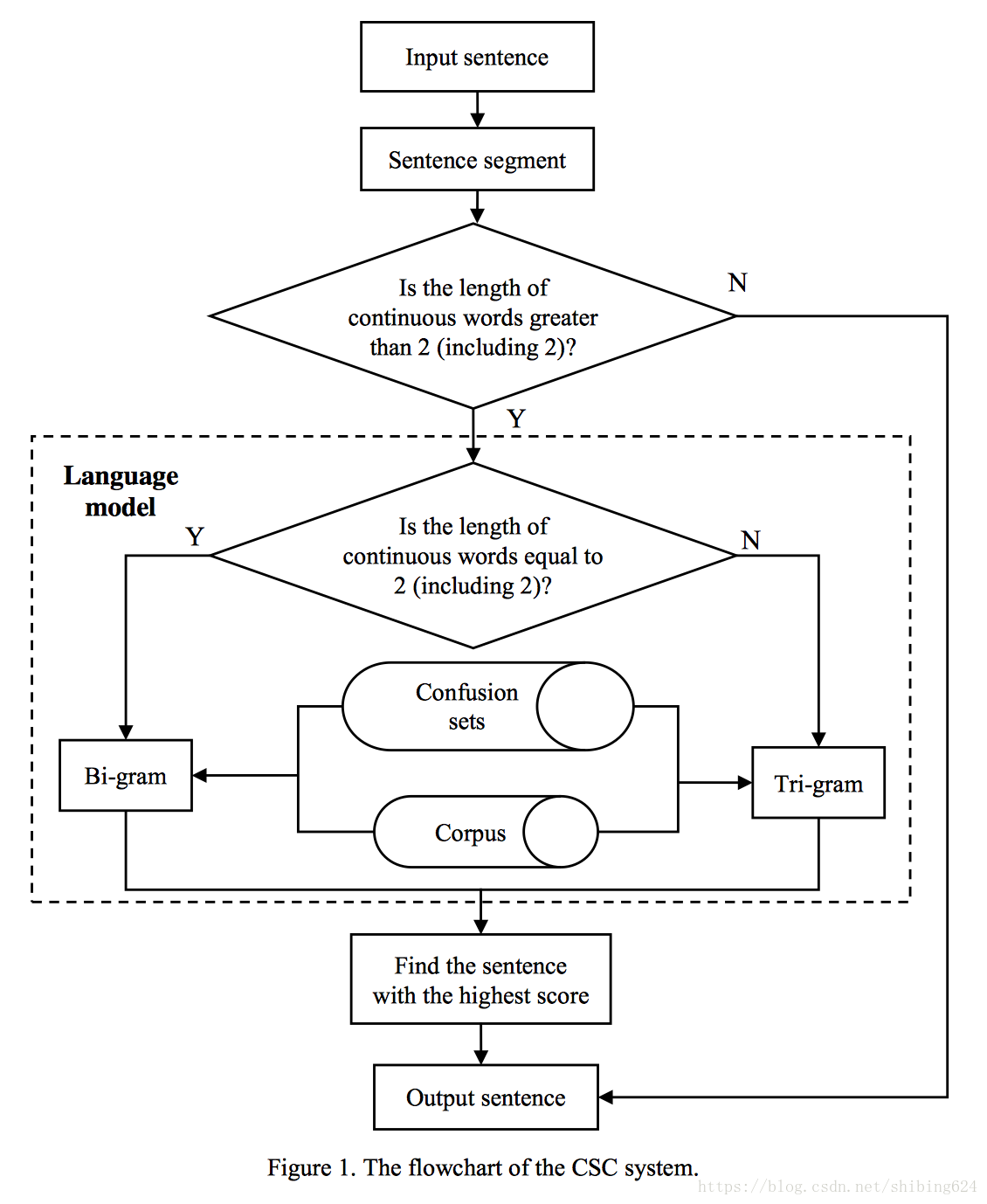
图1显示了我们的CSC系统的流程图。该系统主要由中文分词、混淆集、语料库和语言模型四部分组成。它有以下步骤:
- 步骤1:利用中文分词技术对给定句子进行切词。分词结果将作为下一步的基础。
- 步骤2:根据判断条件,系统收集句子中对应词的混淆集。
- 步骤3:对于这个句子中可以替换的每个字符(根据相应的条件),系统将枚举其混淆集的每个词来替换原始词语。我们将在这个步骤之后得到一个候选句子集。
- 步骤4:系统采用联合二元和三元文法语言模型(根据不同的条件使用二元文法和三元文法)计算每个候选句子的得分。我们使用CCL语料库和搜狗语料库来生成N元文法的频率。最后,选择最高得分的句子作为最终输出。
为了减少在步骤3和步骤4中的运行时间,我们采用动态规划来优化算法。
2.2 混淆集
混淆集,由容易被混淆的字符及词组成的数据集,在文本的拼写错误检测和纠正中起着关键作用(Wang等人,2013)。大多数汉字在形状或发音上都有相似的特征。由于拼音输入法是当前最流行的中文输入法,因此在构建我们系统中使用的混淆集时,相似发音占优势。此外,形似的字符不是特别多,但仍然存在着相当大的比例(Liu等人,2011)。书写相似的字符也被添加到我们的混淆集中。因此,系统使用的混淆集是由许多带有约束的规则创建的,包括相似的发音和类似的字形。
一些发音相似的汉字,如汉语同音字(“字”和“自”)、鼻音(“藏”)和非鼻音(“赞”)、卷舌(“找”和非卷舌(“早”)等。
此外,它还包括其他容易混淆的条件(基于统计),如“妻”-“西”、“嫂”-“搜”等。
对于形似的汉字,例如汉字的同一字根(“固”和“回”)和类似的五笔输入法(“丏”和“丐”)。
所有这些规则都受限于汉字的笔划,以减少每个字符的混淆集的大小。
2.3 语言模型
由于语言模型可以用来测量给定文本的通顺度,因此许多以前的研究者采用语言模型预测正确的词来替换句子中疑似错误的词(Chen等人,2009;Liu等人,2011;Wu等人,2010)。迄今为止最广泛使用和效果良好的语言模型是N元文法模型(Jelinek,1999),因为它的简单并且预测结果公平。
在n-gram建模中选择n-gram的顺序是非常重要的。高阶的n-gram模型,如4gram或5gram以及更大的语料库,往往会提高模型的质量,因此会生成较低的文本困惑度。然而,高阶n-gram模型通常具有稀疏性,从而导致一些零条件概率结果产生(Chen等人,2013)。由于这个原因,我们基于不同规则使用二元文法模型或者三元文法模型,来确定哪个字符是最佳纠正选择。具体的,在我们的系统中,根据中文分词结果,判断它是否有长度大于或等于2的连续的词,如果单词的长度等于2,则使用二元模型,如果大于2,则使用三元模型。
3 中文N元文法模型
3.1 二元文法模型
给定中文字符串,如果句子中有错误,错误单词将出现在中文分词后的一个连续的单词串中。一般,连续句的长度在没有错误的句子的分裂之后不超过2。根据这个判断,当连续词的长度等于2时,系统将采用双元文法模型来检测和纠正错误。
