大家好,我是王老狮,上一篇我们简单介绍了下什么是决策树,这章我们来看如何根据实际问题构建决策树,然后来进行决策。
1.影响决策的重要因素,纯度和信息熵
我们先看一组数据集:

我们该如何构造一个判断是否去相亲的决策树呢?
根据创建决策树的步骤,首先我们要确定决策树的根节点。但是在众多影响因子中,每种影响因素肯定有所区别,那么我们应该选取那个属性当做根节点呢?
那么我们先了解下两个重要概念:纯度和信息熵
1.1.纯度
纯度就是我们一组数据差异性的大小,换种方式来解释就是让目标变量的分歧变小。纯度越高,差异性越小。
集合 1:6 次都去相亲;
集合 2:4 次去相亲,2 次不去相亲;
集合 3:3 次去相亲,3 次不去相亲;
按照纯度指标来说,集合 1> 集合 2> 集合 3。因为集合 1 的分歧最小,集合 3 的分歧最大。
1.2.信息熵
信息熵(information entropy)是信息论的基本概念。描述信息源各可能事件发生的不确定性。20世纪40年代,香农(C.E.Shannon)借鉴了热力学的概念,把信息中排除了冗余后的平均信息量称为“信息熵”.可以理解为信息的不确定度。
随机离散事件出现的概率存在着不确定性。为了衡量这种信息的不确定性,信息学之父香农引入了信息熵的概念,并给出了计算信息熵的数学公式:

p(i|t) 代表了节点 t 为分类 i 的概率,其中 log2 为取以 2 为底的对数。这里的公式含义表示:当不确定性越大时,它所包含的信息量也就越大,信息熵也就越高。
根据公式,我们计算下面集合的信息熵
集合1:6 次都见面 信息熵就是 -6/6log26/6 = 0;
集合2:4 次去见面,2 次不去见面 -(4/6log2 4/6+2/6log2 2/6)=0.918
集合 3:3 次去见面,3 次不去见面 -(3/6log2 3/6+3/6log2 3/6)=1
从上面的计算结果中可以看出,信息熵越大,纯度越低。当集合中的所有样本均匀混合时,信息熵最大,纯度最低。
我们在构造决策树的时候,会基于纯度来构建。常用的算法分别是信息增益(ID3 算法)、信息增益率(C4.5算法)以及基尼指数(Car算法)
2.ID3算法
2.1.ID3算法介绍
ID3算法最早是由罗斯昆(J. Ross Quinlan)于1975年在悉尼大学提出的一种分类预测算法,算法的核心是“信息熵”。ID3算法通过计算每个属性的信息增益,认为信息增益高的是好属性,每次划分选取信息增益最高的属性为划分标准,重复这个过程,直至生成一个能完美分类训练样例的决策树。
ID3 算法计算的是信息增益,本身是一种贪心算法,信息增益指的就是划分可以带来纯度的提高,信息熵的下降。它的计算公式,是父亲节点的信息熵减去所有子节点的信息熵。在计算的过程中,我们会计算每个子节点的归一化信息熵,即按照每个子节点在父节点中出现的概率,来计算这些子节点的信息熵。所以信息增益的公式可以表示为
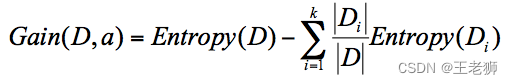
公式中 D 是父亲节点,Di 是子节点,Gain(D,a) 中的 a 作为 D 节点的属性选择。
2.2.使用ID3算法进行决策树的构造
我们根据信息增益的公式来算一个各个属性的信息增益是多少,来选择更合适的属性当做根节点
7条数据,根据结果4条不见面,3条见面,所以根节点的信息熵是:
Entropy(D)=-(4/7log2 4/7+3/7log2 3/7)=0.985
如果将经济条件当做属性划分,则有三个子节点,分别为有钱、一般、没钱,我们用D1,D2,D3标识,他们对应的见面结果我们用+,-表示。那么经济条件作为属性节点的计算方式如下:
经济条件信息增益
D1(经济条件=有钱)={1-,2-,6+}=Ent(D1)=-(2/3log2 2/3+1/3log2 1/3)=0.918
D2(经济条件=一般)={3+,7-}=Ent(D2)=-(1/2log2 1/2+1/2log2 1/2)=1
D3(经济条件=没钱)={4+,5-}=Ent(D2)=-(1/2log2 1/2+1/2log2 1/2)=1
信息熵归一化 3/70.918+2/71+2/7*1=0.965
以经济条件作为属性节点的信息增益为Gain(D,经济)=0.985-0.965=0.020.
