只做自己喜欢做的事情,不被社会和时代裹挟着前进,是一件很奢侈的事。

文章目录
一、 网络基础
1.局域网和广域网
1.
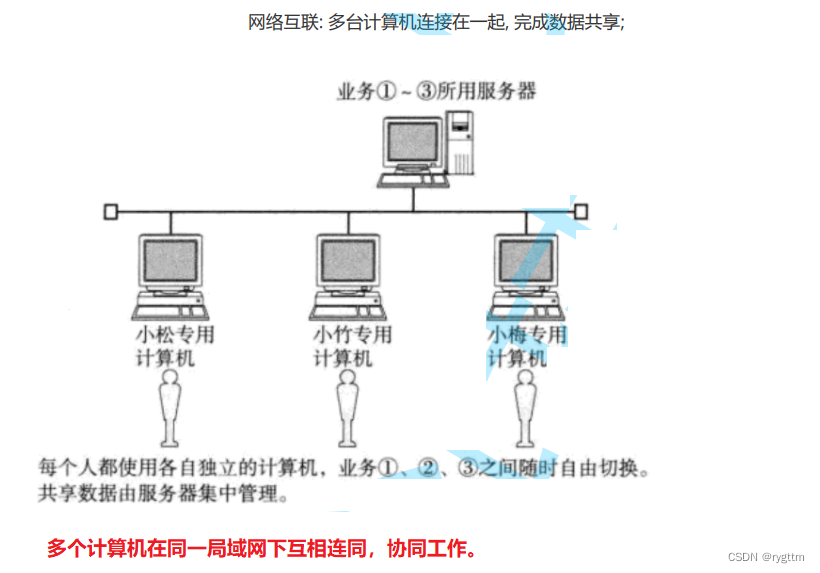
首先计算机是人类设计出来提高生产力的工具,而人类的文明绵延至今一定离不开人类之间互相的协作,既然人类需要协作以完成更为复杂的工作和难题,所以计算机作为人类的工具自然也一定需要协作,而计算机之间的协作其实说白了就是网络通信,也就是各个主机之间的数据互通。
所以我们可以得出来结论,计算机网络的出现是必然的。
而刚开始的计算机之间确确实实是各自相互独立的,他们想要进行通信那就只能人为的拷贝数据到U盘,然后把U盘插到另一个主机上,让另一个主机来进行网络通信,只要是人参与的工作他一定是效率低的,所以为了避免这种效率低下的通信方式,第一版本的通信方案搞出来了服务器,即为多个主机之间通过一台服务器进行网络通信,每个主机可以将自己的数据发送到服务器上,其他主机想要拿到数据,则可以直接从服务器里面读取数据。
2.
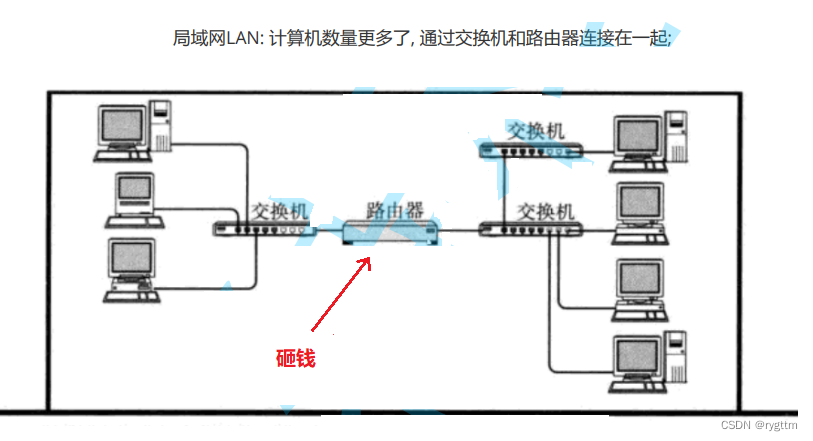
当通信的距离变长时,通过一台服务器来给多个主机提供服务显然是不够的,所以有了局域网的出现,比如广州和内蒙的两台主机或者更多更多的主机要进行通信,此时就需要交换机,集线器,路由器等设备来进行数量诸多的计算机之间的连接。
但你说连接就连接,你用嘴说呢?实际背后牵扯和涉及了很多的事情。局域网和局域网之间其实也要通信,家庭,办公室,校园等都是局域网,局域网之间一定也是要通信的,但局域网之间可能距离非常的远,这该怎么通信呢?难道拉一根光纤实现连接吗?这肯定是不现实的。
而完成连接工作的一个重要角色就是运营商,早在网络兴起也就是20世纪60-70年代的时候,政府看到了未来网络时代趋势的必然性,促使运营商在当时完成了各个地区的基站建设,光纤电缆的铺设,大型交换机器房,数据转换中心的建立,打好了网络通信的基础,而我们所做的工作仅仅是光纤入户,把网线拉到家里面,配个路由器,配个调制解调器,仅此而已。所以局域网之间的连通并没有那么简单,不是像下面的逻辑图那样搞个路由器一连就好了,他背后一定是有人替你负重前行,做了很多底层的工作,才能让你现在的网络通信变得如此简单,而这个人就是运营商,所以你可以认为网络通信的基础建设背后就是国家和运营商的推动而成功的。
所以,网络不是平白无故长出来的,所有你不知道的东西一定是有人替你负重前行的做了,而我们做的仅仅是光纤入户而已。
3.
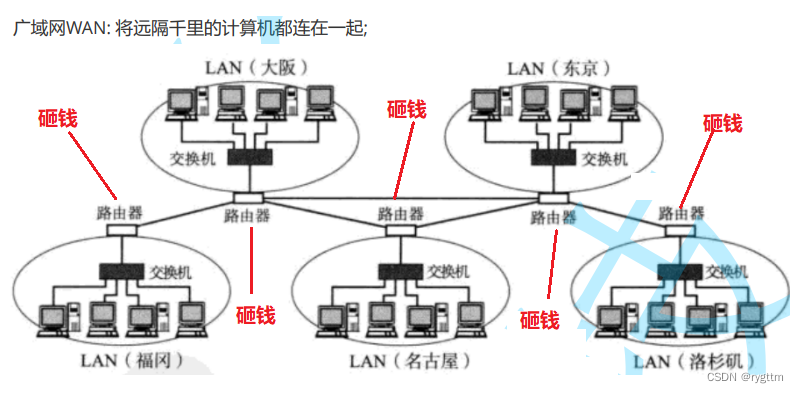
而广域网就是将远隔千里的计算机都连接到一起,让全球的人通信起来更加的方便,那这是怎么做到的呢?答案和之前的一样,还是有人替我们负重前行铺设好了通信的基础,建设基站、铺设光纤电缆等等。
广域网通常由多个局域网通过高速网络连接设备路由器互联而成的,互联网就是典型的广域网。广域网的连接设备主要包括路由器,调制解调器,网关等,局域网中的连接设备主要包括路由器,集线器,交换机等等。
(网关是一种笼统的概念,它可以是硬件,例如路由器、交换机等等,也可以是软件,例如防火墙,代理服务器等。它通常具有不同网络(ipv6和ipv4)的转换功能,以及协议(HTTP转换为FTP)之间的转换和交换数据功能。)
局域网通常使用双绞线,光纤或无线技术等来作为传输媒介,广域网使用的传输媒介种类丰富,包括光纤,卫星,微波,电话线等。
在实现局域网之间的互联之前一定少不了砸钱的环节,铺设网络通信的基础设施,一定是需要钱和人力的以及诸多的时间。
2.协议初识和网络协议分层(TCP/IP四层模型)
1.
一台计算机里面有很多的硬件,正是这些硬件之间互相配合协同工作才能让我们的计算机健康的运行,当然这里面也离不开软件对硬件的管理。
假设我们脑洞大一点,把计算机里面的各个硬件拉出来,各自放到很远很远的地方,而计算机依旧能正常运行,靠的就是协议,而协议本质就是一种约定,硬件和硬件之间也有协议,比如磁盘的HBA协议,磁盘和内存IO时也有协议,所以协议不仅仅是网络专属的,计算机体系结构里面也有协议,那计算机内部不就相当于一个小型的网络吗?各个设备通过网线连接,设备之间有协议约定,所以各个设备能够正常通信,以便于计算机为用户提供良好的服务,所以网络和计算机是不分家的,体系结构中有网络,网络中有体系结构!
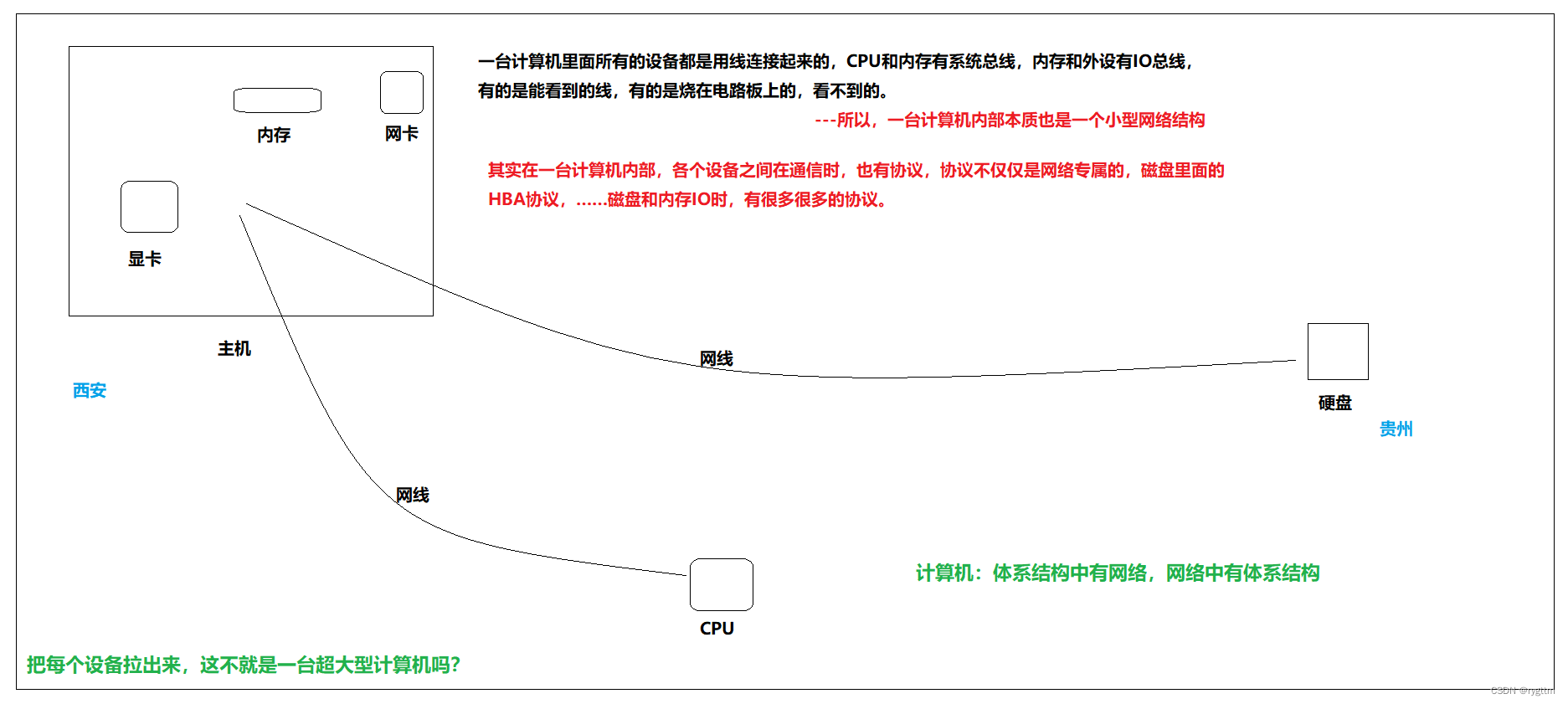
2.
上面谈论了关于计算机和网络的关系后,我们还是没谈论协议的话题。
实际在网络中,所有的网络问题本质都是传输距离变长了,如果传输距离很短,那还需要担心发送数据会丢失吗?或者对方接收不到数据,又或者对方没有接收到完整的数据,这些问题自然就不用考虑了,因为传输距离很短,中间的障碍很少,出错的概率很低。而当传输距离过长的时候,就容易导致出现问题,比如传输信号减弱从而导致数据丢失,所以一旦长距离传输的时候,就会引入新的通信问题,而为了尽可能的减少通信的成本,就需要定制协议!!!
我们提前做好约定,达成双方的共识,让通信的两台主机之间约定好协议,而协议就会降低通信的成本。
3.
但有了协议之后,网络通信就万事大吉了吗?计算机生产厂商那么多,操作系统厂商也有那么多,磁盘厂商也有很多,其他硬件设备的厂商也有很多,那如果每个厂商都有自己的协议,生产出来的各式各样的计算机还如何通信呢?只能一个厂商里面的计算机才能通信,这显然是不行的,所以此时就需要一个人站出来,定制统一的网络协议标准,这个网络协议就是TCP/IP协议,1983年TCP/IP协议正式替代NCP,成为大部分因特网共同遵守的网络协议标准。(你不遵守也OK,你就入不了网嘛,入不了网就无法通信,你的设备就自个儿玩吧。)

4.
在1977年国际标准化组织提出了OSI七层网络模型,为什么要进行分层呢?因为在网络数据传输的过程中,需要面临很多方面的问题,比如物理层,驱动层,软件层,用户层等等都有各自需要解决的网络传输问题,而分层其实就是进行解耦,每一层都是功能比较集中,高内聚的模块,用于处理该层面临的网络传输问题,层与层之间是低耦合的。
并且每一层都有自己匹配的协议,每一层协议都用于处理当前层的传输问题。
虽然是七层模型,但实际使用时,将上三层压为一层,统称为应用层,所以我们平常所说的都是TCP/IP四层或五层模型,物理层我们不考虑。
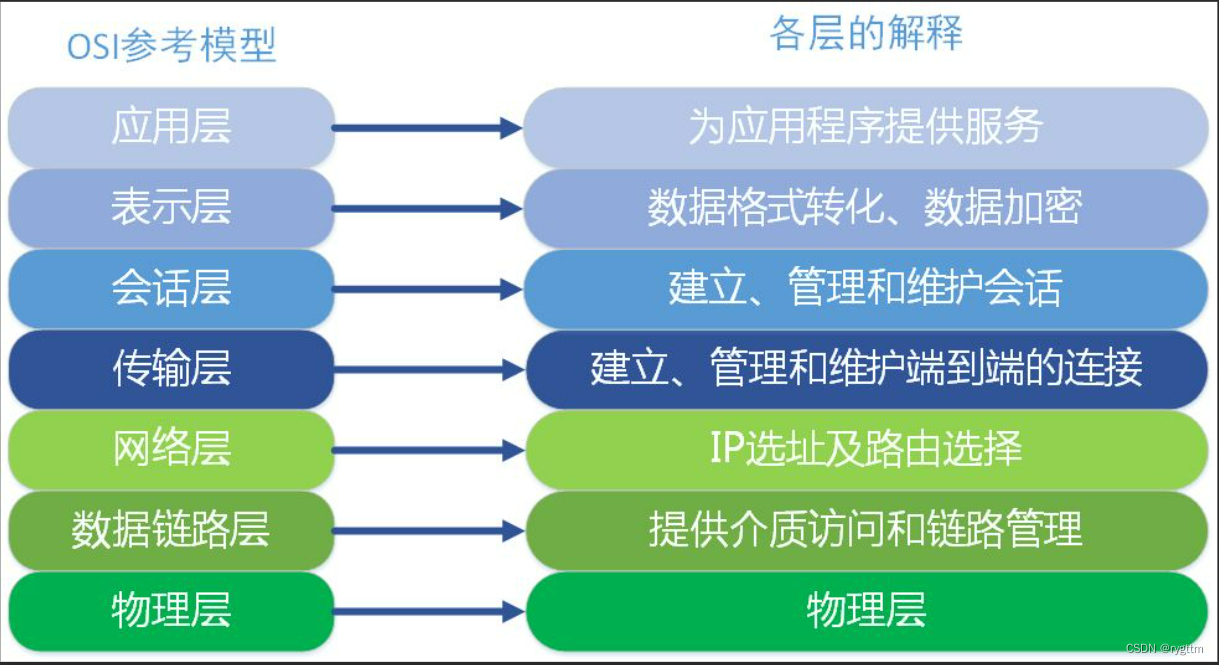
5.
我们先通过一个生活例子来预热理解一下TCP/IP四层模型,比如你现在要从北京去云南骑自行车旅游,你首先面临的问题不是怎么去云南,而是应该怎么去云南,第一站要到哪里,第二站要到哪里,最后再到达云南,所以第一个面临的问题就是自己如何到达下一站,比如要先骑到河南。那么第二个问题就是怎么到河南,是往北走呢?还是往南走呢?所以我们要有路径选择的能力。而有没有可能骑车的方向出错了呢?当然是有的,所以也要有容错和纠错的能力,最终到达云南之后,我们要开始玩,其实对应计算机就是处理数据。这就是生活例子中的四层模型,他们对应的分别是数据链路层:把数据交付给和自己相连的下一台主机。网络层:通过路由表的方式规划出两台主机之间数据传输的路由(线路)。传输层:负责两台主机之间的数据传输是可靠的,例如传输控制协议TCP,也就是提供容错纠错的能力。应用层:负责应用程序app之间的沟通,网络编程主要就是针对应用层,应用层和传输层之间有操作系统提供的系统调用接口。
TCP和IP是传输层和网络层协议的大哥,所以我们的模型叫做TCP/IP五层模型,网络层和传输层是操作系统内部实现的,所以我们写的代码要想访问下层则必须调用应用层和传输层之间的system call。