例如,像这个句子“李大年的确是一个问提”的切词结果是“李大年/的确/是/一个/问/提”,而“题”是“提”的纠正结果。如果存在多个连续单词长度等于2的地方,这意味着句子可能存在多处拼写错误,那么我们在相应的地方使用二元文法模型。例如,在切词之后,句子“李大年的是的确是一个温题”将是“李大年/的/是/的确/是/一个/温/题”,其中第一“是”应该是“事”,而“温”应该是“问”。
二元文法模型中字符串的概率是由各个词的条件概率乘积的近似表示(Jelinek,1999),在二元文法模型中,我们作出一个假设,一个词的概率只取决于其前面的一个单词。在我们的系统中,以下面的方式使用二元文法模型:使用具有最大得分的二元组单词作为正确的字符串来替换旧的字符串。
3.2 三元文法模型
上面提到的二元文法模型,我们认为如果连续单词的长度超过2,则二元文法模型来表达句子的似然概率就不合适了。因为有三个或更多的连续词,我们有理由相信出现在打字错误中的句子可能是连续的。因此,在这种情况下,我们使用三元模型来检测和纠正错误。
在上述三元文法模型中,我们对词语的似然概率的近似只依赖于其前面两个单词的似然概率值。
3.3 得分函数的定义
我们先定义一个候选句子, 这个候选句子是从原句中通过混淆集替换派生出来的。利用得分计算函数选择最合适的候选句子。图2(a)和(b)分别是用二元模型和三元模型表示得分函数的伪代码。

图3(a)和(b)分别是用二元模型和三元模型计算得分函数的示例。

3.4 动态规划
比较简单,不多说。
3.5 加法平滑
在统计学中,加法平滑或其别名Laplace平滑和Lidstone平滑都是一种用于平滑数据的技术(Chen等人,1996)。
在我们的模型中,数据弥补了语料库中每个字符串的出现次数。由于训练数据的稀疏性,即训练数据中没有出现的汉字,我们使用加法平滑来缓解这种数据稀疏性问题。
我们重新定义新的得分计算函数,如图5所示。

4 实验
4.1 任务
中文拼写检查任务是为SIGHAN-8 bake-off而组织的。本课题的目标是确定中文拼写检查系统的能力,并希望产生更先进的中文拼写检查技术。文章由几个有或没有拼写错误的句子组成,即多词、缺词、单词乱序和单词选择错误。每个字符或标点都算一个位置,如果句子中有任何拼写错误,系统应该自动返回不正确字符和正确字符的位置。提供两个训练数据(CLP-SIGHAN 2014 CSC Datasets 3 and SIGHAN-7 CSC Datasets),以及CFL数据。
4.2 评测标准
判断正确的标准是:
(1)检测级别:给定段落中不正确字符的所有位置都应该与金标准完全一致。
(2)纠正级别:所有纠正位置和纠正词应与金标准完全一致。
4.3 评测结果
SIGHAN-8中文拼写检查任务吸引了9个队伍参加。9个队伍中有6个提交了结果。对于正式测试,每个参与者有权提交最多三次运行结果,使用不同的模型或参数设置。最后提交了15次结果。
我们系统的三个结果
我们的系统三次提交结果如下:
第一次(Tri-gram+分词):先依次用相应的混淆集替换句子中的每个词,然后使用tri-gram模型计算新的句子得分。同时,我们将句子切分数作为评分计算的标准之一。换言之,我们认为切分总数越少,句子得分越高,即切词数与得分成反比。
