Pytorch加载本地自己整理好的cifar10数据集,并进行训练
使用pytorch在线下载cifar10数据集时,经常报错,而且很慢,倘若下载cifar100,那等待时间可想而知了。为了不浪费时间等待,可以将数据集先下载到本地,在自行加载,下面介绍一种修改源码简单的方法。
1.下载数据集
(随意下载,官网地址:http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz)**
 下载以后会有三种,根据你的需求选取一种,我用的是python语言。
下载以后会有三种,根据你的需求选取一种,我用的是python语言。
2.解压
把cifar-10-python.tar.gz解压,得到如下所示目录
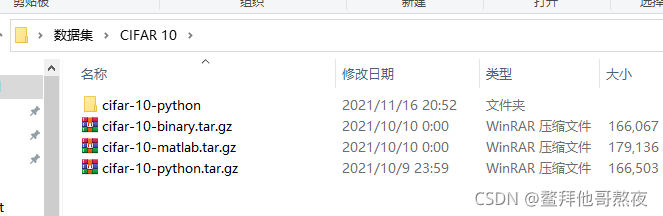
3.复制移动
将解压后的cifar-10-python文件内容复制到自己工程下的一个文件夹里(自己随意新建一个数据集文件夹即可)
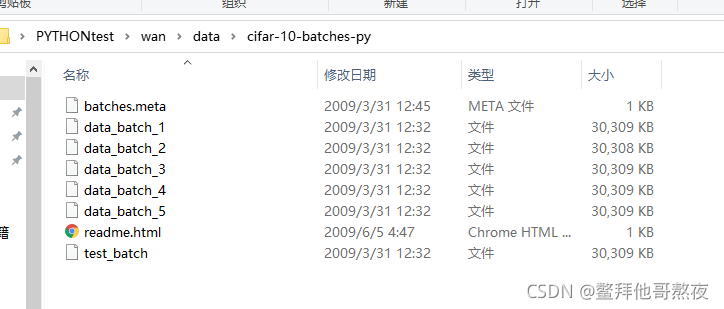
4.修改tv.datasets.CIFAR10源码
如下,可以把**“base_folder = ‘cifar-10-batches-py’”修改成你自己建立的数据集文件夹名称,我这里直接跟它一样了。可以注释掉url和filename**,使用已经下载好的数据集不需要这两个。其中tgz_md5也可注释掉,MD5是一种消息摘要加密算法,torch使用这个估计是为了下载数据集时防止木马病毒入侵篡改文件,由于我们已经下载好,故不需要了。接下来注释掉以下内容。(这些代码是检验数据集的存在和下载数据集的,我们使用本地数据集就不需要这些了)
完整注释如下
class CIFAR10(VisionDataset):
base_folder = 'cifar-10-batches-py'
#url = "https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz"
#filename = "cifar-10-python.tar.gz"
tgz_md5 = 'c58f30108f718f92721af3b95e74349a'
train_list = [
['data_batch_1', 'c99cafc152244af753f735de768cd75f'],
['data_batch_2', 'd4bba439e000b95fd0a9bffe97cbabec'],
['data_batch_3', '54ebc095f3ab1f0389bbae665268c751'],
['data_batch_4', '634d18415352ddfa80567beed471001a'],
['data_batch_5', '482c414d41f54cd18b22e5b47cb7c3cb'],
]
test_list = [
['test_batch', '40351d587109b95175f43aff81a1287e'],
]
meta = {
'filename': 'batches.meta',
'key': 'label_names',
'md5': '5ff9c542aee3614f3951f8cda6e48888',
}
def __init__(
self,
root: str,
train: bool = True,
transform: Optional[Callable] = None,
target_transform: Optional[Callable] = None,
download: bool = False,
) -> None:
super(CIFAR10, self).__init__(root, transform=transform,
target_transform=target_transform)
self.train = train # training set or test set
if download:
self.download()
"""if not self._check_integrity():
raise RuntimeError('Dataset not found or corrupted.' +
' You can use download=True to download it')"""
if self.train:
downloaded_list = self.train_list
else:
downloaded_list = self.test_list
self.data: Any = []
self.targets = []
# now load the picked numpy arrays
for file_name, checksum in downloaded_list:
file_path = os.path.join(self.root, self.base_folder, file_name)
with open(file_path, 'rb') as f:
entry = pickle.load(f, encoding='latin1')
self.data.append(entry['data'])
if 'labels' in entry:
self.targets.extend(entry['labels'])
else:
self.targets.extend(entry['fine_labels'])
self.data = np.vstack(self.data).reshape(-1, 3, 32, 32)
self.data = self.data.transpose((0, 2, 3, 1)) # convert to HWC
self._load_meta()
def _load_meta(self) -> None:
path = os.path.join(self.root, self.base_folder, self.meta['filename'])
"""if not check_integrity(path, self.meta['md5']):
raise RuntimeError('Dataset metadata file not found or corrupted.' +
' You can use download=True to download it')"""
with open(path, 'rb') as infile:
data = pickle.load(infile, encoding='latin1')
self.classes = data[self.meta['key']]
self.class_to_idx = {
_class: i for i, _class in enumerate(self.classes)}
def __getitem__(self, index: int) -> Tuple[Any, Any]:
"""
Args:
index (int): Index
Returns:
tuple: (image, target) where target is index of the target class.
"""
img, target = self.data[index], self.targets[index]
# doing this so that it is consistent with all other datasets
# to return a PIL Image
img = Image.fromarray(img)
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, target
def __len__(self) -> int:
return len(self.data)
def extra_repr(self) -> str:
return "Split: {}".format("Train" if self.train is True else "Test")
""" def _check_integrity(self) -> bool:
root = self.root
for fentry in (self.train_list + self.test_list):
filename, md5 = fentry[0], fentry[1]
fpath = os.path.join(root, self.base_folder, filename)
if not check_integrity(fpath, md5):
return False
return True
def download(self) -> None:
if self._check_integrity():
print('Files already downloaded and verified')
return
download_and_extract_archive(self.url, self.root, filename=self.filename, md5=self.tgz_md5)"""
如果使用的是cifar100数据集也是一样修改的方法。处理完以后就可以加载训练了,以下是我用CPU跑的LeNet+cifar10,无障碍正常运行。
import torch as t
import torch.nn as nn
import numpy as np
from torch.autograd import Variable
from torch.nn import functional as F
import torchvision as tv
import torchvision.transforms as transforms
from torchvision.transforms import ToPILImage
show = ToPILImage()
from torch import optim
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
trainset = tv.datasets.CIFAR10(
root='G:\PYTHONtest\wan\data',
train=True,
download=False,
transform=transform,
)
trainloader = t.utils.data.DataLoader(
trainset,
batch_size=4,
shuffle=True,
num_workers=2,
)
testset = tv.datasets.CIFAR10(
'G:\PYTHONtest\wan\data',
train=False,
download=False,
transform=transform,
)
testloader = t.utils.data.DataLoader(
testset,
batch_size=4,
shuffle=False,
num_workers=2,
)
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(x.size()[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
if __name__ == '__main__':
for epoch in range(60):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
inputs, labels = Variable(inputs), Variable(labels)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' \
% (epoch + 1, i+1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
