1.背景
在云渲染容器组pod中,有xx,xx,xx,unity四个container容器组成,然后因为unity容器镜像的构成是基于vlukan(cudagl相关)和cuda-base打包的,这里的cuda是nvidia的一个驱动版本,类似显卡驱动。现象是启动unity容器后无法运行nvidia-smi和vlukaninfo
初步排查:
因为容器化运行需要依赖宿主机的GPU机器资源,需要宿主机有nvidia驱动且容器能正常映射到宿主机资源。
最后定位到容器中nvidia-smi未输出任何信息,是由于nvidia-container-toolkit组件未将GPU设备挂载到容器中,组件中的nvidia-container-runtime无法被containerd管理和使用。
2.部署
2.1.宿主机上部署nvidia驱动
- 选择操作系统和安装包,单机下载驱动版本,访问官网下载
- 在宿主机上执行安装
chmod a+x NVIDIA-Linux-x86_64-460.73.01.run && ./NVIDIA-Linux-x86_64-460.73.01.run --ui=none --no-questions
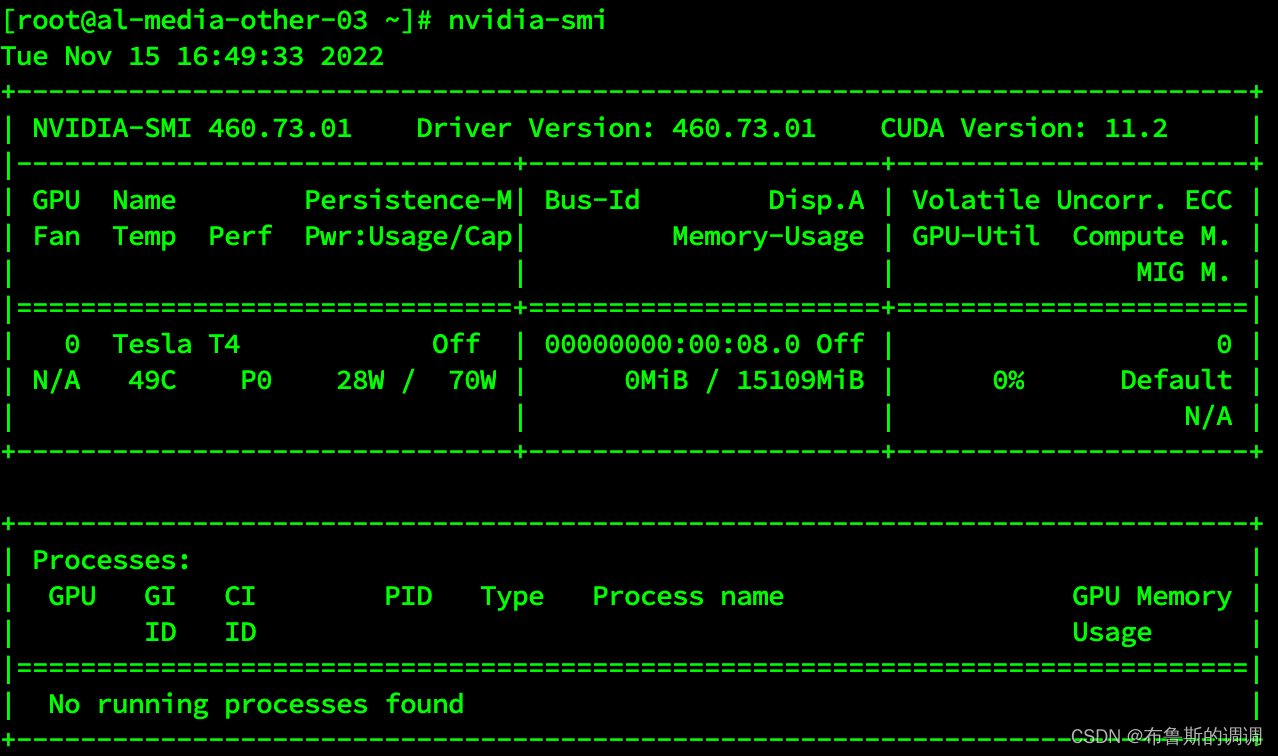
- 宿主机验证是否安装成功,执行nvidia-smi,输出下图则安装成功
- cuda驱动安装
- 备注:此操作已经在打包的容器镜像中安装,可以跳过执行
- 可以在官网下载驱动版本

- 添加nvidia-docker仓库且安装工具包nvidia-container-toolkit
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
yum install -y nvidia-container-toolkit
- 安装x,可视化桌面
- 修改/etc/X11/xorg.conf中的pci序列号和nvidia-smi中的序列号一样
- 运行gdm服务
2.2.k8s容器中部署驱动
- 集群中部署nvidia gpu设备插件
kubectl apply -f https://github.com/NVIDIA/k8s-device-plugin/blob/main/nvidia-device-plugin.yml
# Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: nvidia-device-plugin-daemonset
namespace: kube-system
spec:
selector:
matchLabels:
name: nvidia-device-plugin-ds
updateStrategy:
type: RollingUpdate
template:
metadata:
labels:
name: nvidia-device-plugin-ds
spec:
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
# Mark this pod as a critical add-on; when enabled, the critical add-on
# scheduler reserves resources for critical add-on pods so that they can
# be rescheduled after a failure.
# See https://kubernetes.io/docs/tasks/administer-cluster/guaranteed-scheduling-critical-addon-pods/
priorityClassName: "system-node-critical"
containers:
- image: nvcr.io/nvidia/k8s-device-plugin:v0.13.0-rc.1
name: nvidia-device-plugin-ctr
env:
- name: FAIL_ON_INIT_ERROR
value: "false"
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop: ["ALL"]
volumeMounts:
- name: device-plugin
mountPath: /var/lib/kubelet/device-plugins
