面试官来找茬(1):Java八股文背过吧,说说HashMap
- 一、前言
- 二、HashMap 概念
- 三、HashMap 面试题
-
- 3.1 说说 HashMap 和 Hashtable 的区别
- 3.2 说说 HashMap 和 TreeMap 的区别
- 3.3 说说 HashMap 和 ConcurrentHashMap 的区别
- 3.4 说说 Hashtable 和 ConcurrentHashMap 两者的性能和锁区别
- 3.5 说说 Hashtable、SynchronizedMap 和 ConcurrentHashMap 三者的区别
- 3.6 HashMap 的 size 和 capacity 有什么区别
- 3.7 可以使用任何类作为 HashMap 的 Key 吗
- 3.8 HashMap 的长度为什么是 2 的 N 次方呢
- 3.9 HashMap 的扩容机制了解吗
- 3.10 为什么 HashMap 的负载因子(loadFactory)默认设置成 0.75f
- 3.11 为什么建议集合初始化时指定容量大小
- 3.12 HashMap 的初始容量设置为多少合适
- 3.13 为什么 JDK 1.8 中的 HashMap 引入 红黑树 而不是 AVL树
- 3.14 HashMap 中 链表 和 红黑树 互相转换的过程了解吗
- 3.15 为什么将 HashMap 由 链表 转换成 红黑树 的阈值(TREEIFY_THRESHOLD)设置为 8
- 3.16 为什么将 HashMap 由 红黑树 转换成 链表 的阈值(UNTREEIFY_THRESHOLD)设置为 6
- 四、资料参考
一、前言
Java深坑两抹泪,面试碰壁基础废。问君背过八股否,HashMap啥的教吾呗。——《不背八股学HashMap》
小弟不才,恰得押韵,勿喷勿喷。面试中,面试官经常拿 HashMap 来找茬,也不知道他们是真的“姚明举灯笼——高手”,还是和我们一样,背背八股文,略懂皮毛。披着“毛不多的皮”的我,也来聊聊 HashMap 这种数据结构吧,网上都说烂了。内容只针对 JDK 1.8 ,更高版本是否有变动暂时没有研究。
我不是“砖”家,也只是捧着一些书籍和资料参考来写文章的“平”民罢了,有错误请指出,不吝赐教。同时,《面试官来找茬》是一个系列博客,后面的博客同样精彩。
本文由 CSDN@大白有点菜 原创,如需转载,请说明出处。如果觉得文章还不错,可以 点赞+收藏+关注 ,你们的肯定是我创作优质博客的最大的动力。
二、HashMap 概念
2.1 什么是 HashMap
Hash 译作 散列 或者 哈希,把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。(百度百科)
Map(映射) 属于 关联数组(Associative Array),是一个抽象的数据结构,包含着类似于 Key(键)/Value(值) 的有序对。(维基百科)
HashMap 基于哈希表的 Map 接口的实现。(百度百科)
所有散列函数都有的 基本特性(维基百科):
1、如果根据同一散列函数计算
两个散列值不相同,那么这两个散列值的原始输入值也不相同。具有这种性质的散列函数称为单向散列函数。
2、如果根据同一散列函数计算两个散列值相同,那么这两个散列值的原始输入值可能相同,可能不相同,这种情况称为“散列碰撞(collision)”。
2.2 常见的 HashMap 算法
- 直接定制法:直接以关键字 k 或 k 加上某个常数(k+c)作为 Hash 地址。
- 数字分析法:提取关键字中取值比较均匀的数字作为 Hash 地址。
- 除留余数法:用关键字 k 除以某个不大于 Hash 表长度 m 的数 p 作为 Hash 地址。
- 分段叠加法:按照 Hash 表地址位数将关键字分成位数相等的几部分,其中最后一部分可以比较短,然后将这几部分相加,舍弃最高进位后的结果就是该关键字的 Hash 地址。
- 平方取中法:如果关键字各个部分分布都不均匀,则可以先求出它的平方值,然后按照需求取中间的几位作为 Hash 地址。
- 伪随机数法:采用一个伪随机数当做 Hash 函数。
2.3 解决 HashMap 碰撞的方法
- 开放定址法:一旦发生了碰撞,就去寻找下一个空的散列地址,只要散列表足够大,总能找到空的散列地址,并将元素存入。
链地址法:将 Hash 表的每个单元作为链表的头节点,所有 Hash 地址为 i 的元素构成一个同义词链表,即发生碰撞时就把该关键字链接在以该单元为头节点的链表的尾部。
再 Hash 法:当 Hash 地址发生碰撞时使用其它函数计算另一个 Hash 函数地址,直到不再产生冲突为止。
- 建立公共溢出区:将 Hash 表分为基本表和溢出表两部分,发生冲突的元素都放入溢出表。
2.4 HashMap 数据结构
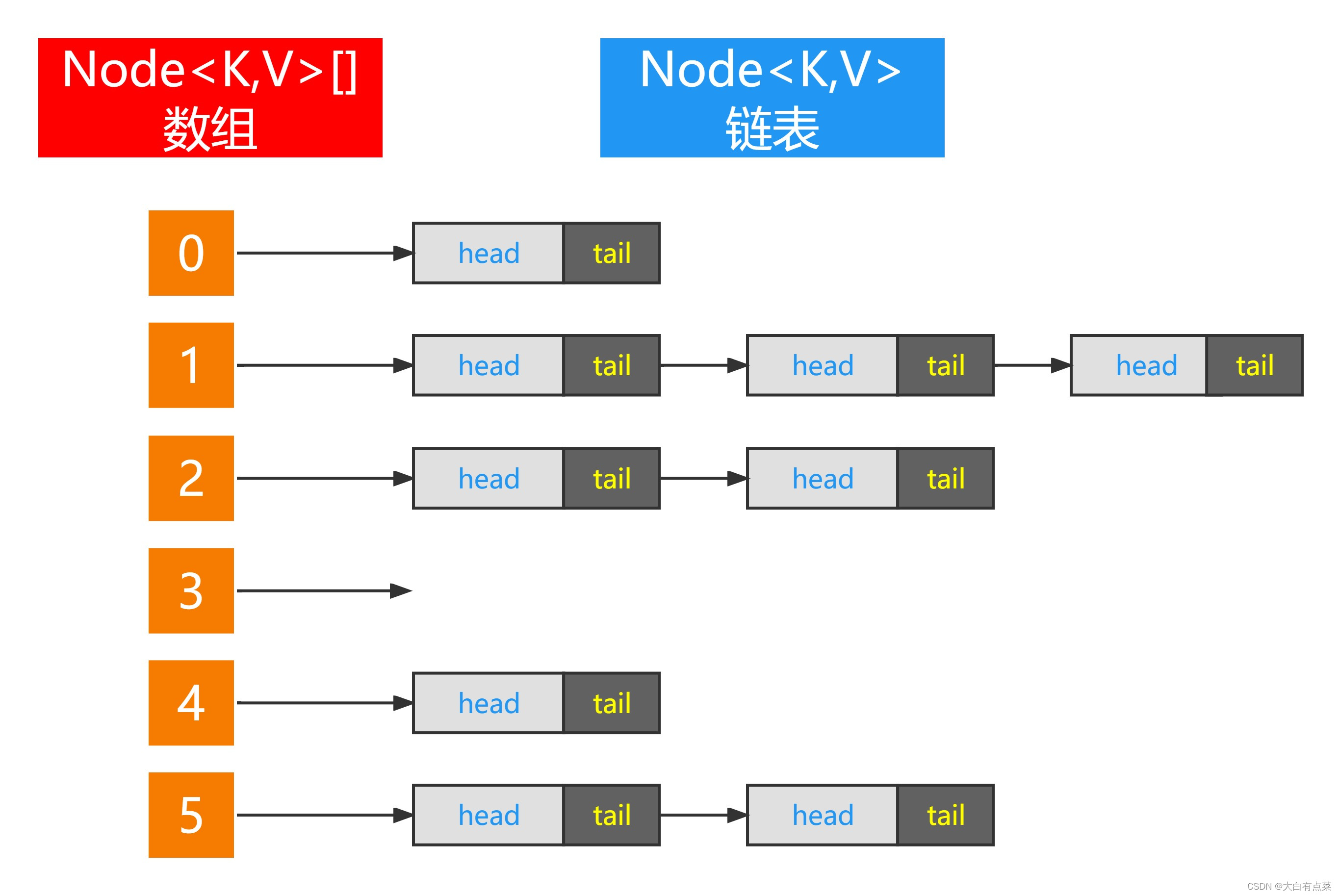
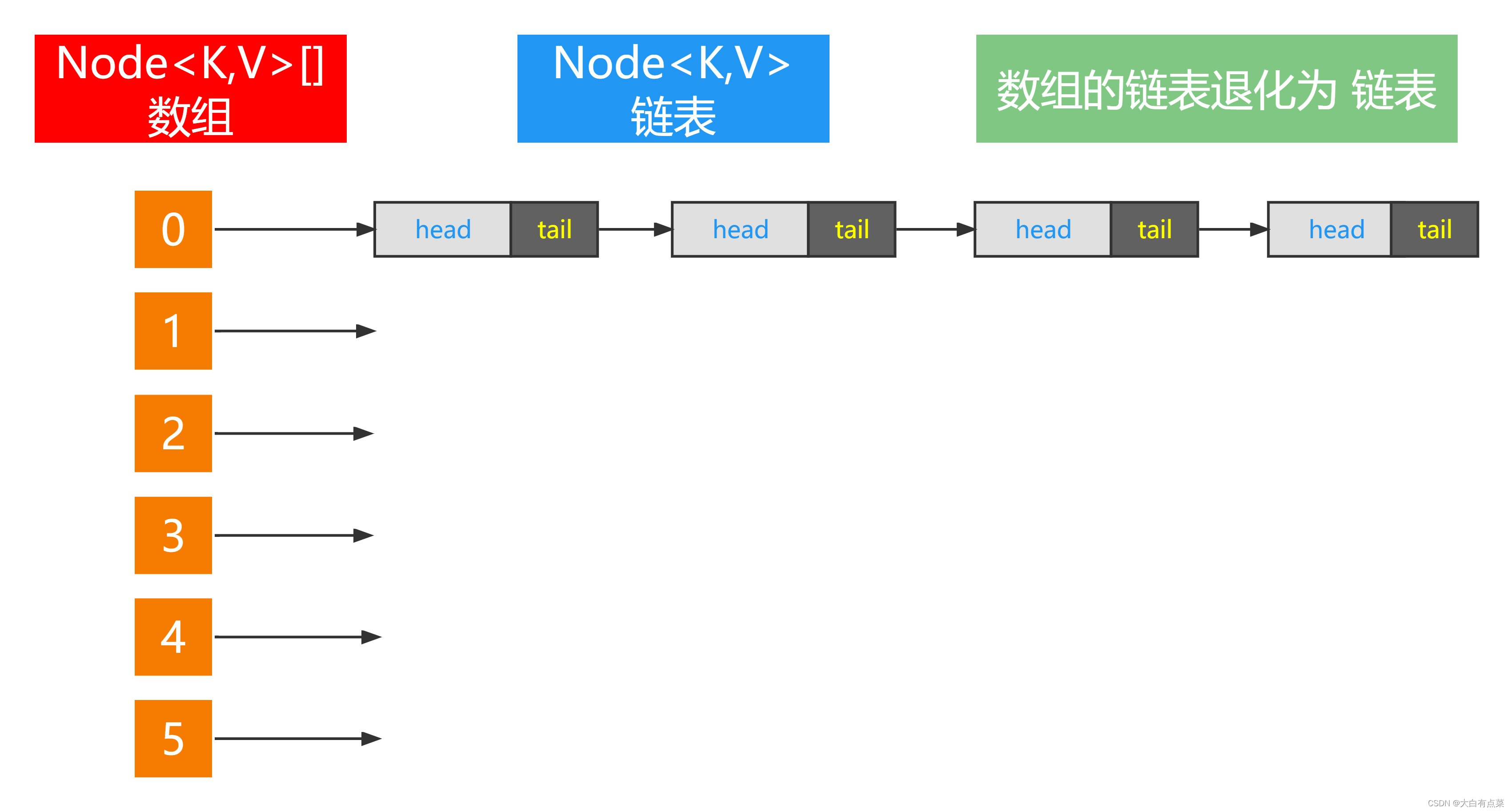
在 JDK 1.8 之前,HashMap 的数据结构是:数组 + 链表,主要是为了解决 Hash 冲突的问题,Hash 冲突是无法避免的,在极端情况下,数组的链表会退化为链表。如图所示。
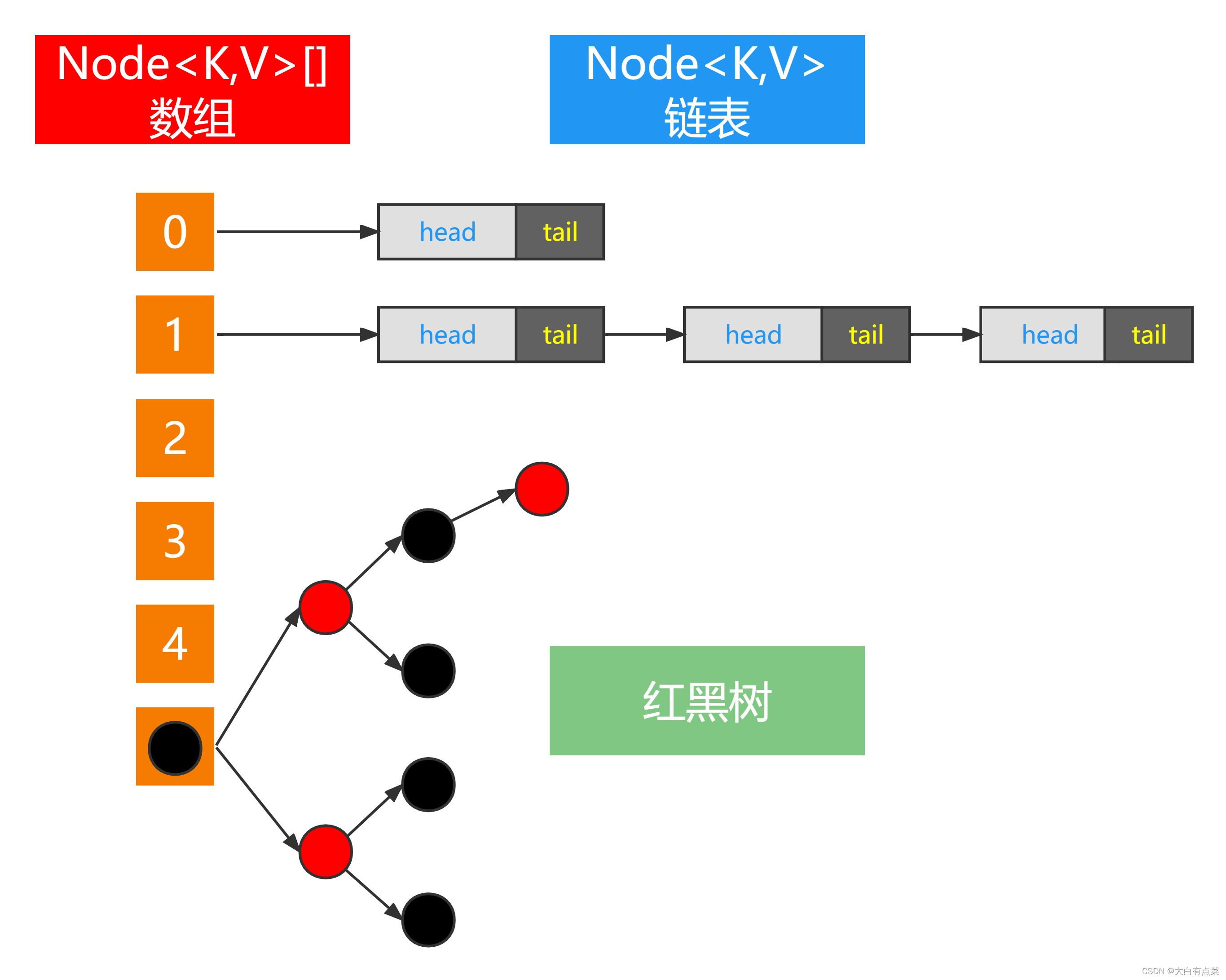
在 JDK 1.8 中,HashMap 引入 红黑树,HashMap 的数据结构为:数组 + 链表 + 红黑树。当链表长度太长时,链表转换为红黑树,利用红黑树增删改查速度快的特点解决链表过长导致查询性能下降问题。如图所示。
2.5 Fail-fast 和 Fail-safe
2.5.1 什么是 Fail-fast
在维基百科中,Fail-fast 说明如下(https://en.wikipedia.org/wiki/Fail-fast):
In systems design, a fail-fast system is one which immediately reports at its interface any condition that is likely to indicate a failure. Fail-fast systems are usually designed to stop normal operation rather than attempt to continue a possibly flawed process. Such designs often check the system’s state at several points in an operation, so any failures can be detected early. The responsibility of a fail-fast module is detecting errors, then letting the next-highest level of the system handle them.
在系统设计中,fail-fast(快速失败系统)是一种在其界面上立即报告任何可能表明故障的情况的系统。快速失败系统通常旨在停止正常操作,而不是尝试继续可能存在缺陷的过程。此类设计通常会在操作中的多个点检查系统状态,因此可以及早检测到任何故障。快速失败模块的职责是检测错误,然后让系统的下一个最高级别处理它们。【谷歌翻译】
这是一种设计理念,在做系统设计时先考虑异常情况,一旦发生异常,就直接停止并上报。
举个 fail-fast 的栗子:
public static void main(String[] args) {
divide(6, 0);
}
/**
* 除法运算
* @param divisor 除数
* @param dividend 被除数
* @return
*/
public static int divide(int divisor, int dividend) {
if (dividend == 0) {
throw new RuntimeException("被除数(dividend)不能为 0 ");
}
return divisor / dividend;
}

对两个整数做除法运算,在 divide 方法中,对被除数(dividend)做了一个简单的检查,如果值为 0 ,那么就直接抛出一个异常,并明确提示异常原因。这就是 fail-fast 理念的实际运用。
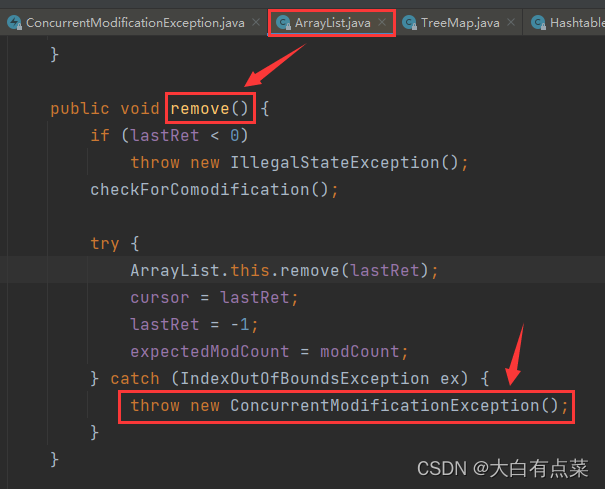
Java集合中运用 fail-fast 机制广泛,当多线程对部分集合进行结构上的改变的操作时,就有可能触发 fail-fast 机制,这时会抛出 ConcurrentModificationException 异常。
2.5.2 什么是 Fail-safe
在维基百科中,Fail-safe 说明如下(https://en.wikipedia.org/wiki/Fail-safe):
In engineering, a fail-safe is a design feature or practice that, in the event of a specific type of failure, inherently responds in a way that will cause minimal or no harm to other equipment, to the environment or to people. Unlike inherent safety to a particular hazard, a system being “fail-safe” does not mean that failure is impossible or improbable, but rather that the system’s design prevents or mitigates unsafe consequences of the system’s failure. That is, if and when a “fail-safe” system fails, it remains at least as safe as it was before the failure.Since many types of failure are possible, failure mode and effects analysis is used to examine failure situations and recommend safety design and procedures.
