导入数据
import pandas as pd
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])df
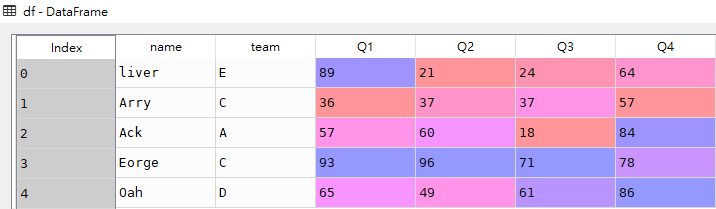
问题: 筛选出'team'字段包含'C'值的所有数据行
cteam_data = df[df["team"].str.contains("C")]cteam_data

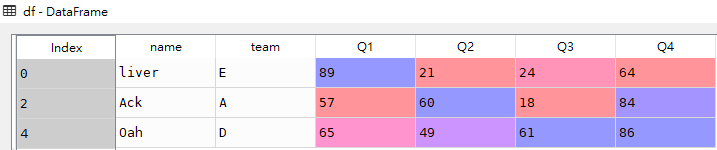
问题扩展: 删除'team'字段包含'C'值的所有数据行
import pandas as pd
df = pd.DataFrame([['liver','E',89,21,24,64],
['Arry','C',36,37,37,57],
['Ack','A',57,60,18,84],
['Eorge','C',93,96,71,78],
['Oah','D',65,49,61,86]
],
columns = ['name','team','Q1','Q2','Q3','Q4'])
# 删除'team'字段包含'C'值的所有行
df = df[~df["team"].str.contains("C")]df
文本包含.str.contains()![]() https://blog.csdn.net/Hudas/article/details/122922868
https://blog.csdn.net/Hudas/article/details/122922868