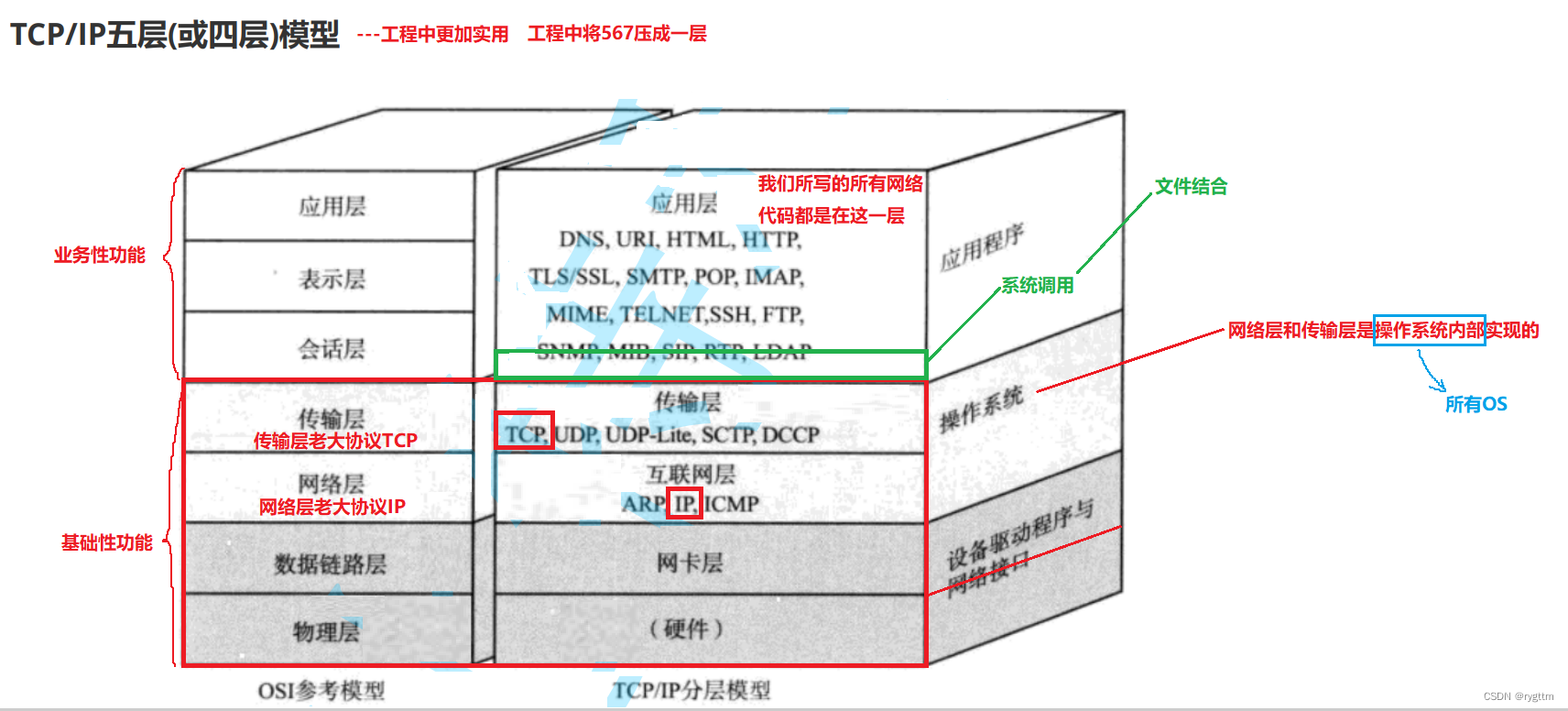
6.
物理层:负责光电信号的传递方式,早期以太网用的同轴电缆现在一般用于有线电视,而现在的以太网所使用的网线都是双绞线。物理层的能力决定了最大传输速率,传输距离,抗干扰性等等。例如集线器Hub就是工作在物理层的,集线器负责将快要衰减没的信号强度重新放大,让传输距离变得更远。比如光纤和光猫modem等都属于工作在物理层,还有路由器等等。光纤插的就是调制解调器光猫,猫主要是用于将数字信号转成模拟信号,或者将模拟信号转换成数字信号。模拟信号适用于网络发送和局域网解释,一般光纤就是用于传输模拟信号到光猫上的,光纤会插到光猫上,然后从光猫上再拉一根线连到路由器上,光猫负责将模拟信号转换成0101的数字信号,路由器真正识别的就是0101的二进制序列。网卡也是物理层的设备,负责对各种网络信号进行转换。
数据链路层:进行数据帧和二进制比特流之间的转换,进行数据查错校正,网卡设备的驱动,有以太网,令牌环网,无线LAN等标准,交换机就是工作在数据链路层
网络层:负责地址管理和路由选择,在IP协议中,网络通过IP来标识一台主机,路由器会通过路由表规划处两台主机之间数据传输的路由,路由器正是工作在网络层的。
传输层:通过某些传输协议来两台主机进行数据传输时,数据的可靠性。
应用层:网络编程主要针对于应用层,因为下面的四层大佬早就已经写好了,我们的编程主要是在应用层进行app程序之间的沟通,例如电子邮件传输,网络远程访问等。


7.
现在的网络各层设备早已突破了先前TCP/IP五层模型的限制。

3.MAC地址和IP地址(子网掩码,路由表,IP地址跨网路通信,以太网和互联网)
1.
一般数据在实际发送的时候都会多发一部分数据,这部分数据称为协议报头,由于模型的每层都有自己的协议,而数据在向下传递时必须携带上该层的协议报头,以便于数据流向到最底层的物理层之后,将数据传输给对方主机,对方主机将数据向上交付时,对方主机的每层都能看懂我的协议,所以数据在发送的时候一定是需要报头的,而具体的数据内容我们喜欢叫做报文,就相当于报纸,报头是该报刊社的协议规定,例如剧中排版,新华社报刊什么的类似协议,这些东西一般都会放在报纸的第一行而且是字体放大的那种,很醒目也就是报头。
协议报头阐述了该层协议的内容。
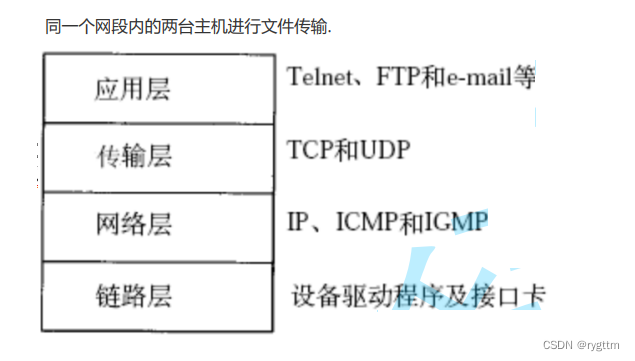
2.
在局域网中的两台主机是可以直接通信的,因为每一台主机都有自己的"名字",每一台主机都有自己的网卡,而网卡都有自己的地址,这个地址就是MAC地址。MAC地址是48位的二进制数据,也就是6字节大小的数,可以用16进制来解释该MAC地址。例如我的网卡物理地址就是16进制表示的。
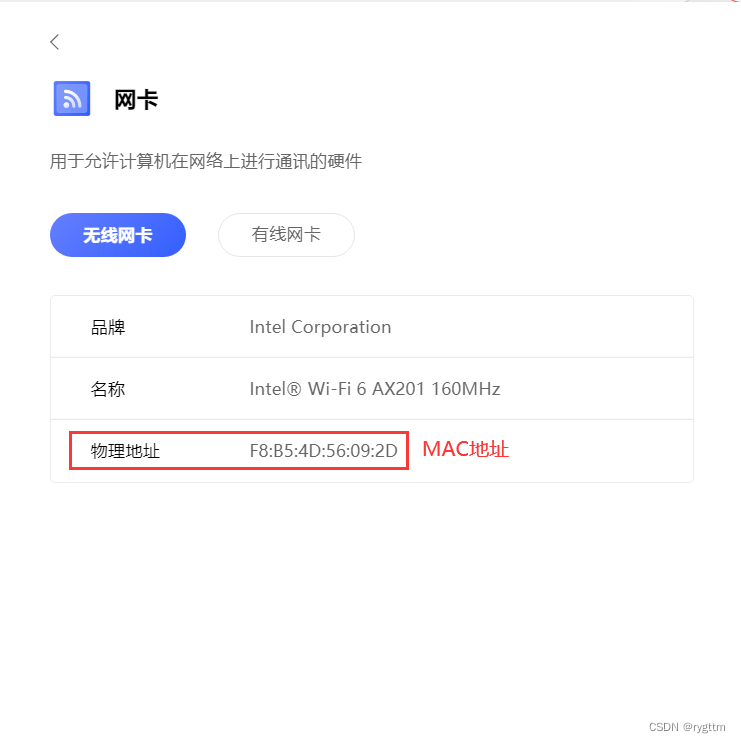
3.
MAC地址是数据链路层的地址,用于在同一网络中的主机之间进行通信。如果目标主机和发送主机在同一个网络中,那么数据包就可以直接发送到目标主机的MAC地址,所以MAC地址是在本地网络中分配的。不同的网络可能使用相同的MAC地址。
而IP地址是网络层的地址,用于在不同的网络之间进行路由和寻址,以便于不同网络之间的数据传输。
如果目标主机和发送主机不在同一个网络中,那么发送主机需要先将数据包发送到一个特定的路由器,路由器会通过路由表以及发送主机的ip地址确定出数据包的下一跳位置在哪里,路由表中记录了不同网络和主机的ip地址以及如何到达这些ip地址的信息。那么ip地址在哪里呢?ip地址实际就在数据报的报头中,报头中的第三层网络层协议中包含了该数据报的ip地址位置,而路由器的核心工作位置也是在网络层,所以路由器可以看懂网络层的IP协议,确定发送主机的数据报下一跳应该发送到哪个网络当中。
传输层以上的协议都使用IP地址来标识主机的位置,IP地址是因特网上分配给主机的标识符,他是全球唯一的,可以在全球范围内进行路由寻址。而MAC地址是在本地网络中分配的,并且不同的网络可能使用相同的MAC地址,因此在跨网络的通信场景下,无法使用MAC地址,另外由于MAC地址是48比特位的,比32位比特位的IP地址长2个字节,这是不利于在通信协议中进行使用的,所以传输层向上的协议通常都使用IP地址来标识主机的位置,因为IP地址是跨网络的,而MAC地址仅仅是本地网络分配的。常见使用IP地址标识主机位置的协议有HTTP、FTP、SMTP、SSH等,在这些协议中,app之间通过IP地址来建立连接和交换数据,路由器使用IP地址进行数据报的转发和路由,以此来实现跨网络的通信。
上面说了这么多跨网路,不同的网络等等概念,那什么是不同的网络呢?该怎么分辨呢?
IP地址由网络地址和主机地址两部分构成,如果两个主机的ip地址中的网络地址相同,那么这两个主机就是在同一网络中,否则就不在同一网络中。子网掩码是一个与IP地址配对的掩码,用于将IP地址分为上述两部分,如果两个主机的IP地址和子网掩码进行按位与之后的结果相同,则两个主机就是在同一网络中。需要注意的是不同的网络有不同的子网掩码,和IP地址配对使用。
4.
以太是古希腊神话中的宇宙空间,它常被认为是一切事物存在的基础。
以太网是使用电磁信号在以太中传播的数据链路层协议,它使用MAC地址来标识本地网络上的各个设备,每一块以太网卡在出厂时都会被assigned一个唯一的MAC地址,作为该以太网卡的永久标识。
以太网的数据传输依靠空气和电缆作为传输介质,这两种介质统称为以太。以太网线缆包括黑频线缆和同轴电缆这两种电缆。这些线缆可以将计算机和其他网络设备连接起来,如交换机和路由器,以此实现局域网内的互联。例如使用UTP(未纠错双绞线)将计算机与交换机连接,然后交换机再相互连接,形成局域网。
在局域网中,如果是需要高自由移动性和easier部署的环境中,还可以选择使用WIFI技术,无线信号通过空气(以太)作为传输媒介,将数据映射到高频电磁波上传播。例如WiFi IEEE 802.11a等标准,以及BlueTooth,ZigBee紫峰(与蓝牙类似)
有线以太通过电缆实现稳定高速的连接,无线以太可提供高自由和便捷性。
以太网是互联网的物理基础,互联网是由许多的局域网和广域网互连而成的,局域网中最常见的连接技术就是以太网。以太网定义了物理层和数据链路层的标准,通过以太电缆或以太无线信号为互联网提供高效的本地数据传输,也就是局域网内的数据传输。互联网在以太网建立好的局域网基础之上通过路由器等设备实现不同局域网之间的互联。而TCP/IP提供了网络层和传输层,以太网和TCP/IP协同工作实现了互联网。互联网使用IP地址标识网络设备,以太网使用MAC地址标识设备,两者通过ARP(Address Resolution Protocol)协议进行对应,实现互联网(因特网)的通信。
127.0.0.1是一个类IP的特殊地址,叫做本地环回地址。他是IPV4地址段保留的特殊IP地址,只能用于当前计算机本身,其他计算机无法访问此地址。所以127.0.0.1就是计算机自己,对于访问该地址的请求,数据包会从发送主机走一圈协议栈然后又返回到主机自己本身。一般用于本地测试网络代码,或本地访问apache Web服务器软件

5.
IP协议一般有ipv4和ipv6两个版本,主流使用的还是ipv4协议,但ipv4是4字节32位的整数,最多只有42亿九千万个ip地址,所以IP地址在全球分配时肯定是不够的,ipv4的地址一般喜欢用点分十进制的方式来表示,ipv4分为公网ip和内网ip,因为公网ip不够,所以引入了内网ip新技术。
而我国搞出来的ipv6协议是16字节128位的整数,最多有2^128次方个地址,号称能给地球上的每一粒沙子各自都分配一个ip地址,由于10进制表示时长度过长,所以ipv6的地址一般用16进制的方式来表示,ipv6协议我国搞的比较好,但广域网中ipv6协议比较难推行,但实际上国内许多公司的机房内部已经在使用ipv6地址了,我国内网和局域网已开始使用ipv6协议了。
而右侧打印出来的IP地址并不是真正的公网ip,他实际上是腾讯公司内部(我用的是腾讯云服务器)为了标识每一台云服务主机所搞出来的局域网ip。
Mac地址就是工作在局域网的ip地址,在win和linux下分别可以使用ipconfig和ifconfig指令打印出MAC地址。而IP地址通常在广域网中使用,但实际上ip地址既可以在局域网中使用又可以在广域网中使用,但我们暂且不谈在局域网中的使用,只谈在广域网中。