在工程中,fail-safe(故障安全)是一种设计特征或实践,在发生特定类型的故障时,它会以一种对其他设备、环境或人造成最小伤害或不造成伤害的方式进行固有响应。与特定危险的固有安全性不同,“故障安全”系统并不意味着故障是不可能或不可能的,而是系统的设计可以防止或减轻系统故障的不安全后果。也就是说,如果“故障安全”系统发生故障并且当它发生故障时,它至少会保持与故障前一样安全。由于可能发生多种类型的故障,因此使用故障模式和影响分析来检查故障情况并推荐安全设计和程序。【谷歌翻译】
在 java.util.concurrent 包下的容器都是 “fail-safe” 的,可以在多线程下并发使用和修改,也可以在 foreach 中执行 add/remove 操作。
三、HashMap 面试题
HashMap 类中几个很重要的静态常量:
| 静态常量 | 描述 | 默认值 |
|---|---|---|
| DEFAULT_INITIAL_CAPACITY | 默认初始容量,必须是 2 的幂。 | 1 << 4,即 16 |
| MAXIMUM_CAPACITY | 最大容量,如果任一构造函数使用参数隐式指定了更高的值,则使用。必须是 2 的幂。 | 1 << 30,即 1073741824 |
| DEFAULT_LOAD_FACTOR | 负载因子。 | 0.75f |
| TREEIFY_THRESHOLD | 由链表转换为红黑树的阈值。 | 8 |
| UNTREEIFY_THRESHOLD | 由红黑树转换为链表的阈值。 | 6 |
| MIN_TREEIFY_CAPACITY | 由链表转换为红黑树时,容器的最小容量的阈值。 | 64 |

3.1 说说 HashMap 和 Hashtable 的区别
【注意】:Hashtable 不能写作 HashTable,JDK中并不存在 HashTable.java 这个文件。 HashMap 和 Hashtable 都存在 java.util 包下。
3.1.1 两者父类不同,接口实现相同
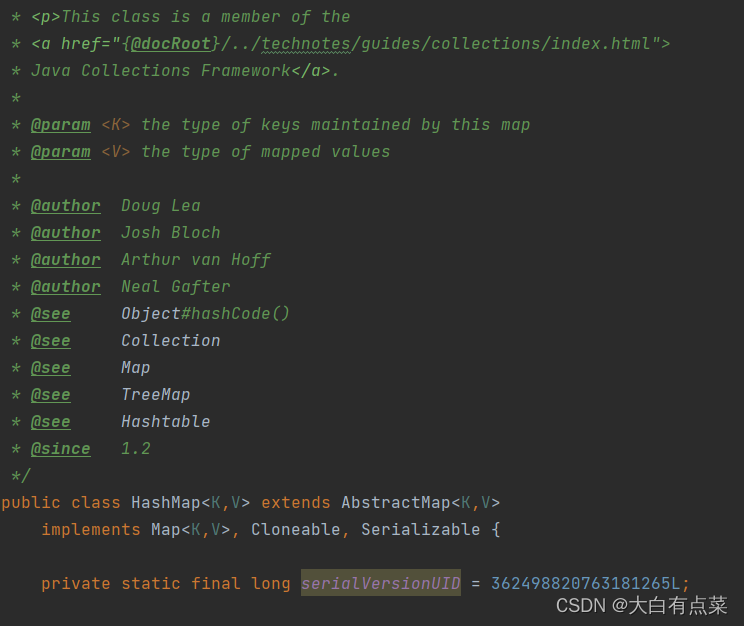
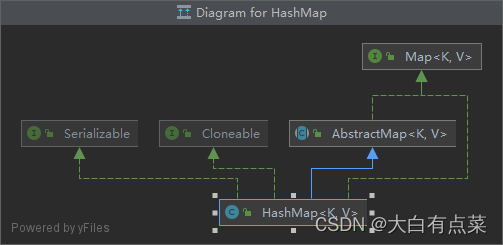
(1)HashMap 继承自 AbstractMap 类,实现 Map、Cloneable、Serializable 三个接口。
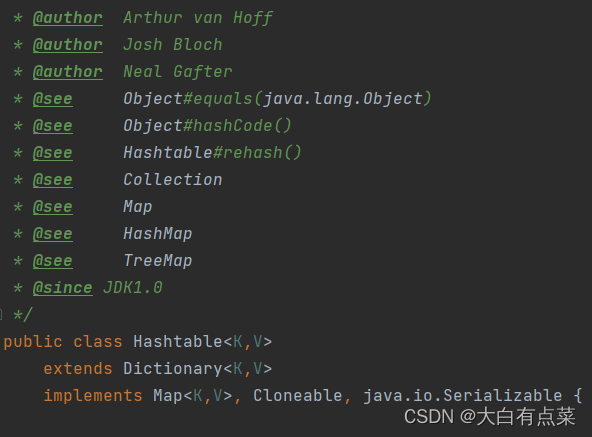
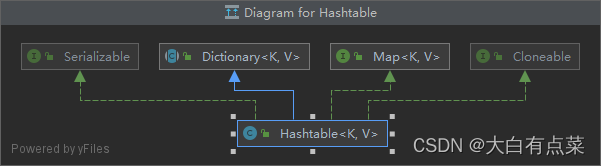
(2)Hashtable 继承自 Dictionary 类,实现 Map、Cloneable、Serializable 三个接口。
3.1.2 对 Null 支持不同
(1)HashMap 允许存储 一个空键(Null Key)和 任意数量的空值(Null Value)。
【示例代码:HashMapTest】
public class HashMapTest {
public static void main(String[] args) {
Map<String, String> hashMap = new HashMap<>(16);
hashMap.put(null, "大白有点菜1");
hashMap.put(null, "大白有点菜2");
System.out.println(hashMap.get(null));
hashMap.put(null, null);
hashMap.put(null, null);
System.out.println(hashMap.get(null));
System.out.println("HashMap的个数:" + hashMap.size());
}
}
【HashMapTest运行结果】
大白有点菜2
null
HashMap的个数:1
(2)Hashtable 不允许存储 空键(Null Key)和 空值(Null Value)。
【示例代码:HashMapTest】
public class HashMapTest {
public static void main(String[] args) {
Map<String, String> hashtable = new Hashtable<>();
hashtable.put(null, "大白有点菜");
System.out.println(hashtable.get(null));
hashtable.put("dbydc", null);
System.out.println(hashtable.get("dbydc"));
}
}
【HashMapTest运行结果】
Exception in thread "main" java.lang.NullPointerException
at java.util.Hashtable.put(Hashtable.java:460)
at cn.zhuangyt.javabase.hashmap.HashMapTest.main(HashMapTest.java:30)

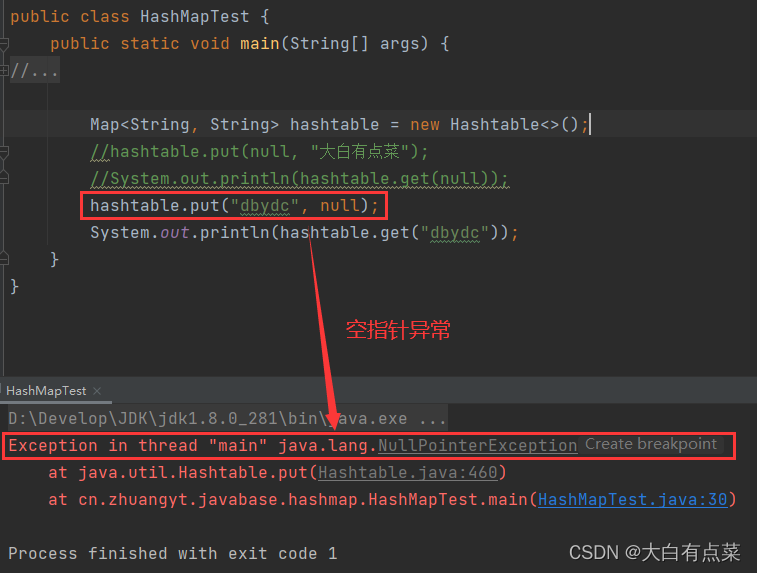
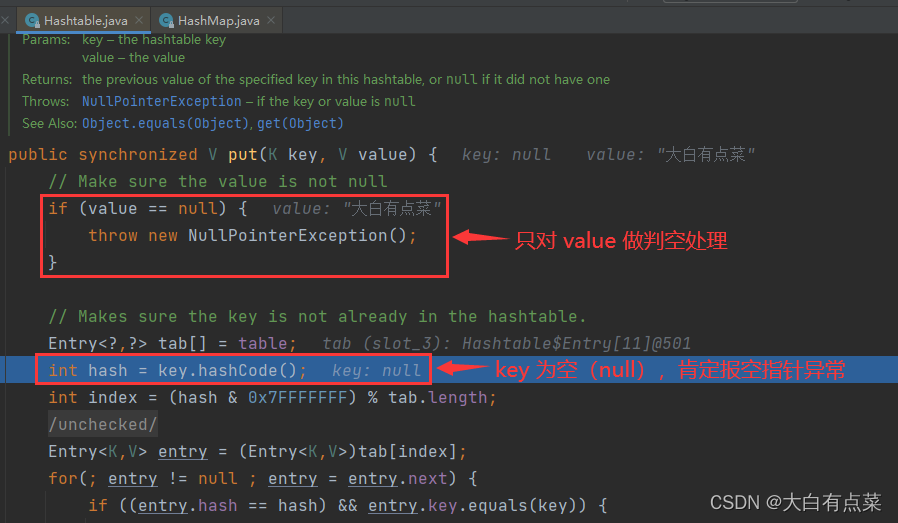
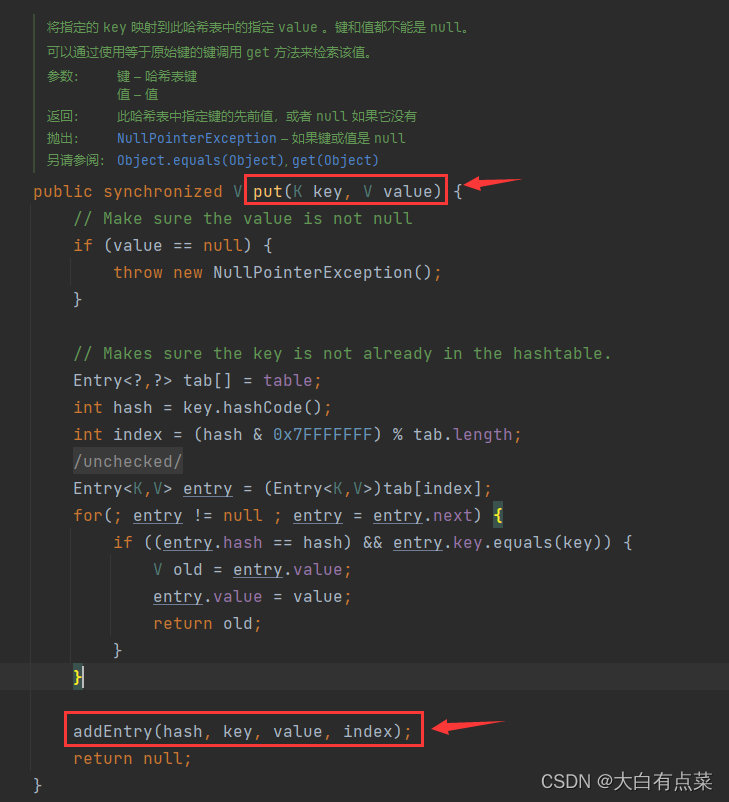
Hashtable 无论是存储 Null 键 还是存储 Null 值,都会报空指针异常(NullPointerException)。其实由源码中 Hashtable 的 put(K key, V value) 方法也可以看出,首先判断 value 的值是否为 Null,满足则手动抛出 NullPointerException。如果 key 也为 Null ,调用 key.hashCode() 时直接抛出 NullPointerException。 如图所示:
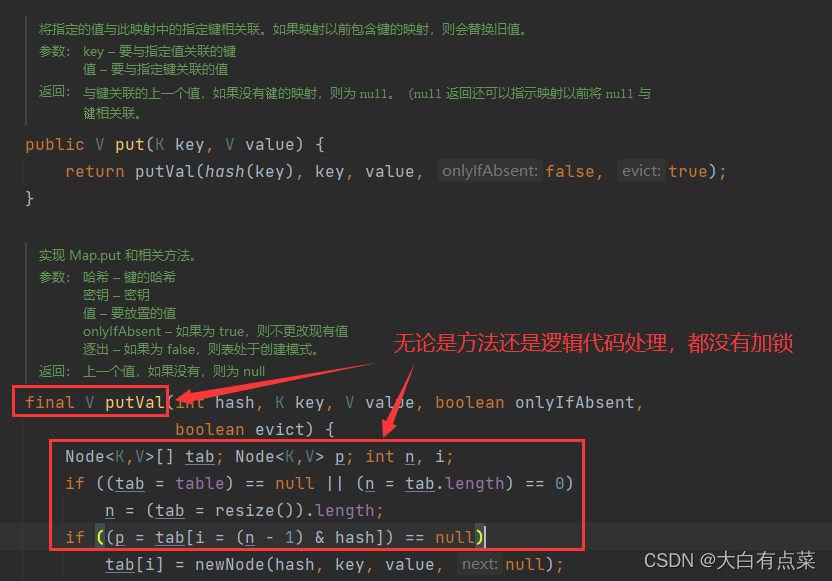
3.1.3 安全性不同
(1)HashMap 线程不安全。无论是方法还是逻辑代码处理,都没有加锁(synchronized 关键字或 Lock)。
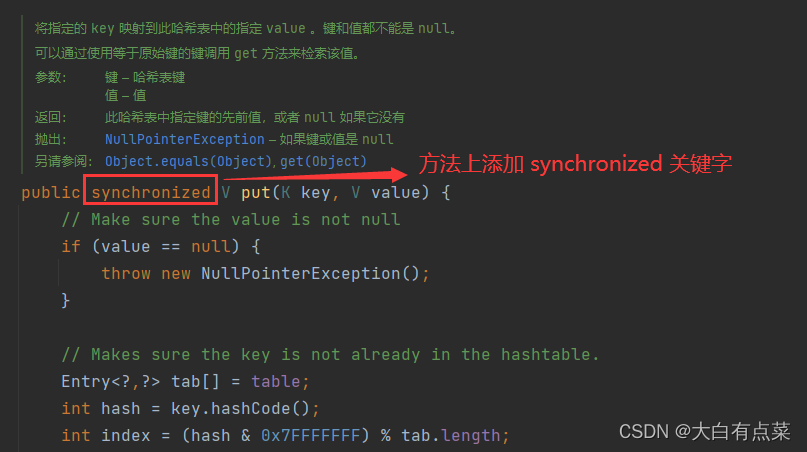
(2)Hashtable 线程安全。方法上添加了 synchronized 关键字。
3.1.4 初始容量大小不同,每次扩充容量大小不同
(1)HashMap 初始化容量为 16 ,每次扩充容量大小为原来的 2 倍。注意:通过 new HashMap() 方式创建对象时,并没有初始化容量,只有 put(K key, V value) 新增元素时,先判断 Node<K,V>[] 数组是否为 null 或者数组大小是否为 0 ,通过 resize() 方法进行容量初始化。同时 resize() 方法也用来扩容。
/**
* 构造一个具有默认初始容量 (16) 和默认加载因子 (0.75) 的空 HashMap。
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
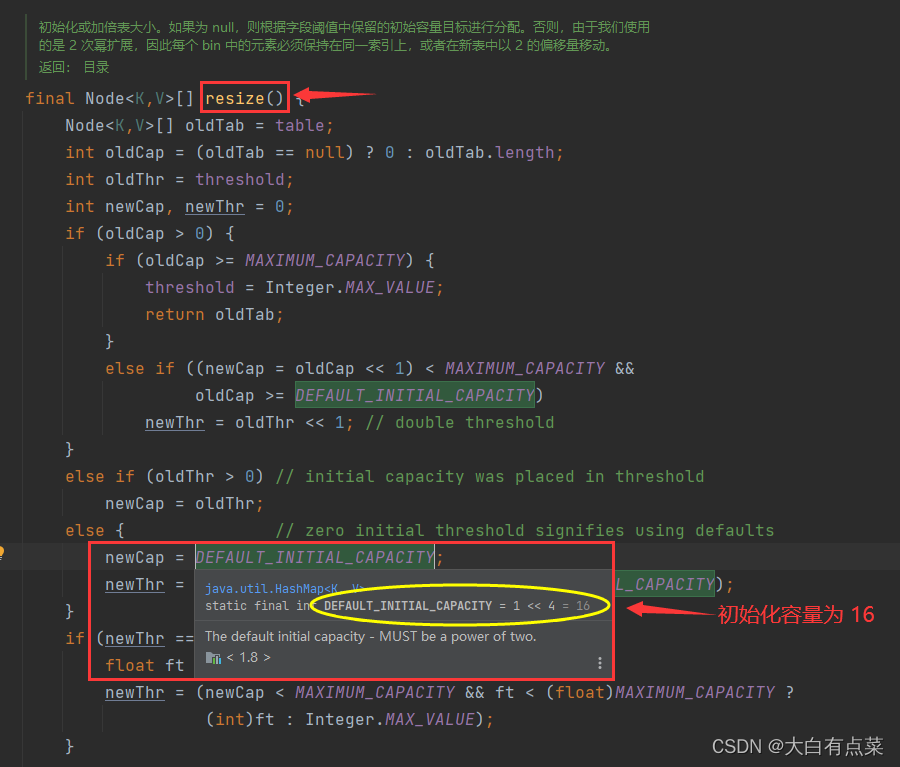
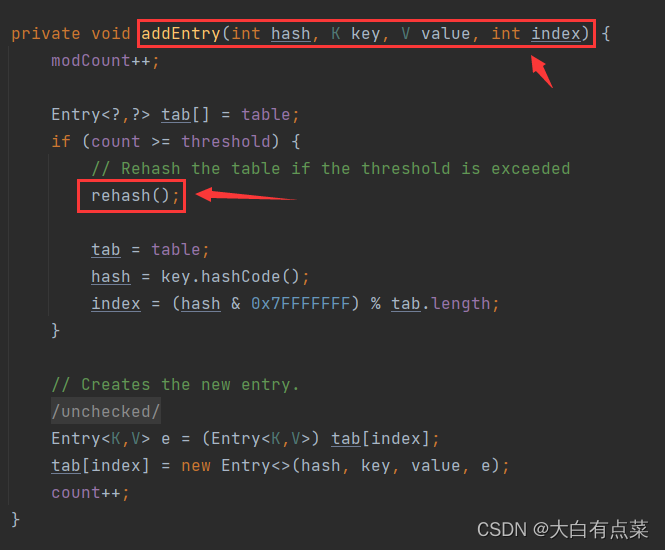
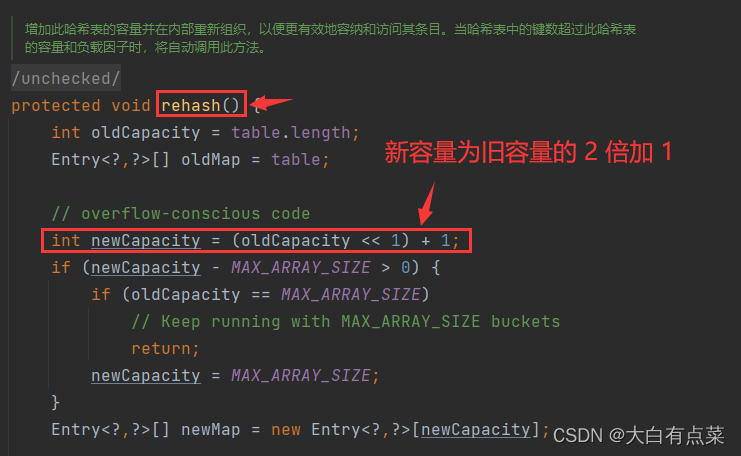
HashMap 通过 resize() 进行扩容,新容量为旧容量的2倍。
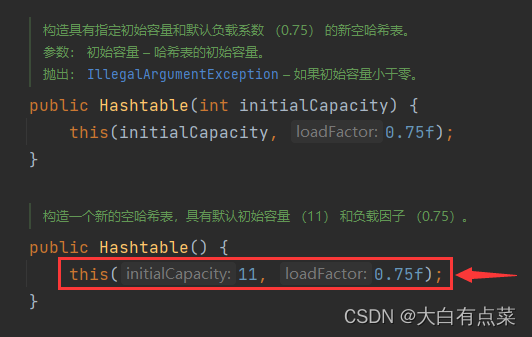
(2)Hashtable 初始化容量为 11 ,每次扩充容量大小为原来的 2 倍加 1 。注意:通过 new Hashtable() 方式创建对象,默认初始化容量为 11 。扩充容量则是在 put(K key, V value) 方法里调用 addEntry(int hash, K key, V value, int index) 方法,addEntry() 方法里面再调用 rehash() 方法。
/**
* 构造具有指定初始容量和默认负载系数 (0.75) 的新空 HashMap
*
* 参数:initialCapacity 哈希表的初始容量
* 抛出异常:IllegalArgumentException 如果初始容量小于零
*/
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
/**
* 构造一个具有默认初始容量 (11) 和默认加载因子 (0.75) 的空 HashMap
*/
public HashMap() {
this(11, 0.75f);
}
3.1.5 计算 Hash 值的方法不同
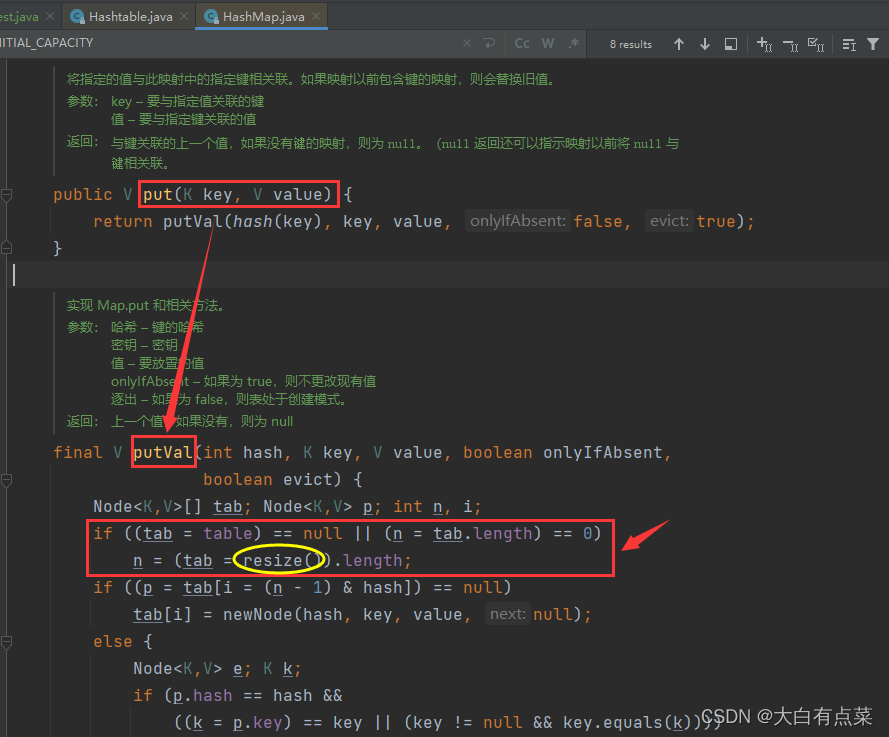
(1)HashMap 通过 hash(Object key) 方法进行计算 Hash 值:(h = key.hashCode()) ^ (h >>> 16)。当新增数据 put(K key, V value) 时,实际调用 putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) 方法,入参包含一个 int 类型的 hash 值。
/**
* 将指定的值与此映射中的指定键相关联。如果映射以前包含键的映射,则会替换旧值。
* 参数:
* key – 要与指定值关联的键
* value – 要与指定键关联的值
