文章目录
4. HashMap
4.1 HashMap的快速查找演示
- 采用ArrayList存储元素,查找元素过程
当采用ArrayList存储元素,进行查找元素时,需要从头到位进行遍历.比如要查找元素a,需要遍历整个ArrayList,然后进行匹配.
时间复杂度为 O ( N ) O(N) O(N)
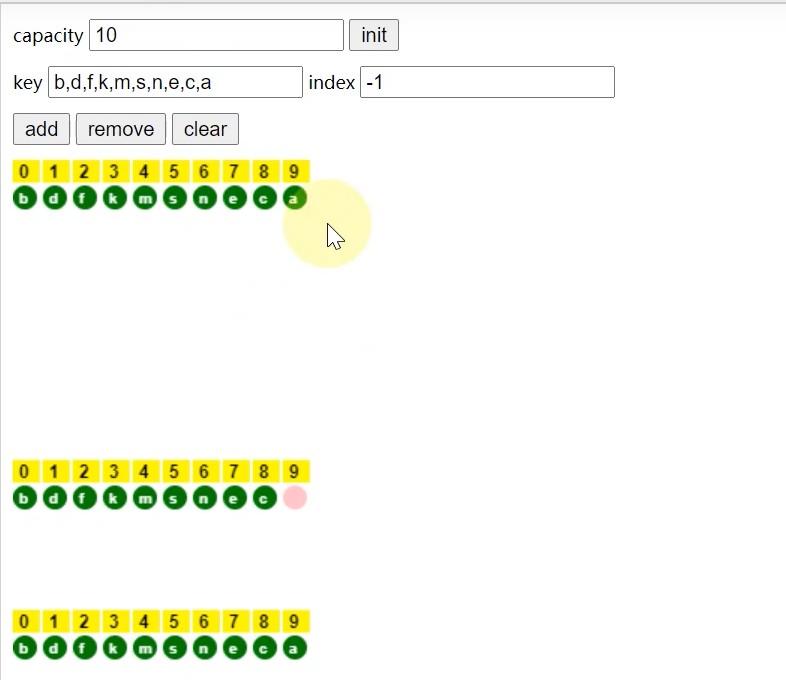
- 当采用HashMap存储元素,查找元素过程
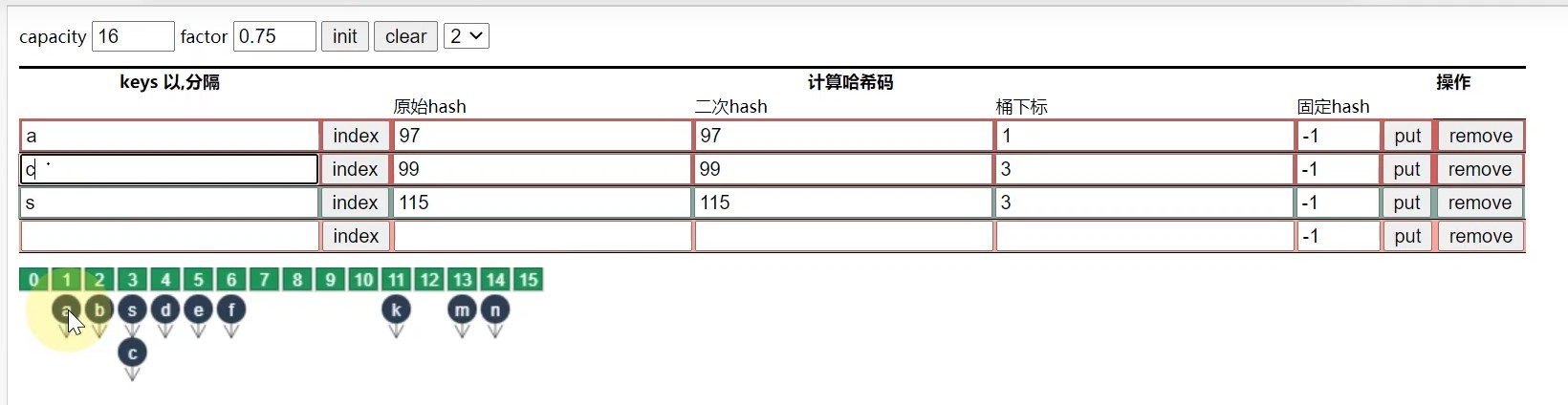
首先我们分析以下HashMap的存储过程.比如元素a,先利用hash算法(hashCode())计算出key对应的hash值,然后再进行二次hash(演示中的两次hash是一样的,实际中未必哦!),然后计算元素的下标: 97 % 16 = 1,最后就将元素存储在1位置.
如何进行元素的查找呢?