4.局域网和广域网的通信示意图(无线LAN和无线以太网)
1.
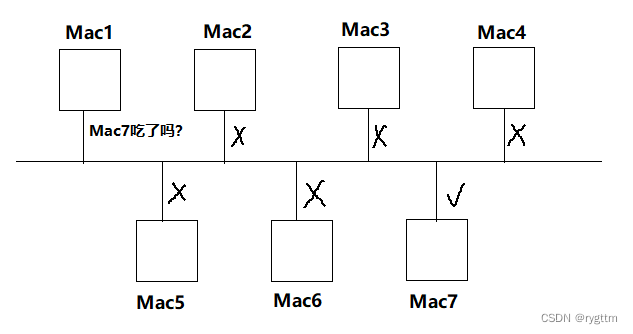
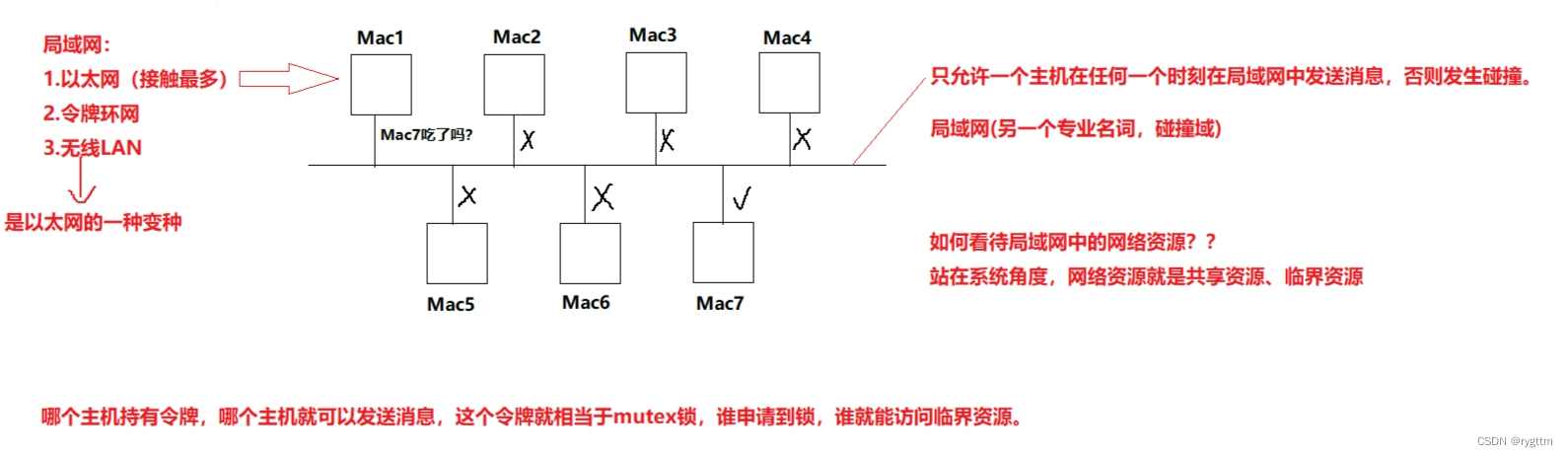
下面是简易的一个局域网内部的主机通信图,例如MAC1主机问MAC7吃了没,只有MAC7才会收到对应的消息并作出响应,而其他的主机虽然收得到消息,但他们并不会做出响应,这是为什么呢?是因为MAC1发出的数据包中的以太网协议报头信息中包含了目标主机的MAC地址,其他收到该数据报的主机都会甄别自己的MAC地址是否与协议报头的地址相同,如果相同则会进行数据包的解包分用,如果不相同则什么都不会做。
2.
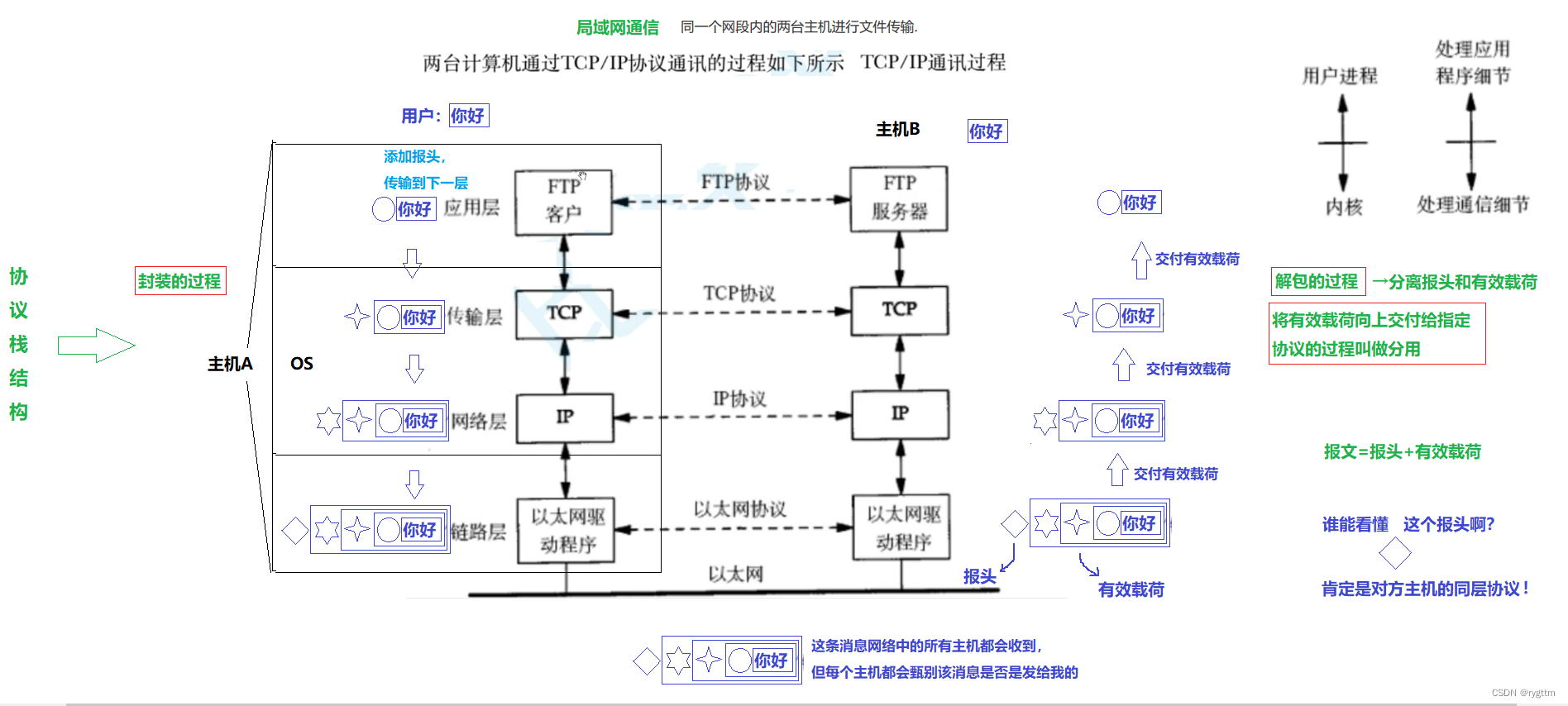
下面是TCP/IP四层模型下的局域网通信时数据包的传输流程图,首先可以看到同一个局域网内主机之间在通信时并不需要路由器来拿取发送主机的ip地址,而是直接可以通过以太网协议进行数据包的交付,但需要注意的是,数据包一定是需要经过底层的物理层的,只不过图中没有画出来。
从上层的应用层到第二层的数据链路层,每一层都有自己的协议,所以从用户发送数据到目标主机时,首先就是将数据包向下层层交付给底层协议,每一层都要封装上自己层的协议报头。在到达数据链路层之后,由于发送和目标主机在同一网段内,则可以直接通过以太网协议中的MAC地址确定好这一网段内目标主机的位置,然后再将数据包交付给目标主机的数据链路层(先交付给物理层),目标主机会进行数据包的解包分用,每一层都会进行报头和有效载荷分离,然后向上交付有效载荷,向上交付有效载荷的过程称为分用,目标主机的每一层正好对应发送主机每一层封装的协议报头,则目标主机可以读懂发送主机的层层封装协议,在经过向上层层交付有效载荷的过程后,目标主机的应用层就可以拿到对应的数据内容了。
更为形象化的例子是这样的,你和你的朋友用QQ聊太,你首先做的第一件事就是打开QQ,QQ就是应用层软件,然后你选择好聊天的朋友之后向对方发送了一条消息,你的消息不是直接发到对方的QQ软件上的,你的消息需要先进行本主机的网络协议栈的协议报头封装,然后通过本主机的数据链路层的以太网协议找到对方主机的MAC地址,将数据包交付给对方主机,对方主机又需要向上进行数据包的解包和分用,直到消息到达对方主机的QQ应用层软件,这样就完成了你和你朋友的一次通信过程。
在网络协议中,我们可以认为同层协议之间在直接通信,也可以理解为数据包在发送主机会向下交付进行协议封装,数据包在目标主机会向上交付进行协议报头和有效载荷的分离,这是两种不同的认知,但这两种认知并不冲突,而是互相补充的。
这里再提出两个小问题,这两个问题的答案隐含在上面的传输过程中,如何判断报文的报头和有效载荷的位置呢?因为报文仅仅只是一串二进制数据,同层协议进行解包分用时该怎么分辨报头和有效载荷的位置呢?分离之后,该怎么判断将自己的有效载荷向上交付给上层的哪一个协议呢?
实际上面的问题答案都在协议报头里面,所有的协议都会面临上面的两个问题,报头中一定涵盖了有效载荷的位置,向上应该交付给上层的哪个协议等信息,所以目标主机在解包分用时不会出现问题。
3.
除常见的有线以太网,以电缆作为传输介质,还有无线以太网,无线以太网就是我们上面提到过的以空气作为传输介质的以太网。而所谓的无线LAN是一种更为广义的概念,它包括使用各种无线技术构建的局域网络,其中包括了无线以太网,无线以太网是采用IEEE 802.11标准的一种无线LAN技术。
而所谓的WiFi就是IEEE 802.11标准的商标名,用于标识使用802.11标准的产品,WIFI 技术就是对无线以太网的商标名称。所以WiFi就是将无线以太网进行商业化的结果,WIFI技术 = IEEE 802.11标准 = 无线以太网(Wireless Ethernet)。
无线LAN除WIFI外,还包括红外线,BlueTooth,ZigBee等技术。
实际上无线LAN就是以太网的变种,是基于以太网的无线级别的局域网技术,当然以太网也有自己的基于IEEE 802.11标准的无线局域网技术。
下面是常见的几种局域网,以太网和无线LAN上面介绍的很清楚,唯一需要说一下的就是令牌环网,令牌环网就像mutex锁一样,发送主机在发送消息时,会连通令牌环一起交付给目标主机,只有主机持有令牌环时才能发送数据,原理很简单。
在局域网中发送消息时,任何一个时刻都只能允许一个主机在局域网中发送消息,否则消息在发送的过程中可能产生碰撞,所以局域网有另外一个专业的名词叫做碰撞域。
在同一个局域网内网络资源实际就是共享资源,网段内的每个主机都可以访问网络资源进行数据的发送和接收。
4.
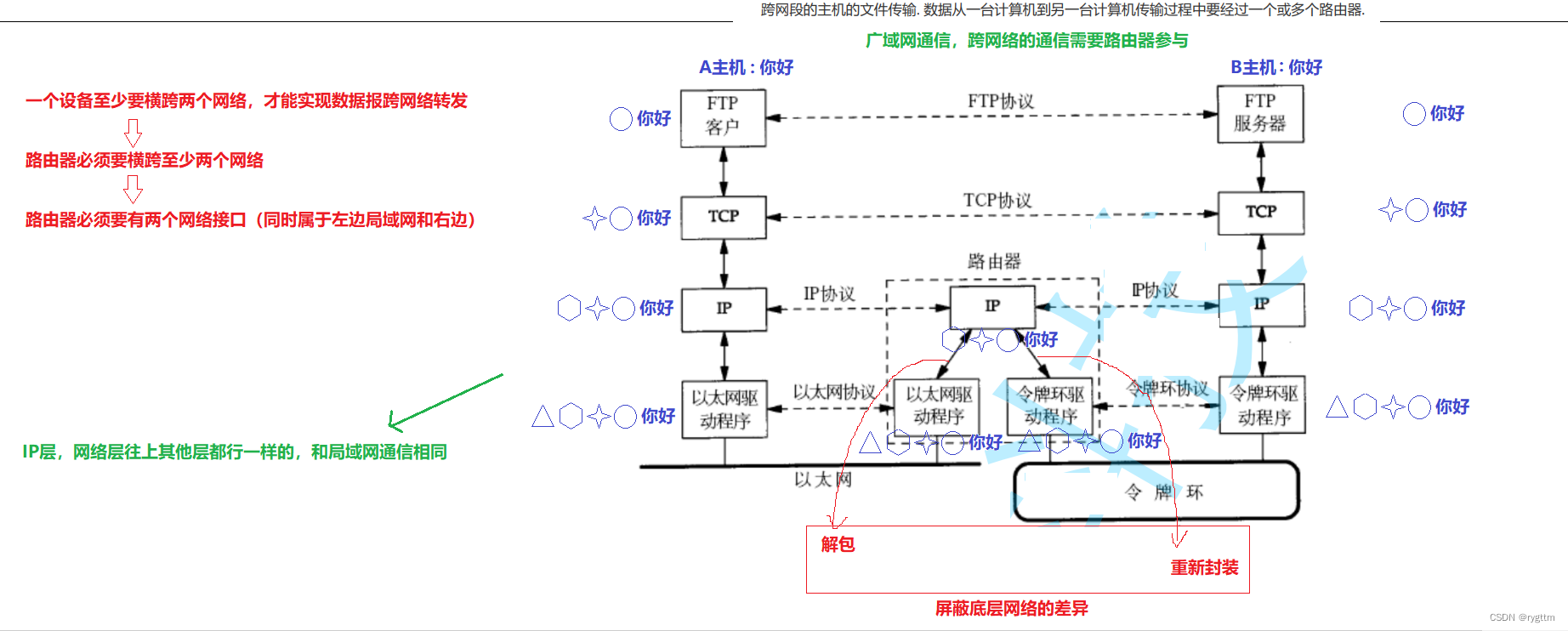
下面是需要通过路由器参与进行ip地址路由的网络通信示意图,你可以暂时将其理解为广域网通信,但实际这是不准确的,后面的文章会详细解释这个地方,或者你可以理解为局域网和局域网之间进行通信的示意图。
网络层之上的传输层和应用层与同一局域网内的通信过程相同,与其不同的是,发送主机的数据包在到达数据链路层时,无法将数据包直接交付给目标主机的以太网协议,因为发送主机和目标主机并不在同一个网段内,无法通过MAC地址确认出数据包的下一跳位置,所以数据包首先要进行以太网协议层的解包分用,将数据包交付给网络层的路由器,路由器会通过自己的路由表确定出数据包要发送的主机的ip地址,然后再向下进行封装,将数据包向下交付给指定ip地址的目标主机的数据链路层令牌环驱动程序,之后的工作还是进行数据包向上的解包分用,直到数据包传输到应用层,目标主机拿到对应的数据。
网络层的路由器进行了数据包的解包分用和重新封装,目的就是屏蔽不同局域网的底层的网络差异,为用户提供更为快速稳定健康的网络通信。例如在下面的通信过程中,发送主机和目标主机底层使用的协议分别是以太网协议和令牌环网协议,但路由器可以在网络层屏蔽掉下层不同协议之间的差异,怎么屏蔽呢?通过ip地址确定不同网段的主机位置来屏蔽。(值得注意的是,目前令牌环网已经使用的很少了,数据链路层通常使用的都是Ethernet)
像平常生活中的同一个wifi下的几个设备进行聊天时,是不会经过路由器的,仅仅通过以太网协议MAC地址就可以确定不同设备的位置。
5.数据包封装和解包分用(数据段,数据报,数据帧)
1.
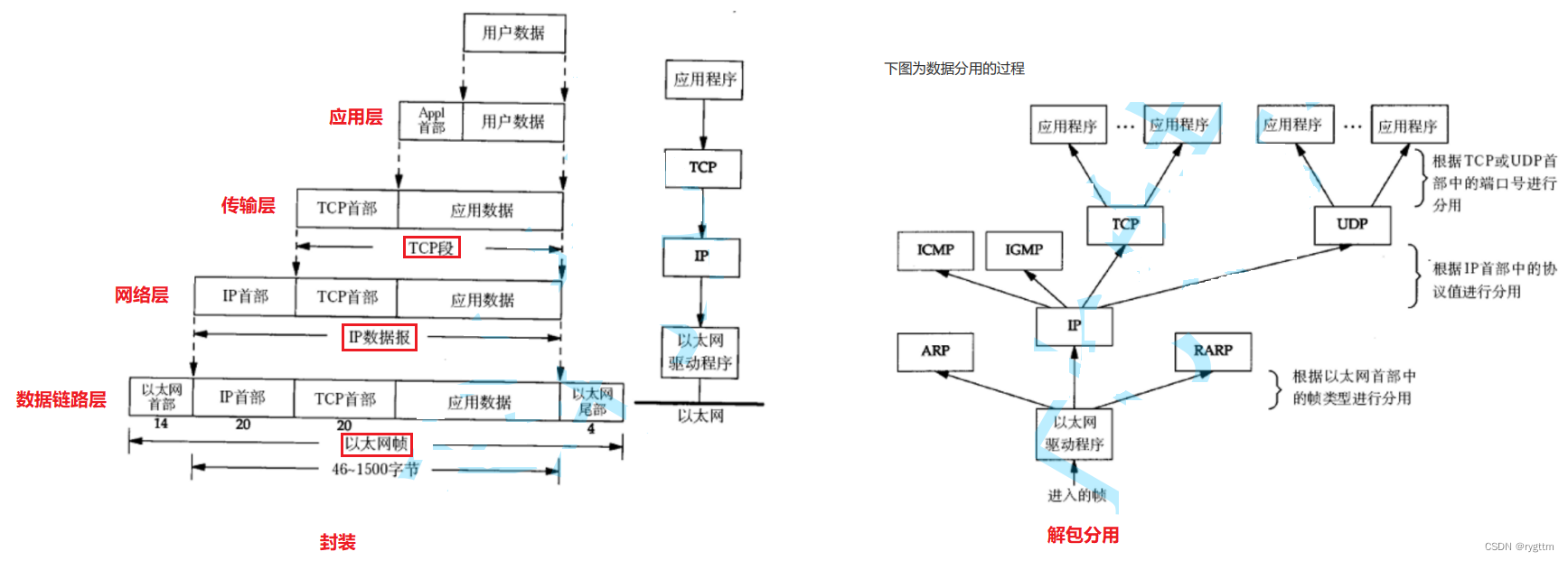
在传输层一般将数据包叫做数据段,网络层叫数据报,数据链路层叫数据帧,应用层叫请求与响应。数据在向下经过协议栈封装成帧之后会通过传输介质网线(很多种类)发送到目标主机,目标主机会剥离层层协议的报头,根据报头的信息再将有效载荷发送到上层指定的协议进行处理。