同理,其他属性作为根节点的信息增益计算方式如下:
身高信息增益
D1(身高=高)={5-}=Ent(D1)=-(1log2 1+1log2 1)=0
D2(身高=一般)={6+,7–}=Ent(D2)=-(1/2log2 1/2+1/2log2 1/2)=1
D3(身高=低)={1-,2-,3+,4+}=Ent(D2)=-(1/2log2 1/2+1/2log2 1/2)=1
归一化信息熵为 1/70+2/71+4/7*1=0.857
信息增益为Gain(D,经济条件)=0.985-0.857=0.128
长相信息增益
D1(长相=帅)={3+,4±,5-,6-}=Ent(D1)=-(2/4log2 2/4+2/4log2 2/4)=1
D2(长相=不帅)={1-,2-,6+}=Ent(D2)=-(2/3log2 2/3+1/3log2 1/3)=0.918
归一化信息熵为 4/71+3/70.918=0.965
信息增益为Gain(D,长相)=0.985-0.965=0.02
得到每个属性当做属性节点的归一化信息熵和信息增益数据如下:
| 属性 | 归一化信息熵 | 信息增益 |
|---|---|---|
| 经济 | 0.965 | 0.02 |
| 身高 | 0.857 | 0.128 |
| 长相 | 0.965 | 0.02 |
| 附加 | 0.965 | 0.02 |
所以以身高作为根节点则信息增益最大,ID3算法就是以信息增益最大的节点当做父节点,获取纯度高的决策树。因此以身高当做根节点,那么决策树形状如下
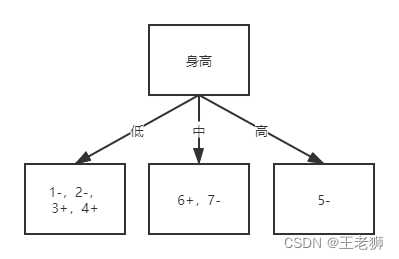
继续往下划分,以低属性节点继续往下分,计算不同属性的信息增益
长相
D1(长相=帅)={3+,4+}=Ent(D1)=-(1log2 1 +10log2 0)=0
D2(长相=不帅)={1-,2-}=Ent(D2)=-(1log2 1 +10log2 0)=0
归一化信息熵为 0
信息增益为Gain(D,长相)=1-0=1
经济条件
D1(经济条件=有钱)={1-,2-}=Ent(D1)=-(1log2 1 +1log2 1)=0
D2(经济条件=一般)={3+}=Ent(D2)=-(1log2 1 +1log2 1)=0
D3(经济条件=没钱)={4+}=Ent(D2)=0
归一化信息熵为 0
信息增益为Gain(D,经济条件)=1-0=1
附加
D1(其他优点=有)={1-,3+,4+}=Ent(D1)=-(1/3log2 1/3 +2/3log2 2/3)=0.918
D2(其他优点=无)={2-}=Ent(D2)=-(1log2 1 +1log2 1)=0
归一化信息熵为 3/40.918+1/40 = 0.6885
信息增益为Gain(D,经济条件)=1-0.689=0.3115
| 属性 | 归一化信息熵 | 信息增益 |
|---|---|---|
| 长相 | 0 | 1 |
| 经济 | 0 | 1 |
| 附加 | 0.6885 | 0.3115 |
可以看到长相和经济条件可以得到最大的信息增益,可以选择长相或者经济作为下一个节点的的属性节点
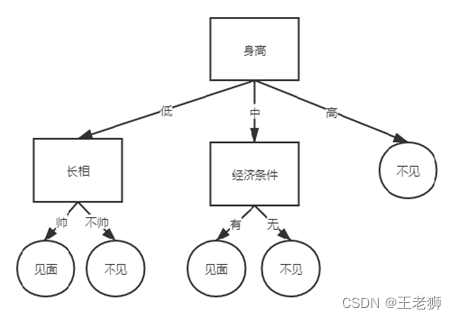
这样我们一颗决策树就构建好了,根据对方提供的条件通过决策树来决定到底该不该见面。