* 返回:与键关联的上一个值,如果没有键的映射,则为 null。(null 返回还可以指示映射以前将 null 与键相关联。
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* 计算 key.hashCode() 并将散列的高位散布 (XOR) 到低位。
* 由于该表使用二次方掩码,因此仅在当前掩码以上的位上有所不同的散列集将始终发生冲突。
* (在已知的例子中有一组 Float 键在小表中保存连续的整数。)
* 所以我们应用一个转换来向下传播较高位的影响。 在位扩展的速度、效用和质量之间存在权衡。
* 因为许多常见的哈希集已经合理分布(因此不会从传播中受益),
* 并且因为我们使用树来处理 bins 中的大量冲突,
* 所以我们只是以最便宜的方式对一些移位的位进行 XOR 以减少系统损失,
* 以及合并最高位的影响,否则由于表边界而永远不会在索引计算中使用这些位。
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
(2)当新增数据 put(K key, V value) 时,Hashtable 通过 Object 类的 hashCode() 方法进行计算 Hash 值:key.hashCode()。
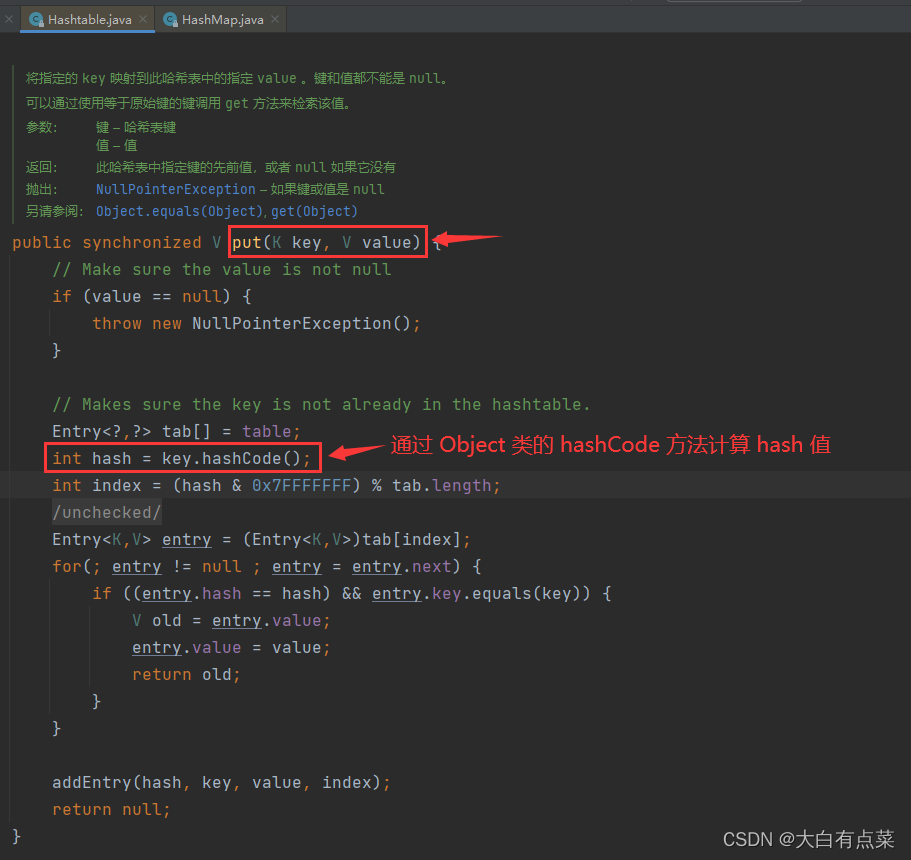
3.1.6 fail-fast 机制不同
HashMap 是 fail-fast 的,但 Hashtable 不是。
3.2 说说 HashMap 和 TreeMap 的区别
HashMap 和 TreeMap 都存在 java.util 包下。
3.2.1 两者父类相同,接口实现有相同也有不同
(1)HashMap 继承自 AbstractMap 类,实现 Map、Cloneable、Serializable 三个接口。父类和 TreeMap 一致。
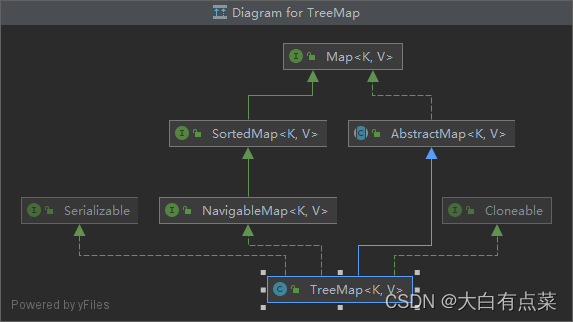
(2)TreeMap 继承自 AbstractMap 类,实现 NavigableMap、Cloneable、Serializable 三个接口。因为 NavigableMap 接口继承 SortedMap 接口,而 SortedMap 接口最终继承 Map 接口,所以 TreeMap 和 HashMap 会存在一些共同的实现方法(来自 Map 接口)。父类和 HashMap 一致,底层基于红黑树实现。
3.2.2 对 Null 支持不同
(1)HashMap 允许存储 一个空键(Null Key)和 任意数量的空值(Null Value)。
【示例代码:HashMapTest】
public class HashMapTest {
public static void main(String[] args) {
Map<String, String> hashMap = new HashMap<>(16);
hashMap.put(null, "大白有点菜1");
hashMap.put(null, "大白有点菜2");
System.out.println(hashMap.get(null));
hashMap.put(null, null);
hashMap.put(null, null);
System.out.println(hashMap.get(null));
System.out.println("HashMap的个数:" + hashMap.size());
}
}
【HashMapTest运行结果】
大白有点菜2
null
HashMap的个数:1
(2)TreeMap 不允许存储 空键(Null Key),但允许存储 多个空值(Null Value)。
【示例代码:HashMapTest】
public class HashMapTest {
public static void main(String[] args) {
Map<String, String> treeMap = new TreeMap<>();
treeMap.put(null, "大白有点菜");
System.out.println(treeMap.get(null));
treeMap.put("dbydc", null);
System.out.println(treeMap.get("dbydc"));
}
}
【HashMapTest两种运行结果】
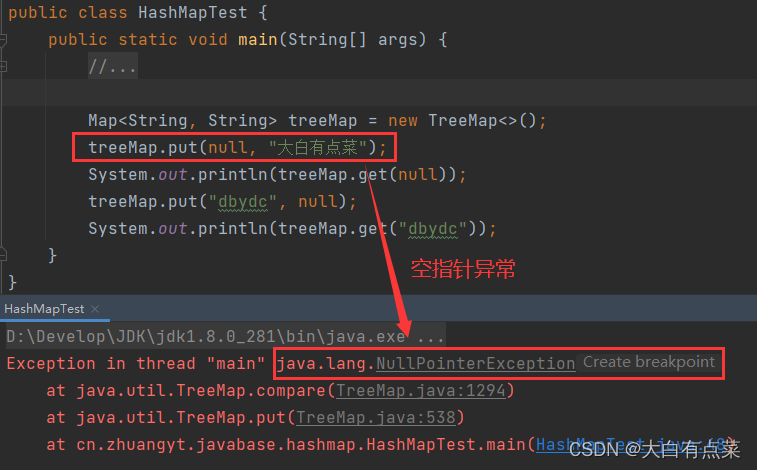
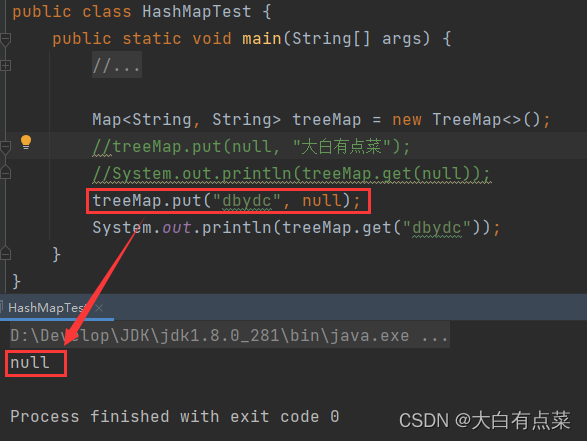
TreeMap 存储 Null 键 才会报空指针异常(NullPointerException)。由源码中 TreeMap 的 put(K key, V value) 方法可以看出,我们在 new TreeMap() 创建对象的时候,Comparator 的对象 comparator 初始化为 null 。新增元素时,comparator 指向新的 cpr 对象,所以 cpr = null ,会执行 else 条件里面的代码。由于 key = null ,所以直接抛出 NullPointerException。 如图所示:

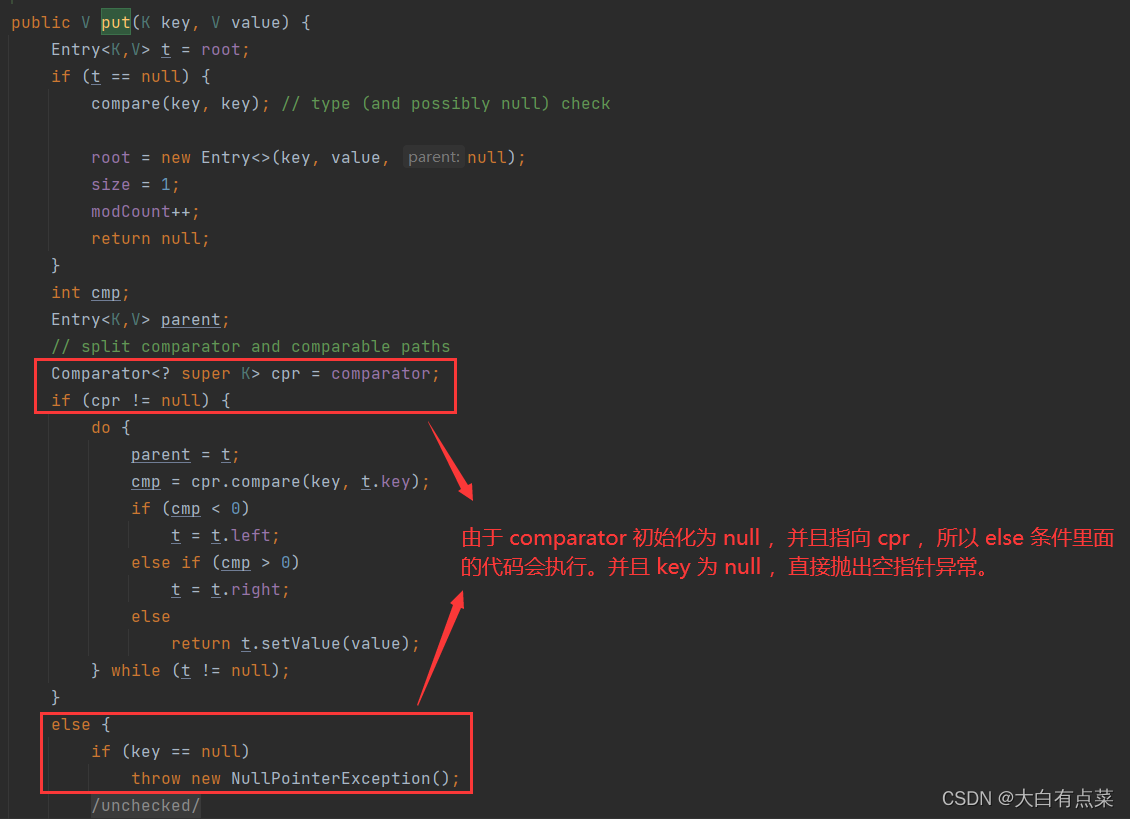
3.2.3 都是线程不安全的
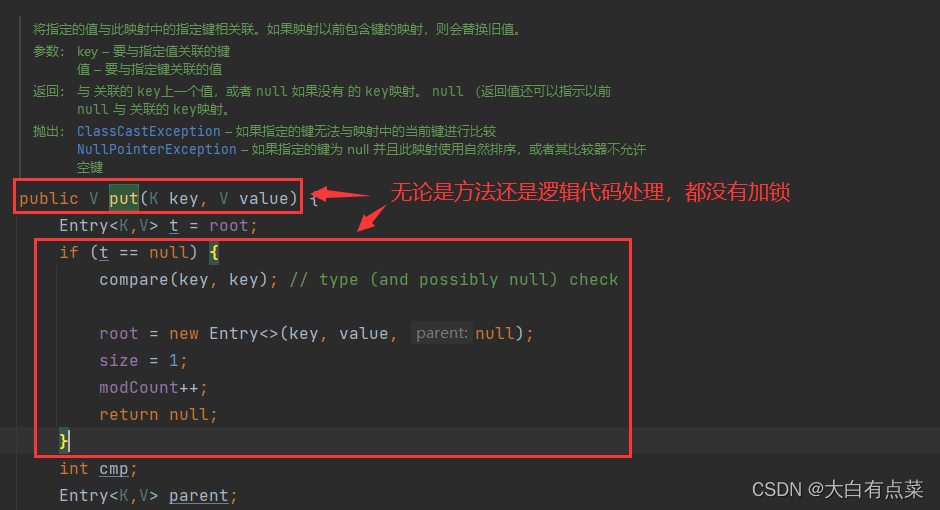
(1)HashMap 线程不安全。无论是方法还是逻辑代码处理,都没有加锁(synchronized 关键字或 Lock)。
(2)TreeMap 线程不安全。无论是方法还是逻辑代码处理,都没有加锁(synchronized 关键字或 Lock)。
3.2.4 都不支持重复键
HashMap 和 TreeMap 都不支持重复键(Key)。如果添加相同的 Key ,那么后入的元素会覆盖前面的元素。
3.2.5 有序性不同
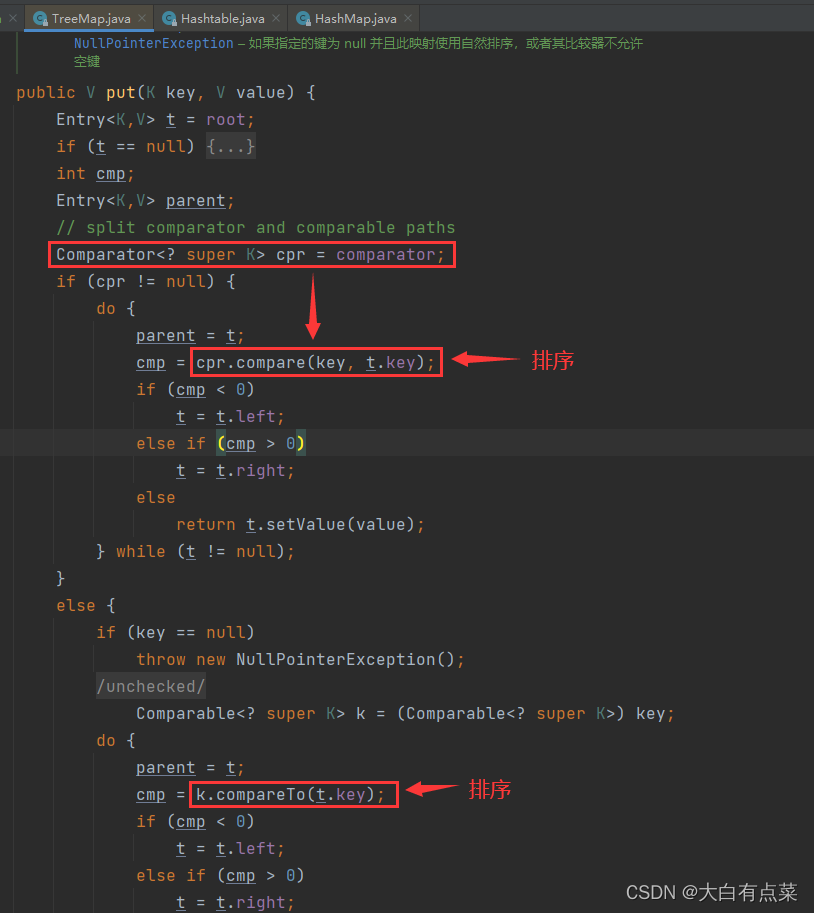
HashMap 底层基于哈希表实现,不提供元素在 Map 中的排列方式的任何保证,它是无序的。
而 TreeMap 底层基于红黑树实现,它是有序的,具体的排序方式通过 Comparator 的 compare() 方法或 compareTo() 方法来实现,如图所示。
3.2.6 都是 fail-fast
HashMap 和 TreeMap 都是 fail-fast 的。
3.3 说说 HashMap 和 ConcurrentHashMap 的区别
HashMap 存在 java.util 包下,但 ConcurrentHashMap 存在 java.util.concurrent 并发包下,从 JDK 1.5 开始存在,由 Doug Lea 大神实现 ConcurrentHashMap 类。
3.3.1 两者父类相同,接口实现有相同也有不同
(1)HashMap 继承自 AbstractMap 类,实现 Map、Cloneable、Serializable 三个接口。父类和 TreeMap 一致。
(2)ConcurrentHashMap 继承自 AbstractMap 类,实现 ConcurrentMap、Serializable 两个接口。因为 ConcurrentMap 接口继承 Map 接口,所以 ConcurrentHashMap 和 HashMap 会存在一些共同的实现方法(来自 Map 接口)。父类和 HashMap 一致。
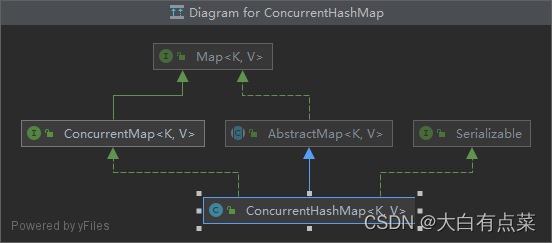
3.3.2 对 Null 支持不同
(1)HashMap 允许存储 一个空键(Null Key)和 任意数量的空值(Null Value)。
【示例代码:HashMapTest】
public class HashMapTest {
public static void main(String[] args) {
Map<String, String> hashMap = new HashMap<>(16);
hashMap.put(null, "大白有点菜1");
hashMap.put(null, "大白有点菜2");
System.out.println(hashMap.get(null));
hashMap.put(null, null);
hashMap.put(null, null);
System.out.println(hashMap.get(null));
System.out.println("HashMap的个数:" + hashMap.size());
}
}
【HashMapTest运行结果】
大白有点菜2
null
HashMap的个数:1
(2)ConcurrentHashMap 不允许存储 空键(Null Key)和 空值(Null Value)。
【示例代码:HashMapTest】
public class HashMapTest {
public static void main(String[] args) {
Map<String, String> concurrentHashMap = new ConcurrentHashMap<>(16);
concurrentHashMap.put(null, "大白有点菜");
System.out.println(concurrentHashMap.get(null));
