今天read_csv处理一个csv文件出现了这个问题:期待一个分割出现了两个。初步估计可能是文件格式问题。
首先打开文件看一下
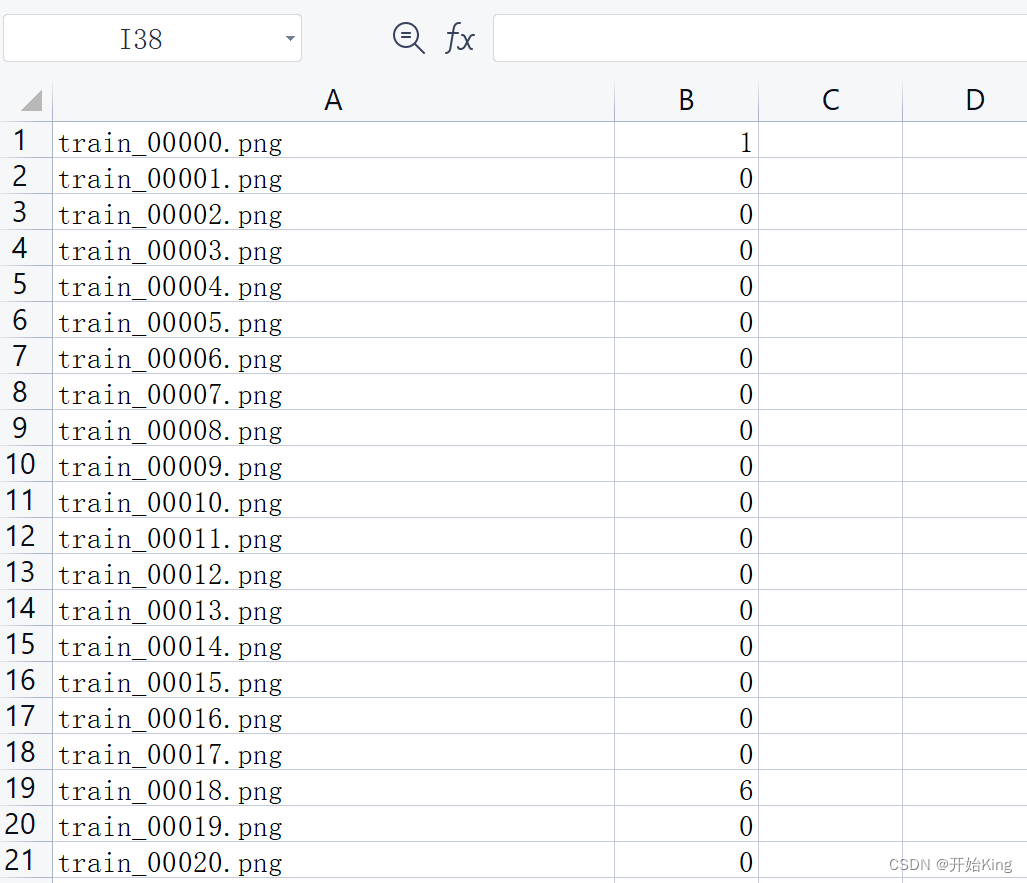
没有列名,接着往下看
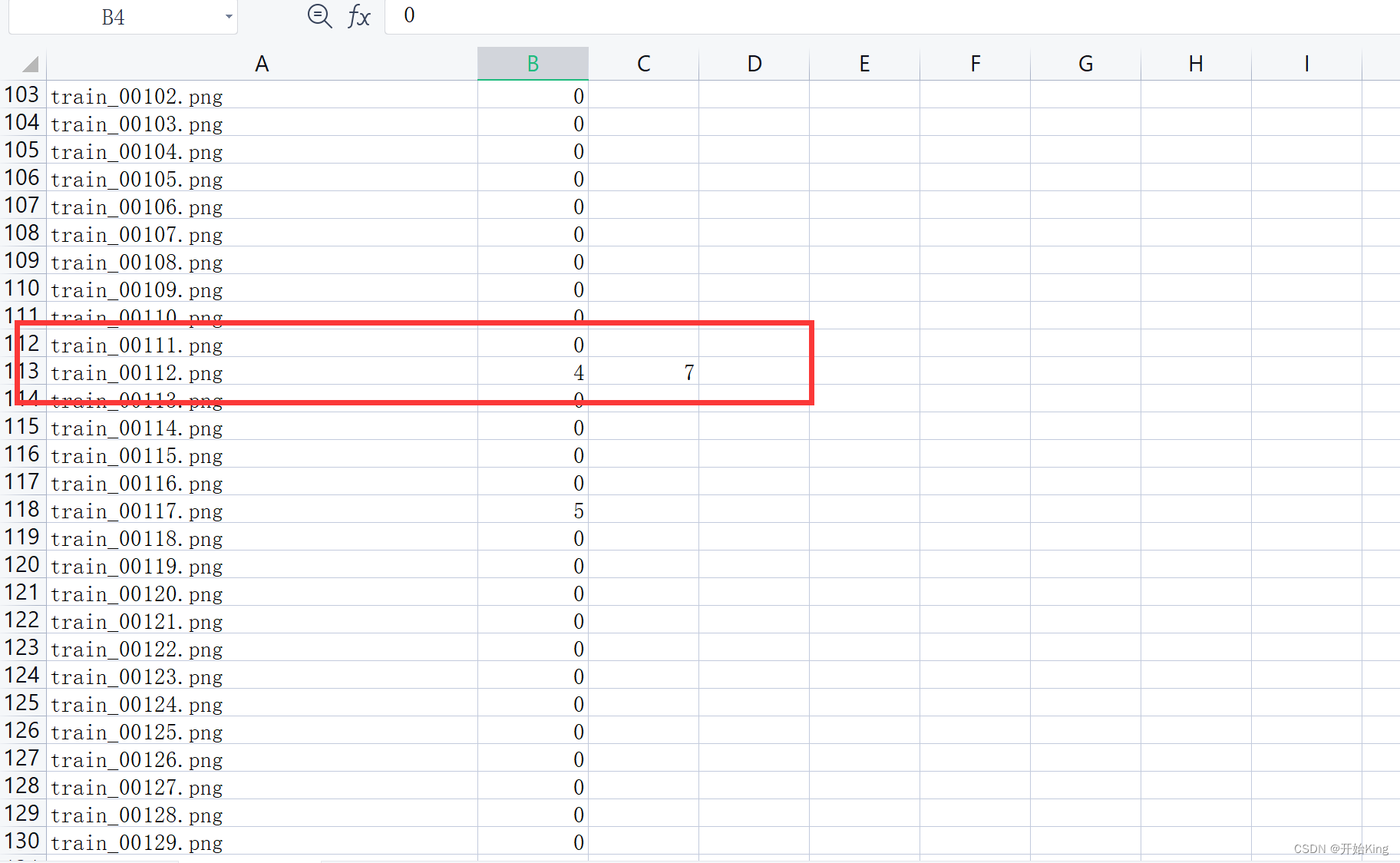
也就是有的 行有两列数据,有的有一列。用记事本打开看一下分隔符
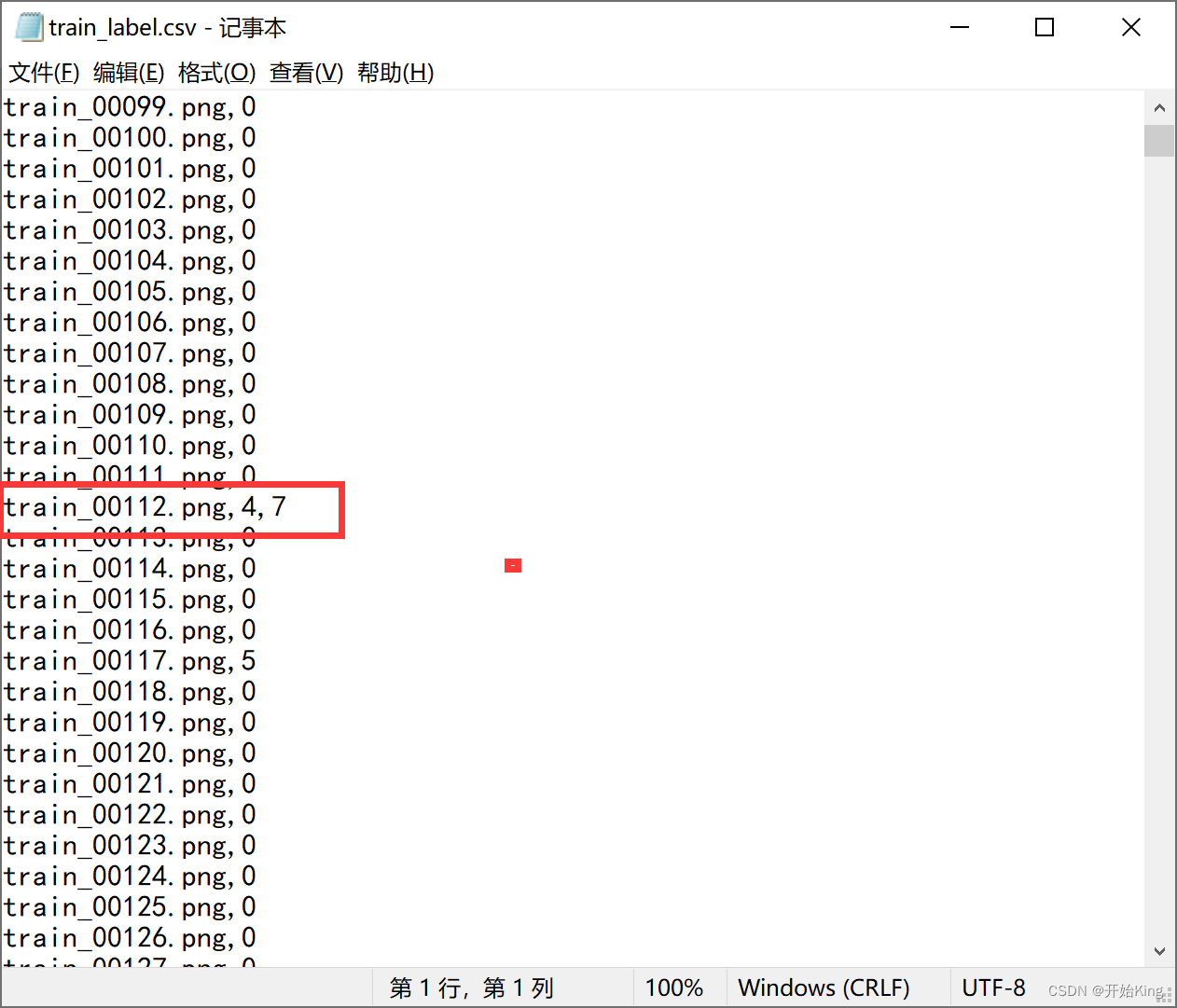