volumes:
- name: device-plugin
hostPath:
path: /var/lib/kubelet/device-plugins
- 进入容器untiy测试执行,nvidia-smi
- 或者直接用containerd命令行ctr测试
ctr images pull docker.io/nvidia/cuda:9.0-base
ctr run --rm -t --gpus 0 docker.io/nvidia/cuda:9.0-base nvidia-smi
nvidia-smi
3.问题排查
3.1.方向一sealos节点加入集群后,提示错误
- 在宿主机配置完后,sealos加入集群
[root@iZbp1329l07uu7gp2xxijhZ ~]# sealos join --node xx.xx.xx.xx
15:26:33 [EROR] [check.go:91] docker exist error when kubernetes version >= 1.20.
sealos install kubernetes version >= 1.20 use containerd cri instead.
please uninstall docker on [[10.0.1.88:22]]. For example run on centos7: "yum remove docker-ce containerd-io -y",
see details: https://github.com/fanux/sealos/issues/582
- 因为之前在加入集群之前,安装了docker-ce进行测试,和kubernetes下载的运行时containerd相冲突,根据提示需要将这些删除
- 根据官网安装步骤
- 更新yum源并添加源
- 安装docker-ce
- 安装nvidia container tookit,参见宿主机安装过程
- 安装nvidia-docker2
- 验证,容器内是否能映射到gpu资源
yum update -y
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum makecache fast
yum install docker-ce -y
systemctl --now enable docker
yum clean expire-cache
yum install -y nvidia-docker2
systemctl restart docker
docker run --rm --gpus all nvidia/cuda:11.6.2-base-ubuntu20.04 nvidia-smi
结论:
这里是在加入集群k8s之前的操作,安装了docker-ce和container-io,需要先卸载,然后在sealos加入集群后,在去安装nvidia-docker2
3.2.方向二集群k8s容器守护进程containerd未加载插件和docker启动错误
- 在加入容器后,修改daemon.json后docker容器报错
[root@al-media-other-03 ~]# systemctl status docker
● docker.service - Docker Application Container Engine
Loaded: loaded (/usr/lib/systemd/system/docker.service; enabled; vendor preset: disabled)
Active: failed (Result: start-limit) since Tue 2022-11-15 17:29:31 CST; 7s ago
Docs: https://docs.docker.com
Process: 17379 ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock (code=exited, status=1/FAILURE)
Main PID: 17379 (code=exited, status=1/FAILURE)
Nov 15 17:29:28 al-media-other-03 systemd[1]: Failed to start Docker Application Container Engine.