concurrentHashMap.put("dbydc", null);
System.out.println(concurrentHashMap.get("dbydc"));
}
}
【HashMapTest两种运行结果】
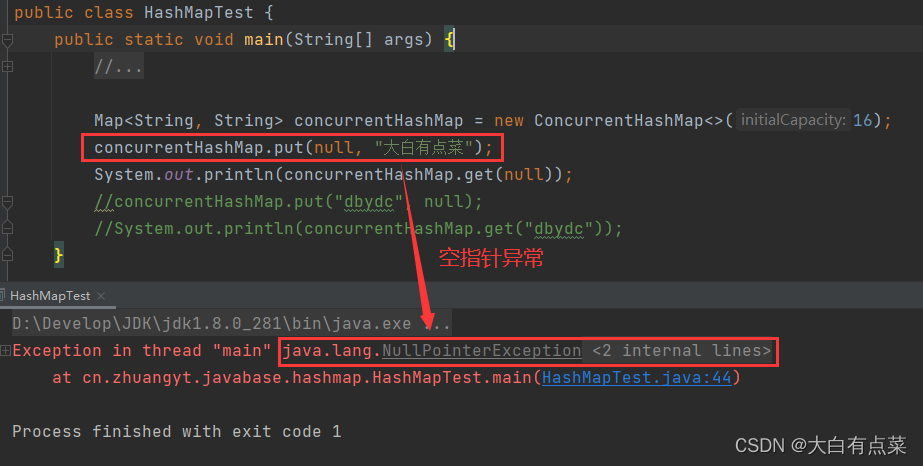
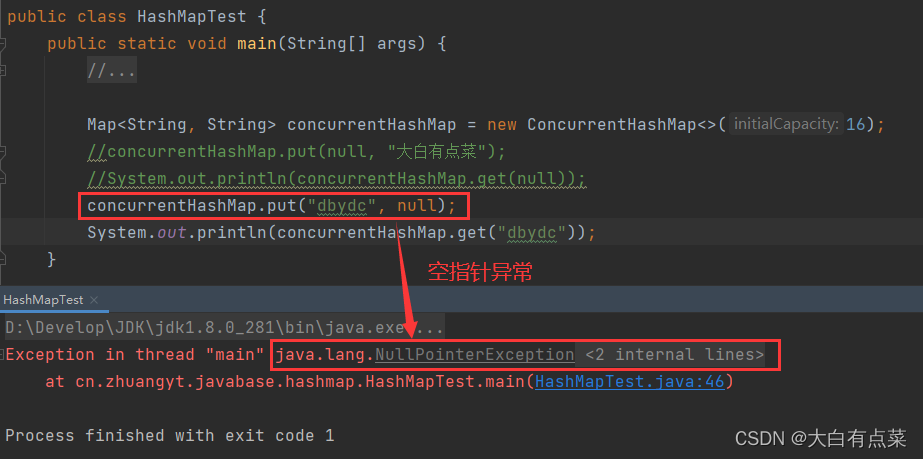
ConcurrentHashMap 无论是存储 Null 键 还是 Null 值 都会报空指针异常(NullPointerException)。由源码中 ConcurrentHashMap 的 putVal(K key, V value, boolean onlyIfAbsent) 方法可以看出,当 key = null 或者 value = null 时,直接抛出 NullPointerException。 如图所示:
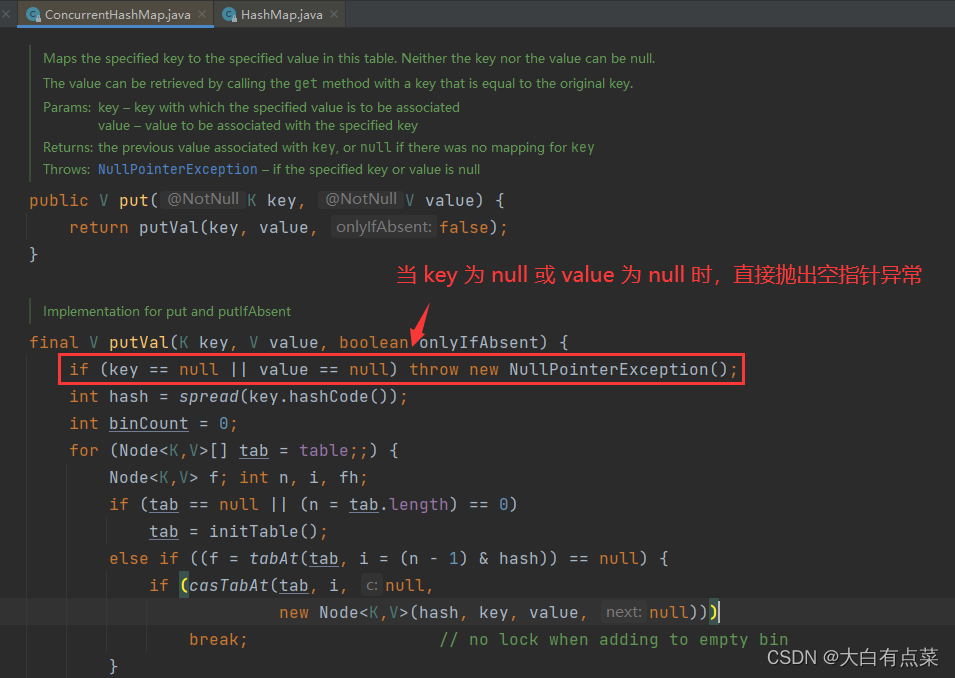
3.3.3 安全性不同
(1)HashMap 线程不安全。无论是方法还是逻辑代码处理,都没有加锁(synchronized 关键字或 Lock)。
(2)ConcurrentHashMap 线程安全。在 JDK 1.8 中,ConcurrentHashMap 的 putVal(K key, V value, boolean onlyIfAbsent) 方法中使用 synchronized 代码块和 CAS 组合方式实现并发安全地插入数据。
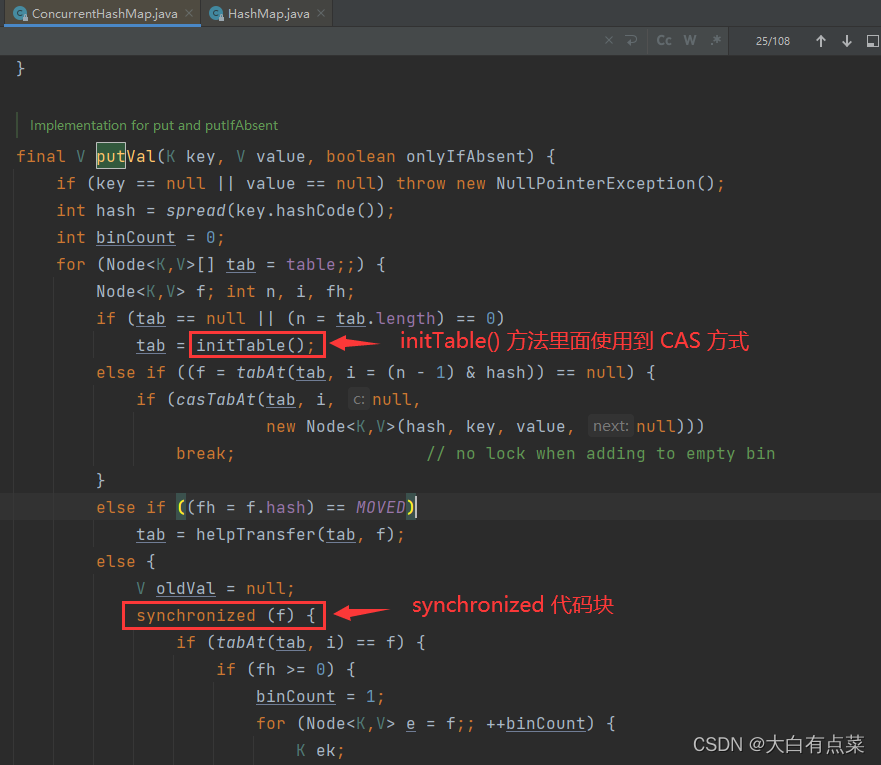

3.3.4 计算 Hash 值的方法不同
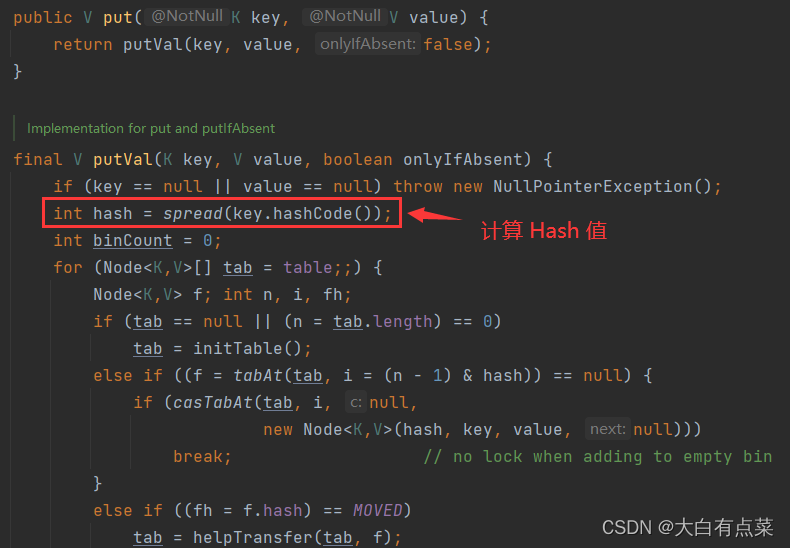
(1)HashMap 通过 hash(Object key) 方法进行计算 Hash 值:(h = key.hashCode()) ^ (h >>> 16)。当新增数据 put(K key, V value) 时,实际调用 putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) 方法,入参包含一个 int 类型的 hash 值。
/**
* 将指定的值与此映射中的指定键相关联。如果映射以前包含键的映射,则会替换旧值。
* 参数:
* key – 要与指定值关联的键
* value – 要与指定键关联的值
* 返回:与键关联的上一个值,如果没有键的映射,则为 null。(null 返回还可以指示映射以前将 null 与键相关联。
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* 计算 key.hashCode() 并将散列的高位散布 (XOR) 到低位。
* 由于该表使用二次方掩码,因此仅在当前掩码以上的位上有所不同的散列集将始终发生冲突。
* (在已知的例子中有一组 Float 键在小表中保存连续的整数。)
* 所以我们应用一个转换来向下传播较高位的影响。 在位扩展的速度、效用和质量之间存在权衡。
* 因为许多常见的哈希集已经合理分布(因此不会从传播中受益),
* 并且因为我们使用树来处理 bins 中的大量冲突,
* 所以我们只是以最便宜的方式对一些移位的位进行 XOR 以减少系统损失,
* 以及合并最高位的影响,否则由于表边界而永远不会在索引计算中使用这些位。
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
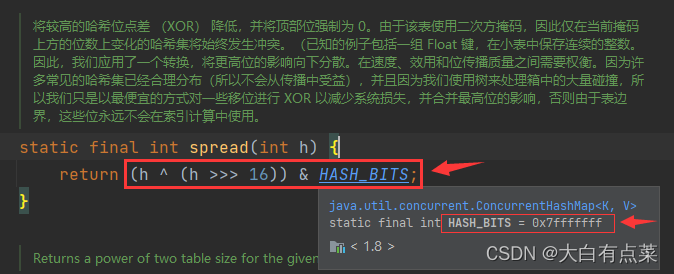
(2)当新增数据 put(K key, V value) 时,ConcurrentHashMap 通过 spread(int h) 方法,入参 h 是 Object 类的 hashCode() 方法计算 Hash 值后,再进行其它位移、异或和“&”一个常量 HASH_BITS(值为 0x7fffffff)得出最后的 Hash 值:(h ^ (h >>> 16)) & HASH_BITS。
3.4 说说 Hashtable 和 ConcurrentHashMap 两者的性能和锁区别
前面已经分析 HashMap、Hashtable 和 ConcurrentHashMap 之间的区别,这里主要介绍 Hashtable 和 ConcurrentHashMap 的性能和用到的锁的区别。
3.4.1 ConcurrentHashMap 并发性能比 Hashtable 并发性能好
Hashtable 通过在方法上添加 synchronized 来实现线程安全,这是重量级锁,锁粒度大,通过 JVM 层面来实现加锁和释放锁。synchronized 在 JVM 的实现原理:JVM 基于进入和退出 Monitor 对象来实现方法同步和代码块同步。代码块同步使用 monitorenter 和 monitorexit 指令实现。而方法同步是使用另外一种方式实现的,细节在 JVM 规范里并没有详细说明,方法的同步同样可以使用 monitorenter 和 monitorexit 指令来实现。【出处:《Java并发编程的艺术》】
synchronized 加锁过程会把对象锁住,当一个同步方法获得了对象锁后,这个对象上的其它同步方法都会被阻塞,也就大大降低了并发操作的效率。
为了解决 Hashtable 使用的锁粒度太大的问题,在 JDK 1.8 之前,ConcurrentHashMap 采用分段锁(Segment,默认数组大小为 16 )来降低锁的冲突,提升性能,即 HashEntry + Segment。在 JDK 1.8 之后,优化为使用 synchronized 代码块和 CAS 方式进一步提升性能,即 Node + synchronized + CAS。
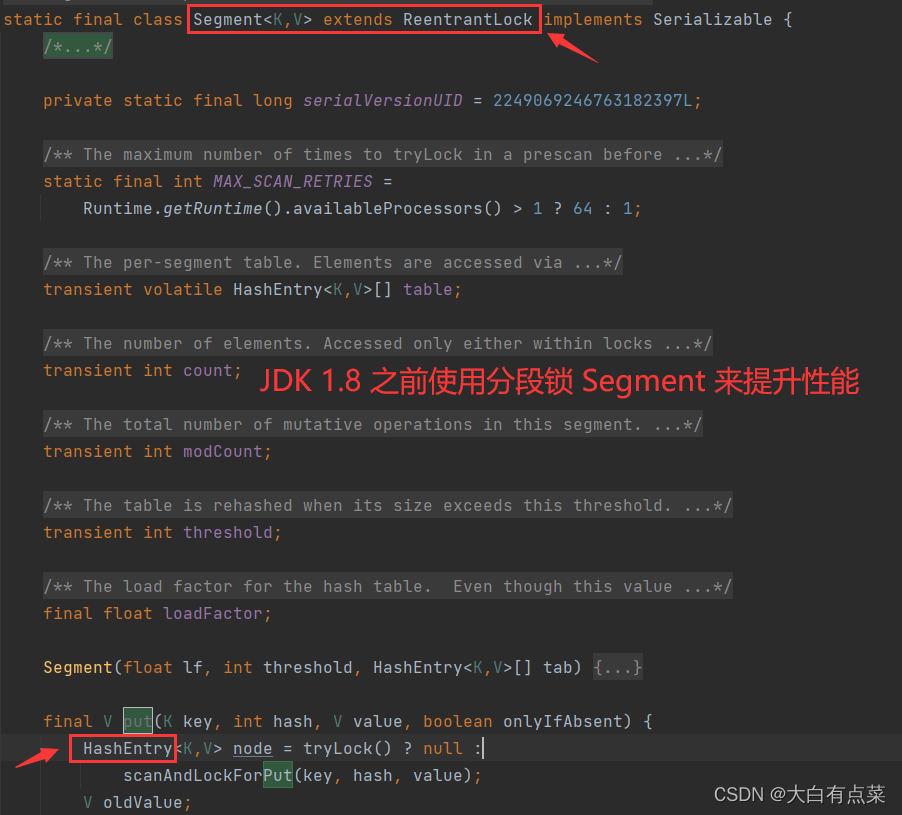
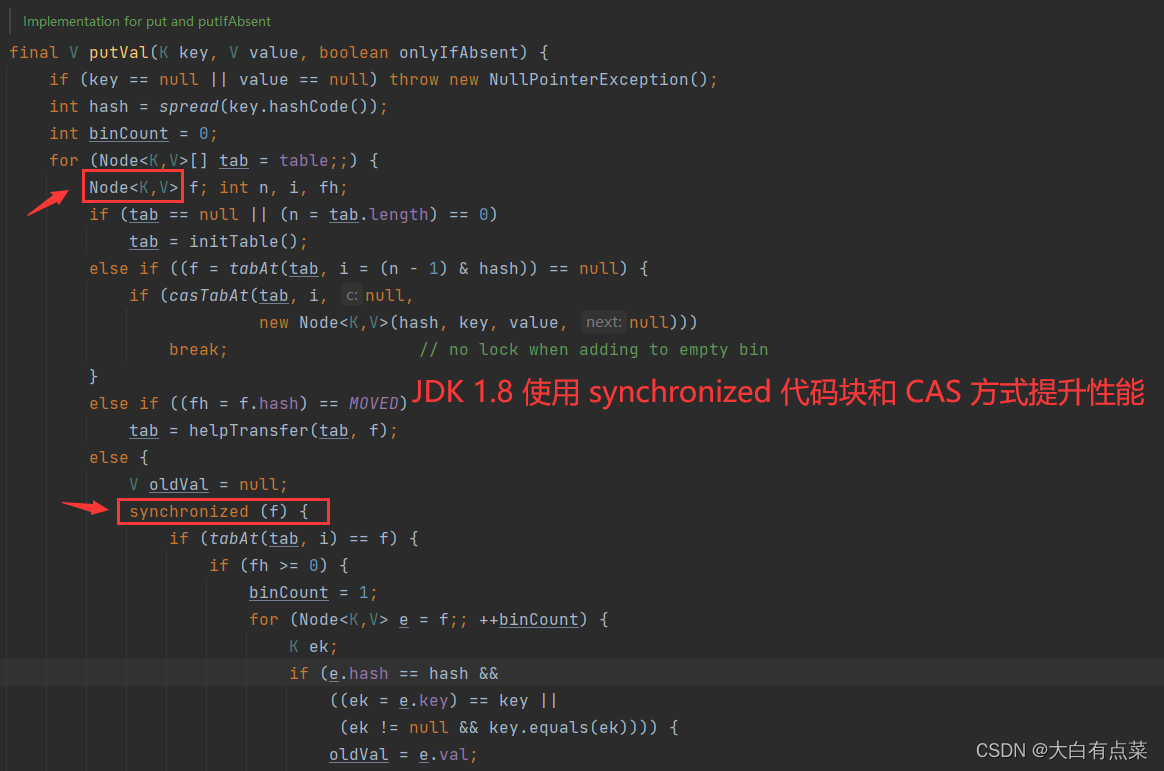
ConcurrentHashMap 把数据分成多个段(Segment)进行存储(默认为 16 个),然后给每一段的数据单独加锁,当一个线程占用锁访问其中一个段(Segment)的数据时,其它段(Segment)的数据可以被其它线程访问。
3.4.2 ConcurrentHashMap 和 Hashtable 的锁的区别
Hashtable 的 put(K key, V value) 和 get(Object key) 等方法上使用 synchronized 锁。而 ConcurrentHashMap 的 put(K key, V value) 方法也使用 synchronized 锁,但只作用于部分代码块,并且使用到 CAS 方式。
3.5 说说 Hashtable、SynchronizedMap 和 ConcurrentHashMap 三者的区别
| Hashtable | SynchronizedMap | ConcurrentHashMap |
|---|---|---|
| 线程安全,锁定整个Map对象 | 线程安全,锁定整个Map对象 | 线程安全,无须锁定整个哈希表,只需要一个桶级锁 |
| 一次只允许一个线程对一个Map对象执行操作 | 一次只允许一个线程对一个Map对象执行操作 | 同时允许多个线程安全地操作Map对象 |
| 读和写操作都需要加锁 | 读和写操作都需要加锁 | 读操作可以不加锁 |
| 当一个线程迭代Map对象时,其它线程不允许修改,否则报ConcurrentModificationException异常 | 当一个线程迭代Map对象时,其它线程不允许修改,否则报ConcurrentModificationException异常 | 当一个线程迭代Map对象时,另一个线程被允许修改,不会报ConcurrentModificationException异常 |
| 键(Key)和值(Value)不允许为Null | 键(Key)和值(Value)都允许为Null | 键(Key)和值(Value)不允许为Null |
| 在Java 1.0引入 | 在Java 1.2引入 | 在Java 1.5引入 |
3.6 HashMap 的 size 和 capacity 有什么区别
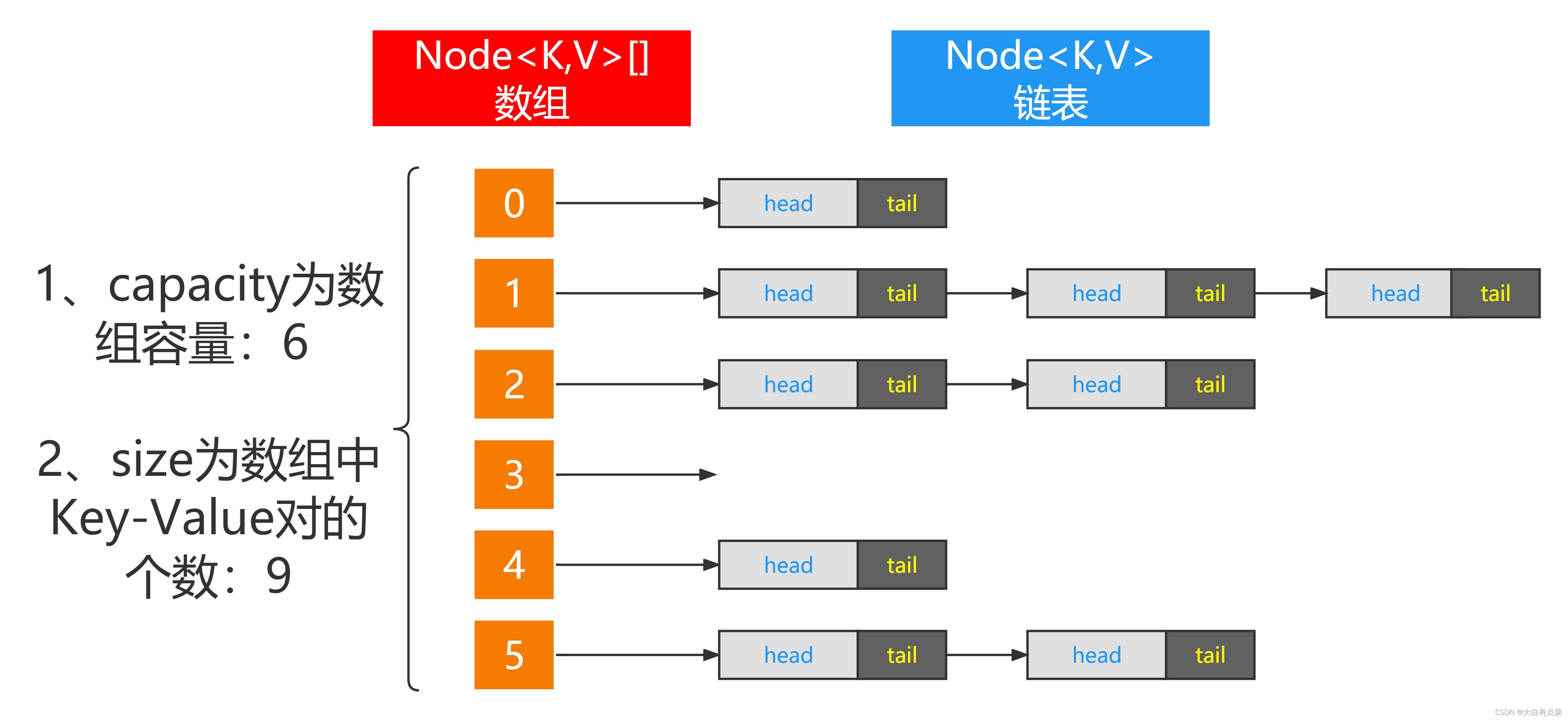
- size:记录 Map 中 Key-Value 对的个数。
/**
* The number of key-value mappings contained in this map.
* 此映射中包含的键值映射数。
*/
transient int size;
- capacity:容量。数组的个数,如果不指定,则默认为 16 。
/**
* The default initial capacity - MUST be a power of two.
* 默认初始容量 - 必须是 2 的幂。
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
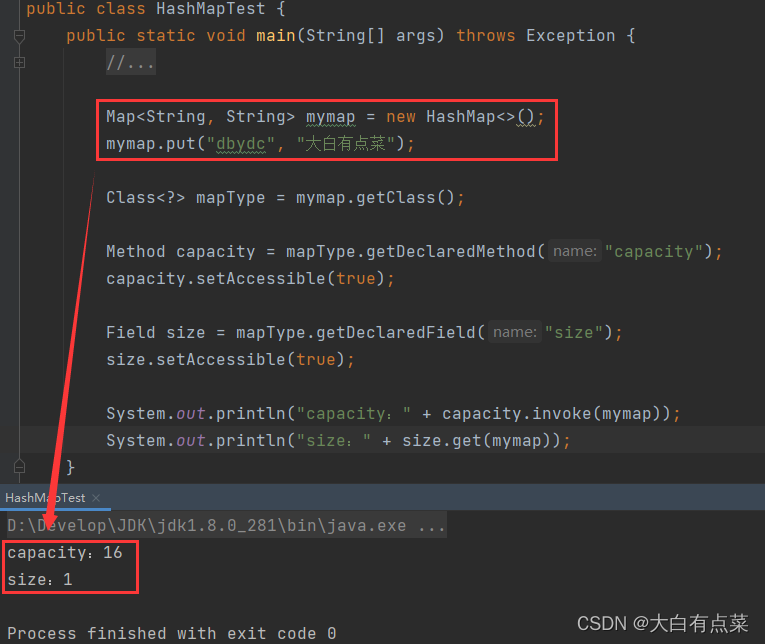
写个样例获取 HashMap 中 capacity 和 size 的值。代码如下:
public class HashMapTest {
public static void main(String[] args) throws Exception {