果然是这样,前面pandas读入的时候都是一个分割符两列数据,这里突然两个分隔符变成三列了。
处理方法 ,根据你不同的任务有不同的处理方法
第一种就是如果你不想要这些有多余分割符的数据,那么就删除这些行,使用参数
error_bad_lines=False
第二种 这些数据你需要保留,那么你给这个表加上列名即可,
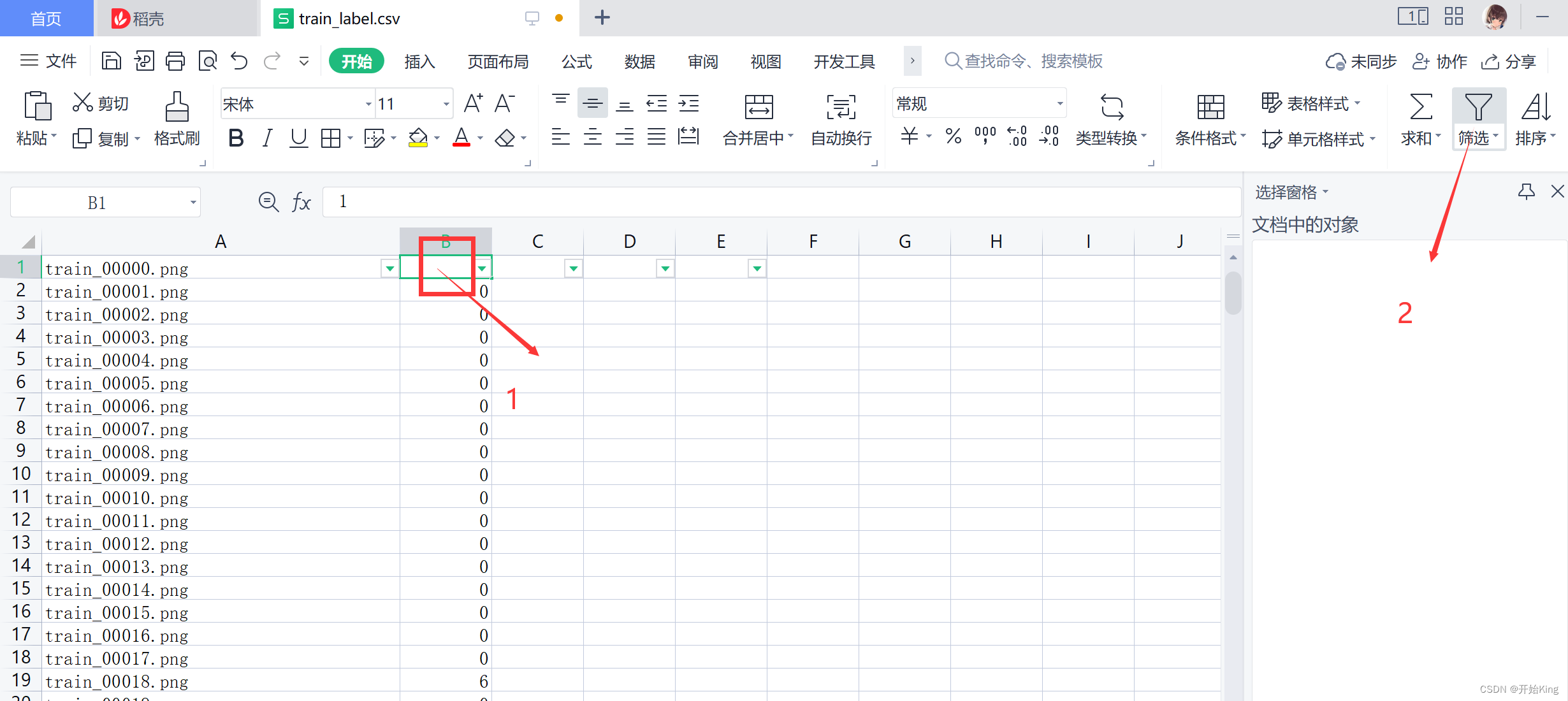 