目标
生活苦累过程中,享受一下其他方面带来的乐趣,目标是网络爬虫,也了解了一下网页制作相关的内容,整理于此,便于自己日后温故以及供大家一起学习,提出自己的宝贵意见
网站
图像网站:https://www.58pic.com/
内容
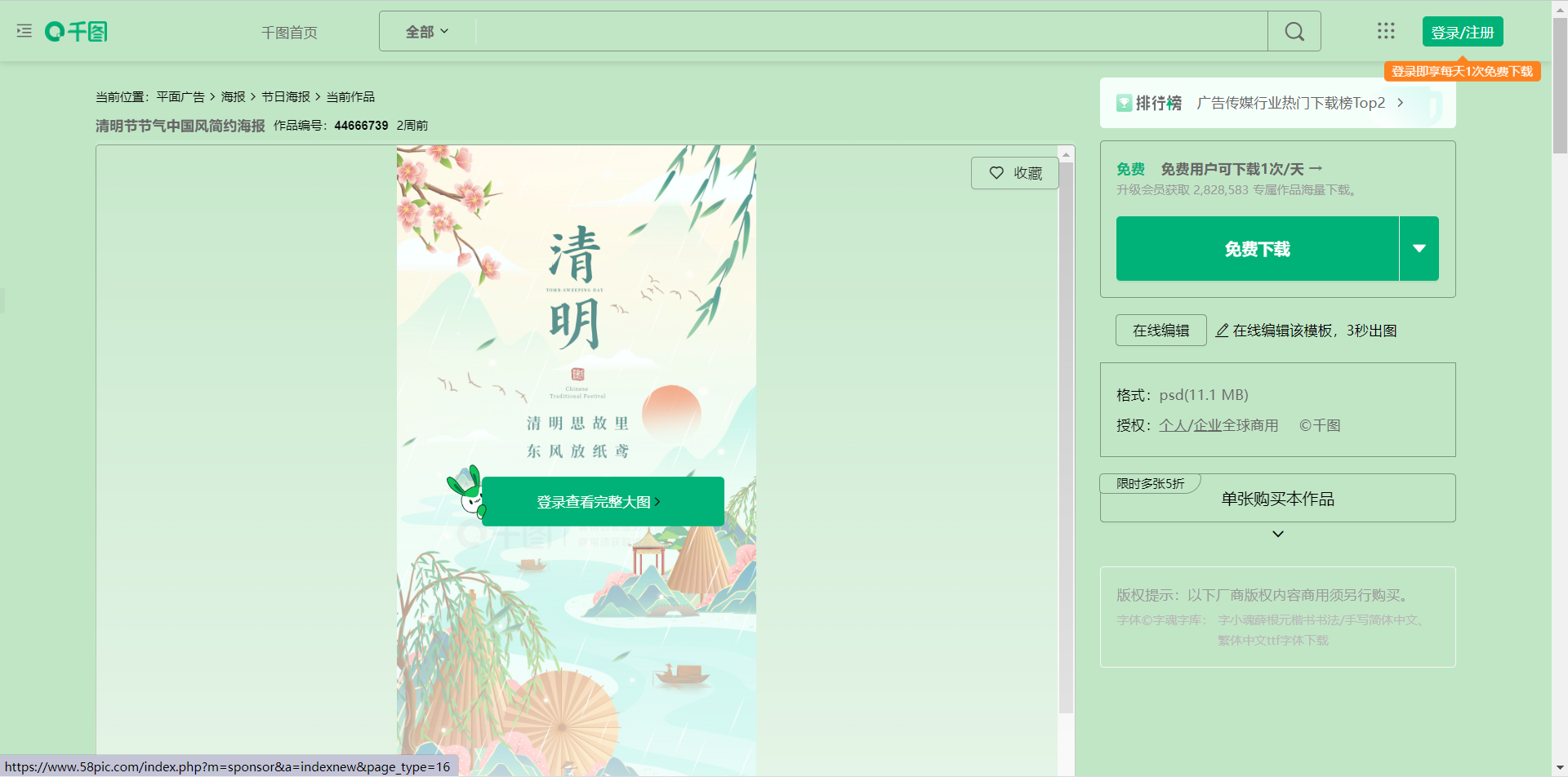
选择网站https://m.58pic.com/newpic/44666739.html
过程:
爬取这些小图片

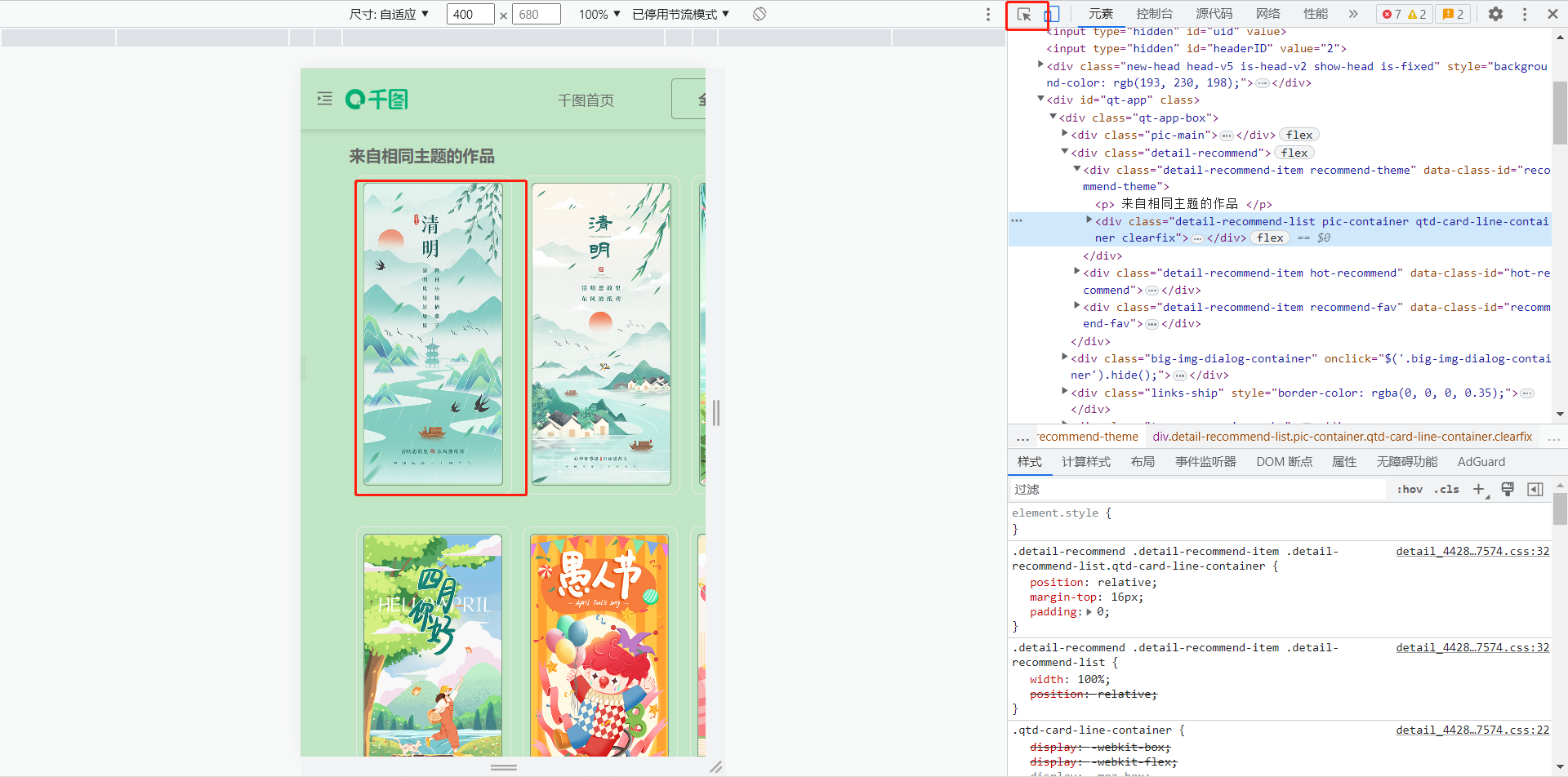
- 鼠标右键网页选择
检测 - 点击下图中的箭头手势