2.
下图是封装和解包分用的示意图,尤其是解包分用的示意图,很形象的体现出协议报头的作用,即数据包向上该如何交付,交付给哪个协议。
二、 UDP网络套接字编程
1.网络通信的本质(port标识的进程间通信)
1.
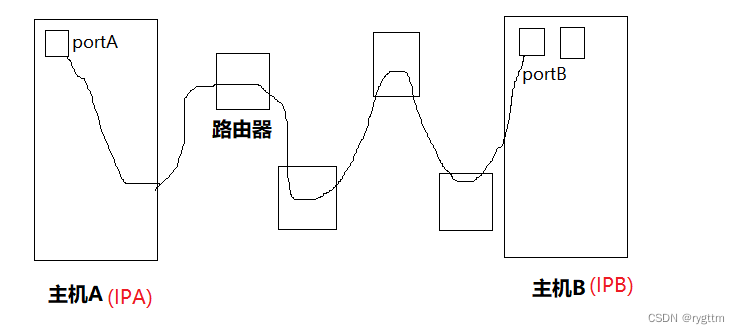
只要有目的ip地址和源IP地址就能够完成客户端和服务器的通信了吗?并不是这样的,实际通信的并不是两台主机,而是两台主机上分别的客户端进程和服务器进程,ip地址能够标识主机的全网唯一性,那用什么来标识客户端进程和服务器进程的唯一性呢?其实是用端口号port来标识的。所以只要有ip地址+port就能够确定数据包发送给哪一个主机的哪一个进程了。
端口号是传输层协议的内容,应用层可以通过system call来获取端口号,端口号是一个2字节16位的整数,最大可达到65536的大小,因为传输层和网络层是操作系统实现的,所以port可以告诉操作系统应该将数据包发送给目标主机的哪一个进程。端口号在同一个ip地址对应的主机内只能被一个进程所占用,所以不同主机内部可能会出现相同端口号,这是很正常的事情,因为port标识的进程唯一性是在一台主机内部的,不同主机内出现相同port是很正常的。
例如下面图中主机A和主机B分别通过自己的ip+port标定了各自内部的进程在全网中的唯一性,从而实现跨局域网的网路通信。
2.
所以网络通信的本质实际就是进程间通信,只不过今天的进程间通信是跨主机,跨网络的,而之前我们学习的进程间通信只是在一台主机内部各自进程之间的通信,并没有跨主机和跨网路,而在ip和port以及网络协议栈的支撑下,就能够实现跨主机跨网络的进程间通信,而这样的进程间通信实际就是网络通信。
如果要来谈进程间通信的话,我们说过进程间通信的前提是让不同的进程先看到同一份资源,这份资源是什么呢?这份资源其实就是网络,包括局域网和广域网。而通信的本质实际就是IO,我们所有的上网行为无外乎就是两种,一种是将自己的数据发送出去,一种是接收别人给我发的数据。
3.
我有一个问题,既然进程已经有pid了,为什么还要有port来标识唯一的进程呢?
理由1:系统是系统,网络是网络,我们并不希望这两个模块儿是强耦合在一起的,因为一旦强耦合一个改变时另一个也需要改动,代码的鲁棒性不好,单纯从技术角度来讲,只用pid不用port绝对是可以实现的,但我们希望系统和网络能够解耦,互不影响。
理由2:服务器进程的端口号是不能轻易改变的,一个服务器设置好端口号之后,很长一段时间内这个服务器会一直使用这个端口号,因为客户端需要每次快速准确的找到服务器进程,所以这就意味着服务器的ip和port都是不能轻易改动的,就像110,120,119的电话一样,一旦设置了能轻易改动吗?当然是不能轻易改动的!而进程的pid是每次操作系统给随机分配的,每次的pid都是随机的,所以需要有port来标识进程。
理由3:不是所有的进程都需要提供网络服务,但所有的进程都需要有pid。
4.
所以当进程绑定一个端口号之后,我们便称这个进程为网络服务进程。
那底层操作系统如何依靠这个uint16_t类型的端口号找到对应的进程结构体struct task_struct结构体呢?这里简单说一下,底层中操作系统实际是通过哈希的方案通过port来找到对应的PCB结构体的,用端口号作为哈希表的key值,哈希桶中存放对应的PCB结构体地址,也就是struct task_struct类型的指针,只要找到PCB指针,那就能找到进程相关的所有信息,例如文件描述符表struct files_struct *files,进程的信号位图,地址空间等等一系列信息。
进程不仅仅在双链表当中,他还有可能在红黑树,哈希表等数据结构当中,内核中多个数据结构会缠绕在一起,非常的复杂。
5.
一个进程可以绑定多个端口号,但一个端口号不能被多个进程绑定。
比如某个端口号代表的服务器进程功能是传数据的,另外的端口号是执行指令的,那么有可能一个服务器进程兼具了这两种功能,当客户端向这两个端口号发送数据进行请求时,有可能请求到的是同一个服务器进程,这个服务器进程同时响应两个客户端的请求,为他们同时提供服务。
但一个端口号只能对应一个进程,否则客户端向该端口号发送请求的时候,进行响应的都不知道是哪个进程了,此时就有可能出现服务器接收数据丢失或失败等问题。
在有些网络服务中,可能会出现留后门的情况,即为一个进程绑定了两个端口号,一个端口号给客户用,一个端口号给另外的某个人用,但客户并不知晓,这就是软件开后门。
6.
所以,即使我们两个套接字编程一点都还没学,但从我们现在掌握的知识也能够推断出来,在网络通信时一定是要多发一部分数据的,ip+port标定了客户端或服务器进程的唯一性,除了发送数据外,一定是要把自己的ip和port发送给对方的。因为通信他一定是双向的,既然是双向的,服务器就得知道自己接收到客户端的请求之后,自己要把客户端的请求所对应的响应返回给客户端,那服务器怎么知道发送给哪个客户端呢?当然是通过客户端的ip和port来确定发送的位置,所以在网络通信时,除数据本身外,一定还要多发一部分数据,这部分数据(ip和port)以协议的形式呈现,标识各自在全网中的唯一性。
2.传输层协议UDP/TCP
1.
TCP/UDP都是传输层协议,我们在进行网络编程时,一定是少不开访问传输层的,因为应用层在进行开发时,一定会调用传输层和应用层之间的system call API。
TCP叫做传输控制协议,他在进行网络通信时,是需要建立连接的,所以TCP是一种可靠传输,当然我们是无法感受到这种可靠性的,因为传输层在OS中,我们只停留在应用层。另外TCP是面向字节流的。
UDP叫做用户数据报协议,他在进行网络通信时,不需要建立连接,所以UDP是一种不可靠传输,同样我们还是无法感受到这种不可靠性。UDP是面向数据报的。
等到后门进行套接字编程的时候你就能体会到了,UDP在通信时,客户端发什么服务器就接受什么,通信起来非常的方便,TCP在通信时就比较繁琐,需要先建立链接,然后用文件IO(字节流)那一套来进行客户端和服务器的通信.
但需要注意的是可靠和不可靠都是中性词,并不是说不可靠是贬义词,针对不同的常见适合不同的传输层协议,例如银行转账时一定是要用TCP协议的,数据的传输必须是稳定可靠的,但某些网络广告推送就比较适合用UDP,因为稳定可靠一定是有代价的,在代码处理上一定是更为繁琐复杂的,维护和编码的成本一定是比较高的。而广告推送这样的场景对稳定可靠的要求没那么高,自然就比较适合使用UDP协议,因为维护和编码的成本低。

2.
协议谈完之后,需要面临的第一个问题就是网络字节序的问题,因为我们知道一般企业级的服务器一般都是大端字节序,我们用户级的笔记本都是小端,不同的主机使用的大小端都是不同的,这该怎么统一 一下呢?如果某个主机发送的数据是小端字节序,而接收的主机按照大端字节序来进行数据解释,这一定是会出问题的。
所以早在网络还没有大面积推广的时候,就已经规定了网络中的数据必须是大端的,如果你是小端机那就必须先将数据转为大端然后再发送到网络中,如果是大端机则直接发送数据即可。
其实这样规定也是有一定道理的,因为小端规定数据的高位在高地址处,低位在低地址处,而地址是从左向右逐渐增大的,数据的比特位是从左向右逐渐减小的,则内存中的存放和逻辑上的形式正好是反过来的,不利于看待,大端字节序更符合我们的逻辑认知。
主机在发送数据和接收数据时,都是按照从低地址到高地址的顺序来进行发送和接收。

3.
小端和大端之间的转换工作谁来做呢?linux早已为我们提供好了一批字节序的转换API了。主机和网络分别对应host和net,l和s代表long和short,主机转网络时,会统一将数据转换为大端,网络转主机时,会将数据转换成主机的字节序,可能是大端也可能是小端,这取决于主机的字节序。
上面接口只提供了short和long两种数据类型,那如果有char和double的数据类型要进行主机和网络的转换呢?一般在网络发送的时候发送的数据都是字符串,如果能显示用上面的接口那就显示用,如果类型不匹配,那就发送隐式类型转换,系统帮我们做这个工作。

3.socket编程API和sockadder结构
1.
以下是socket编程常见的几个API,现在混个眼熟就行,后面我们会进行代码的编写,到时候就知道怎么用这些API了。

2.
套接字编程中,常见的有网络套接字编程,原始套接字编程,unix域间套接字编程。
网络套接字支持多主机跨网络通信,下面讲到的都是这个套接字编程。原始套接字比较难,它可以绕过传输层直接访问网络层以及下面的层,抓包和网络监测工具就是通过原始套接字来完成的,文章不谈论原始套接字和unix域间套接字,只谈论网络套接字编程。unix域间套接字只能进行本地通信,无法进行网络通信,这个套接字只要在学习网络套接字过后,找篇unix域间套接字的相关源代码一看就能懂了。
3.
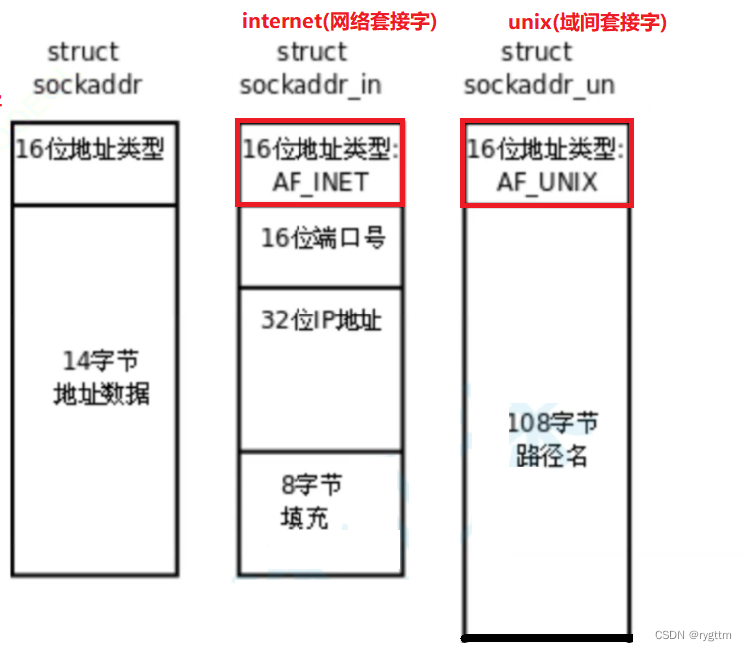
应用层的socket API是一层抽象的网络编程接口,他适用于各种网络层协议,如IPV4,IPV6,然而各种网络协议的地址格式并不相同,例如Inet socket,Unix Domain socket的网络地址并不相同。所以为了解决这样的问题,搞出来了struct sockaddr结构体,定义好的struct sockaddr_in或struct sockaddr_un结构体指针可以直接赋值给struct sockaddr类型指针,相关函数内部会提取struct sockaddr结构体的前两个字节内容,如果前两个字节内容是AF_INET宏,那就在函数内部强转回struct sockaddr_in类型的指针,如果是AF_UNIX,那就在函数内部强转回struct sockaddr_un类型的指针。
其实这样的方式不就是C++的多态吗?用基类指针接收派生类对象指针。
有人可能会有疑问,为啥不直接用void *来接收参数呢,然后在函数内部先强转为short,然后提取指针的前两个字节,然后再进行比对,最终进行inet sock或unix domain sock的地址类型的转换呢?主要是因为这套接口在使用的时候C语言还没出生呢,还没有C语言的标准呢。而当C语言诞生之后,由于历史只能向前兼容,之前的不好改,因为如果把之前的接口改为void *代价太大了,要重新进行接口的测试,功能的校验等等工作,所以由于历史的包袱只能向前兼容。
4.服务器客户端简单通信代码
1.
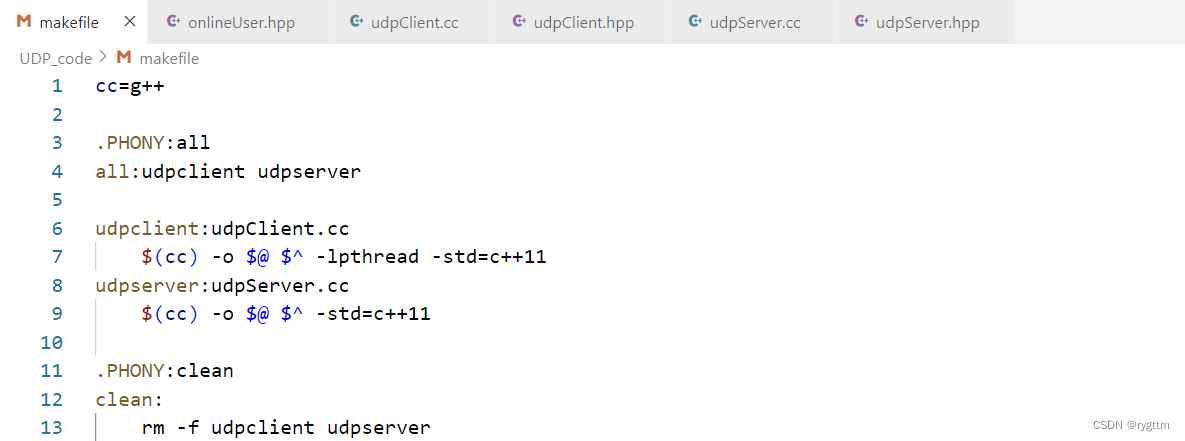
服务器和客户端要进行通信,所以要搞出两个可执行文件,一个是udpclient,一个是udpserver,makefile中可以定义变量,例如将变量cc定义为g++,$可以用于提取变量中的内容,如果想要同时生产两个可执行文件,我们可以定义一个伪目标all,然后让伪目标依赖于两个可执行文件,依赖方法为空,然后再生成对应的可执行文件。
2.
因为要做的demo测试比较多,所以贴出来的代码看起来非常多,但没有关系,我们还是按照服务器客户端简单通信,服务器翻译,服务器执行指令,服务器做消息的路由群发,linux服务器和windows客户端联动通信,等5个demo逐一讲解,所以只要按照我所讲述的模块儿去对应的看代码就好了。
A. 先来看一下服务器的调用逻辑,直接看main就可以。先说一下服务器的使用手册,在执行服务器时,需要显示的给服务器进程一个端口号,让服务器进程绑定该端口号,实际上服务器是不建议指明绑定一个ip地址的,因为这样的灵活性很差,如果该ip地址被重新分配或释放时,该服务器进程就无法使用该ip地址,服务器就挂掉了。并且如果绑定指定ip,则服务器无法利用多余的ip地址,服务器的健壮性就会降低。而最为推荐的做法就是让服务器绑定任意ip地址0.0.0.0,这样的话若某个ip地址失效那也不会影响服务器,服务器依旧可以用其他的地址来为客户端提供服务,这样能增强服务器进程的可靠性和健壮性,所以在执行服务器进程时,我们只需要在命令行增加服务器需要bind的端口号即可,无须指定服务器需要bind的ip地址。
B. 有人可能会问,那如果多个客户端用不同的ip地址同时给8080号端口发送请求,那到底是一个服务器接收多个客户端的请求呢?还是多个服务器接收多个客户端的请求呢?你不是告诉我,服务器bind了任意ip地址么,那多个服务器之间一定会存在相同的port,那就可能出现客户端给某一个ip地址和8080号端口发送的请求,不知道该用哪个服务器去响应啊,这该怎么办呢?
C. 你不用担心,在客户端和后端服务器之间实际还有一个中间角色负载均衡器或代理服务器,客户端的请求会首先发送到负载均衡器上,然后根据所采用的负载均衡策略,例如轮询,ip哈希,最小连接等,将客户端请求路由到后端合适的服务器上,让该服务器处理对应的请求。后端服务器处理请求后会将响应发送回负载均衡器,负载均衡器最后再将响应转发回相应的客户端。客户端无需知道是哪个后端服务器处理了自己的请求,只需要将请求发送到负载均衡器即可,而负载均衡器充当了客户端和服务器的中间代理这样的一个角色,实现了后端服务器处理请求的封装。
D. 路由器是工作在网络层的设备,负载均衡器是工作在应用层的设备。前者负责将数据包按照目的ip地址转发到对应的局域网中,后者负责将应用层的多个请求分发到多个后端服务器上,以实现高可用和负载分担,不要把两个设备搞混了。
E. main代码中首先进行了一个使用手册的说明,如果你命令行式输入时的形式不符合使用手册时,便会调用Usage函数打印出使用说明,即为运行服务器程序时要指明服务器绑定的端口号。接下来用智能指针unique_ptr来管理udpserver对象,创建对象时,会将命令行输入的端口号传给udpserver对象,传递前需要将字符串式的port atoi转换为整数。当智能指针对象销毁时,会同时释放掉udpserver对象的堆空间,而类udpserver中实现了两个接口,一个是服务器初始化initServer,一个是服务器运行start。这就是第一版的通信代码。
3.
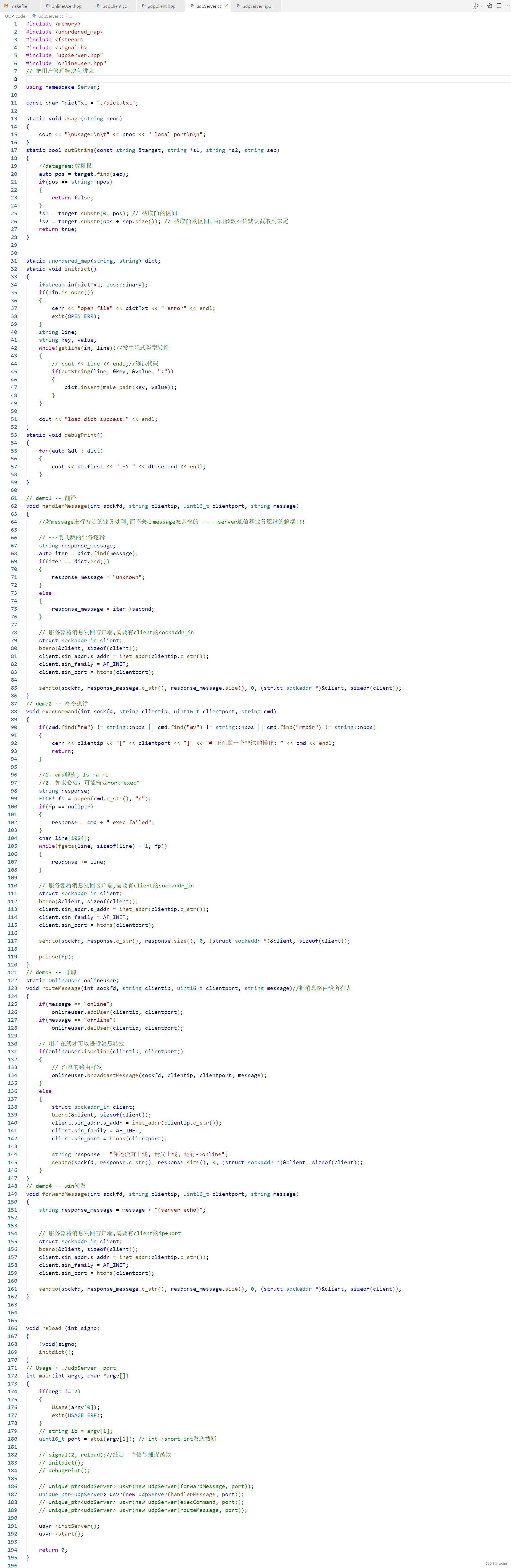
服务器这里的callback我们暂且不考虑,这个callback是下面版本通信代码所使用的。udpserver类需要什么类成员变量呢?端口号,ip地址,sockfd,就这三个,服务器需要绑定任意的ip地址,服务器创建套接字需要一个文件描述符sockfd。所以在构造函数这里,初始化ip时,默认就使用0.0.0.0任意ip地址进行绑定。
初始化服务器的第一步就是创建服务器的套接字,通过套接字文件描述符能够帮助我们实现UDP的全双工通信。调用接口为socket,即创建网络通信的一端endpoint并返回文件描述符,socket返回的文件描述符不同于一般的文件描述符,sockfd专门用于创建套接字通信。第一个参数代表你创建套接字的域,是用inet网络套接字通信呢?又或是用unix域间套接字通信呢?又或是其他的套接字来进行通信,本文只讲网络套接字编程,所以我们用的宏是AF_INET,而AF_INET又被宏定义为PF_INET即IP协议家族的一个宏,所以第一个参数除AF_INET之外还可以填PF_INET。第二个参数代表套接字提供的服务类型,SOCK_DGRAM代表传递数据报其实就是UDP协议,SOCK_STREAM代表传递字节流其实就是TCP协议,在这里我们填SOCK_DGRAM即可,第二个参数实际就可以确定套接字提供的传输类型,所以第三个参数可以不填,默认写0就可以,这就默认代表使用UDP协议进行网络通信。