第二次(联合bi-gram和tri-gram+分词):本文中提出的联合bi-gram和tri-gram语言模型以及分词提出的方法。
第三次(Tri-gram):使用第一次的方法,但没有中文分词的结果。这是我们去年在Bake-Off 2014任务中提出的方法(Huang等人,2014)。我们用它作为基线模型。
第二次结果的验证
表1显示了第二次结果的前3名验证分数,即使用不同加法平滑参数的结果,并且它们的参数值分别是30、35和40。我们利用TEST1的方法和参数作为任务的最终结果提交。
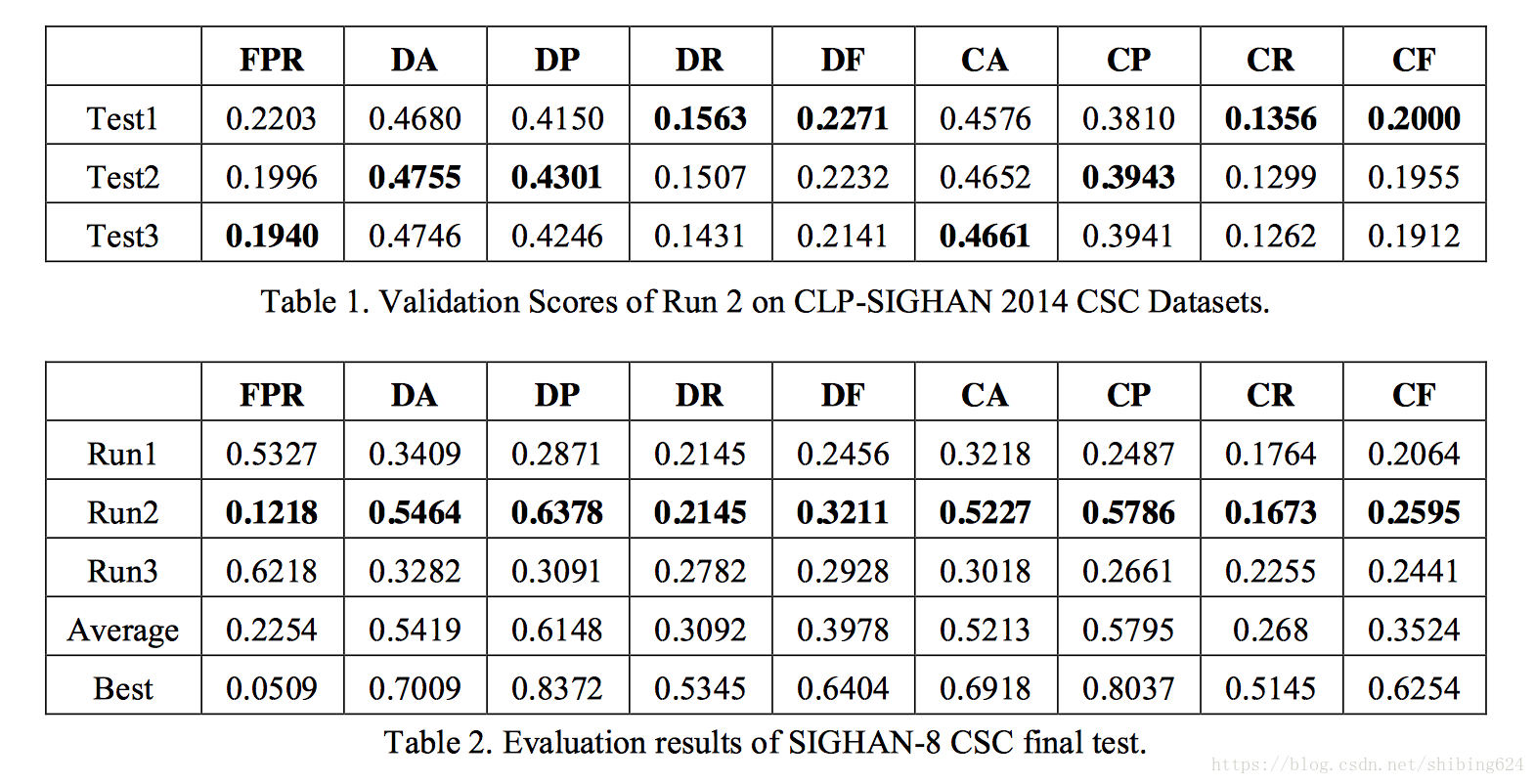
SIGHAN中文纠错任务最终结果
表2显示了最终测试的评测结果。Run1、Run2和Run3是我们的系统用不同的方法提交的三次运行结果。“最佳”表示CSC任务中每个度量指标的最高分。“平均”代表15次结果的平均值。
根据表2中的结果,我们可以看到我们的系统的结果接近于平均水平。我们系统的主要缺点是召回率。原因可能是我们没有应用单独的错误检测模块。
虽然与三元文法模型的基线模型相比,使用联合二元文法和三元文法的模型得到了比较好的改善,但N元文法模型的潜在能力远未充分利用。下一节将介绍当前系统的一些典型错误,在第5节中将总结一些可能的改进。
4.4 错误分析
图6显示了我们系统中的一些典型错误示例(“O”代表原始句子,“M”代表纠正后的句子):

5 结论和展望
本文介绍了华南农业大学(SCAU)参加SIGHAN-8中文拼写检查任务。本文提出的联合二元和三元文法语言模型有助于提高检测和校正的结果。在输入句子上进行分词,针对三元文法模型计算过程中计算量大的问题,采用动态规划的方法提高算法的效率。采用加法平滑的方法解决训练集中的数据稀疏问题。此外,我们通过在混淆集中补充书写相似的字符(五笔相似)来优化纠正正准确率。
这是我们第二次尝试中文拼写检查任务,SIGHAN-8最终测试的评估结果表明,与去年CLP-SIGHAN Bake-Off 2014CSC任务中提出的方法相比,错误检测F值(DF)和错误纠正F值(CF)分别提高了9.7%和6.3%。语言模型在中文纠错任务中得到了广泛的应用。然而,N元文法语言模型仅仅着眼于捕捉语言的局部上下文信息或词汇规律。未来的工作将探索大跨度语义信息的语言建模,以进一步改善中文纠错任务。更重要的是,我们仍然需要对如何处理字符误杀(过多纠正)问题进行更多的研究,使中文纠错系统更加完善。
参考文献
Zhuowei Bao, Benny Kimelfeld, Yunyao Li. 2011. A Graph Approach to Spelling Correction in Domain- th Centric Search. In Proceedings of the 49 Annual Meeting of the Association for Computational Linguistics (ACL 2011), pp.905–914.