选中有数据的单元格,然后筛选,那么你就知道,哪些列是有数据的,这里是五个绿色小三角,也就是说五列数据,加上参数name列名即可
选中有数据的单元格,然后筛选,那么你就知道,哪些列是有数据的,这里是五个绿色小三角,也就是说五列数据,加上参数name列名即可
names=[1,2,3,4,5]
df=pd.read_csv(r'D:\train_label.csv',header=None,names=[1,2,3,4,5],
)
那么读入后的数据,没有的数据就会nan,有数据的就正常读入了
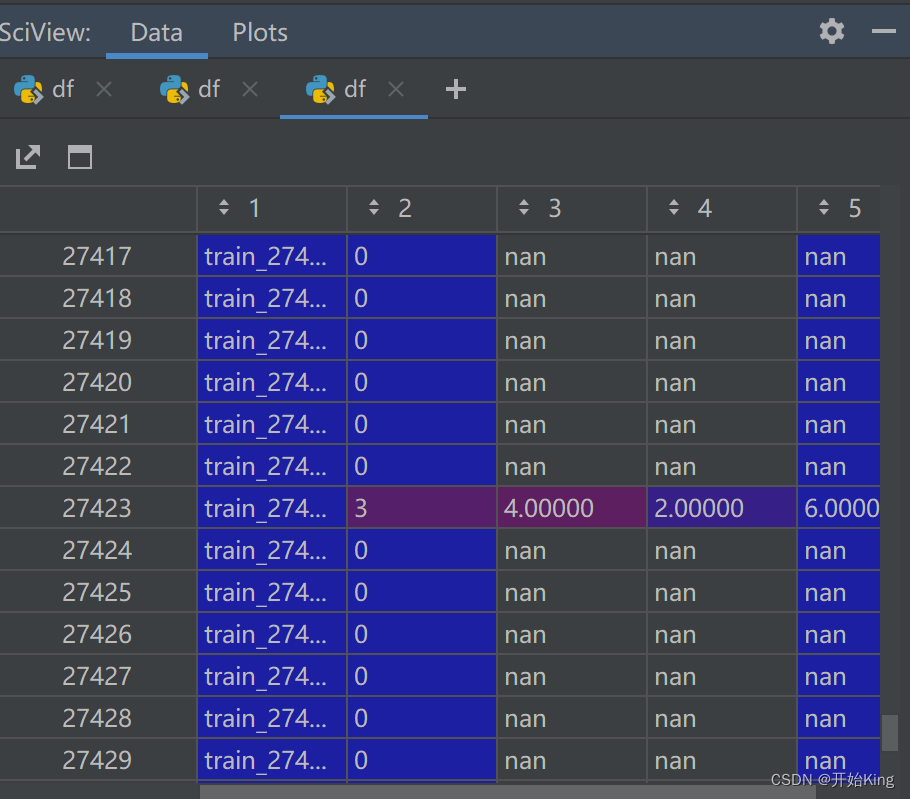
这个问题发生的原因就是没有列名,那么pandas读入时默认按照第一行的格式,前面都是两列,而后面出现了三列,四列,五列数据就会报错。而你直接读入时指定数据列就可以避免这个问题了
其实你还可以把分隔符改成不是,的其他,比如sep='\t',那么就把每行的所有的数据读入一个单元格,后期使用正则化以逗号分割