也是通过元素的hash值进行查找,比如我要查找a,那么a对应的下标经过计算可以得到是1,然后直接去下标为1的地方获取值即可.这个时候的时间复杂度就成了 O ( 1 ) O(1) O(1)
但是如果遇到了hash冲突,则计算出下标后还需要进行多次匹配,直到匹配到指定的元素.
4.2 链表过长的解决方案
4.2.1 方案1—扩容
先说明一个问题,hashMap出现链表过长的原因是什么?这样会给我们带来的弊端是什么?
原因: 当元素数量增多,经过key计算出来的hash值更容易冲突(也就是hash值一致),从而会导致同一个下标下的链表长度会不断的增长.
弊端: 如果链表过长,就会大大降低查找元素的效率. 当我们通过hash算法计算得到下标后,还需要遍历链表来匹配元素,由LinkedList底层原理可知,链表迭代的效率是非常低的,从而导致查找元素的效率大大降低
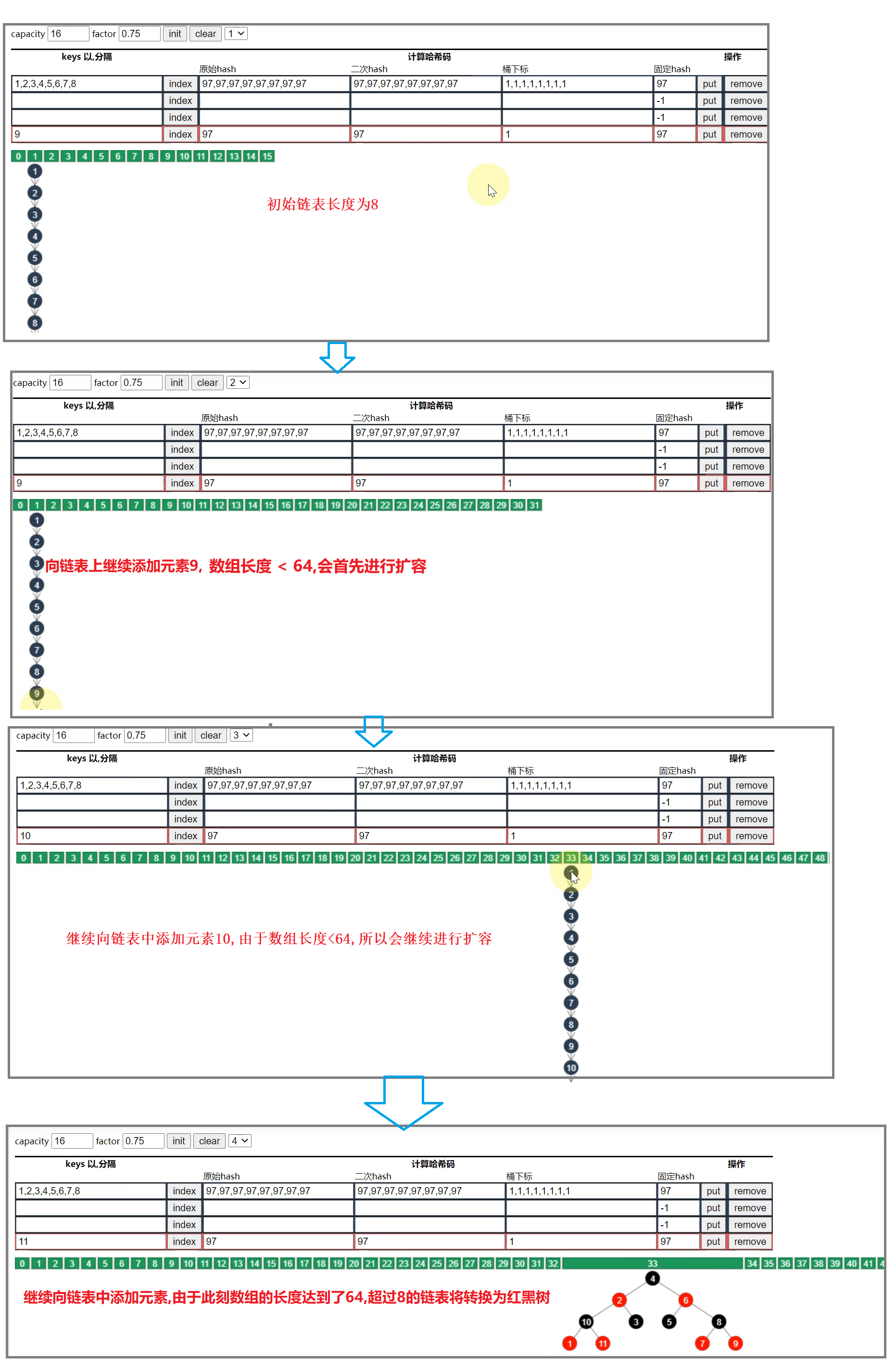
这时候我们就需要提高元素查找效率了,第一种方案就是扩容,演示如下:
- 若下图,1,2,3,4和5,6,7,8 经过hash运算和下标计算得到的数组下标是一样的,都是1
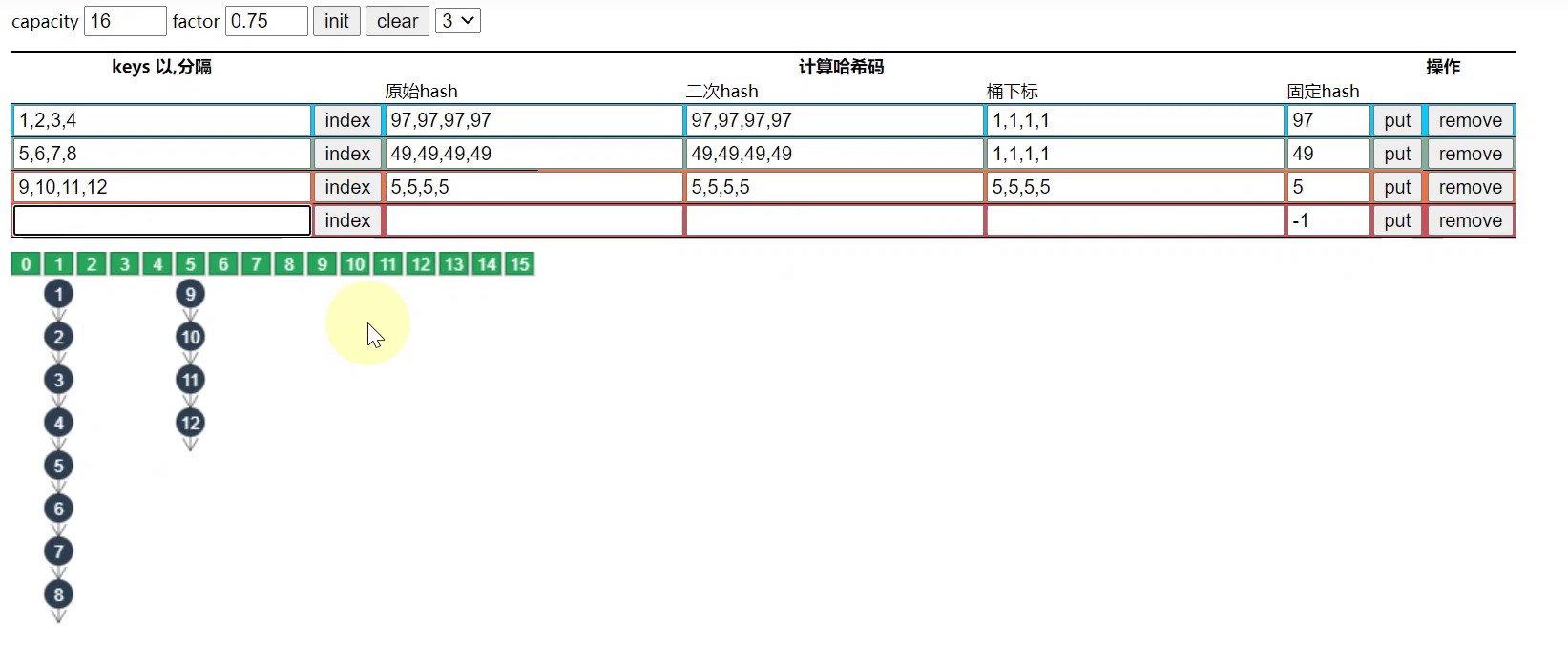
- 当元素的个数> 容量 * 负载因子,也就是 > 12的时候,链表就会进行扩容,每次库容后的大小是之前的2倍.
此时5,6,7,8的下标就会变化,从而链表长度就会缩短.
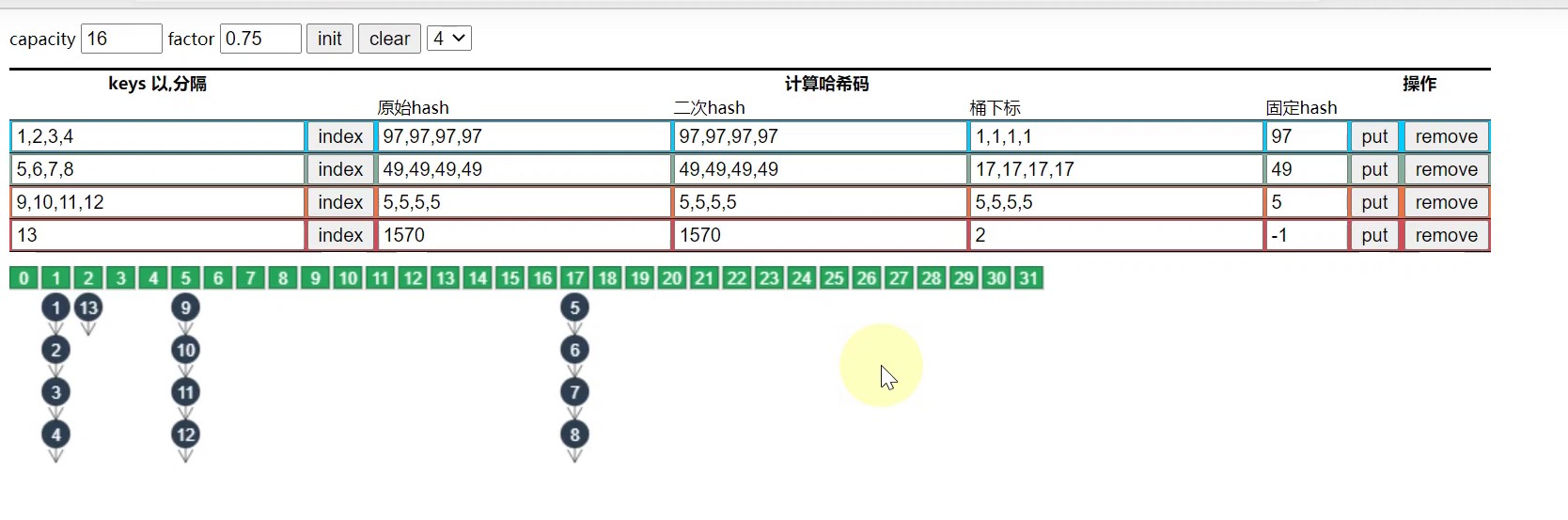
备注: 但是对于一些特殊情况,比如扩容前链表中的元素的hash值是一样的,那么即使扩容后元素仍然还在同一条链表上,并无法达到缩短链表的效果. 如下图所示:
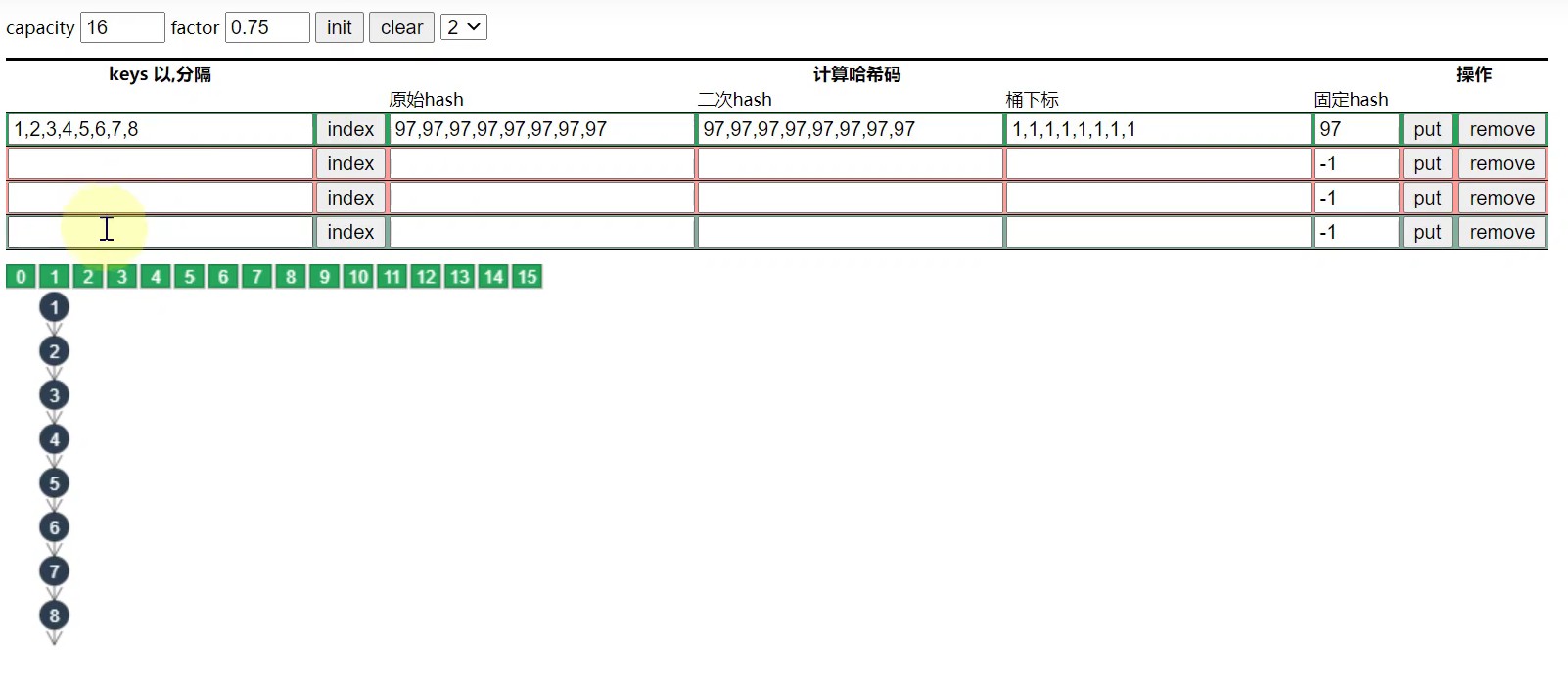
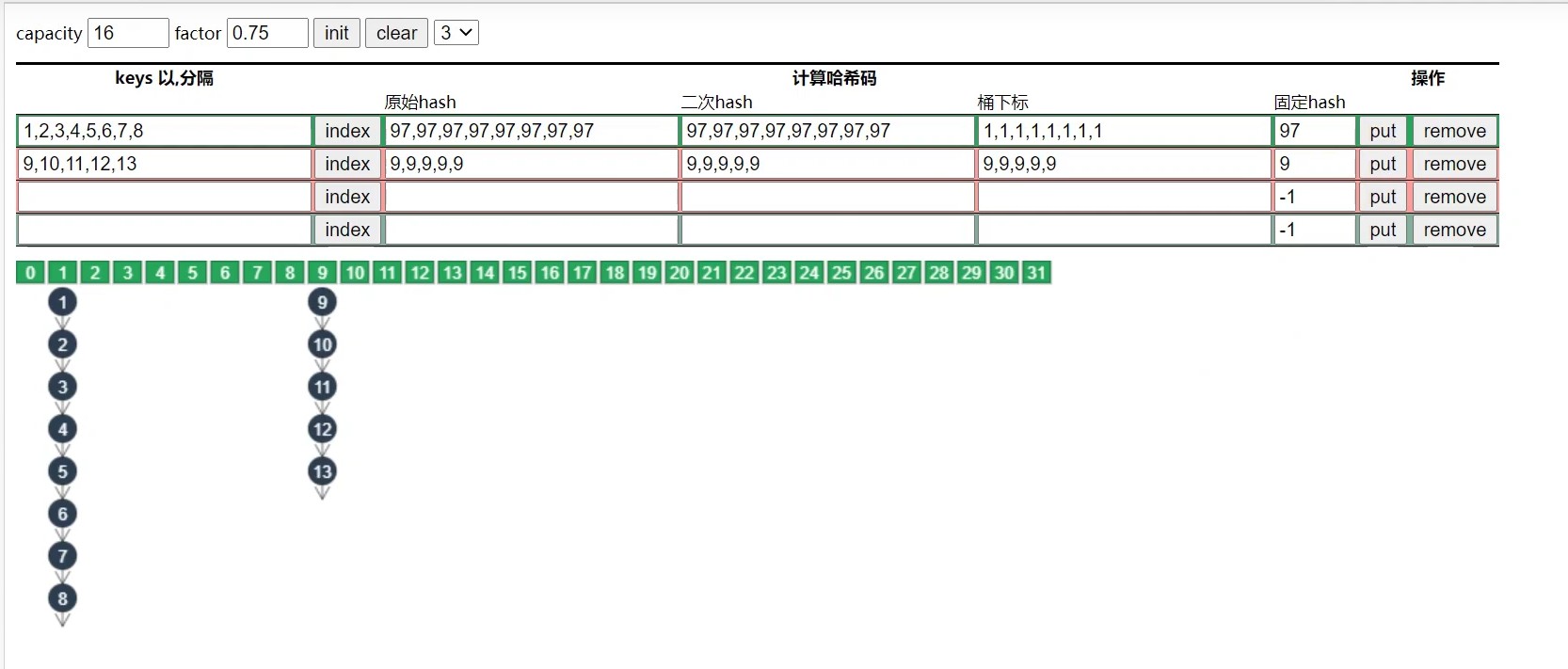
总结:扩容并不能完全解决链表过长的问题,因此就有了下面我们将要介绍的将链表转换为红黑树
4.2.1 方案2—树化
树化的前提条件
- 链表的长度必须达到阈值(8)