创建套接字之后我们做一下简单的查错处理,接下来的工作就是bind,仅仅创建套接字是无法完成网络通信的,还需要给sockfd绑定ip和port以告诉操作系统,sockfd已经和特定的ip和port绑定好了,可以使用该sockfd进行网络通信了。
给sockfd绑定ip和端口时,需要使用网络套接字的结构地址完成绑定,即我们自己先定义好一个struct sockaddr_in local网络套接字的结构体,然后向结构体中填充好字段,最后再将填充好字段的结构体指针强转类型转换为struct sockaddr *后传递给bind API。struct sockaddr_in结构体主要填充的是三个字段,第一个字段就是sin_family,他的类型是sa_family_t,这个类型实际就是一个无符号的短整型,填充时的字段实际就是协议家族中的协议,我们填充AF_INET或PF_INET即可。其他两个字段就是无符号的短整型port,和一个包含in_addr_t类型的32位ip地址字段的结构体sin_addr,在填充时,我们直接填充sin_addr的s_addr字段即可,用返回in_addr_t类型的inet_addr接口进行填充。
绑定前需要定义一个struct sockaddr_in类型的结构体local代表服务器本地,然后调用bzero将结构体内的所有字段先都清零,使用memset也可以完成这样的工作,但有人喜欢用bzero,我们也用用这样的写法。之后在填充sin_family时只需要填充AF_INET即可,填充sin_port时需要进行主机转网络的工作,调用htons进行port的转换,然后填充到结构体中,而我们所使用的点分十进制的ip地址格式,在类型上一定是与in_addr_t类型的ip地址不兼容的,所以我们需要调用一个接口叫做inet_addr,该接口可以帮我们做两个工作,第一个是将char *类型转换为32位的in_addr_t类型,然后它还可以帮我们做32位的ip主机转网络htonl的工作,一举两得,在使用时,我们可以调用string的c_str()接口将点分十进制的_ip传给inet_addr()接口,然后将接口的返回值填充到local中。而实际上在填充ip地址这里,也可以直接使用INADDR_ANY宏来进行填充,他所表示的意思也是任意地址,和我们默认的_ip0.0.0.0意思相同。bind的第三个参数是一个输入型参数,即告诉bind函数,我们定义的local的大小,在bind函数内部会做结构体类型的解析和结构体中字段的提取,而这些工作一定是需要结构体大小的,所以socklen_t类型的addrlen其实就是local的字节大小。
点分十进制风格的ip可读性更好,但他不适用于网络通信,因为他所占的字节数过大,而32位整数的ip地址更适用于网络通信,所以在填充struct sockaddr_in结构体字段时,我们要进行string到uint32_t类型的转换,以及主机到网络字节序的转换,这两步都由inet_addr接口帮我们做了。(网络通信这里非常的负责,如果我们自己做类型的转换一定是能够做到的,但不要自己乱搞,用别人提供的接口就好了,因为除了类型转换之外,可能还有很多我们无法考虑到的网络通信问题,而像这些API都是经过严格测试之后的接口,比我们自己进行转换要安全的多,所以千万不要自己转换,很有可能转出事,用API就好。)
所以socket接口更偏向于系统方面,在系统中创建一个sockfd,而bind更偏向于网络方面,给这个sockfd绑定好网络通信需要使用的ip地址和port端口号。
最后进行简单的查错处理之后,udp服务器的初始化工作就完成了,而全程其实我们只调用了socket和bind这两个API接口,是不是很简单呢?

4.
服务器初始化之后,接下来需要完成的就是服务器启动的接口了。服务器启动后本质就是一个死循环,而当前版本的通信逻辑也比较简单,就是服务器接收客户端发来的消息并将其显示到显示器上即可,所以start接口这里没有调用回调函数_callback进行收到消息的处理,而仅仅只是做了接收客户端消息的处理工作。
之前我们就谈到过网络通信中数据在进行接收的时候,对方发送的数据不仅仅只有数据,一定是要多发一部分数据的,这部分数据就是客户端的ip和port,由于今天客户端和服务器同时在linux云服务器这一台主机上,并且可供使用的ip地址也就只有云服务器主机公网ip(我的腾讯云服务器是43.143.224.5)和本地环回127.0.0.1这两个IP地址,所以实际上服务器收到的客户端ip和目的ip是一样的,因为是在同一台主机下进行测试的。至于其他的ip地址有可能被网络中的其他主机绑定了,所以在测试时我们一般都只能使用两个ip地址,一个是云服务器的公网ip,另一个就是本地环回ip地址127.0.0.1,此地址只会在当前主机的协议栈中绕一圈,并不会进行真正的网络通信,通常都是程序员自己来测试网络通信代码时所使用的ip地址。当然除127.0.0.1这样常用的本地环回地址之外,云服务器的厂商还有自己公司内部的内网ip,就是eth0以太中的inet地址10.0.8.2地址,这个地址是腾讯公司内部标识多个服务器之间的内网ip,也就是腾讯内部局域网中的ip,这个ip当然也可以作测试用,但他的角色已经和本地环回127.0.0.1重叠了,因为这个ip只能在腾讯内网中使用,阿里,字节,百度的主机无法访问这个ip,所以一般我们只使用主机的公网ip和本地环回127.0.0.1这两个ip地址。
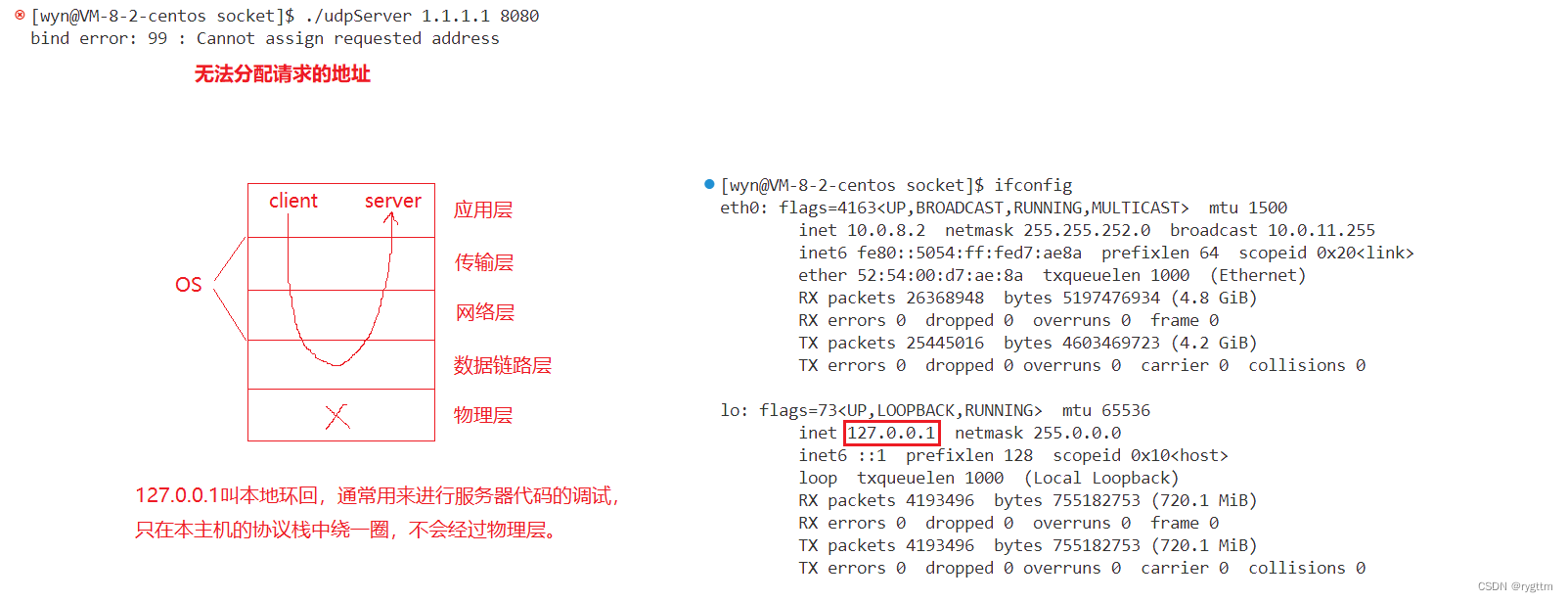
查看udp协议下的主机网络状态时,可以使用sudo netstat -unpa指令来进行查看。
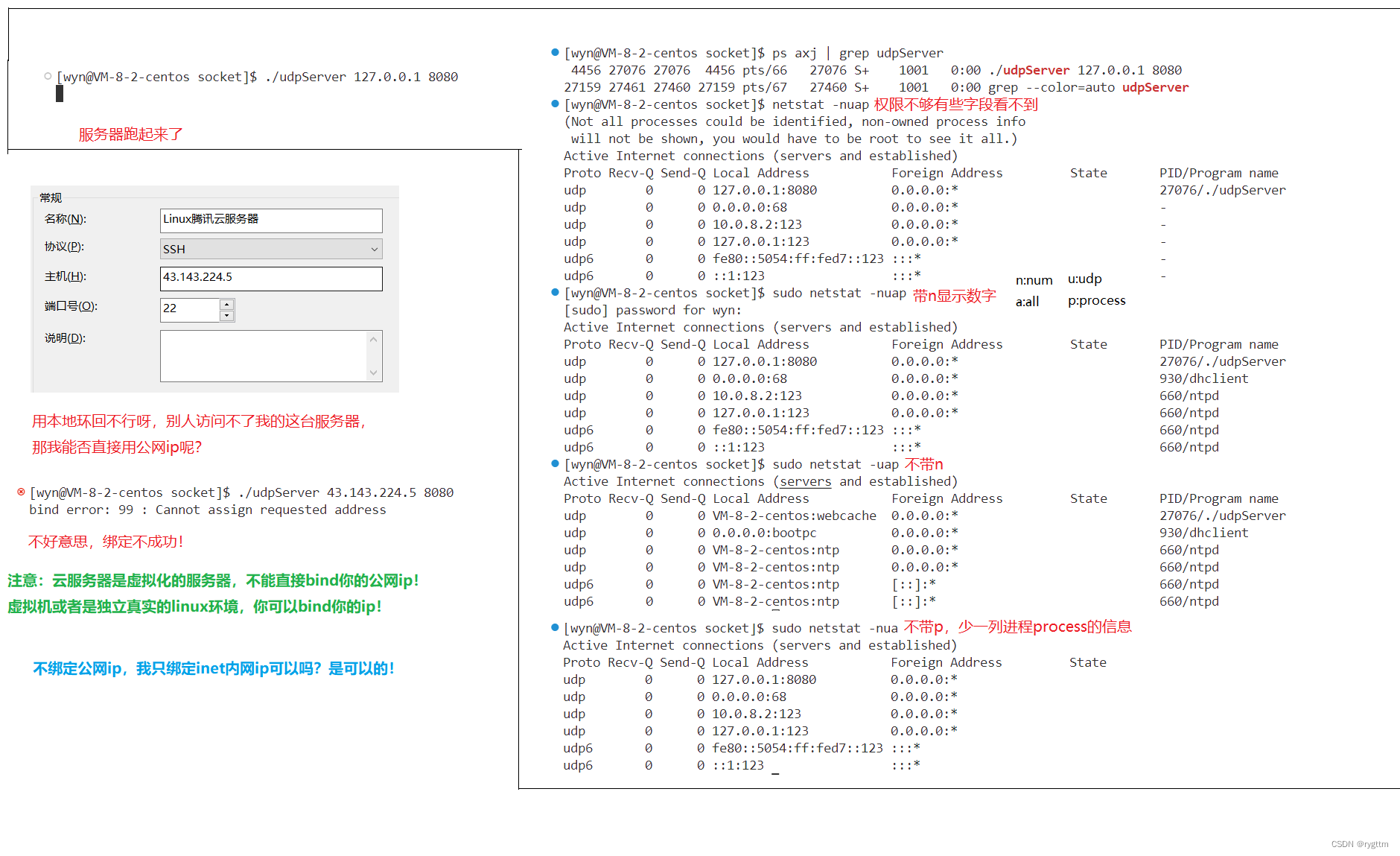
bind任意地址和8080号端口的服务器进程udpserver跑起来了,通过指令可以看到udp网络服务信息中我们的进程确实已经跑起来了。