Map<String, String> mymap = new HashMap<>();
mymap.put("dbydc", "大白有点菜");
Class<?> mapType = mymap.getClass();
Method capacity = mapType.getDeclaredMethod("capacity");
capacity.setAccessible(true);
Field size = mapType.getDeclaredField("size");
size.setAccessible(true);
System.out.println("capacity:" + capacity.invoke(mymap));
System.out.println("size:" + size.get(mymap));
}
}
运行结果:
3.7 可以使用任何类作为 HashMap 的 Key 吗
我们平时最多使用 String 作为 HashMap 的 Key ,如果想使用自定义的类作为 Key ,需要注意几点:
- 如果类重写了 equals 方法,它也应该重写 hashCode 方法。
- 类的所有实例需要遵循与 equals 和 hashCode 相关的规则。
- 如果一个类没有使用 equals,你不应该在 hashCode 中使用它。
- 自定义 Key 类的最佳实践是使之为不可变的,hashCode 值可以被缓存起来,拥有更好的性能。不可变的类也可以确保 hashCode 和 equals 在未来不会改变,这样就会解决与可变相关的问题了。
3.8 HashMap 的长度为什么是 2 的 N 次方呢
为了让 HashMap 存和取数据的效率高,尽可能地减少 Hash 值的碰撞,尽量把数据均匀地分配,每个链表或者红黑树长度尽量相等,“取模(%)”操作可以实现。
“取模(%)”操作中,如果被除数是 2 的幂次,则等价于其被除数减一的“与(&)”操作,公式表达为:hash % length == hash & (length - 1),前提是 length 是 2 的 n 次方。采用位运算 & 操作比取模 % 操作运算效率要高,主要原因是位运算直接对内存数据进行操作,不需要转成十进制数据,处理速度非常快。
3.9 HashMap 的扩容机制了解吗
首先抛出一个问题:HashMap 是一个数组链表,按道理来说,不扩容也可以无限存储元素,为什么还要扩容呢?
主要还是 Hash 碰撞的缘故。散列(Hash)碰撞:如果根据同一散列函数计算 两个散列值相同,那么这两个散列值的原始输入值可能相同,可能不相同。HashMap 采用 链地址法 解决 Hash 碰撞。
如果一个 HashMap 碰撞太多,那数组的链表会退化为链表,查询速度会大大降低。为了保证 HashMap 的读取速度,需要尽可能保证 HashMap 的碰撞次数不要太多。通过扩容有效避免 HashMap 碰撞。
导致 HashMap 碰撞较多的情况主要有两方面:
1、容量太小。容量小,元素碰撞的概率就高。
2、Hash 算法不合理。算法不合理,元素就有可能都分到同一个或几个数组下标的位置
解决思路:在合适的时候扩大数组容量,再通过合理的 Hash 算法将元素分配到这个数组中,既可以大大减少元素碰撞的概率,也可以避免查询效率低下的问题。
HashMap 的扩容需要达到一定的条件才会触发。threshold(容量扩容阈值) 和 loadFactor(负载因子,默认值为 0.75f) 是两个重要的成员变量,HashMap 的扩容机制就以此相关,而且 threshold = capacity * loadFactor,capacity 代表数组链表的容量。
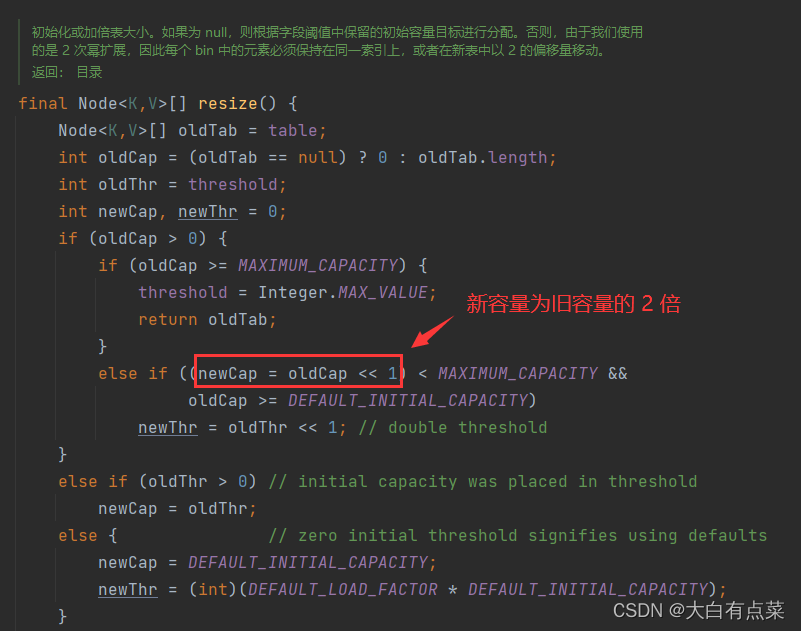
HashMap 通过 resize() 方法进行扩容,每 put(K key, V value) 一个元素时,都会判断数组链表中的 Key-Value 对的个数 size 是否大于数组容量扩容阈值 threshold,如果满足条件就进行扩容,新容量为旧容量的 2 倍。扩容之后,还需要对 HashMap 原有的元素进行重新 Hash 计算值。
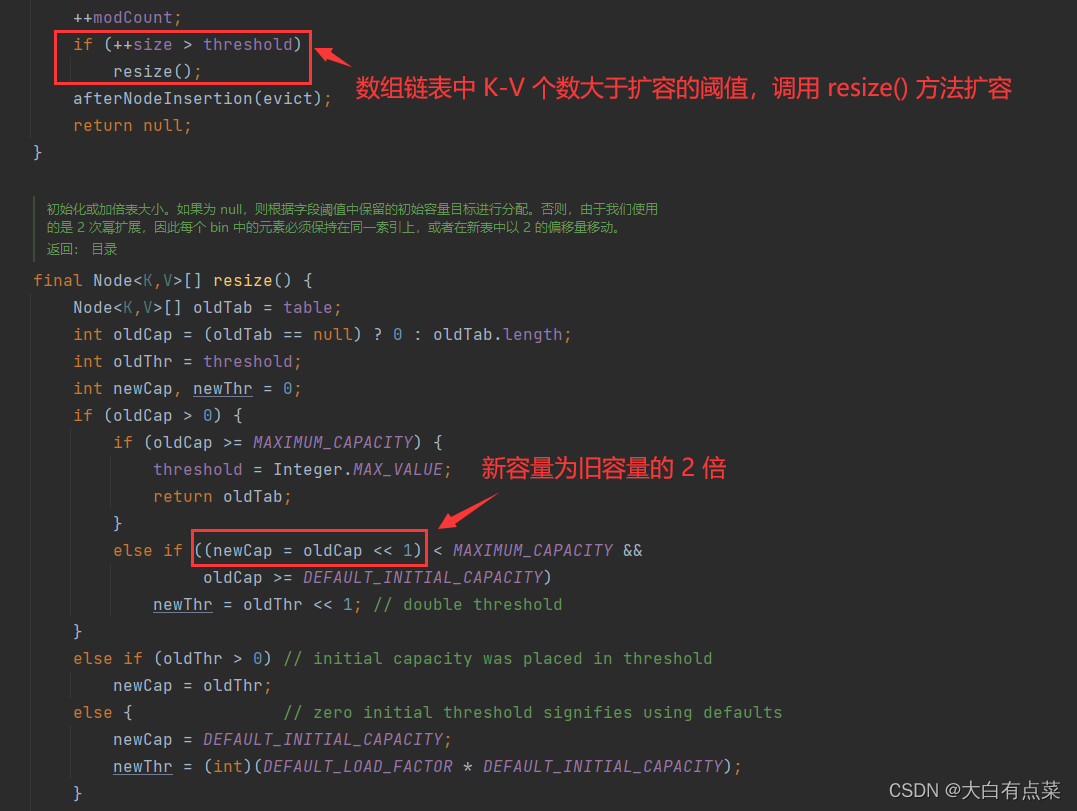
对于默认的 HashMap 来说(默认容量 16 ),默认情况下(默认负载因子 0.75 ),当 size 大于 12 (16 x 0.75 = 12)时触发扩容。验证代码如下:
public class HashMapTest {
public static void main(String[] args) throws Exception {
Map<String, String> map = new HashMap<>();
//只插入 12 个元素,刚好等于默认的扩容阈值 12
for (int i = 1; i < 13; i++) {
map.put("dbydc" + i, "大白有点菜" + i);
}
System.out.println("----------分割线1----------");
Class<?> mapType = map.getClass();
Method capacity1 = mapType.getDeclaredMethod("capacity");
capacity1.setAccessible(true);
System.out.println("capacity:" + capacity1.invoke(map));
Field size1 = mapType.getDeclaredField("size");
size1.setAccessible(true);
System.out.println("size:" + size1.get(map));
Field threshold1 = mapType.getDeclaredField("threshold");
threshold1.setAccessible(true);
System.out.println("threshold:" + threshold1.get(map));
Field loadFactor1 = mapType.getDeclaredField("loadFactor");
loadFactor1.setAccessible(true);
System.out.println("loadFactor:" + loadFactor1.get(map));
System.out.println("----------分割线2----------");
map.put("dbydc13", "大白有点菜13"); //再插入一个元素,超过了默认的扩容阈值 12
Method capacity2 = mapType.getDeclaredMethod("capacity");
capacity2.setAccessible(true);
System.out.println("capacity:" + capacity2.invoke(map));
Field size2 = mapType.getDeclaredField("size");
size2.setAccessible(true);
System.out.println("size:" + size2.get(map));
Field threshold2 = mapType.getDeclaredField("threshold");
threshold2.setAccessible(true);
System.out.println("threshold:" + threshold2.get(map));
Field loadFactor2 = mapType.getDeclaredField("loadFactor");
loadFactor2.setAccessible(true);
System.out.println("loadFactor:" + loadFactor2.get(map));
}
}
运行结果如下:
----------分割线1----------
capacity:16
size:12
threshold:12
loadFactor:0.75
----------分割线2----------
capacity:32
size:13
threshold:24
loadFactor:0.75
由结果可以看出,当 HashMap 中的元素个数 size 达到 13 时,capacity 由 16 变成 32 了。
HashMap 提供一个支持传入 initialCapacity 和 loadFactor 的构造函数来初始化容量和负载因子。不建议修改 loadFactor 的值,为什么呢?后面会解释。构造函数如下:
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and load factor.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
3.10 为什么 HashMap 的负载因子(loadFactory)默认设置成 0.75f
HashMap 的扩容机制离不开 负载因子(loadFactory),在类中是一个静态常量:static final float DEFAULT_LOAD_FACTOR = 0.75f; 为什么要设置这个默认值呢?可以随便修改吗?