- 数组的长度必须大于64,否则会采取扩容的策略.
图解
- 当链表的长度超过8,但是数组长度==< 64==时.
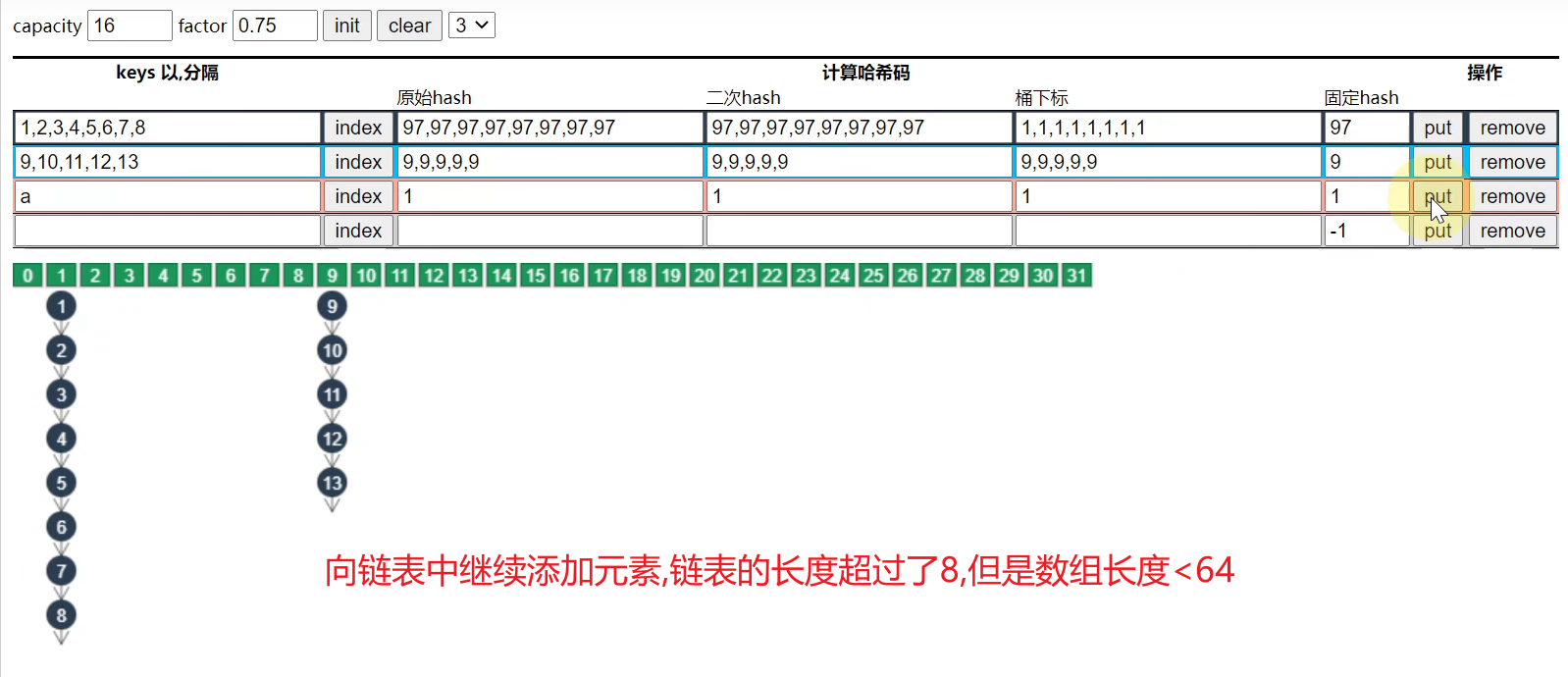
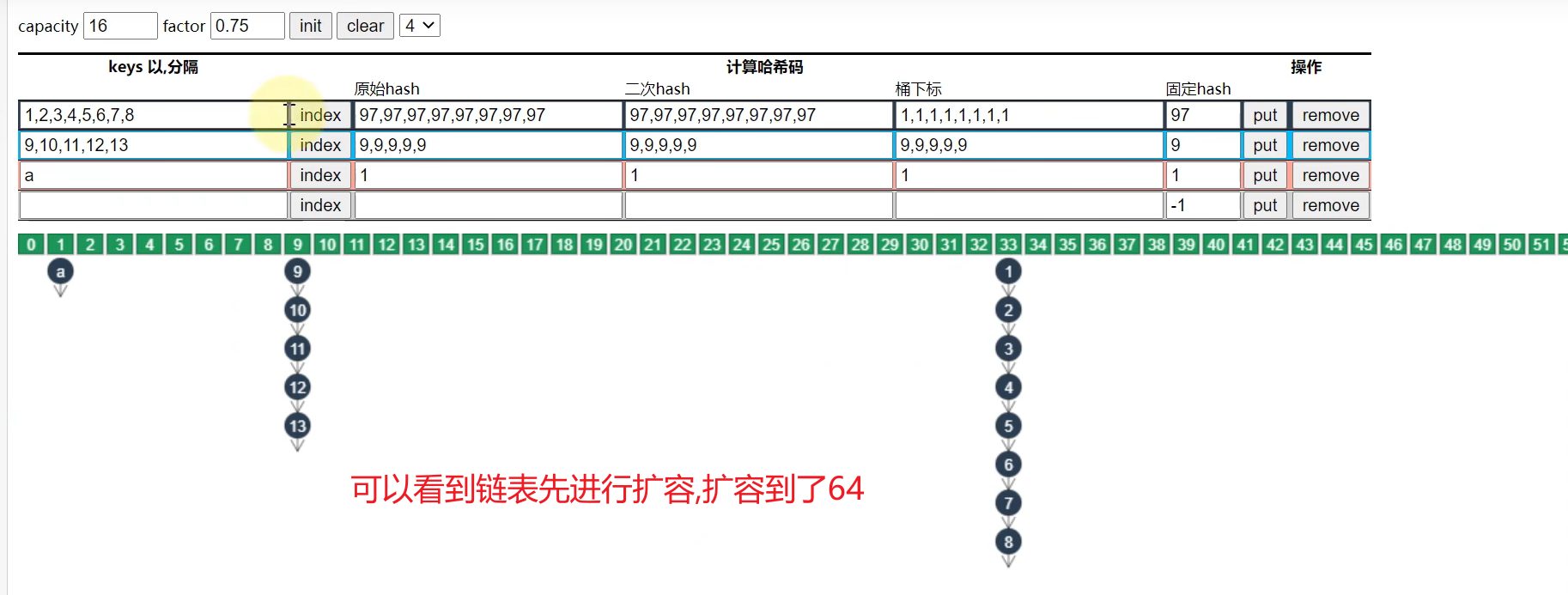
- 当链表的长度超过8,但是数组长度==>= 64==时
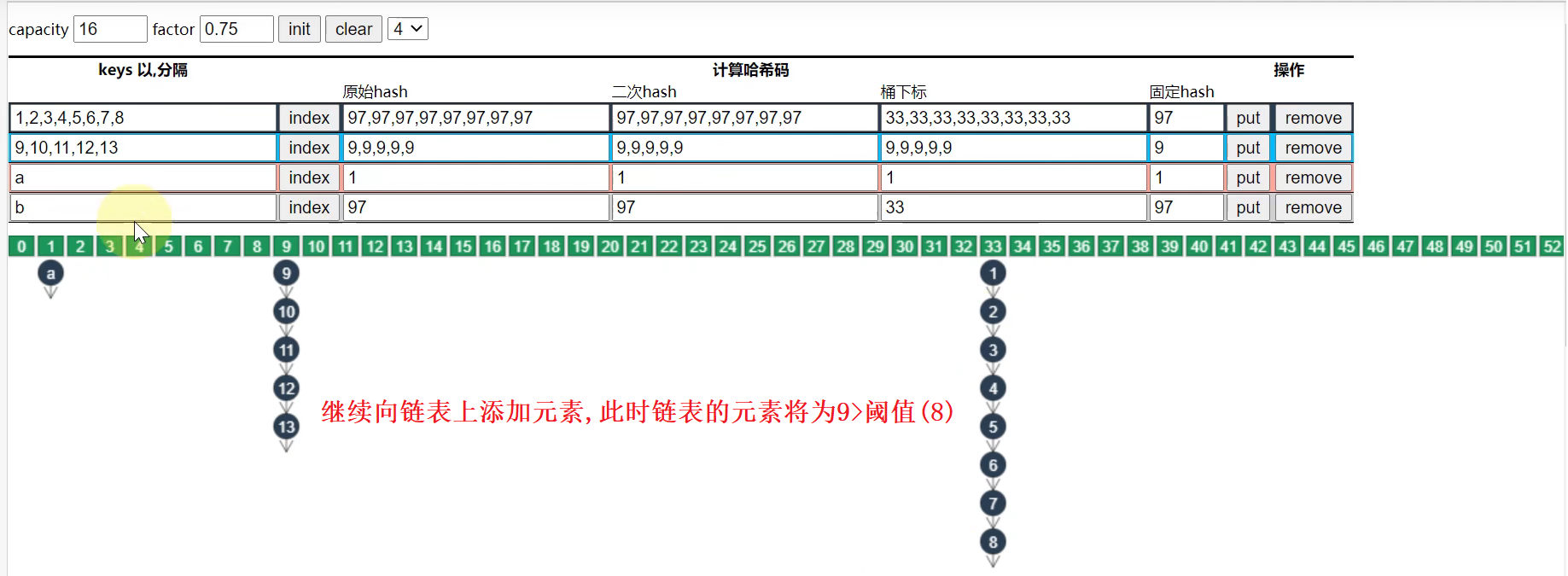
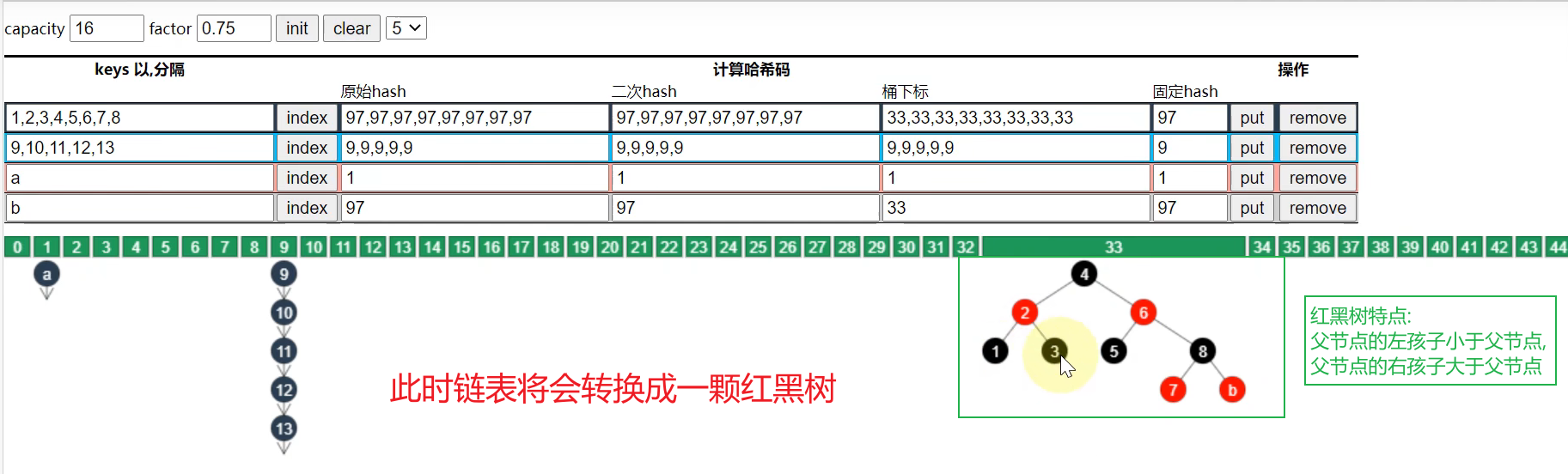
分析
-
红黑树比较规则:先按照hash值比,如果相等,则按照字符值的大小顺序比.
-
树化后的比较:(以数字8为例)
比4大–>右子树查找–>比6大–>右子树寻找–>和8相同,查找结束. 总共需要3次比较,即可找到对应的数.
-
红黑树查找的时间复杂度: O ( l o g 2 N ) O(log2N) O(log2N)
补充:hashMap中的链表长度会大于8吗?