在调用recvfrom接收客户端信息时,一定离不开网络套接字地址struct sockaddr_in,所以我们定义一个struct sockaddr_in类型的peer结构体,这个结构体作为输出型参数来得到客户端进程的ip和端口号等信息,除此之外还应定义一个buffer用于接收客户端发送的有效数据,recvfrom内部会做数据包的报头和有效载荷的分离,他会在应用层帮我们剥离最后一层的协议报头,将客户端发送的有效数据拿到buf数组里面。
recvfrom在传最后一个参数时,该参数是输入输出型参数,我们要将peer的大小的地址传进去,recvfrom调用结束后会将真实的长度写回addrlen。recvfrom与管道的读非常相似,也设置为阻塞式读取。
inet_ntoa是将peer结构体中网络字节序的ip地址转换为点分十进制的ip,与inet_addr相同的是,inet_ntoa在转换时,也完成了两步工作:类型转换+字节序转换。
传参之后peer中就有client的port和ip等信息了,我们可以在服务器这里打印出client发送的消息,至于_callback在这里先不调用,先演示一个仅仅通信的代码。
至此就完成了服务器的代码编写,实际是很简单的。


5.
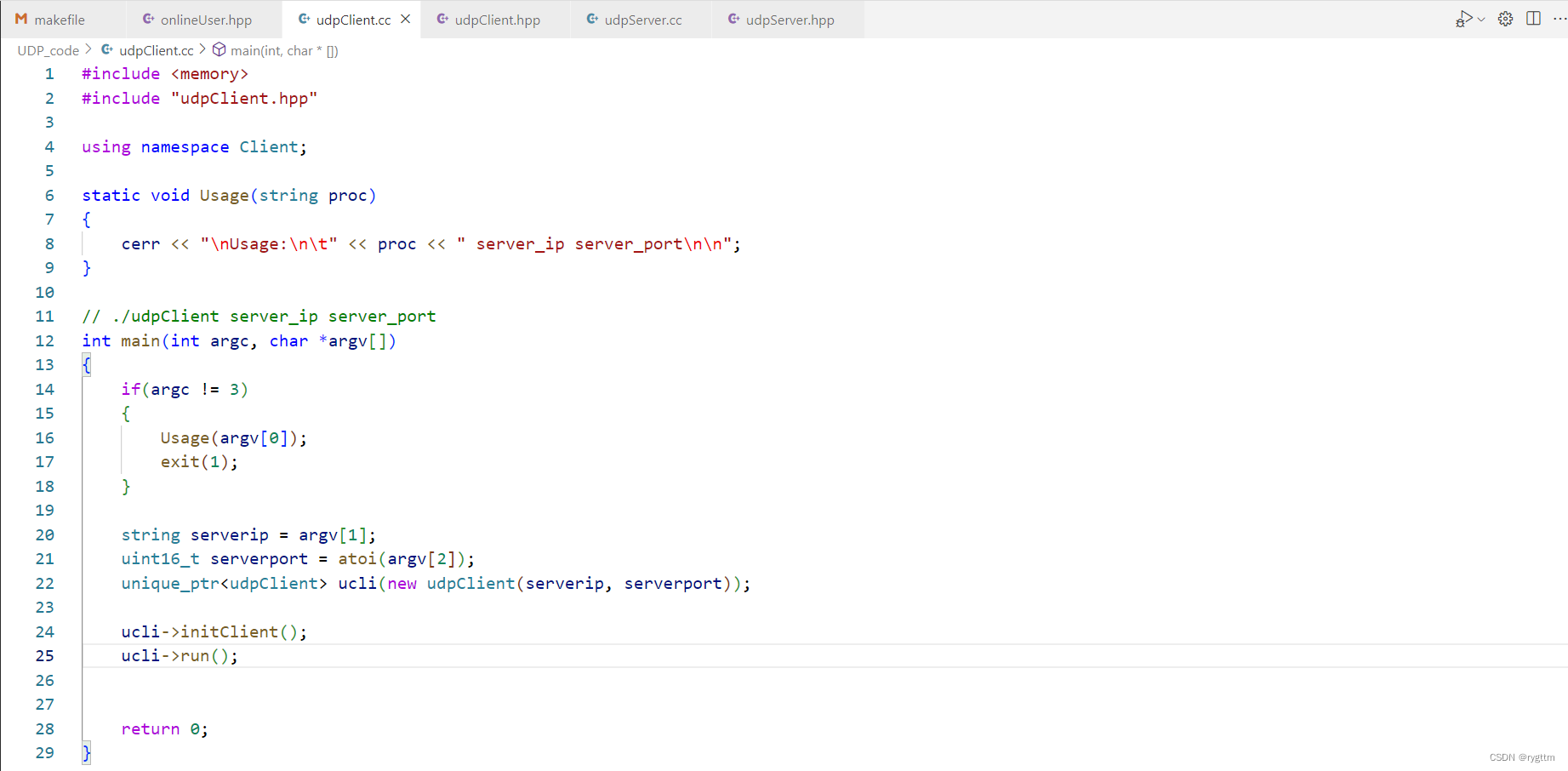
下面是udpclient.cc的代码,客户端在运行时要指明自己发送的消息是发送给哪个主机的哪个服务器进程的,所以运行时要指明服务器的ip和端口号。然后从命令行中获取一下服务器的ip和port,并将这两个参数传给udpclient的构造函数,与udpserver相同的是,同样使用智能指针来管理udpclient对象,即udpclient指针销毁时udpclient对象也会跟着销毁。
udpclient也是实现了initclient初始化客户端和run运行客户端两个接口。
6.
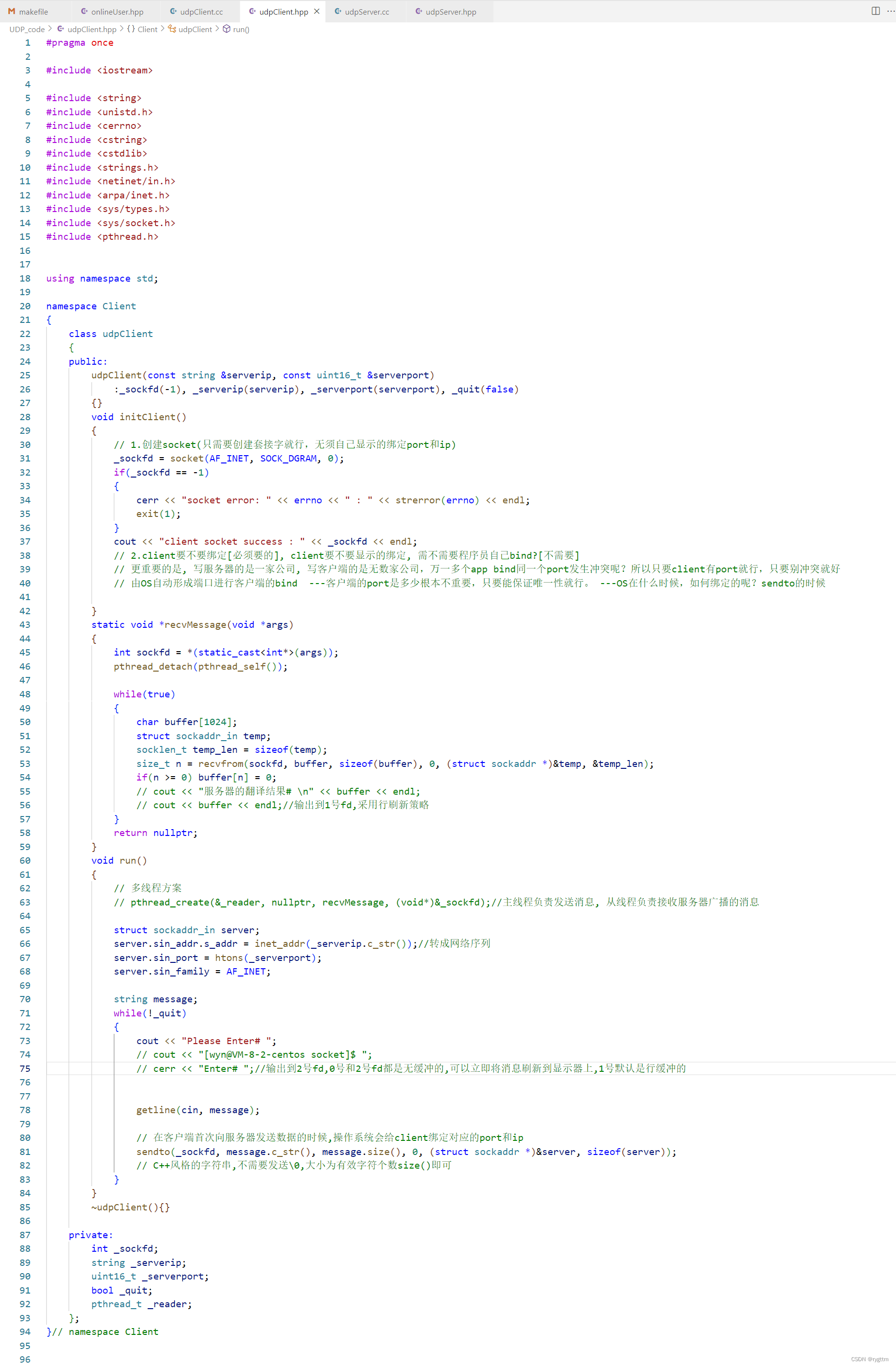
客户端的成员变量是sockfd,serverip,serverport,布尔值_quit,即今天的客户端也是一个死循环,如果我们不主动杀死进程,那么客户端也就会一直运行着。
初始化客户端的代码要做的第一件事和服务器相同,也是要调用socket接口来创建套接字,调用的代码和服务器一样,我也就不说了。
第二件事就是绑定,客户端需不需要绑定呢?首先客户端一定是需要绑定的,因为他需要标识自己进程在全网中的唯一性,但客户端需不需要程序员自己显示的绑定一个ip和端口号呢?答案是不需要的。因为客户端的作用就是向服务器发起请求,客户端只需要知道服务器的ip和端口号就行了,他自己是不在意自己绑定的ip和端口号的,实际上在调用sendto接口向服务器发起请求时,操作系统会自动给客户端的sockfd绑定ip和端口号,客户端的ip和端口号是操作系统动态分配的。
如果客户端显示的绑定一个ip和端口号,同样客户端程序的健壮性会大大降低,一旦其他客户端一不小心也绑定了相同的ip或相同的端口号,那其他客户端就会崩掉,又或者客户端绑定的ip被释放掉或重新分配了,那么客户端就又无法继续运行了,又会崩掉了。所以客户端和服务器是比较相同的,我们不建议服务器绑定指明的ip地址,而是绑定任意ip,这样服务器的健壮性更好,而客户端也同样如此,客户端不需要自己绑定指明的ip地址和端口号,因为这样的绑定会让客户端进程的鲁棒性很差,客户端不需要自己绑定,操作系统会完成客户端绑定的这个工作,程序员无须担心。
所以客户端的初始化代码很简单,只需要调用socket()接口完成套接字的初始化就可以了,sockfd绑定的工作操作系统会动态分配。
7.
在客户端调用sendto向服务器发送消息时,客户端除了消息数据本身需要发送外,还需要发送自己的ip和port,以便于服务器接收消息并处理之后,能够通过客户端自己的ip和port找到客户端进程的位置,从而将处理之后的消息返回给客户端。
第一个参数就是客户端将操作系统给自己绑定好ip和port之后的sockfd发送给服务器,第二和第三个参数代表发送消息的内容和字节大小,第四个参数flags在UDP这里一般设置为0,表示使用默认行为,flags主要控制数据包的一些附加属性,可以修改sendto的默认行为,如果有特殊需求则可以设置对应的flags,今天我们就正常的使用就好了,直接设置为0.
客户端需要自己定义一个struct sockaddr_in 类型的结构体server,并填充server的各个字段,然后把server的地址进行强制类型转换后传给dest_addr参数,再把server的字节大小传给addrlen,sendto的最后一个参数是纯输入型参数,而recvfrom的最后一个参数是输入输出型参数,这里两个接口有些许不同。
还有一个非常重要的知识点就是关于sockfd套接字文件描述符,对sockfd进行读写操作时,实际操作的是文件描述符指向的套接字文件控制块(socket file control block),该文件控制块内部有发送和接收的缓冲区,在进行消息的读取和发送时离不开套接字文件控制块的帮助,我们称这样的网络通信为全双工通信。
而普通的文件描述符fd所指向的文件控制块只管理文件的内容,并没有发送和接收缓冲区,因为普通的文件是被动存储数据的,不需要发送和接收缓冲区。

多提一句,C++string风格的字符串不包含\0,所以在sendto时,直接发送字符串的大小即可。而C语言中字符串在发送时,一般都发送strlen(str) + 1的大小,以便将\0也发送过去,但在C++这里我们直接发送string.size()即可。
8.
下面是实验现象,服务器打印出来了客户端的ip和端口号,以及发送的消息内容。因为今天的客户端和服务器都是在云服务器这一台主机上运行的,所以服务器和客户端的ip地址是相同的,都为本地环回ip127.0.0.1,如果使用云服务器的公网ip,也可以进行测验,但云服务器公网ip的端口号默认都是被关闭的,如果你直接用公网ip去访问某些端口,厂商为了保证云服务器的安全,云服务器的防火墙会自动拦截你对公网ip的某个主机的端口发送的数据包,如果想用公网ip测试某些端口,则需要手动在服务器的控制台中的防火墙配置某些你平常测试想用的端口号,比如8080号,这样你就可以使用公网IP进行端口号的测试了。
云服务器的0-1023号端口云服务器不允许bind,这些端口号在云服务器内部已经被bind好了,从1024到65536号的端口你可以随便bind,我们平常测试代码一般喜欢使用8080号端口。

5.翻译版本和bash指令版本
1.
难道服务器只要接收到客户端的消息然后打印到显示器上就可以了吗?当然不是,服务器读取信息仅仅是完成了网络通信罢了,信息读取之后服务器一定是要进行处理的,所以下面的demo就是服务器翻译单词和执行bash指令的两个版本的代码。
2.
下面是翻译版本中udpclient.cc的主函数,多支持了两个函数,一个是initdict,一个是reload,initdict()接口会将文件dict.txt中的内容先进行分割,然后将分割后的key和value构造成键值对insert到unordered_map中,至此就完成了字典的加载过程,然后将翻译函数传递给udpserver服务器类中,服务器中会用包装器类型的对象_callback接收translateMessage函数指针,在接收到客户端消息之后,会调用_callback,给_callback传sockfd,clientip,clientport,以及获取到的message等参数,此时函数translateMessage就会被回调以完成收到信息的翻译工作。
而对message的处理工作完全放到translateMessage函数中进行处理,与udpserver的通信逻辑完成强解耦,这是一种非常好的代码风格,对message进行特定的业务逻辑处理,translateMessage函数不需要关心message是怎么来的,将信息的业务逻辑处理和获取信息的网络通信完成强解耦,这能够大大提升代码的鲁棒性,是非常好的代码风格。
(大家可能体会不到代码强解耦所带来的好处,之前我写线程池代码的时候,把线程池的初始化即创建多线程的代码和给线程处理函数handler中分配线程名的代码强耦合在了一起,反正很乱,就是有可能出现线程已经开始跑起来了,但线程对象的指针还没分配,我这里也说不清楚,反正几个不同功能的模块代码强耦合在一起了,结果就是代码出现了很恶心很恶心的问题,而且每次爆出来的问题还都不一样,真的非常非常难受。所以大家平常写出来的代码一定是要高内聚,低耦合啊,否则出了问题解决起来真的要把你搞崩,如果还掺杂着多线程,那真的是难搞啊,所以代码一定要强解耦,否则出了bug你就慢慢找吧,难受死你。)