在 JDK 1.8 官方文档中有这么一段描述(https://docs.oracle.com/javase/8/docs/api/index.html):
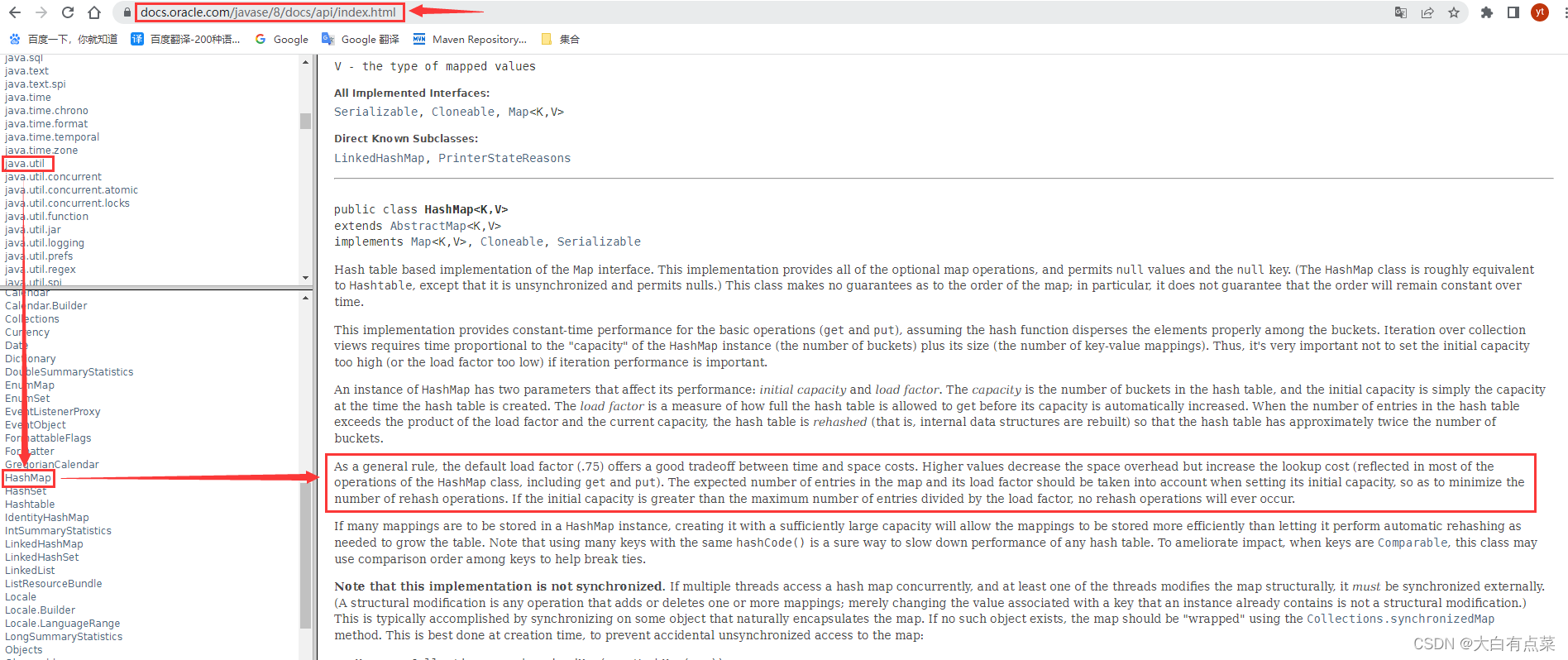
As a general rule, the default load factor (.75) offers a good tradeoff between time and space costs. Higher values decrease the space overhead but increase the lookup cost (reflected in most of the operations of the HashMap class, including get and put). The expected number of entries in the map and its load factor should be taken into account when setting its initial capacity, so as to minimize the number of rehash operations. If the initial capacity is greater than the maximum number of entries divided by the load factor, no rehash operations will ever occur.
作为一般规则,默认加载因子 (0.75) 提供了时间和空间成本之间的良好的权衡。 较高的值会减少空间开销,但会增加查找成本(反映在 HashMap 类的大多数操作中,包括 get 和 put)。 在设置其初始容量时应考虑映射中预期的条目数及其负载因子,以尽量减少重新哈希操作的次数。 如果初始容量大于最大条目数除以负载因子,则不会发生重新散列操作。【谷歌翻译】
如果把负载因子(loadFactory) 设置为 1 ,容量默认初始大小为 16 ,那么表示一个 HashMap 需要在容量满了之后才会进行扩容。
在 HashMap 中,最好的情况是 16 个元素通过 Hash 函数计算后分别落到对应的 16 个不同数组下标位置,否则必然发生 Hash 碰撞。而且随着元素越多,Hash 碰撞的概率越大,查找速度也会越低。
0.75 的数学依据:非JDK官方文档体现,只是 StackOverflow 上一个问题,网友的数学推论。推论过程如图所示(绿色背景中文使用谷歌翻译工具翻译)。网址:https://stackoverflow.com/questions/10901752/what-is-the-significance-of-load-factor-in-hashmap
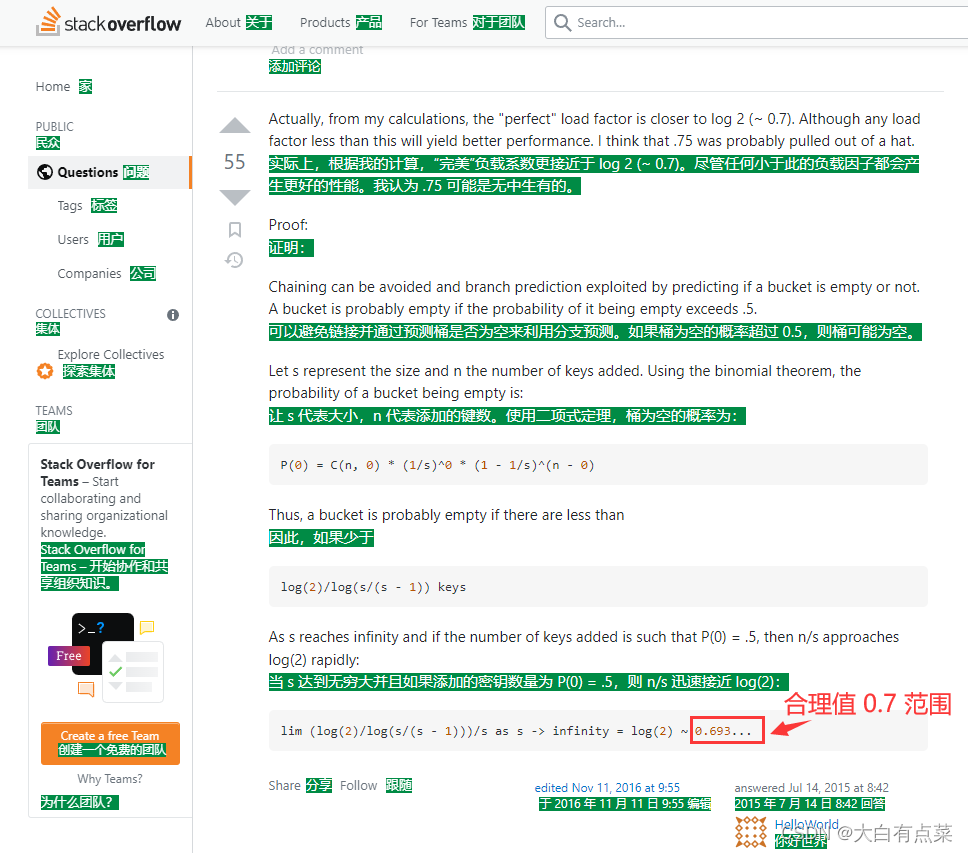
理论上 负载因子(loadFactory)不能太大,不然会导致大量的 Hash 碰撞,也不能太小,那样会频繁扩容而浪费空间。0.75 为什么更合理呢?
根据 HashMap 的扩容机制,capacity(容量)是 2 的幂。为了保证 负载因子(loadFactory)x 容量(capacity) 的结果是一个整数,这个 0.75 值(即3/4) 更加合理,因为这个数和任何的2的幂的乘积结果都是整数。可以修改 负载因子(loadFactory) 的值,但不建议。
3.11 为什么建议集合初始化时指定容量大小
Java 集合类中的 ArrayList、HashMap 等,在初始化时可以指定容量。

那为什么建议集合初始化时指定容量大小呢?其实是为了提高性能。我们写个样例来验证一下,采用 JMH 微基准测试工具来测试。如果有兴趣,可以查阅我这个系列文章:《性能调优之JMH必知必会3:编写正确的微基准测试用例》。
package cn.zhuangyt.javabase.hashmap;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.TimeUnit;
/**
* HashMap的容量未初始化和指定容量初始化性能测试
* @author 大白有点菜
* @className HashMapJmhTest
* @date 2023-05-14
* @description
* @since 1.0
**/
@BenchmarkMode(Mode.AverageTime)
@Warmup(iterations = 5)
@Measurement(iterations = 5)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@State(Scope.Thread)
public class HashMapJmhTest {
/**
* 元素个数
*/
private final int COUNT = 10000000;
/**
* 没有初始化HashMap容量
*/
@Benchmark
public Map<String, String> noInitialHashMapCapacity() {
Map<String, String> map = new HashMap<>();
for (int i = 1; i <= COUNT; i++) {
map.put("dbydc" + i, "大白有点菜");
}
return map;
}
/**
* 初始化HashMap容量 5000000
*/
@Benchmark
public Map<String, String> initialHashMap5000000Capacity() {
Map<String, String> map = new HashMap<>(COUNT >> 1);
//Map<String, String> map = new HashMap<>(1 << 22); //1 << 22 即是 4194304
for (int i = 1; i <= COUNT; i++) {
map.put("dbydc" + i, "大白有点菜");
}
return map;
}
/**
* 初始化HashMap容量 10000000
*/
@Benchmark
public Map<String, String> initialHashMap10000000Capacity() {
Map<String, String> map = new HashMap<>(COUNT);
//Map<String, String> map = new HashMap<>(1 << 23); //1 << 23 即是 8388608
//Map<String, String> map = new HashMap<>(1 << 24); //1 << 24 即是 16777216
for (int i = 1; i <= COUNT; i++) {
map.put("dbydc" + i, "大白有点菜");
}
return map;
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(HashMapJmhTest.class.getSimpleName())
.forks(1)
.build();
new Runner(opt).run();
}
}
HashMapJmhTest 运行结果如下:
Benchmark Mode Cnt Score Error Units
HashMapJmhTest.initialHashMap10000000Capacity avgt 5 2757766.439 ± 1458852.513 us/op
HashMapJmhTest.initialHashMap5000000Capacity avgt 5 2256201.404 ± 705114.516 us/op
HashMapJmhTest.noInitialHashMapCapacity avgt 5 2485808.481 ± 901925.036 us/op
分析运行结果,发现往 HashMap 中插入 10000000 个元素,性能最好的是 initialHashMap5000000Capacity() 方法,容量初始化为 5000000 。没有初始化容量的 noInitialHashMapCapacity() 方法性能次之。反而初始化容量为 10000000 的方法 initialHashMap10000000Capacity() 性能最差。
这个结果有点出乎意料啊!按道理来说,初始化容量为 5000000 的方法 initialHashMap5000000Capacity() 性能(Score = 2256201.404)比没有初始化容量的方法 noInitialHashMapCapacity() 性能(Score = 2485808.481)要好,符合预估。但初始化容量为 10000000 的 initialHashMap10000000Capacity() 方法性能(Score = 2757766.439)最差而不是最好,为什么呢?是因为初始化容量不满足 2 的 N 次方(也可以叫 2 的 幂)吗?