4.3 红黑树的意义—树化阈值
hash 值如果足够随机,则在 hash 表内按泊松分布,在负载因子 0.75 的情况下,长度超过 8 的链表出现概率是 0.00000006,树化阈值选择 8 就是为了让树化几率足够小
代码演示大量单词(234937个)加入到hashMap中后,链表的长度情况
package com.rg.map;
import java.io.IOException;
import java.lang.reflect.Array;
import java.lang.reflect.Field;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.stream.Collectors;
// --add-opens java.base/java.util=ALL-UNNAMED
public class HashMapDistribution {
public static void main(String[] args) throws IOException {
Object value = new Object();
Map<String, Object> words = Files.readAllLines(Path.of("words")).stream()
.collect(Collectors.toMap(w -> w, w -> value));
System.out.println(words.getClass());
showDistribution(words);
}
private static void showDistribution(Map<String, Object> map) {
try {
Field tableField = HashMap.class.getDeclaredField("table");
Field nextField = Class.forName("java.util.HashMap$Node").getDeclaredField("next");
tableField.setAccessible(true);
nextField.setAccessible(true);
Object array = tableField.get(map);
int length = Array.getLength(array);
System.out.println("总的桶个数[" + length + "]");
Map<Integer, AtomicInteger> result = new HashMap<>();
for (int i = 0; i < length; i++) {
Object node = Array.get(array, i);
AtomicInteger c = result.computeIfAbsent(i, key -> new AtomicInteger());
while (node != null) {
c.incrementAndGet();
node = nextField.get(node);
}
}
Map.Entry maxEntry = null;
int max = -1;
HashMap<Integer, AtomicInteger> counting = new HashMap<>();
for (Map.Entry<Integer, AtomicInteger> entry : result.entrySet()) {
int value = entry.getValue().get();
AtomicInteger c = counting.computeIfAbsent(value, k -> new AtomicInteger());
c.incrementAndGet();
}
counting.forEach((k, v) -> {
System.out.println(k + "个元素的桶个数[" + v + "]");
});
} catch (Exception e) {
e.printStackTrace();
}
}
}

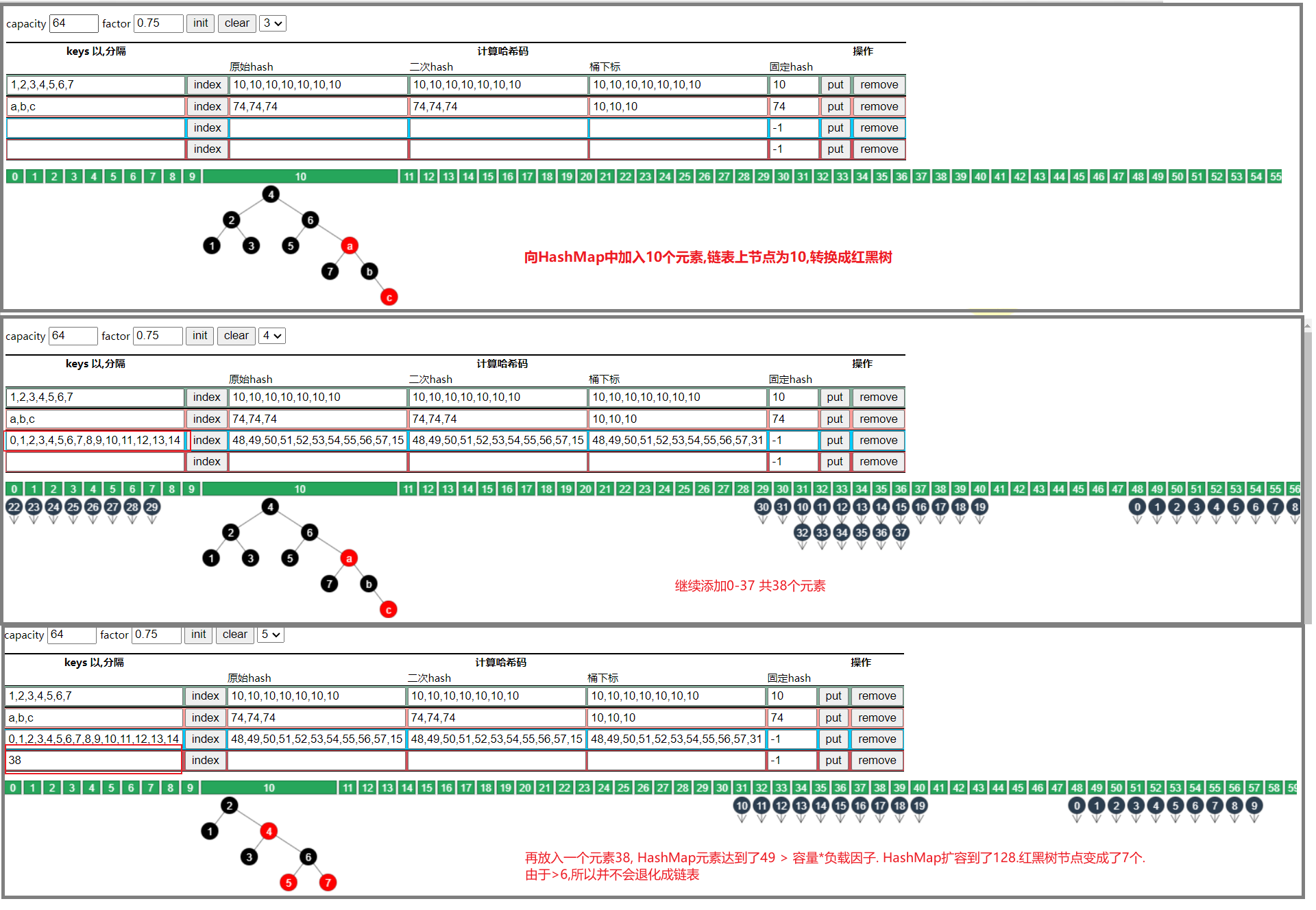
4.4 树退化链表
4.4.1 情况1—树节点个数<=6
情况1:在扩容时如果拆分树时,树元素个数 <= 6 则会退化链表
退化图解
- 当HashMap的链表中红黑树为6时,发生退化

- 当HashMap中的红黑树节点为7时,保持红黑树
4.4.2 情况2—当某些节点为NULL
情况2:remove 树节点时,若 root、root.left、root.right、root.left.left 有一个为 null ,也会退化为链表
退化过程图解:
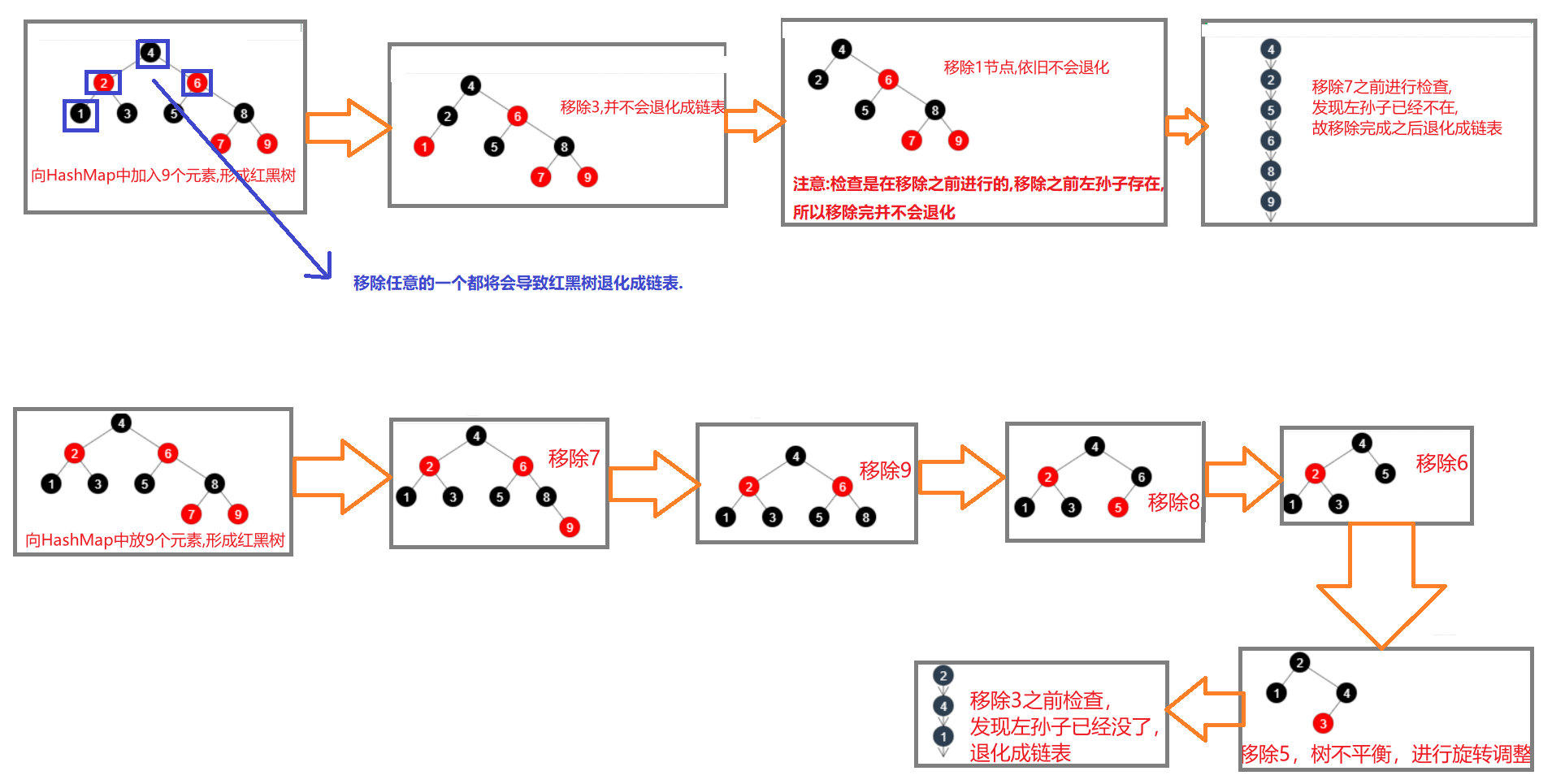
备注:
-
检查节点是在移除之前进行的,如果移除(以上四种)之前存在,则移除之后依旧不会退化
-
当执行resize也就是扩容的情况下是判断元素小等于6,而在执行remove时才去判断root节点及子孙。两个情况不一样。 所以图中,在remove过程中即使节点数<=6,也不会退化成链表.