ID3 的算法规则相对简单,可解释性强。同样也存在缺陷,比如我们会发现 ID3 算法倾向于选择取值比较多的属性。
ID3 有一个缺陷就是,有些属性可能对分类任务没有太大作用,但是他们仍然可能会被选为最优属性。这种缺陷不是每次都会发生,只是存在一定的概率。在大部分情况下,ID3 都能生成不错的决策树分类。针对可能发生的缺陷,后人提出了新的算法进行改进,那就是C4.5。
3.C4.5算法
3.1.C4.5算法的思路
1.采用信息增益率
因为 ID3 在计算的时候,倾向于选择取值多的属性。为了避免这个问题,C4.5 采用信息增益率的方式来选择属性。信息增益率 = 信息增益 / 属性熵。
2.采用悲观剪枝
ID3 构造决策树的时候,容易产生过拟合的情况。在 C4.5 中,会在决策树构造之后采用悲观剪枝(PEP),这样可以提升决策树的泛化能力。
悲观剪枝是后剪枝技术中的一种,通过递归估算每个内部节点的分类错误率,比较剪枝前后这个节点的分类错误率来决定是否对其进行剪枝。这种剪枝方法不再需要一个单独的测试数据集。
3.离散化处理连续属性
C4.5 可以处理连续属性的情况,对连续的属性进行离散化的处理。比如相亲存在的“身高”属性,不按照“高、低”划分,而是按照身高高度进行计算,那么身高取什么值都有可能。
C4.5 选择具有最高信息增益的划分所对应的阈值。
4.处理缺失值
3.2.C4.5算法如何处理缺失值
我们看下面这组数据,数据集存在丢失的情况下,如何进行属性选择?如果已经做了属性划分,但是样本在这个属性上有缺失又该怎么对样本进行划分?

如果不考虑确实的信息,身高的信息可以表示={2-,3+,4+,5-,6+,7-},计算属性的信息熵
身高=低=D1={2-,3+,4+} 信息熵=-(1/3 log2 1/3+2/3 log2/3)=0.918
身高=一般=D2={6+,7-} 信息熵=-(1/2 log2 1/2+1/2 log1/2)=1
身高=高=D3={5-} 信息熵=-(1 log2 1)=0
计算信息增益Gain(D,身高)=Ent(D)-0.792=1-0.792=0.208
属性熵 =-3/6log3/6 - 1/6log1/6 - 2/6log2/6=1.459
信息增益率 Gain_ratio(D′, 温度)=0.208/1.459=0.1426
D′的样本个数为 6,而 D 的样本个数为 7,所以所占权重比例为 6/7,所以 Gain(D′,温度) 所占权重比例为 6/7,所以:Gain_ratio(D, 温度)=6/7*0.1426=0.122。
这样即使在温度属性的数值有缺失的情况下,我们依然可以计算信息增益,并对属性进行选择。
3.2.C4.5算法和ID3算法的对比
ID3算法
优点:
- 算法简单,通俗易懂
缺陷:
- 无法处理缺失值
- 只能处理离散值,无法处理连续值
- 用信息增益作为划分规则,存在偏向于选择取值较多的特征。因为特征取值越多,说明划分的不确定性越低,信息增益则越高
- 容易出现过拟合
C4.5算法
优点:
- 能够处理缺省值
- 能对连续值做离散处理
- 使用信息增益比,能够避免偏向于选择取值较多的特征。因为信息增益比=信息增益/属性熵,属性熵是根据属性的取值来计算的,一相除就会抵消掉
- 在构造树的过程中,会剪枝,减少过拟合
缺点:构造决策树,需要对数据进行多次扫描和排序,效率低