再优化一下初始化容量值,满足 2 的 幂 ,看看各个方法的性能如何。这里初始化容量值分别设置为:1 << 23(即 8388608)和 1 << 22(即 4194304)。
/**
* 初始化HashMap容量 5000000
*/
@Benchmark
public Map<String, String> initialHashMap5000000Capacity() {
//Map<String, String> map = new HashMap<>(COUNT >> 1);
Map<String, String> map = new HashMap<>(1 << 22); //1 << 22 即是 4194304
for (int i = 1; i <= COUNT; i++) {
map.put("dbydc" + i, "大白有点菜");
}
return map;
}
/**
* 初始化HashMap容量 10000000
*/
@Benchmark
public Map<String, String> initialHashMap10000000Capacity() {
//Map<String, String> map = new HashMap<>(COUNT);
Map<String, String> map = new HashMap<>(1 << 23); //1 << 23 即是 8388608
for (int i = 1; i <= COUNT; i++) {
map.put("dbydc" + i, "大白有点菜");
}
return map;
}
优化后的HashMapJmhTest 运行结果如下(两次):
Benchmark Mode Cnt Score Error Units
HashMapJmhTest.initialHashMap10000000Capacity avgt 5 2045832.930 ± 124675.288 us/op
HashMapJmhTest.initialHashMap5000000Capacity avgt 5 2275266.420 ± 894396.032 us/op
HashMapJmhTest.noInitialHashMapCapacity avgt 5 2484181.438 ± 498123.176 us/op
Benchmark Mode Cnt Score Error Units
HashMapJmhTest.initialHashMap10000000Capacity avgt 5 2263702.172 ± 782462.635 us/op
HashMapJmhTest.initialHashMap5000000Capacity avgt 5 2377371.070 ± 851303.325 us/op
HashMapJmhTest.noInitialHashMapCapacity avgt 5 2488953.867 ± 813447.990 us/op
这次,性能上 initialHashMap10000000Capacity > initialHashMap5000000Capacity > noInitialHashMapCapacity ,将初始化容量值设置为 2 的 幂 才是更合理的做法,能大大地提升性能。
为什么初始化合理的容量能提升性能呢?其实不难理解,HashMap 如果没有初始化容量大小,那么随着元素的不断增加,HashMap 会发生多次扩容,而 HashMap 的扩容机制决定了每次扩容都需要重建 Hash 表,非常影响性能。
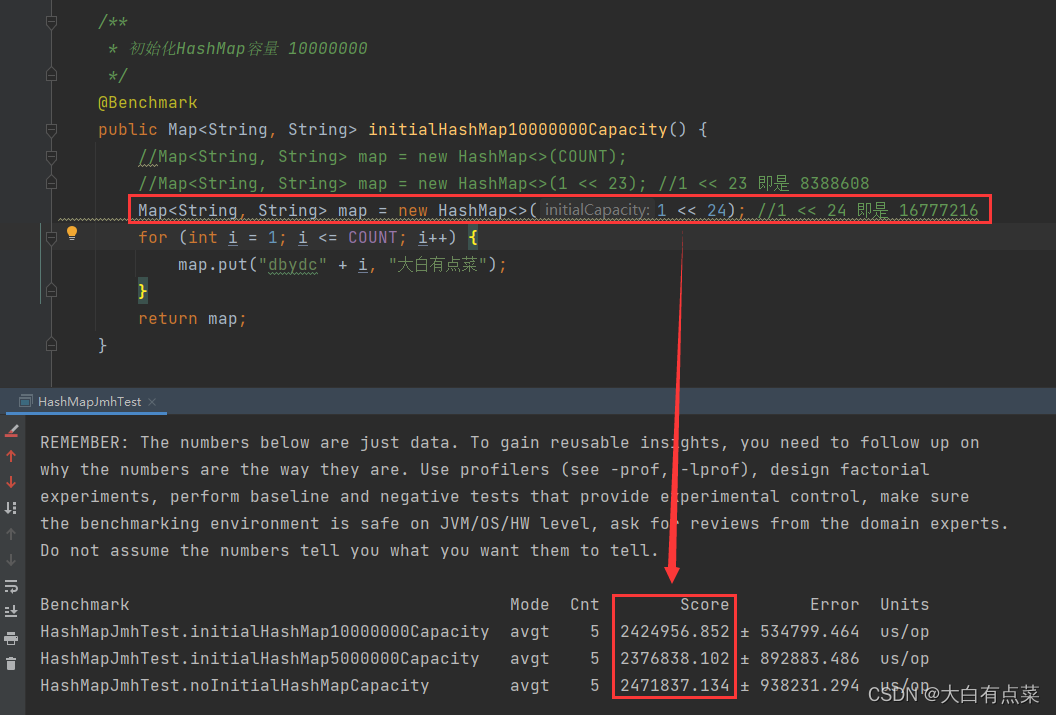
有个猜想:如果初始化的容量值(满足 2 的 N 次方)大于要插入的元素个数,性能又是怎样的呢? 为此,我特意做了测试,前后测试了 4 次,发现这种设置的性能只比没有初始化容量的性能要好那么一丢丢(少许浮动),远远比不上初始化的容量值(满足 2 的 N 次方)小于于要插入的元素个数的性能好!建议设置初始化容量值(满足 2 的 N 次方)时,尽可能做到比预估要插入的元素个数值要小。
/**
* 初始化HashMap容量 10000000
*/
@Benchmark
public Map<String, String> initialHashMap10000000Capacity() {
//Map<String, String> map = new HashMap<>(COUNT);
//Map<String, String> map = new HashMap<>(1 << 23); //1 << 23 即是 8388608
Map<String, String> map = new HashMap<>(1 << 24); //1 << 24 即是 16777216
for (int i = 1; i <= COUNT; i++) {
map.put("dbydc" + i, "大白有点菜");
}
return map;
}
HashMapJmhTest 运行结果如下(4次):

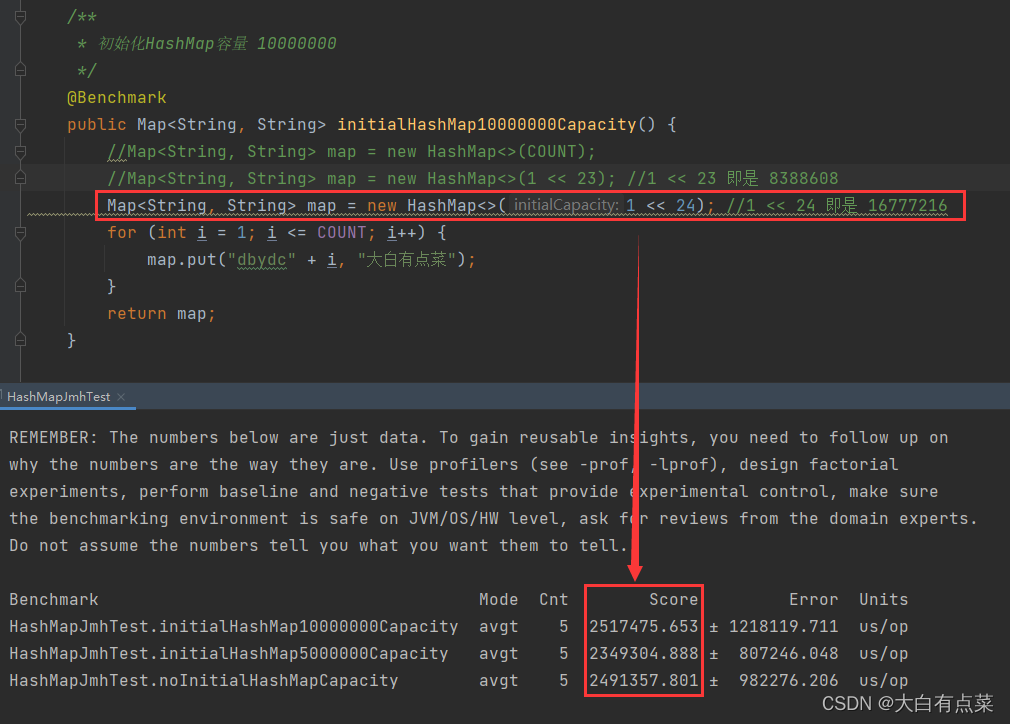
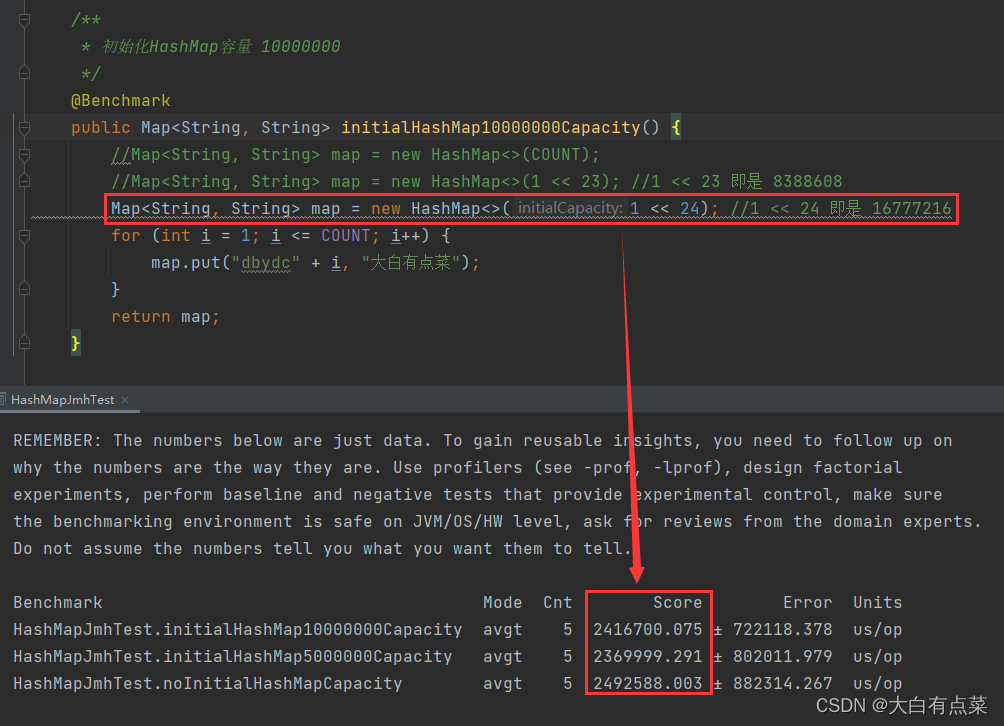
在《阿里巴巴Java开发手册中 第2版》中,第 1 章(编程规约)-》第 1.6 节(集合处理)-》第 17 小节中说到:
【推荐】当集合初始化时,指定集合初始值大小。
说明:HashMap 使用 HashMap(int initialCapacity) 初始化,如果暂时无法确定集合大小,那么指定默认值(16)即可。
正例:initialCapacity =(需要存储的元素个数 / 负载因子)+ 1。注意负载因子(即 load factory)默认为 0.75 ,如果暂时无法确定初始值大小,则设置为 16(即默认值)。
反例:HashMap 需要放置 1024 个元素,由于没有设置容量初始大小,则随着元素的增加而被迫不断扩容,resize() 方法一共会调用 8 次,反复重建哈希表和数据迁移。当放置的集合元素规模达千万级别时,会影响程序性能。
3.12 HashMap 的初始容量设置为多少合适
当 new HashMap(int initialCapacity) 初始化 HashMap 的容量时,JDK 会默认计算一个相对合理的值作为初始容量。
这个值看似合理,其实没有考虑 loadFactory 这个因素,只是简单地计算一个大于这个数字的 2 的 幂。
也就是说,如果我们设置默认值为 7 ,经过 JDK 处理后,HashMap 的容量会被设置成 8 ,但是,这个 HashMap 在元素个数达到 8 x 0.75 = 6 时就会进行一次扩容,而我们不希望看到这种情况。那么,设置成什么值比较合理呢?
参考 JDK 1.8 中 HashMap 类的 putAll(Map<? extends K, ? extends V> m) 方法,其实是调用 putMapEntries(Map<? extends K, ? extends V> m, boolean evict) 方法,值计算方法如下:int capacity = (int)(((float)Map.size() / 0.75F) + 1.0F);。
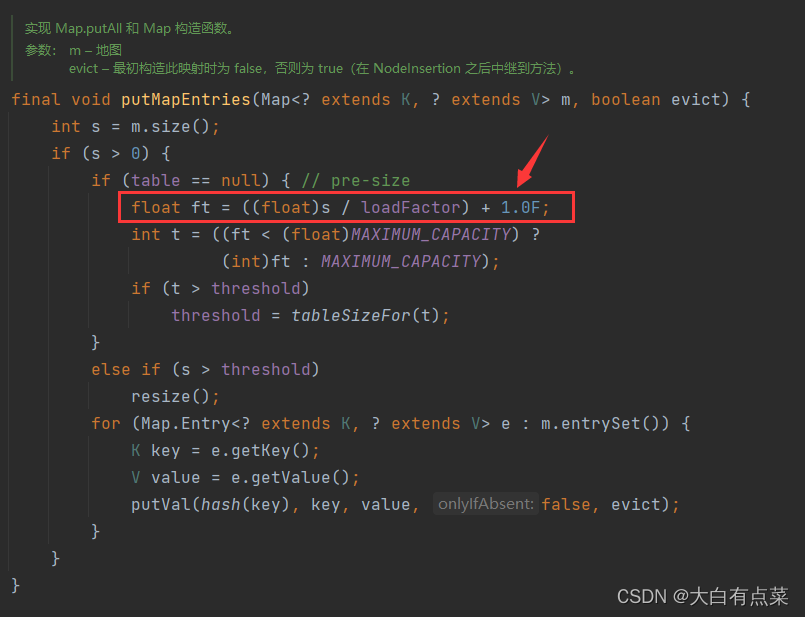
假设向 HashMap 插入 7 个元素,通过 expectedSize / 0.75F + 1.0F 计算,7 / 0.75 + 1 = 10 ,10 经过 JDK 处理后,会被设置成 16 ,这就大大减少了扩容的概率。
当 HashMap 内部维护的 Hash 表的容量达到 75% 时(默认情况下),会触发 rehash ,而 rehash 的过程是比较耗费时间的。所以初始化容量要设置成
expectedSize / 0.75F + 1.0F,既可以有效减少冲突,也可以减少误差。
当明确 HashMap 的元素个数时,把默认容量设置成 expectedSize / 0.75F + 1.0F 是一个在性能上相对好的选择,但同时增加内存占用。JDK 并不会直接以用户传进来的数值作为默认容量,而是会进行一番运算,最终得到 2 的 幂(即 2 的 N 次方)。得到数值的算法使用了无符号右移和按位或运算来提升效率。
3.13 为什么 JDK 1.8 中的 HashMap 引入 红黑树 而不是 AVL树
在 JDK 1.8 之前,为了解决 Hash 冲突问题,HashMap 底层一直采用 数组 + 链表 的结构实现。但是,无论 Hash 算法设计多么合理,都无法完全避免 Hash 冲突,如果一个 HashMap 的冲突太多,在极端情况下,数组的链表会退化为 链表。
在 JDK 1.8 中,HashMap 在 数组 + 链表 的结构基础上引入了 红黑树 。当链表长度太长时,链表转换成红黑树,利用红黑树快速增删改查的特点来解决链表过长导致查询性能下降的问题。为什么是 红黑树 而不是 AVL树(平衡二叉查找树)?
3.13.1 什么是自平衡二叉查找树
二叉查找树是一种经典的数据结构,既有链表的快速插入与删除操作特点,又有快速查找的优势,一颗包含 n 个元素的二叉查找树的平均时间复杂度是 O(logn)。二叉查找树的查找效率取决于树的高度,为了让一个二叉查找树的高度尽可能低,诞生了 AVL树 和 红黑树 这两种自平衡二叉查找树(改进的二叉查找树)。AVL树 的特点是:左右子树的高度差不超过1。红黑树 的特点之一是:近似平衡的二叉查找树,能够确保任何一个节点的左右子树的高度差不会超过二者中较低那个的一倍。
AVL树(Adelson-Velsky and Landis Tree)是计算机科学中最早被发明的自平衡二叉查找树。在AVL树中,任一节点对应的两棵子树的最大高度差为1,因此它也被称为高度平衡树。查找、插入和删除在平均和最坏情况下的时间复杂度都是 O(logn) 。增加和删除元素的操作则可能需要借由一次或多次树旋转,以实现树的重新平衡。AVL树得名于它的发明者G. M. Adelson-Velsky和Evgenii Landis,他们在1962年的论文《An algorithm for the organization of information》中公开了这一数据结构。
节点的平衡因子是它的左子树的高度减去它的右子树的高度(有时相反)。带有平衡因子1、0或 -1的节点被认为是平衡的。带有平衡因子 -2或2的节点被认为是不平衡的,并需要重新平衡这个树。平衡因子可以直接存储在每个节点中,或从可能存储在节点中的子树高度计算出来。【维基百科】:https://zh.wikipedia.org/wiki/AVL%E6%A0%91