4.5 索引计算
4.5.1 索引计算方法
- 首先,计算对象的 hashCode() ,也就是原始Hash
- 再进行调用 HashMap 的 hash() 方法进行二次哈希
- 二次 hash() 是为了综合高位数据,让哈希分布更为均匀
- 最后 & (capacity – 1) 得到索引 (等价于取模运算,但是逻辑运算效率更高)
补充: 取模运算和逻辑运算的关系

4.5.2 为何要二次Hash
观察源码
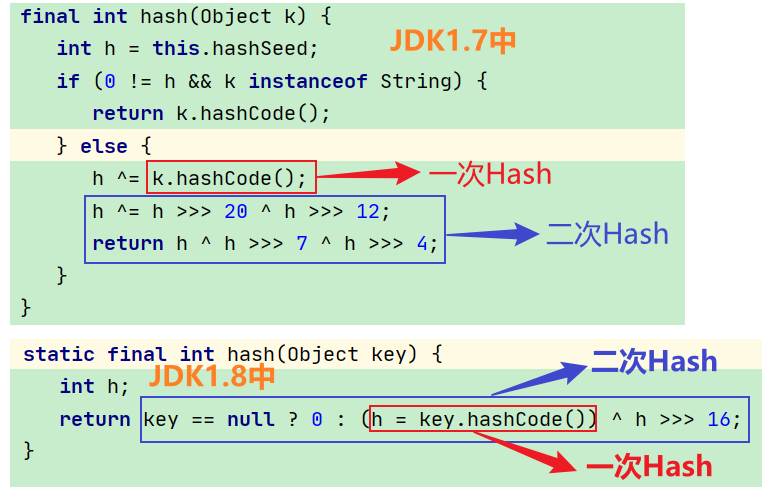
代码验证
- 当使用随机产生的数放入容量为16的Hash表中
public static void main(String[] args) {
int[] array = Utils.randomArray(1000);
System.out.println(Arrays.toString(array));
int[] sizes = {
16};
printHashResult(array, sizes);
}
public static int[] randomArray(int n) {
int lastVal = 1;
Random r = new Random();
int[] array = new int[n];
for (int i = 0; i < n; i++) {
int v = lastVal + Math.max(r.nextInt(10), 1);
array[i] = v;
lastVal = v;
}
shuffle(array);
return array;
}
public static void printHashResult(int[] array, int[] sizes) {
List<Map<Integer, AtomicInteger>> maps = new ArrayList<>();
for (int size : sizes) {
maps.add(getMap(size));
}
for (int hash : array) {
for (int j = 0; j < sizes.length; j++) {
maps.get(j).get(hash % sizes[j]).incrementAndGet();
}
}
for (Map<Integer, AtomicInteger> map : maps) {
System.out.printf("size:[%d] %s%n", map.size(), map);
}
}
运行结果:

- 当使用非随机数(特殊处理过)放入容量为16的Hash表中
public static void main(String[] args) {
int[] array = Utils.lowSameArray(1000);
System.out.println(Arrays.toString(array));
int[] sizes = {
16};
printHashResult(array, sizes);
}
//产生特殊的随机数
public static int[] lowSameArray(int n) {
int[] array = new int[n];
Random r = new Random();
for (int i = 0; i < n; i++) {
array[i] = r.nextInt() & 0x7FFF0002;
}
return array;
}
运行结果:

改进:模仿jdk的hash算法进行二次Hash

总结:二次Hash可以让数在HashMap上分布更为均匀,防止出现超长链表.
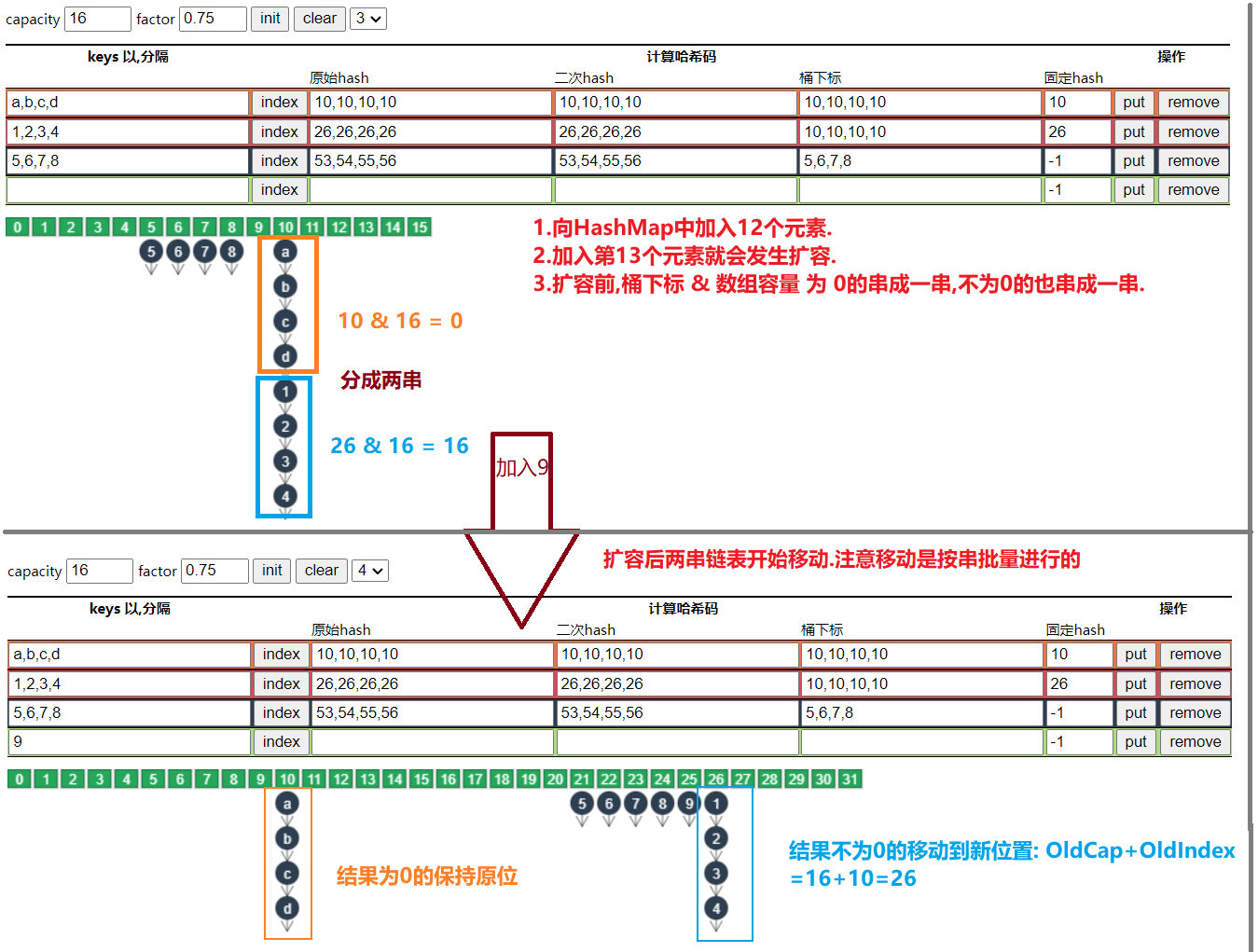
4.5.3 容量为何是2的n次幂
- 计算索引时效率更高:如果是 2 的 n 次幂可以使用位与运算代替取模
- 扩容时重新计算索引效率更高: hash & oldCap == 0 的元素留在原来位置 ,否则新位置 = 旧位置 + oldCap
图解演示
4.5.4 容量不是2的n次幂行不行
答案:可以的
代码演示
// .net 是原始容量 * 2 开始找下一个质数作为新容量
public static void main(String[] args) {
int[] array = Utils.lowSameArray(1000);
// int[] array = Utils.evenArray(1000);
System.out.println(Arrays.toString(array));
int[] sizes = {
11, 16, 23};
printHashResult(array, sizes);
}
public static int[] evenArray(int n) {
//产生n个随机偶数
int[] array = new int[n];
for (int i = 0; i < n; i++) {
array[i] = i * 2;
}
return array;
}
public static int[] lowSameArray(int n) {
//产生n个特殊的数
int[] array = new int[n];
Random r = new Random();
for (int i = 0; i < n; i++) {
array[i] = r.nextInt() & 0x7FFF0002;
}
return array;
}


结论
- 计算对象的HashCode(),在进行调用HashMap的hash()方法进行二次哈希,最后 & (capacity - 1)得到索引
- 二次hash()是为了提高数位数据,让哈希分布更为均匀.
- 计算索引时,如果是2的n次幂可以使用位于运算代替取模,效率更高; 扩容时hash & oldCap==0的元素保留在原来位置,否则新位置 = 旧位置 + oldCap
- 但 1、2、3都是为了配合容量为2的n次幂时的优化手段.也就是说如果 hash 表的容量不是 2 的 n 次幂,则不必二次 hash. 设计者应该是综合了各种因素,最终选择了使用2的n次幂作为容量.
- 没有采用这一设计的典型例子是 Hashtable
一句话:容量是 2 的 n 次幂 这一设计计算索引效率更好,但 hash 的分散性就不好,需要二次 hash 来作为补偿. 如果容量不是 2 的 n 次幂,那么1,2,3这些手段也用不上.
**补充:**HashTable的扩容机制

可以看到扩容的容量中有一些还并不是质数. 微软的.NET中的Dictionary每次扩容的时候,容量大于等于原有空间的2倍的最小质数,这种扩容规则就会让Hash分布更为均匀.
所以:如果要追求效率,则选择2^n作为容量.如果想要追求各个挺好的Hash分布性,则选择一个质数选择Hash容量.
