文章目录
前言
这是本专栏【C转C++之路】第一篇文章,主要讲讲命名空间相关内容。由于笔者水平有限,欢迎指正交流。
命名空间
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的 。
举个例子:
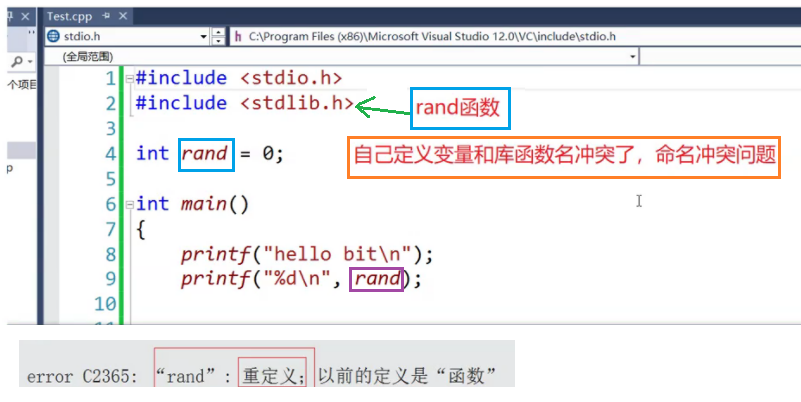
其实有时候你都不知道头文件里有没有同名的标识符,要是有的话又得想别的名字防止冲突,C语言的编译器并没有什么解决办法,一般是建议用户自己改个别的名,有点搞。
在项目中互相合作时有可能发生命名冲突,一群人的代码提交合并后一看命名冲突,那到底有几个?分别在哪里?那谁的代码做修改?这都是些麻烦事儿,这群人肯定会想:凭什么是我改不是你不改?难不成打一架输的人改吗?所以说C++的命名空间在解决这个问题就起到很好的作用了。
命名空间其实就是划分一个个区域,用来“包裹”封装标识符,可以存在同名,只不过是处在不同命名空间,要用哪个可以指定命名空间来使用而不会起冲突。
比如上面的代码可以改为
#include <stdio.h>
#include <stdlib.h>
namespace random
{
int rand = 0;
}
int main()
{
printf("hello bit\n");
printf("%d\n", rand);
}
这里定义了命名空间域,名为random,把rand变量定义在这一命名空间中,按这样最终打印结果会是什么?
结果会打印库函数rand的地址,为什么不是0呢?这里可以先理解为命名空间random用“围墙”把花括号里面的内容围起来了,这样编译器在查找时就不能直接找到它,除非向编译器指定我要找的rand就是命名空间里的那个变量(让编译器“翻进墙内”)。那么这里有一个问题:命名空间random内的变量rand是全局变量还是局部变量?我们一点一点来理解。
命名空间的定义
定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{}中即为命名空间的成员 。
以下是几种定义类型:
// N是命名空间的名字,一般开发中是用项目名字做命名空间名。
//正常的命名空间定义
namespace N
{
// 命名空间中可以定义变量/函数/类型
int rand = 10;
int Add(int left, int right)
{
return left + right;
}
struct Node
{
struct Node* next;
int val;
};
}
发现没有,我们好像可以把各种东西一股脑地塞进命名空间里,它貌似“来者不拒”,那它有那么大的空间装下这些东西吗?等会儿,你可能对它有一点误解,命名空间其实并没有开辟申请内存,也不是变量或类型抑或函数,它只是划分了一片区域来封装内容,对内容本身不作修改,具体来说:
命名空间不影响生命周期,只是限定域,影响编译器的查找规则。那编译器的查找规则是什么呢?默认是局部优先和向上查找,也就是先在最近的局部域里面查找,找不到再去全局域找,且向上找而不向下找。
所以前面那个例子中在命名空间random中定义的rand变量是全局变量,编译器遇到命名空间的“围墙”时看不到里面的内容就不知道里面有什么,直接绕过向后找,除非你对rand变量做出了指定,random::rand,也就是向编译器指明了我要用的是命名空间random下的rand变量,这样编译器就会“翻进墙内”找rand。::又是什么东西啊?别急,我们下面就讲命名空间的使用。
命名空间的使用
以下面代码为例讲讲命名空间三种用法
namespace N
{
// 命名空间中可以定义变量/函数/类型
int a = 10;
int Add(int left, int right)
{
return left + right;
}
struct Node
{
struct Node* next;
int val;
};
}
使用命名空间名称及作用域限定符指定
用域作用限定符::指定是哪个命名空间里的什么成员,::之前是命名空间名,之后是要指定的成员的名称。一旦指定了,编译器就会直接到对应的命名空间查找而不会再按默认规则查找,也就是命名空间改变了编译器的查找规则。
int main()
{
int x = 5;
struct N::Node node;//注意结构体的指定用法
N::a = N::Add(N::a, x);
printf("%d\n", N::a);
return 0;
}
那要是我没有用::指定N会怎样?
不指定的话编译器按默认规则找,若到指定域找不到就报错。
使用using namespace 引入整个命名空间
std是C++官方库内容定义的命名空间。我们可能会觉得每次使用命名空间中的内容都要指定命名空间会有些麻烦,比如在有些变量或函数要大量被使用时。可以使用using namespace N来展开命名空间,这样做就相当于“把围墙给拆了”,让内容直接暴露在全局域中,用起来是方便了,可是命名空间不就失去意义了吗?
我们为什么要使用命名空间?是为了防止自己的命名和已存在的内容产生命名冲突,把内容按需求放到各个命名空间中就有效避免了命名冲突。那你这会儿又把它展开作甚呢?其实不应该贪图这点小便利而忽视更重要的安全性,如果是日常练习展开倒也无妨,但要是实现项目的话就不应该直接展开。
比如展开命名空间N,这样就可以直接使用N里面的内容了。
using namespace N;
int main()
{
int x = 5;
struct Node node;
a = Add(a, x);
printf("%d\n", a);
return 0;
}
使用using引入命名空间中某个成员
折中总是狡猾的,它兼顾各方案的好处而更好地解决问题。展开命名空间固然不太妥当,那我们又想使用起来便利些,于是就可以用using只引入自己需要的某些成员到全局域,其他的仍留在命名空间。
比如只引入了Add函数,就可以不用指定直接使用它了。
using N::Add;
int main()
{
int x = 5;
struct N::Node node;//注意结构体的指定用法
N::a = Add(N::a, x);
printf("%d\n", N::a);
return 0;
}
命名空间的嵌套与合成
命名空间的嵌套
//命名空间可以嵌套
namespace N1
{
int a;
int b;
int Add(int left, int right)
{
return left + right;
}
namespace N2
{
int c;
int d;
int Sub(int left, int right)
{
return left - right;
}
}
}
要访问a的话需要N1::a,要访问b的话需要N1::N2::b,命名空间的嵌套可以看成“围墙”的嵌套,编译器“翻过N1墙”
后会发现里面还有一层“N2墙”,需要再翻过去才能找到b。
命名空间的合成
同一个工程中多个文件中允许存在多个相同名称的命名空间,它们最后会合成到同一个命名空间中,有效避免命名空间的所有内容堆砌在同一个文件内造成臃肿。
比如在两个头文件里把不同的结构体类型定义放在一个命名空间内,再在源文件中包含头文件后使用命名空间里的内容。

感谢观看,你的支持就是对我最大的鼓励~