红黑树(Red–black tree)是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,典型用途是实现关联数组。它在1972年由鲁道夫·贝尔发明,被称为“对称二叉B树”,它现代的名字源于Leo J. Guibas和罗伯特·塞奇威克于1978年写的一篇论文。红黑树的结构复杂,但它的操作有着良好的最坏情况运行时间,并且在实践中高效:它可以在 O(logn) 时间内完成查找、插入和删除,这里的n是树中元素的数目。【维基百科】:https://zh.wikipedia.org/wiki/%E7%BA%A2%E9%BB%91%E6%A0%91
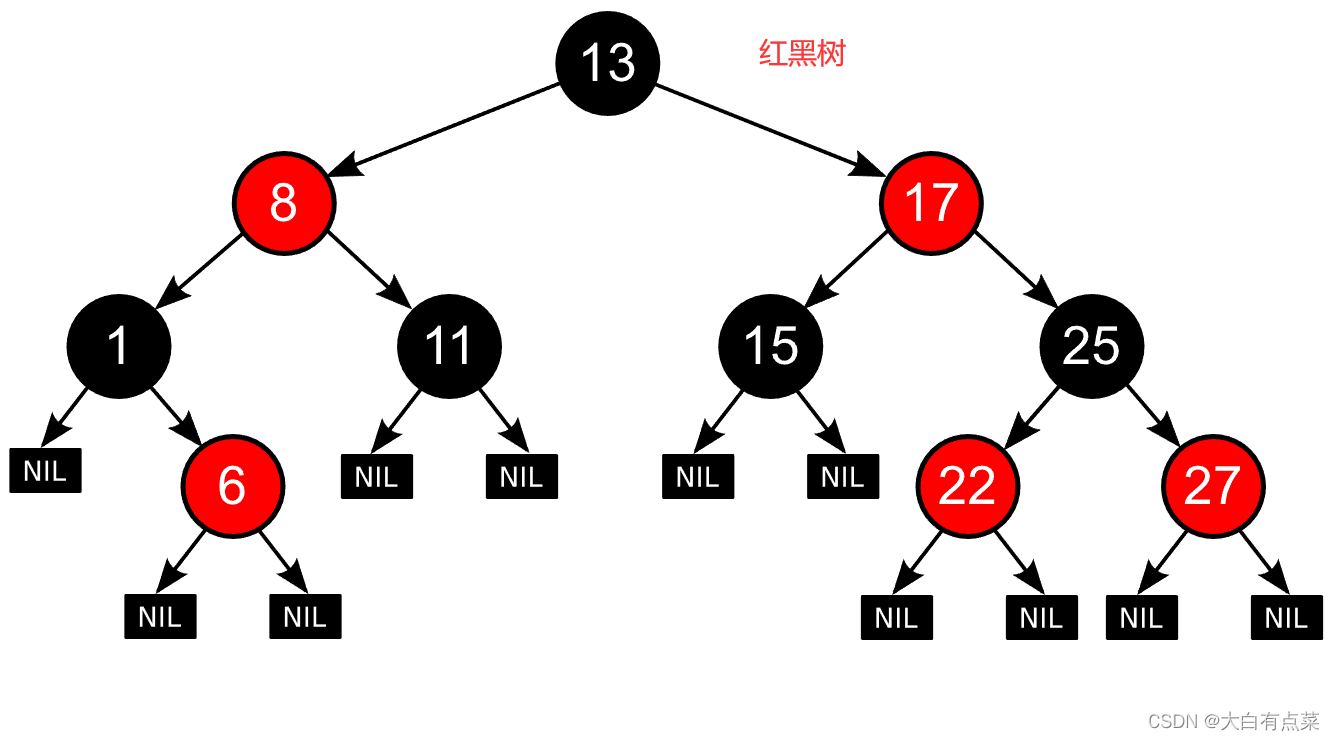
红黑树 的性质如下:
1、节点是红色或黑色。
2、根节点是黑色。
3、所有叶子都是黑色的空节点(NIL)。
4、每个红色节点必须有两个黑色的子节点。(或者说从每个叶子到根的所有路径上不能有两个连续的红色节点。)(或者说不存在两个相邻的红色节点,相邻指两个节点是父子关系。)(或者说红色节点的父节点和子节点均是黑色的。)
5、从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点。
3.13.2 HashMap 为什么选择 红黑树 而不是 AVL树
AVL 树在查找时效率比较高,但为了保证这颗树一直是平衡的,每次在做元素的插入和删除操作时,需要对这棵树进行平衡调整,使它一直保持为一颗平衡树,性能损耗大。
由于 AVL树 追求绝对的平衡,而 红黑树 一样可以做到高效的查询效率,允许局部的不完全平衡,插入和删除元素操作的性能损耗不多。红黑树相对于AVL树来说,牺牲了部分平衡性以换取插入和删除操作时少量的旋转操作,整体来说性能要优于AVL树。所以 HashMap 采用了 红黑树 而不用 AVL树。
3.14 HashMap 中 链表 和 红黑树 互相转换的过程了解吗
JDK 1.8 中新增的 HashMap 中 链表 和 红黑树 互相转换几个重要的静态常量:
| 静态常量 | 描述 | 默认值 |
|---|---|---|
| TREEIFY_THRESHOLD | 由链表转换为红黑树的阈值。 | 8 |
| UNTREEIFY_THRESHOLD | 由红黑树转换为链表的阈值。 | 6 |
| MIN_TREEIFY_CAPACITY | 由链表转换为红黑树时,容器的最小容量的阈值。 | 64 |

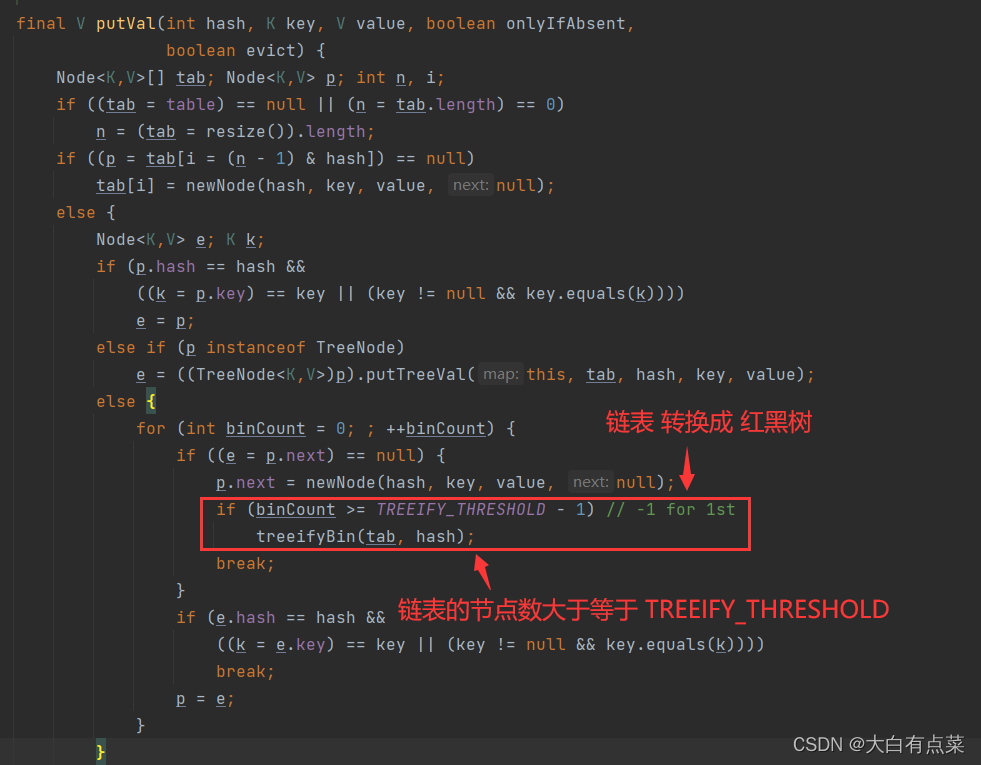
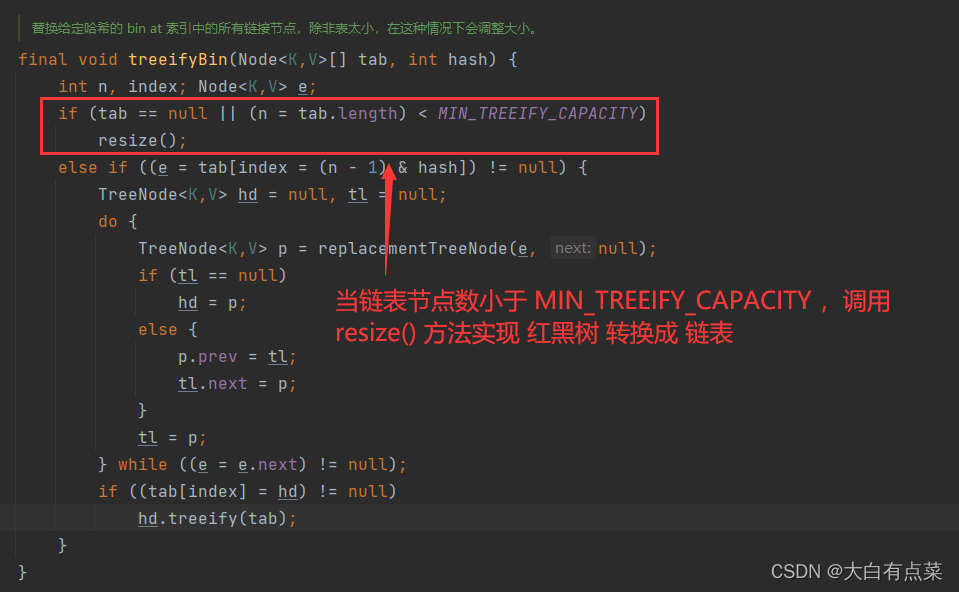
在 HashMap 的 putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) 方法中,当链表节点数量大于或等于 TREEIFY_THRESHOLD 的值(默认值为 8 )并且容量(capacity)大于或等于 MIN_TREEIFY_CAPACITY 的值(默认值为 64 )时,链表 就会转换成 红黑树。当红黑树的节点数量小于等于 UNTREEIFY_THRESHOLD 的值(默认值为 6 )并且容量(capacity)小于 MIN_TREEIFY_CAPACITY 的值(默认值为 64 )时,红黑树 就会转换成 链表 。
3.14.1 HashMap中 链表 转换成 红黑树 的实现过程
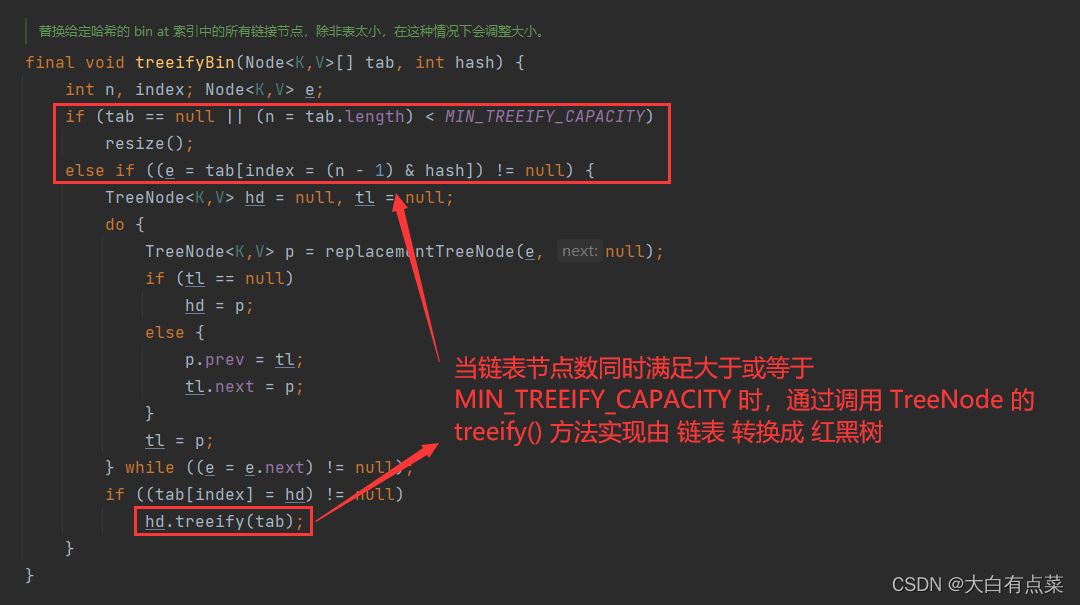
HashMap中 链表 转换成 红黑树 的实现过程如下,在 treeifyBin(Node<K,V>[] tab, int hash)
方法里面调用 TreeNode 的 treeify() 方法实现。链表的节点数 >= TREEIFY_THRESHOLD 同时 容量(capacity)>= MIN_TREEIFY_CAPACITY。
3.14.2 HashMap中 红黑树 转换成 链表 的实现过程
HashMap中 红黑树 转换成 链表 的实现过程如下,在 treeifyBin(Node<K,V>[] tab, int hash)
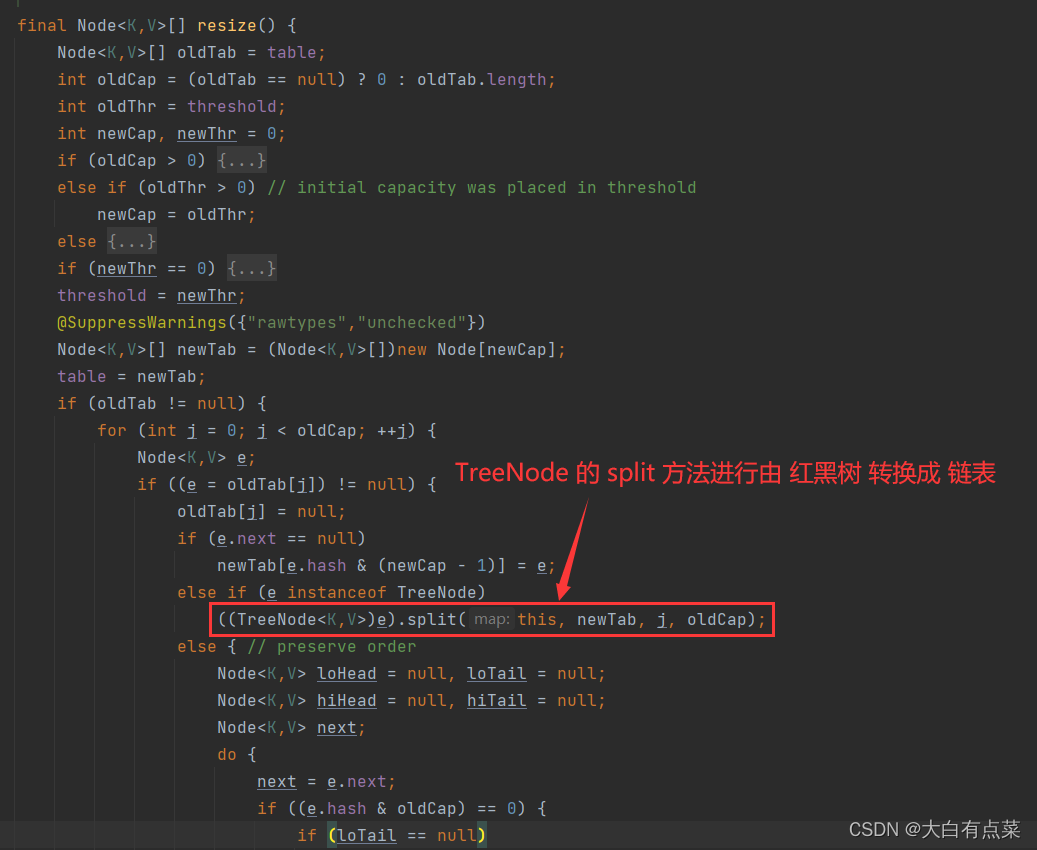
方法里,再调用的 resize() 方法,再调用 TreeNode 的 split() 方法,最后调用 TreeNode 的 untreeify() 方法实现。红黑树的节点数 <= UNTREEIFY_THRESHOLD 同时 容量(capacity)< MIN_TREEIFY_CAPACITY。
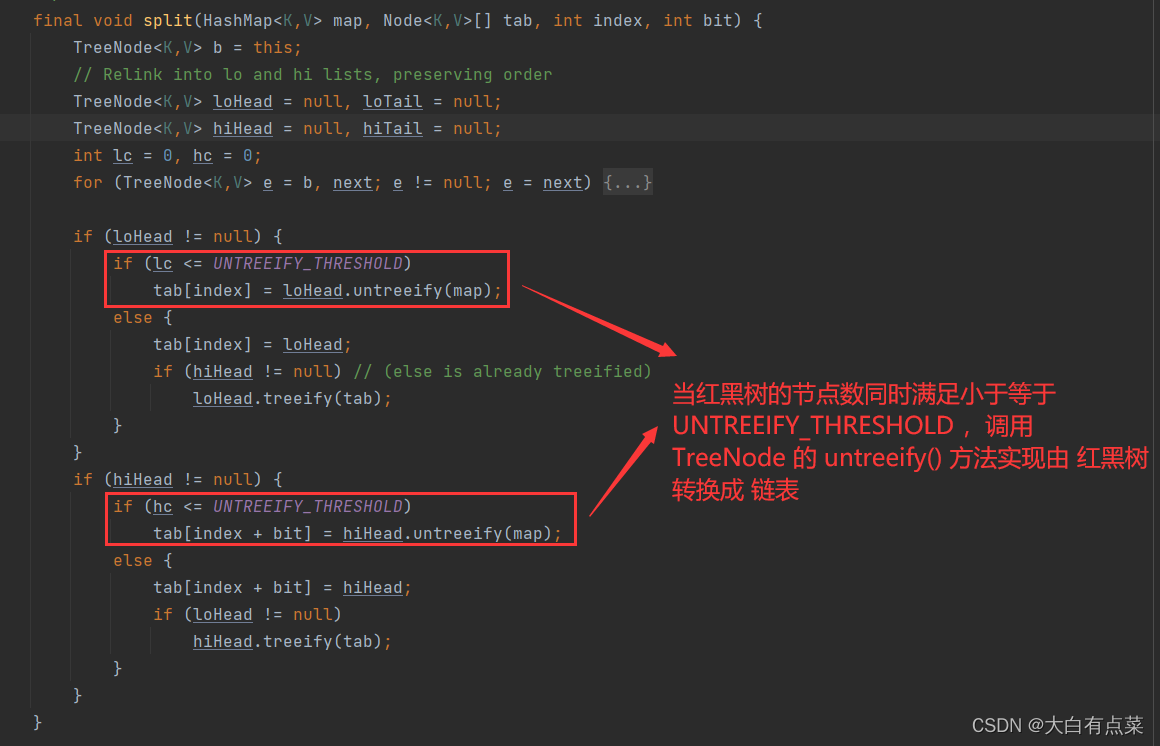
3.15 为什么将 HashMap 由 链表 转换成 红黑树 的阈值(TREEIFY_THRESHOLD)设置为 8
为了确定 HashMap 的数据结构从 链表 转换成 红黑树,JDK 官方人员做了推算,发现在理想情况下,随机 Hash 算法下所有节点的分布频率会遵循 泊松分布 。
泊松分布(Poisson distribution)又称Poisson分布、帕松分布、布瓦松分布、布阿松分布、普阿松分布、波以松分布、卜氏分布、帕松小数法则(Poisson law of small numbers),是一种统计与概率学里常见到的离散概率分布,由法国数学家西莫恩·德尼·泊松在1838年时发表。
泊松分布适合于描述单位时间内随机事件发生的次数的概率分布。如某一服务设施在一定时间内受到的服务请求的次数,电话交换机接到呼叫的次数、汽车站台的候客人数、机器出现的故障数、自然灾害发生的次数、DNA序列的变异数、放射性原子核的衰变数、激光的光子数分布等等。
泊松分布的参数 λ 是随机事件发生次数的数学期望值。【维基百科】:https://zh.wikipedia.org/wiki/%E5%8D%9C%E7%93%A6%E6%9D%BE%E5%88%86%E5%B8%83
泊松分布的概率质量函数公式:
P ( X = k ) = e − λ λ k k ! \Rho(\Chi = k) = \frac {e^{-\lambda}\lambda^{k}} {k!} P(X=k)=k!e−λλk
在默认负载因子(loadFactory)是 0.75 的条件下,泊松分布中的概率参数 λ(读作 lambda )约等于 0.5 。
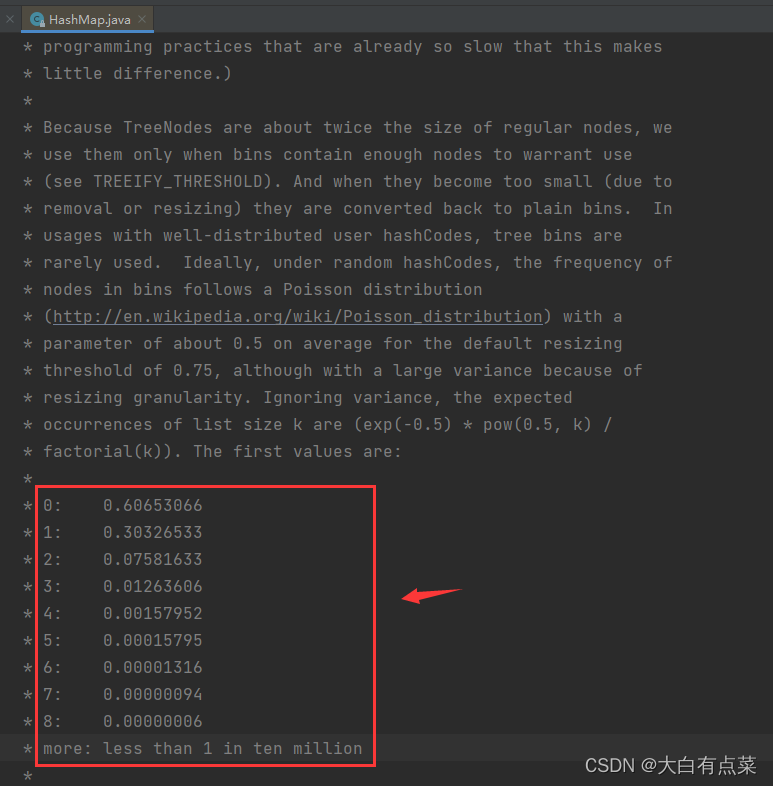
根据公式,将 0.5 代入 λ ,并计算出不同的 k 个元素同时落到一个桶中的概率,结果如下(数据来源于 HashMap 源码中的注释):
- k = 0:0.60653066
- k = 1:0.30326533
- k = 2:0.07581633
- k = 3:0.01263606
- k = 4:0.00157952
- k = 5:0.00015795
- k = 6:0.00001316
- k = 7:0.00000094
- k = 8:0.00000006
- k > 8:小于千万分之一
代码注释中还有一段描述,使用谷歌翻译看看都描述些什么内容:
Because TreeNodes are about twice the size of regular nodes, we use them only when bins contain enough nodes to warrant use (see TREEIFY_THRESHOLD). And when they become too small (due to removal or resizing) they are converted back to plain bins. In usages with well-distributed user hashCodes, tree bins are rarely used. Ideally, under random hashCodes, the frequency of nodes in bins follows a Poisson distribution (http://en.wikipedia.org/wiki/Poisson_distribution) with a parameter of about 0.5 on average for the default resizing threshold of 0.75, although with a large variance because of resizing granularity. Ignoring variance, the expected occurrences of list size k are (exp(-0.5) * pow(0.5, k) / factorial(k)).
因为 TreeNodes 大约是常规节点大小的两倍,所以我们仅在 bins 包含足够的节点以保证使用时才使用它们(参见 TREEIFY_THRESHOLD)。 当它们变得太小时(由于移除或调整大小),它们将被转换回 plain bins。 在使用分布良好的用户 hashCodes 时,很少使用 tree bins。 理想情况下,在随机 hashCode 下,bins 中节点的频率遵循泊松分布 (http://en.wikipedia.org/wiki/Poisson_distribution),对于默认调整大小阈值 0.75,参数平均约为 0.5,尽管由于调整粒度而具有很大的差异。忽略方差,列表大小 k 的预期出现次数为 (exp(-0.5) * pow(0.5, k) / factorial(k))。
从上面的结果可以看出:一个链表中被存放 8 个元素的概率是 0.00000006 ,大于 8 个元素的概率更低。
如果选择 8 作为阈值,那么 链表 还有机会转换成 红黑树 吗?其实,这个数值的推算有一定前提:理想情况下、随机 Hash 算法、忽略方差。
最差的 Hash 算法是所有元素的 Hash 值都一样(public int hashCode(){return 1;}),元素落到同一个链表中的概率高达 100% 了。
为了防止一个不好的 Hash 算法导致链表过长,需要选定一个长度作为 链表 转换成 红黑树 的阈值。在随机 Hash 的情况下,一个链表中有 8 个元素的概率很低(0.00000006),大于 8 的概率小于千万分之一。
选择 8 作为阈值很合适,在使用好的 Hash 算法情况下可以避免频繁地把 链表 转换成 红黑树。在使用不好的 Hash 算法情况下,也可以在合适的时机把 链表 转换成 红黑树 ,从而提高效率。
3.16 为什么将 HashMap 由 红黑树 转换成 链表 的阈值(UNTREEIFY_THRESHOLD)设置为 6
HashMap 中 红黑树 转换成 链表 的阈值(UNTREEIFY_THRESHOLD)设置为 6 ,比 链表 转换成 红黑树 的阈值(TREEIFY_THRESHOLD)8 小一点,主要是为了避免 链表 和 红黑树 之间频繁转换。
四、资料参考
1、《深入理解Java核心技术-写给Java工程师的干货笔记(基础篇)》 :张洪亮[著]
2、10万字总结java面试无敌流笔记.pdf :作者未知
3、《阿里巴巴Java开发手册 第2版》 :杨冠宝[著]