4.6 HashMap的put方法
4.6.1 put过程分析
- HashMap 是懒惰创建数组的,首次使用才创建数组 (首次使用put方法才创建数组)
- 计算索引(桶下标) (通过key计算hash值,然后进行二次hash,进行位与运算得到下标)
- 如果桶下标还没人占用,创建 Node(JDK1.7是Entry对象) 占位返回
- 如果桶下标已经有人占用
- 已经是 TreeNode 走红黑树的添加或更新逻辑
- 是普通 Node,走链表的添加或更新逻辑,如果链表长度超过树化阈值,走树化逻辑
- 返回前检查容量是否超过阈值,一旦超过进行扩容 (添加完成才进行扩容的)
4.6.2 1.7 与 1.8 的区别
-
链表插入节点时,1.7 是头插法,1.8 是尾插法
-
1.7 是大于等于阈值且没有空位时才扩容,而 1.8 是大于阈值就扩容 =>(1.7如果 个数 >= 阈值,并且加入元素时对应下标有元素,才扩容.这俩条件都需要满足.)
-
1.8 在扩容计算 Node 索引时,会优化 (即位与运算)
以上由于过程比较简单,不再进行图解演示.
**问题:**当加入元素扩容时.是先加入元素到旧数组后再进行扩容,还是先扩容再把元素加入新数组呢?
先把元素加入到旧数组,扩容,再迁移元素.
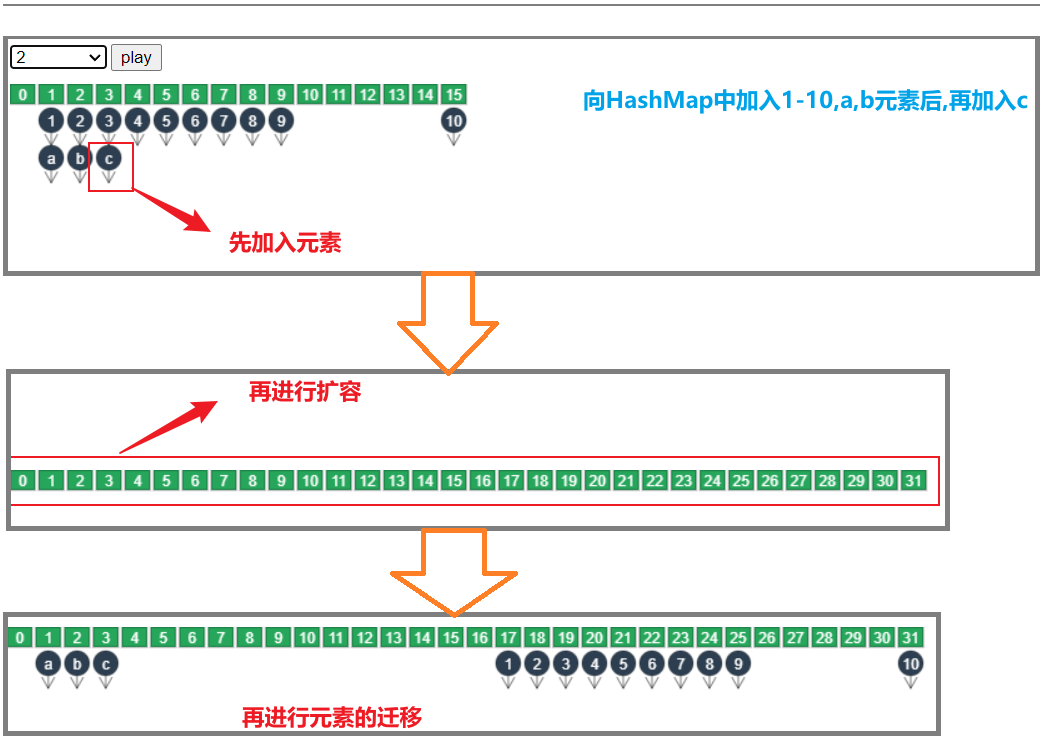
4.6.3 扩容(加载)因子为何默认是 0.75f
- 在空间占用与查询时间之间取得较好的权衡
- 大于这个值,空间节省了,但链表就会比较长影响性能 (比如取1)
- 小于这个值,冲突减少了,但扩容就会更频繁,空间占用也更多 (比如取0.2)
4.7 并发问题
- 数据错乱(1.7,1.8 都会存在)
代码演示
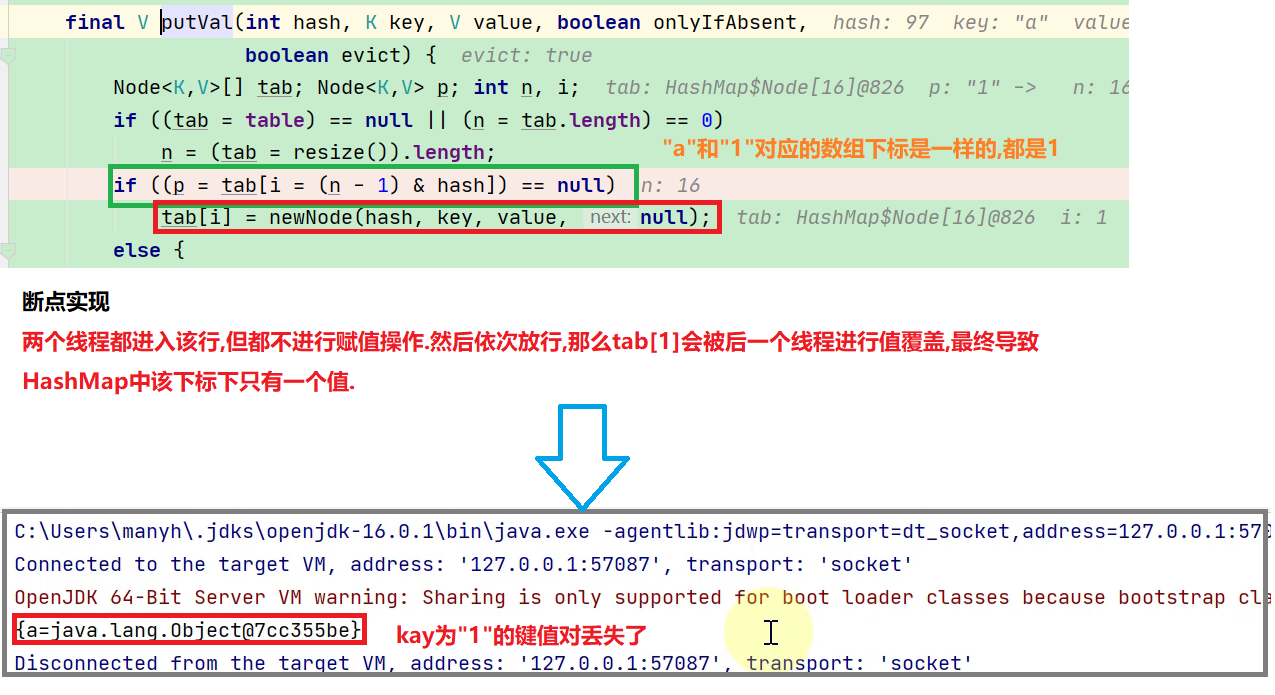
public class HashMapMissData {
public static void main(String[] args) throws InterruptedException {