3.
C++风格的getline会按行读取istream流对象中的内容到string对象中,所以我们可以定义一个ifstream的对象,让这个流对象关联到dict.txt文件,创建ifstream对象时dict.txt文件会自动打开,ifstream对象销毁时dict.txt文件会自动关闭,然后把这个in对象切割赋值给getline的第一个参数istream对象,并将getline获取到的内容存放到string 对象line中,getline会按行读取文件dict.txt中的内容,并忽略掉读取的换行符\n,这点与fgets不同,fgets并不会忽略掉\n。
读取到line之后,接下来要做的工作就是字符串line的切割,以 : 作为separator(分隔符),将字符串切割为key和value两部分,切割之后就是构造键值对插入到unordered_map中,getline一直循环读取重复上述操作,直到getline读取到文件尾,跳出while循环后,我们可以打印一句load dict success,代表已经将文件中的内容切割后搞成键值对插入到unordered_map dict中了。
除此之外还实现了一个热加载函数reload,为什么要实现这个呢?比如在服务器运行的过程中,我又在文件dict.txt中增加了新的汉字和英文的映射关系,此时我不想重新终止掉服务器,然后在重新启动服务器,重新加载文件内容到dict对象中,那么我们就可以使用热加载函数,即捕捉信号SIGINT,让该信号的处理行为变成调用reload,reload重新调一次initdict()函数,重新加载。这就是所谓的热加载。
4.
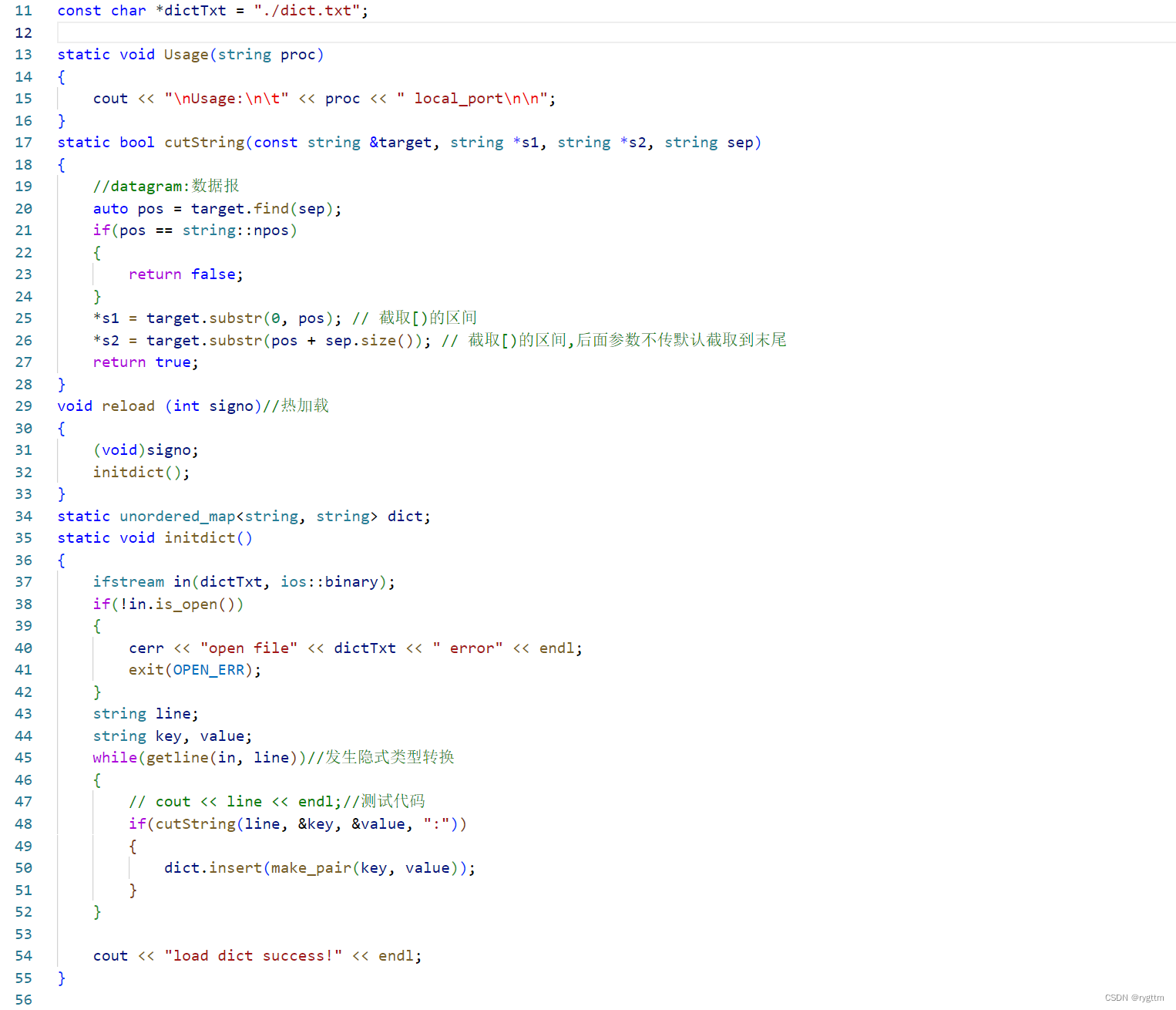
下面是网络通信后得到的message进行信息的业务处理的函数代码。
代码逻辑其实很简单,因为各项的准备工作都已经做好了,我们只需要调用dict中的find接口进行message作为key值的查找,find接口会返回对应存储message的键值对的迭代器,通过迭代器就可以拿到message的翻译结果,然后我们将翻译结果返回给客户端即可,返回的方式也很简单,调用sendto系统调用即可,translateMessage的参数列表中有客户端的ip和port等信息,以及服务器自己的sockfd,所以直接定义一个struct sockaddr_in 结构体对象client,填充好client的内容后,将对应的response_message消息返回给客户端即完成了翻译结果的返回。
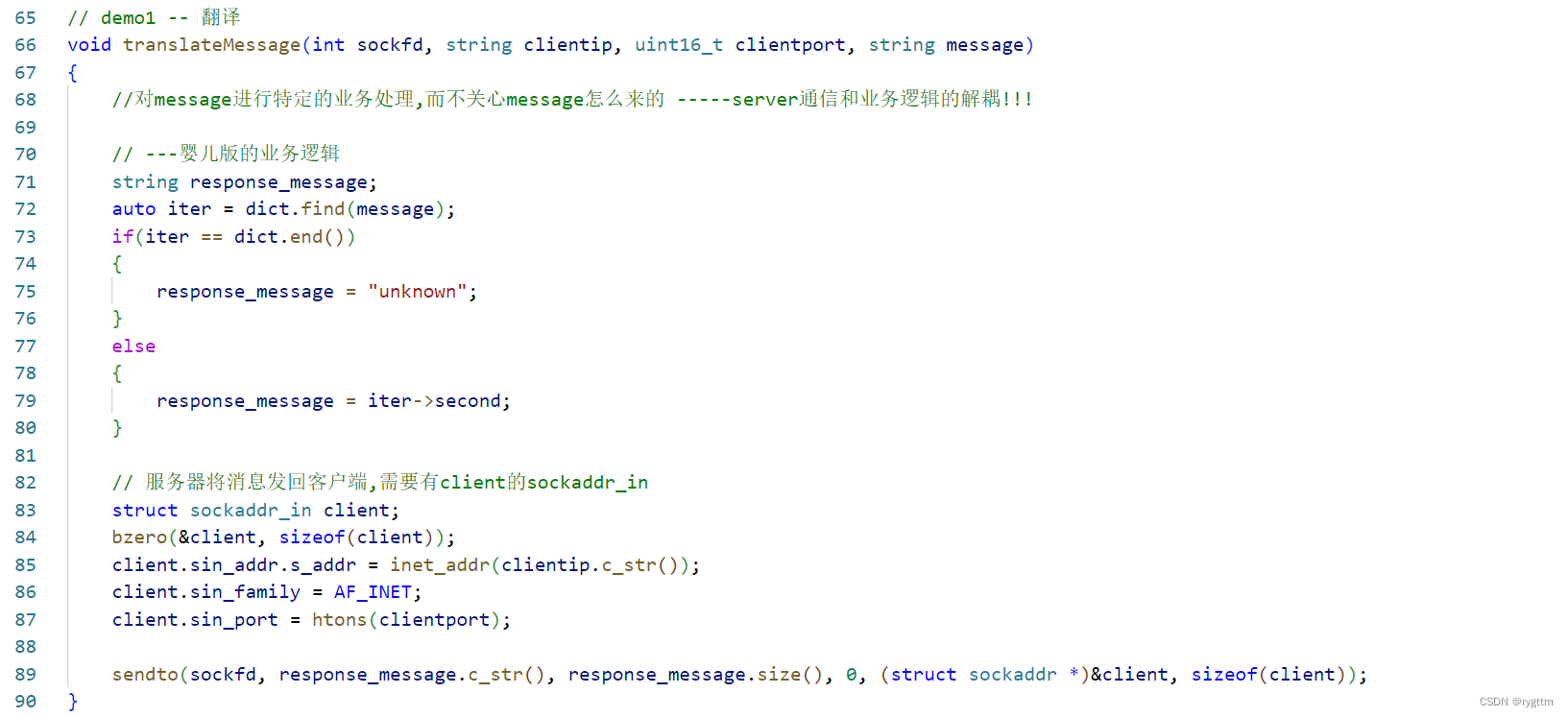
下面代码是udpClient.hpp中类Client的run方法,我们在客户端的死循环代码中增加了一部分接收服务器翻译结果的代码,接收的逻辑也不难,只需要调用system call recvfrom即可,服务器的ip和端口号客户端其实早就知道的,所以这里只要定义一个struct sockaddr_in temp结构体即可,我们也不需要拿temp结构体里面服务器的ip和port,因为早在客户端运行前,客户端就知道自己要给哪个ip哪个port发送数据了,所以这里的temp仅仅只是为了配合recvfrom搞出来的临时结构体。
然后我们打印出服务器的翻译结果,就完成了客户端的通信代码。

下面是翻译版本代码的运行结果,可以看到对于文件dict.txt中已存在的映射关系,服务器可以给出对应英文的翻译结果,如果你输入的英文不存在于dict.txt中,则服务器会返回一个unknown的翻译结果。
在运行的过程中,我中途在dict.txt中增加了两行的映射关系,没进行热加载之前,udp和tcp的翻译结果为unknown,但只要在服务器进程中运行ctrl+c也就是向服务器进程发送SIGINT信号,服务器就会进行文件dict.txt的热加载,则我们输入的tcp和udp英文就可以有正确的翻译结果了。

5.
下面是执行bash指令的版本代码,业务逻辑处理和网络通信的解耦省了我们不少的事,现在想要进行bash指令的执行,那直接在写一份execCommand函数出来即可,可以将函数名传递给udpServer对象,server类内在接收客户端消息之后,会回调execCommand函数进行业务逻辑处理。所以main函数我们几乎什么都不用改,只需要改一下传递给udpServer对象的函数名参数就可以,所以解耦是不是很香呢?
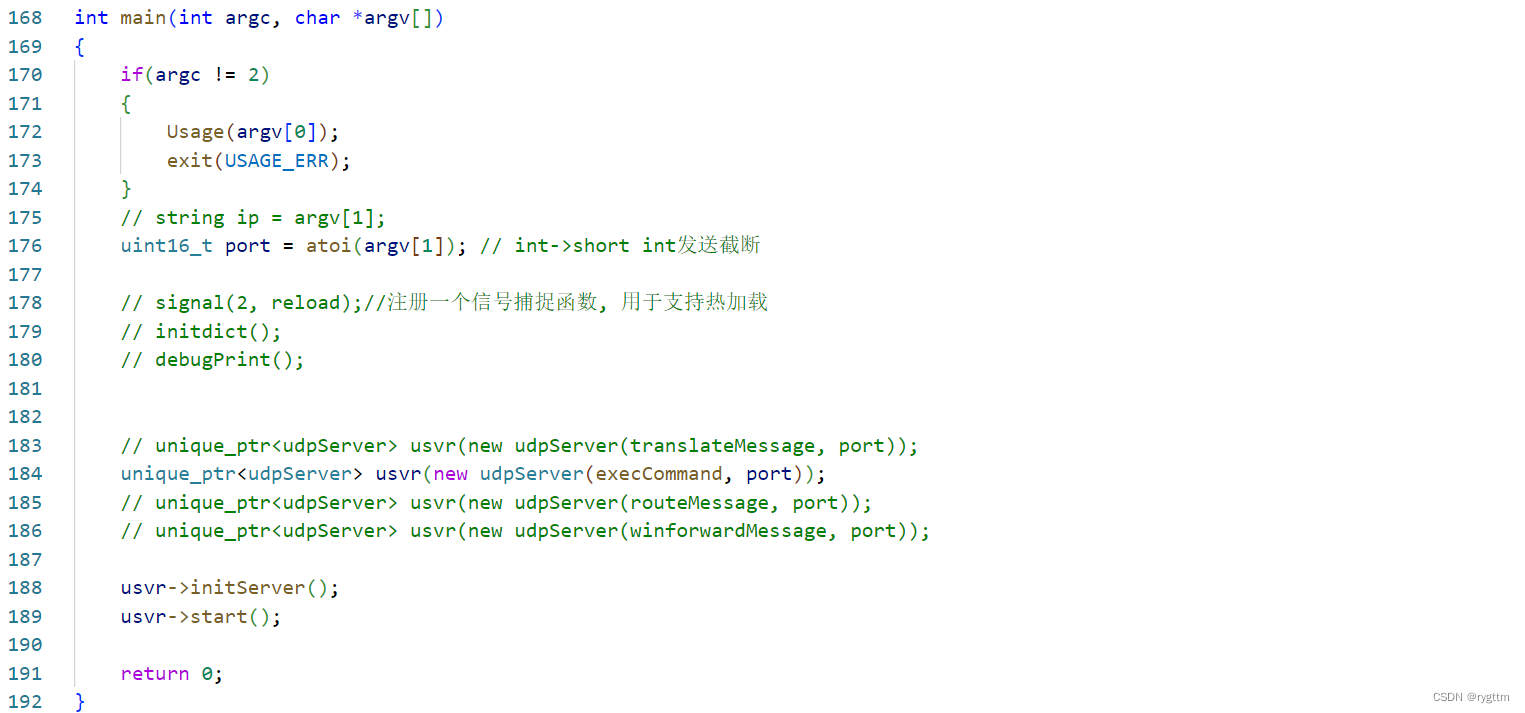
下面是execCommand接口的代码,其中起着关键重要角色功能的函数就是popen,该函数可以创建一个管道和一个子进程,让子进程执行shell指令,并将执行的结果写入到管道文件中,popen可以打开管道文件,从管道文件中读取子进程执行指令的结果。该函数原型如下,需要传递子进程执行的命令也就是command参数,以及管道文件的打开模式,可以是只读只写和追加,我们今天肯定是用只读打开,读取管道文件另一端的子进程执行指令的输出结果。
popen调用后的文件指针fp会指向一个文件,该文件中的内容就是子进程执行bash指令后的输出结果。我们可以通过fgets来读取指针fp指向的文件的内容,并将此内容+=到string类型的对象response中,则需要返回给客户端的信息就是response。返回调用sendto时的套路和之前的翻译版本一样,都是创建出client结构体,填充字段,告诉sendto发送消息要发给哪个客户端。最后关闭文件指针fp即可,这样就完成了bash指令的指向,客户端向服务器发送bash指令,服务器会将bash指令的执行结果返回给客户端。