- 选择图像后找到对应链接 (https://preview.qiantucdn.com/auto_machine/2023031…78c1be-f9a1-45bc-88bc-e9efe1269b58.jpg!qt_kuan320)
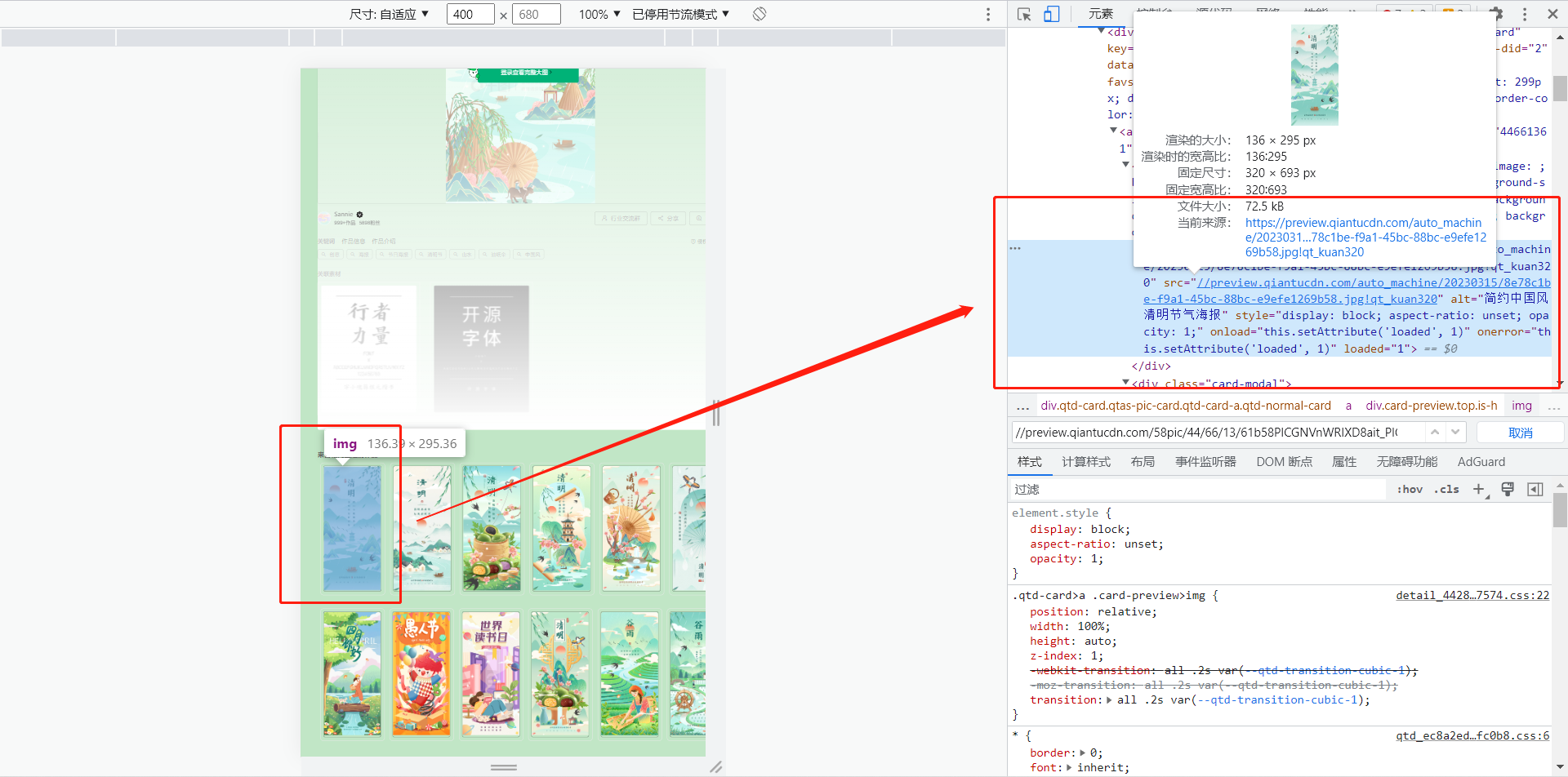
- 鼠标右键
查看网页源代码
- 可以看到相关的图像链接
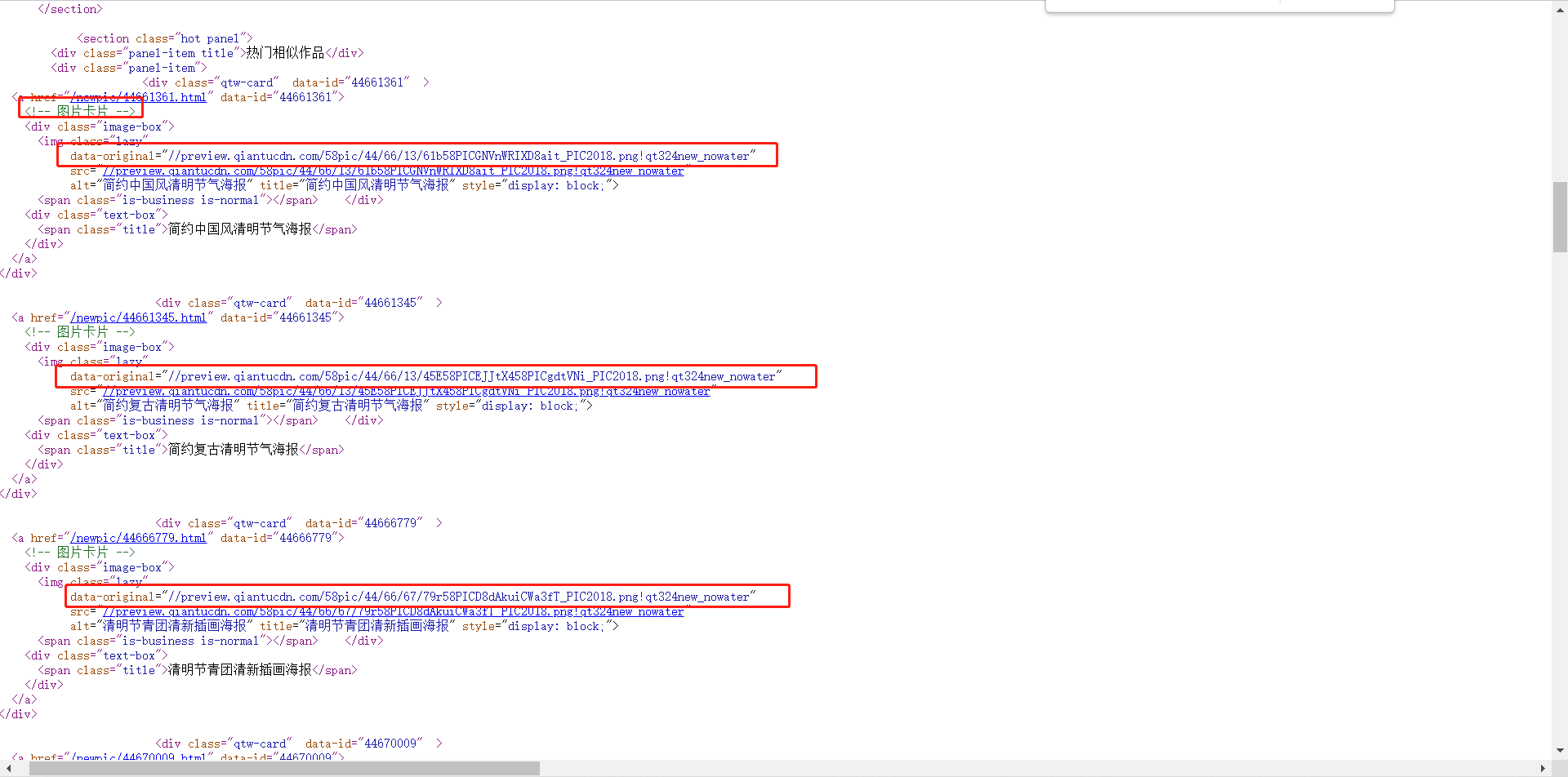
- 通过
正则化表达式将此链接进行查询,并进行图像下载即可
代码实现
import os
import time
import requests
import re
if __name__ == "__main__":
url = "https://m.58pic.com/newpic/44666739.html"
headers = {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Mobile Safari/537.36'}
'''获取网页信息'''
response = requests.get(url=url, headers=headers, timeout=300)
html = response.text
# print(ret.text)
'''解析网页'''
urls = re.findall('data-original=".*?"', html)
print(urls)
save_path = "images"
os.makedirs(save_path, exist_ok=True)
'''保存图像'''
for idx, url in enumerate(urls):
time.sleep(1) # 密集请求容易对他人服务器造成影响
img = 'http://' + url.split('=')[-1][3:-1]
response = requests.get(img, headers=headers)
# 图像名称可以根据自己的情况进行设置
with open(save_path+"/"+str(idx)+'.jpg', 'wb') as f:
f.write(response.content)