安装
安装Scrapy非常简单,只需要在终端输入pip install scrapy,然后执行命令即可,如果不行,那么一般是底层库的问题,可以使用codna install --upgrade scrapy代替之前的命令,虽然anconda的库更新要慢一些,不过一般没什么问题
创建项目
请在命令行下scrapy startproject name即可,示例如下,当我们使用命令之后,scrapy就会帮我们创建相应的项目:
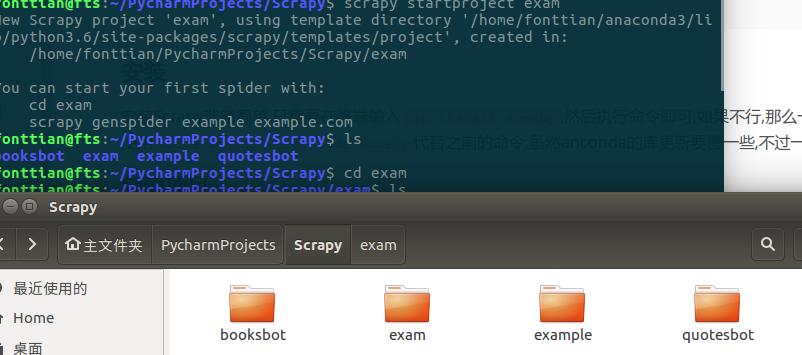
这时候我们可以tree一下,查看我们的目录结构,其中的spider文件夹,就是我们编写我们自己的脚本的地方
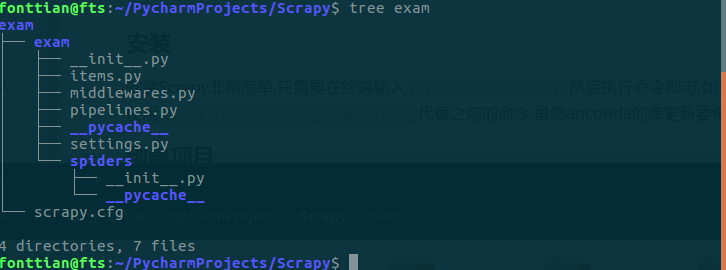
Scrapy 框架除了基本的Response,request,Downloader,等之外,其强大之处就是帮助我们实现了几乎整个流程,在最基本的情况下,我们甚至只需要编写十几行代码就可以完成一个爬虫.
比如其中的item文件中编写的是对数据封装的方法
其中的pipline.py 是用来编写数据处理的方法的,在Spider中的我们自己编写的spider执行之后,我们就可以调用item中的方法对获取的数据进行处理,
而setting则是配置文件,除此之外我们还可以使用Scrapy提供给我们的很多已经写好的方法,或者重写他们来实现一些我们需要的功能,而这一切又都是非常简单的.
我们这里再从github上Scrapy 的项目中下载一个demo,或者也可以从我的这个地址下载相应的内容,之后我的这个系列的代码都会放在这个地址
我们tree一下子这个文档,就可以查看到相应的内容,示例如下:
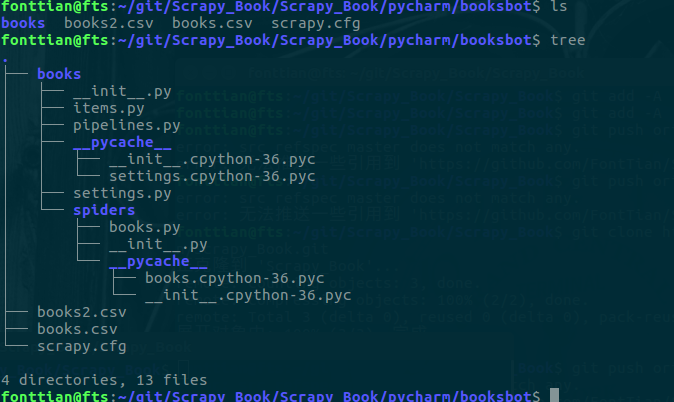
下面是其中的示例代码:
# -*- coding: utf-8 -*-
import scrapy
class BooksSpider(scrapy.Spider):
# 首先要继承原来额Spider方法
name = "books"
# 然后是name ,用于在终端中执行该脚本
# allowed_domains = ["books.toscrape.com"]
#
start_urls = [
'http://books.toscrape.com/',
]
# 我们需要一个start url
def parse(self, response):
for book_url in response.css("article.product_pod > h3 > a ::attr(href)").extract():
yield scrapy.Request(response.urljoin(book_url), callback=self.parse_book_page)
# 然后是获取相应内容,并创建解析函数
next_page = response.css("li.next > a ::attr(href)").extract_first()
if next_page:
yield scrapy.Request(response.urljoin(next_page), callback=self.parse)
# 关键之处之一,找到下一个链接
def parse_book_page(self, response):
# 解析函数,我们在Scrapy中使用,Selector与xpath选择器,css选择器与一些其他Python代码实现该功能
item = {}
product = response.css("div.product_main")
item["title"] = product.css("h1 ::text").extract_first()
item['category'] = response.xpath(
"//ul[@class='breadcrumb']/li[@class='active']/preceding-sibling::li[1]/a/text()"
).extract_first()
item['description'] = response.xpath(
"//div[@id='product_description']/following-sibling::p/text()"
).extract_first()
item['price'] = response.css('p.price_color ::text').extract_first()
yield item
至于,这份代码的详细解释,我会在之后的内容中给出,当然这份简单的demo是不能帮助我们真正的入门的,我们还需要一些其他内容,之后我会写更多的demo.