客户端这里的逻辑没有任何变化,我仅仅只是把“服务器的翻译结果#”这个输出提示信息去掉了而已。并且将Please Enter换成了仿真的服务器提示信息"[wyn@VM-8-2-centos socket]$ "以更为真实的执行bash指令。
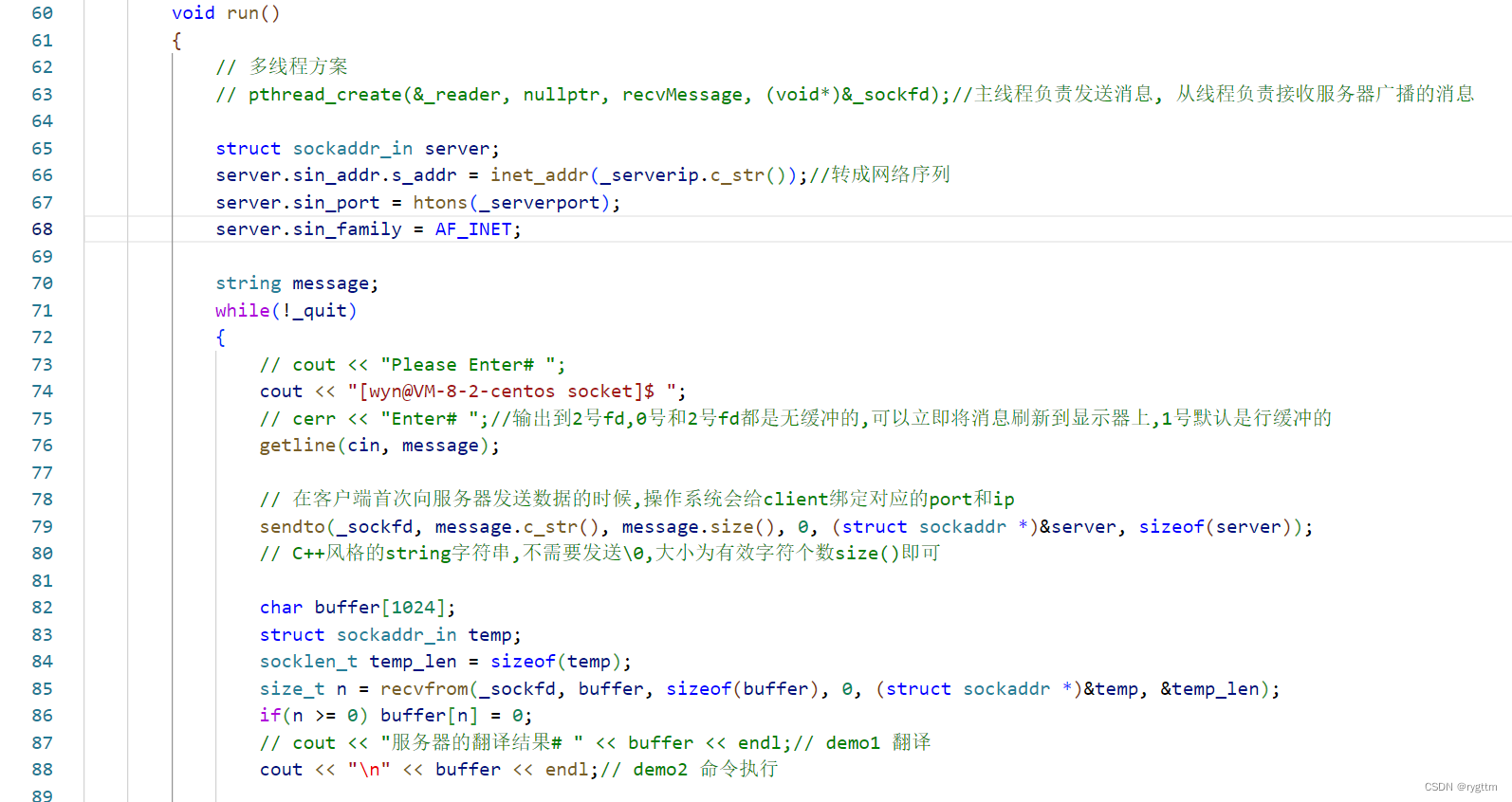
下面是bash指令版本的代码。一般的指令例如,pwd ls touch clear等指令都是可以执行的,对于rm mv rmdir这些指令我给屏蔽掉了,防止客户端对服务器搞破坏,例如经典的rm -rf ./*删除垃圾指令。

6.群聊版本和win+linux联动版本
1.
一个人和服务器聊天多没意思,我们要搞就直接搞个群聊嘛,一个人发的信息其他群聊成员都可以看到,这样才有意思嘛。所以我们就来实现一个消息的路由,即将某个人发送的消息路由群发给所有在线的用户,main函数还是老样子,只需要改一下传递给udpserver对象的函数指针就可以完成main代码的编写。

2.
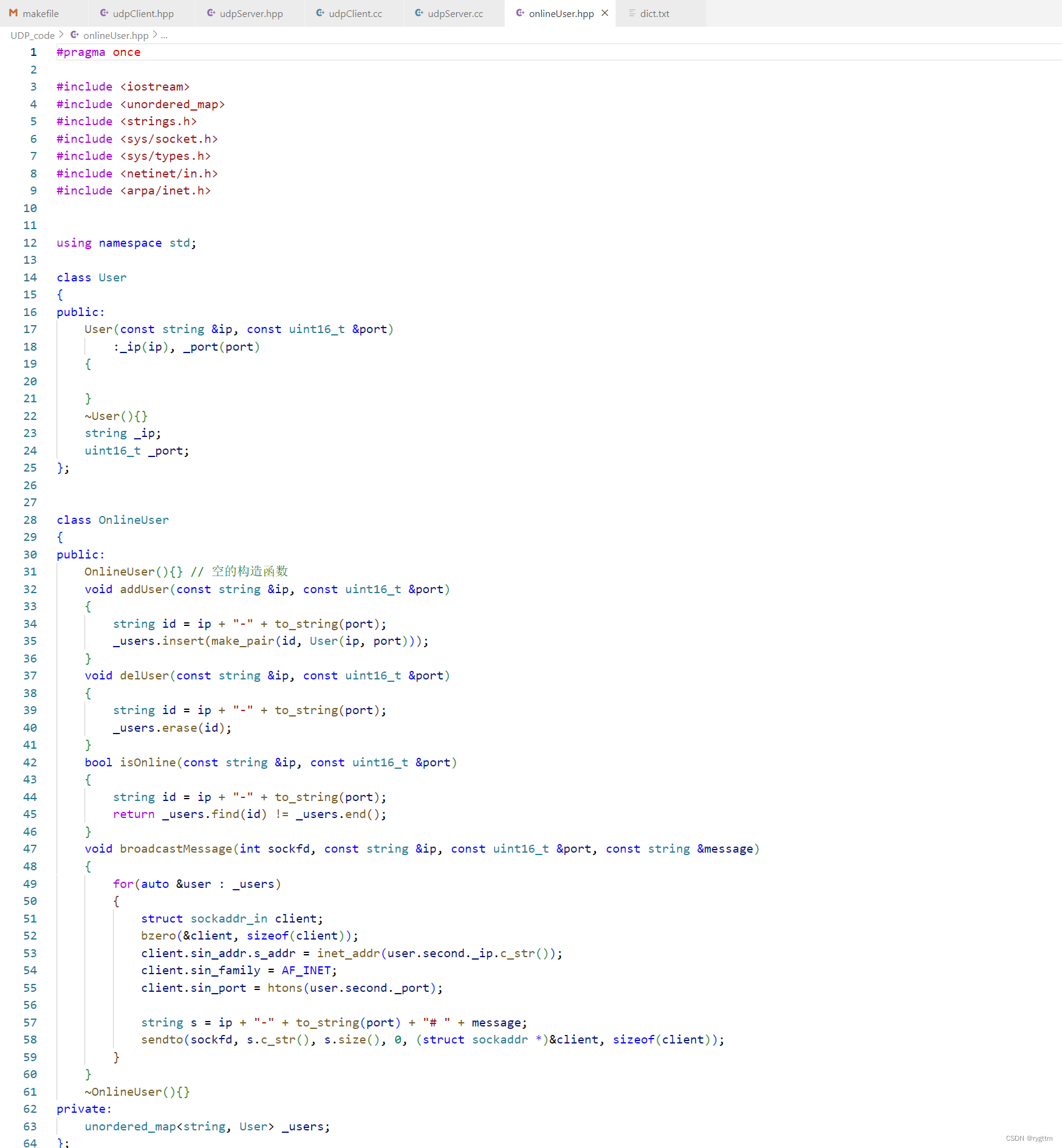
下面是在线用户的onlineUser.hpp文件的代码,其中实现了两个类,一个类是指普通用户,一个类是指所有已经上线了的用户,我们用该类来进行上线用户的添加,用户下线等功能的实现。
User类成员主要还是客户端的ip和端口号,我们用这两个变量来标识一个客户,User的构造函数用这两个变量来进行初始化即可。
OnlineUser类成员变量主要是一个哈希表,用于存储string类型的id和User类型的用户之间的映射关系,这个id是我们用clientip和clientport拼接出来的一个字符串。OnlineUser类主要实现的功能模块有四个,分别是用户要上线时的添加addUser(),已上线用户的删除delUser(),用户是否在线isonlineUser(),消息的路由群发broadcastMessage(),即你发送的消息所有已上线的用户都可以看到。前三个接口的实现并不复杂,说白了就是调用_users哈希表的insert() erase() find等接口。消息的路由群发接口可能需要说一下,路由群发的接口参数需要客户端的ip和port,以及服务器的sockfd和客户端发给服务器的message。
for循环内部遍历哈希表中所有的键值对,键值对中的value值就是已上线的用户,其中含有两个成员变量正好分别是用户的ip和端口。定义一个client结构体,然后用已上线用户的信息填充结构体client,最后将消息发送给所有的已上线用户,我们将发送的消息也进行字符串的拼接,即客户端的ip和端口以及message进行拼接。
3.
下面是server服务器的逻辑处理函数routeMessage,如果用户没上线那就告诉用户,让用户运行online上线(通过调用sendto接口即可),上线之后如果要发送消息那就直接调用broadcastMessage接口进行客户端消息的群发即可。

4.
下面是客户端的代码,采用了多线程的方案,即一个线程进行消息的发送,一个线程负责接收服务器返回的消息,如果不采用多线程的方案,我们无法看到其他客户发送的消息,因为输入消息之后,服务器处理之后,run中的死循环代码调用recvfrom之后又会重新运行到getline处,重新阻塞式的读取键盘输入的消息,那么此时就无法运行recvfrom,也就无法接收其他已上线用户给服务发消息后服务器路由群发给所有online用户的消息,所以我们只能采取多线程的方案,让键盘输入和接收服务器消息是两个不同的执行流在执行。
代码中还是有细节的,发送消息时我用的是cerr,即无缓冲的将消息显示到显示器上,而接收消息的线程执行函数中,打印服务器返回的消息时用的是cout,行缓冲的将消息显示到显示器上。

5.
我用vscode充当服务器,xshell充当客户端,下面是代码的实验现象,cout输出的内容会被重定向到管道文件中,而cerr输出的内容会无缓冲的立马显示在终端上。这可以将发送消息和接收消息这两个步骤分到不同的终端(不同的现象实际就是不同的会话)中,这样实验现象会更加的明显。
用户1发送的消息,用户2是可以收到的,这就是服务器将用户1发送的消息路由群发给了包括用户1 在内的其他所有用户,如果还有用户3,用户4,等等,他们照样也都可以收到用户1发送的消息,前提是只要他们都运行了online上线了之后。

6.
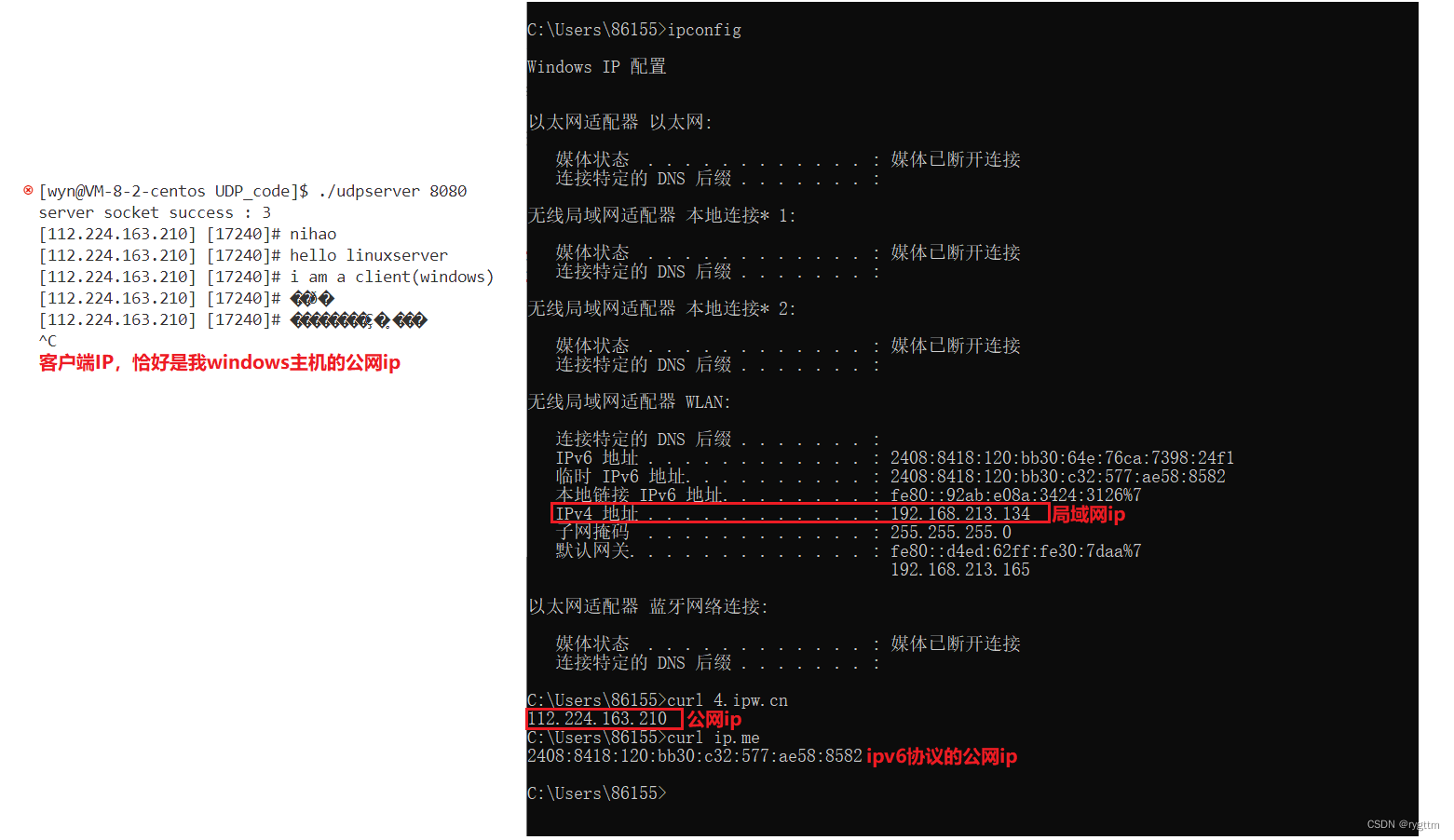
下面是windows的vs2022作为客户端,linux云服务器作为服务端的代码实现。
服务器的代码就不搞那么复杂了,我们就简简单单的实现一个客户端消息的回显就可以了,即server echo.
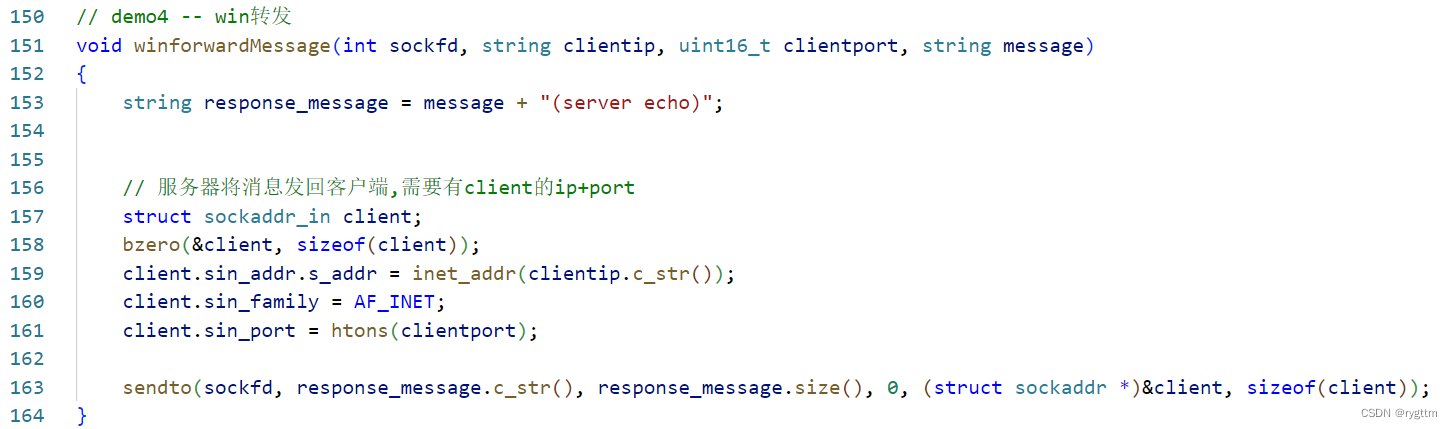
下面代码是windows下网络套接字编程的代码,windows客户端的套接字代码仅仅只有初始化windows的socket网络库,以及最后需要调用windows系统下的WSACleanup()清理接口外,其他的代码和我们在linux上面写的客户端代码不能说非常相似,只能说一模一样,所以我就不过多赘述了,无非就是调用socket() sendto() recvfrom()接口来进行数据包的发送和接收,代码大家可以自己扫一眼。

7.
下面是代码的实验结果,windows用的是GBK编码,而linux是UTF-8的编码,所以在发送中文的数据时,linux解码可能会出现问题,但使用英文就没有问题,可以在不同的平台下进行数据的收发,兼容性很好。

从windows的cmd命令窗口可以查看到我电脑主机的公网ip,以及当前我电脑所连接的手机热点局域网中的ip,而linux服务器打印出来的客户端ip正好是我的windows电脑主机的公网ip 112.224.163.210,而不是我的局域网ip 192.168.213.134。