Nov 15 17:29:28 al-media-other-03 systemd[1]: Unit docker.service entered failed state.
Nov 15 17:29:28 al-media-other-03 systemd[1]: docker.service failed.
Nov 15 17:29:31 al-media-other-03 systemd[1]: docker.service holdoff time over, scheduling restart.
Nov 15 17:29:31 al-media-other-03 systemd[1]: Stopped Docker Application Container Engine.
Nov 15 17:29:31 al-media-other-03 systemd[1]: start request repeated too quickly for docker.service
Nov 15 17:29:31 al-media-other-03 systemd[1]: Failed to start Docker Application Container Engine.
Nov 15 17:29:31 al-media-other-03 systemd[1]: Unit docker.service entered failed state.
Nov 15 17:29:31 al-media-other-03 systemd[1]: docker.service failed.
- 参考官网,修改daemon.json,然后重新启动docker
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
- 在节点加入集群后的,containerd的配置文件不能加载nvidia-container-runtime
- 参考如上官网地址,先执行containerd config default >
/etc/containerd/config.toml初始化containerd配置项,然后修改添加/etc/containerd/config.toml如下,runc修改成nvidia,同时添加plugin加载信息,然后在重启containerd
version = 2
[plugins]
[plugins."io.containerd.grpc.v1.cri"]
[plugins."io.containerd.grpc.v1.cri".containerd]
default_runtime_name = "nvidia"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia]
privileged_without_host_devices = false
runtime_engine = ""
runtime_root = ""
runtime_type = "io.containerd.runc.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options]
BinaryName = "/usr/bin/nvidia-container-runtime"
结论:
需要修改docker和containerd的配置文件,让nvidia-container-runtime可以运行时加载
3.3.方向三nvidia-plugin容器log日志报错
- 前面容器部署驱动yaml的时候,查看pod日志有报错
[root@al-master-01 ~]# kubectl logs nvidia-device-plugin-daemonset-4qdqw -n kube-system
2022/11/15 03:43:58 Loading NVML
2022/11/15 03:43:58 Failed to initialize NVML: could not load NVML library.
2022/11/15 03:43:58 If this is a GPU node, did you set the docker default runtime to `nvidia`?
2022/11/15 03:43:58 You can check the prerequisites at: https://github.com/NVIDIA/k8s-device-plugin#prerequisites
2022/11/15 03:43:58 You can learn how to set the runtime at: https://github.com/NVIDIA/k8s-device-plugin#quick-start
2022/11/15 03:43:58 If this is not a GPU node, you should set up a toleration or nodeSelector to only deploy this plugin on GPU nodes
- 这里根据官网搜索是因为未加载nvidia-container-runtime,暂未解决
- 在deployment.yaml中设置了pod选择nodeSelector独占式使用GPU节点,已经可以在容器内运行nvidia-smi和vlukaninfo
apiVersion: apps/v1
kind: Deployment
metadata:
name: cuda-vector-add
spec:
replicas: 1
selector:
matchLabels:
app: cuda-vector-add
template:
metadata:
labels:
app: cuda-vector-add
spec:
nodeSelector:
node-scope: gpu-node
imagePullSecrets:
- name: xxx
containers:
- name: cuda-vector-add
image: "k8s.gcr.io/cuda-vector-add:v0.1"
imagePullPolicy: IfNotPresent
关注微信公众号
搜索:布鲁斯手记