执行
scrapy crawl name -o xxxxx.csv,这时候我们可以在刚刚的tree的路径下,继续执行爬虫的命令,效果如图:
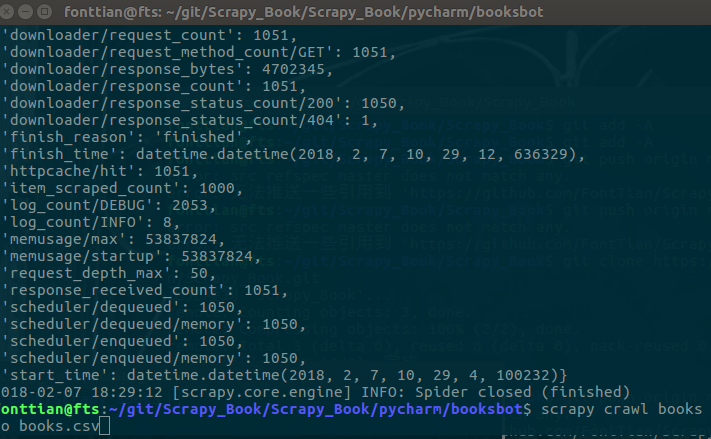
图片上面是执行完毕后的留下的日志,而下面则是我们刚刚执行的命令.
现在我们就可以看看我们获取的信息到底是不是我们的start_url了:
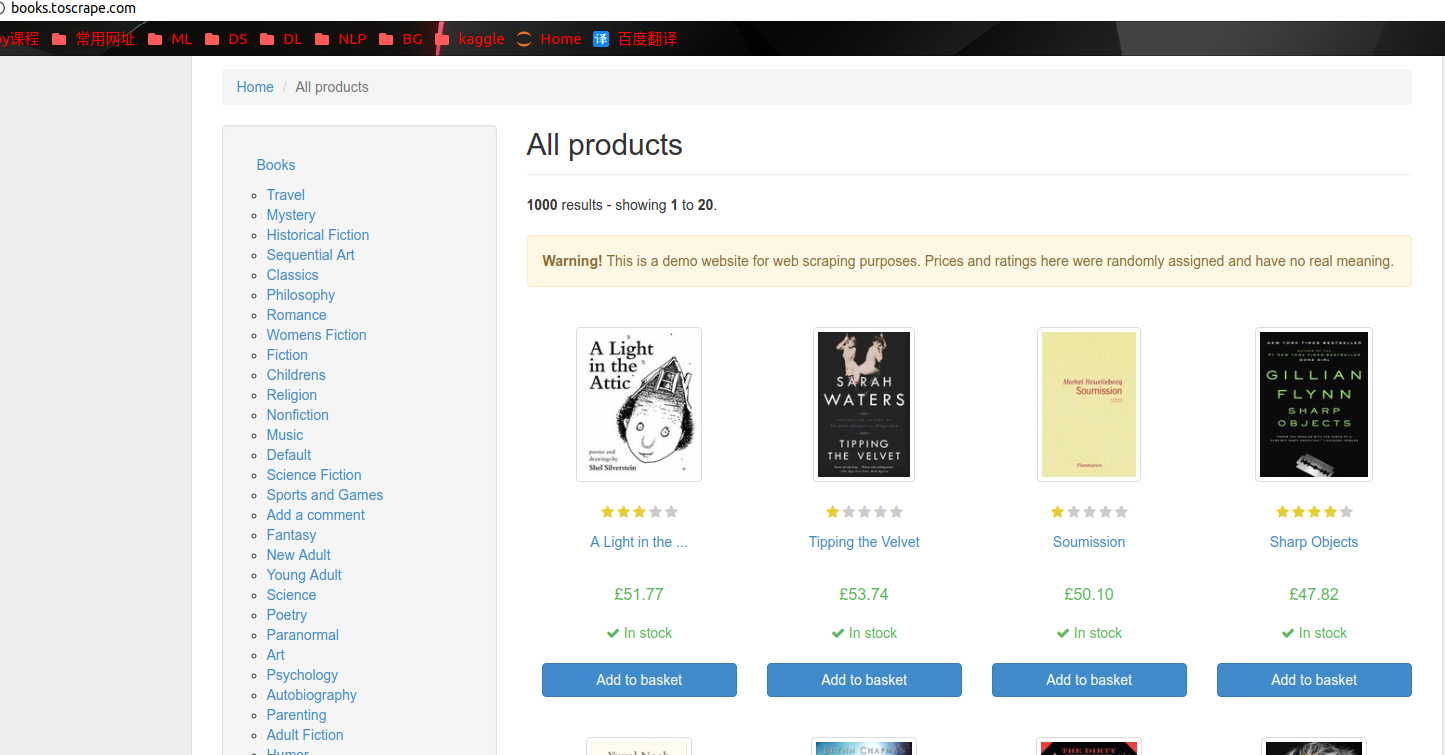
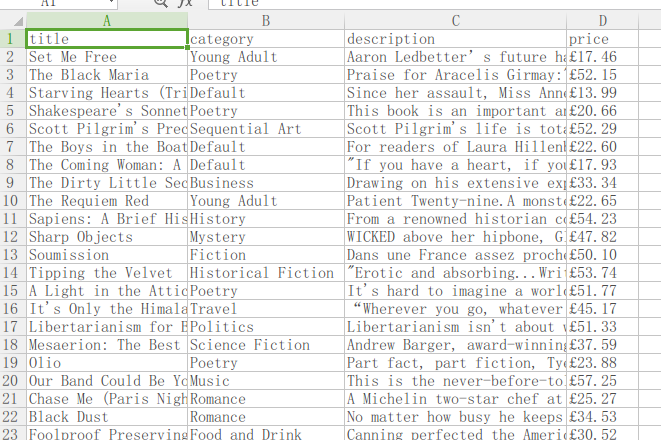
看来没什么问题