Stanley F. Chen, Joshua Goodman. 1996. An Empirical Study of Smoothing Techniques for th Language Modeling. In Proceedings of the 34 Annual Meeting of the Association for Computational Linguistics (ACL 1996), pp.310-318.
Berlin Chen. 2009. Word Topic Models for Spoken Document Retrieval and Transcription. ACM Transactions on Asian Language Information Processing, Vol. 8, No. 1, pp. 2: 1-2: 27.
Kuan-Yu Chen, Hung-Shin Lee, Chung-Han Lee , et al.. 2013. A Study of Language Modeling for Chinese Spelling Check. In Proceedings of the Seventh 7th Workshop on Chinese Language Processing (SIGHAN-7), Nagoya, Japan, 14 Oct., 2013, pp. 79–83.
Hsun-wen Chiu, Jian-cheng Wu and Jason S. Chang. 2013. Chinese Spelling Checker Based on Statistical Machine Translation. In Proceedings of the 7 th SIGHAN Workshop on Chinese Language Processing (SIGHAN-7), Nagoya, Japan, 14 Oct., 2013, pp. 49-53.
Dongxu Han, Baobao Chang. 2013. A Maximum Entropy Approach to Chinese Spelling Check. In Proceedings of the 7 th SIGHAN Workshop on Chinese Language Processing (SIGHAN-7), Nagoya, Japan, 14 Oct., 2013, pp. 74-78.
Qiang Huang, Peijie Huang, Xinrui Zhang, et al.. 2014. Chinese spelling check system based on tri- gram model. In Proceedings of the Third CIPS-SIGHAN Language Joint Conference on Chinese Language Processing (CLP-2014), Wuhan, China, 20-21 Oct., 2014. pp.173-178.