HashMap<String, Object> map = new HashMap<>();
Thread t1 = new Thread(() -> {
map.put("a", new Object()); // 97 => 1
}, "t1");
Thread t2 = new Thread(() -> {
map.put("1", new Object()); // 49 => 1
}, "t2");
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(map);
}
}
运行结果分析
- 扩容死链(1.7 会存在)
1.7 源码如下:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
单线程环境下数据的迁移:
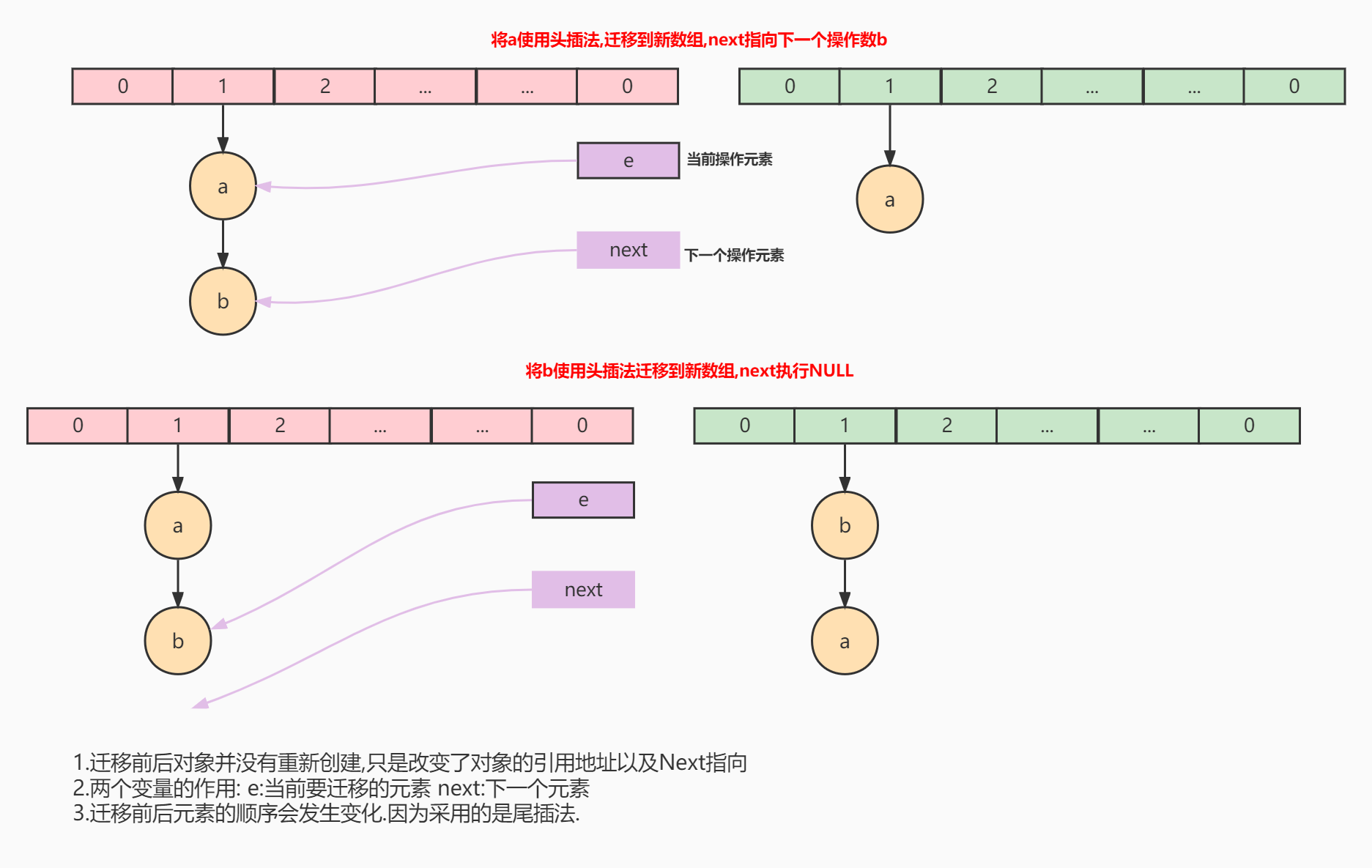
多线程环境下数据的迁移:
- e 和 next 都是局部变量,用来指向当前节点和下一个节点
- 线程1(绿色)的临时变量 e 和 next 刚引用了这俩节点,还未来得及移动节点,发生了线程切换,由线程2(蓝色)完成扩容和迁移
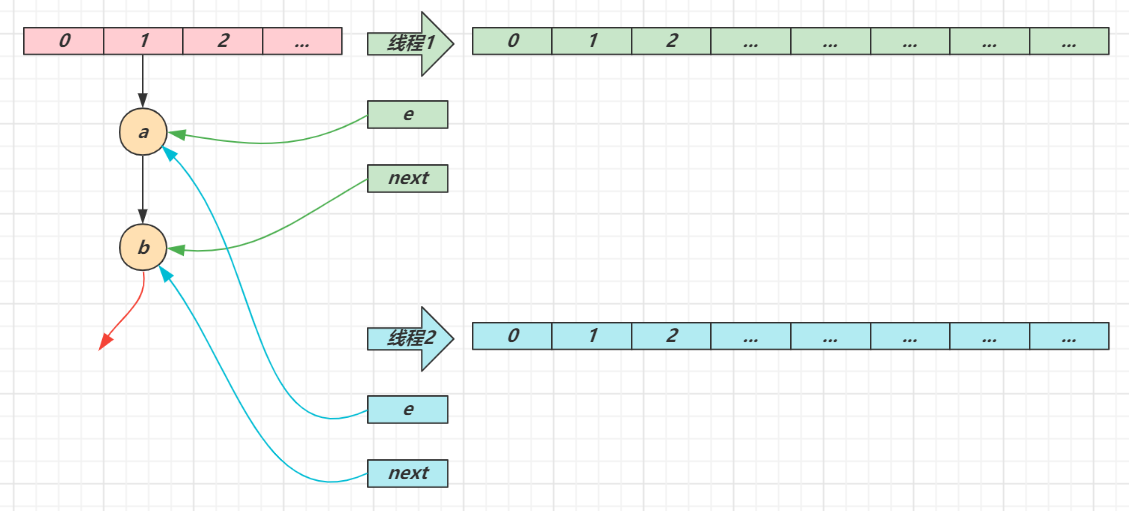
- 线程2 扩容完成,由于头插法,链表顺序颠倒。但线程1 的临时变量 e 和 next 还引用了这俩节点,还要再来一遍迁移
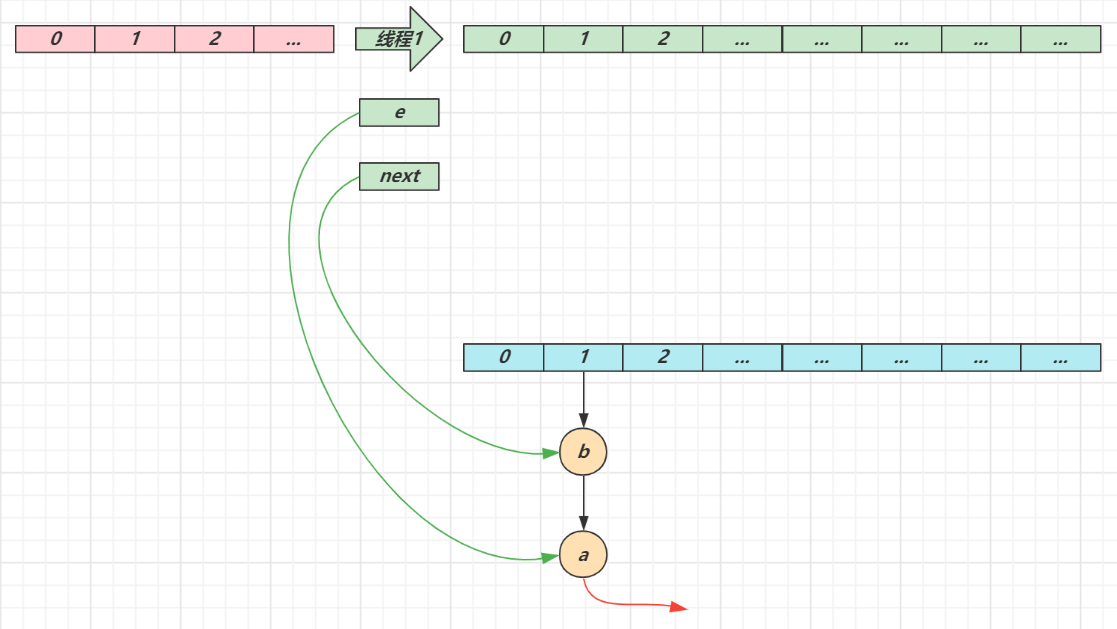
- 第一次循环
- 循环接着线程切换前运行,注意此时 e 指向的是节点 a,next 指向的是节点 b
- e 头插 a 节点,注意图中画了两份 a 节点,但事实上只有一个(为了不让箭头特别乱画了两份)
- 当循环结束是 e 会指向 next 也就是 b 节点
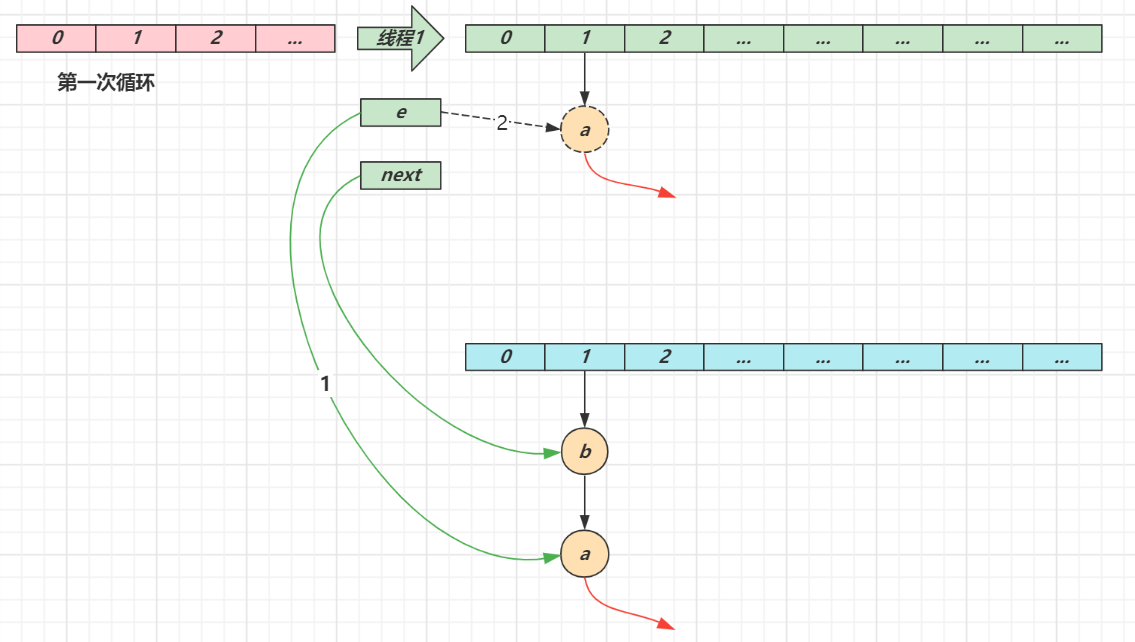
- 第二次循环
- next 指向了节点 a
- e 头插节点 b
- 当循环结束时,e 指向 next 也就是节点 a
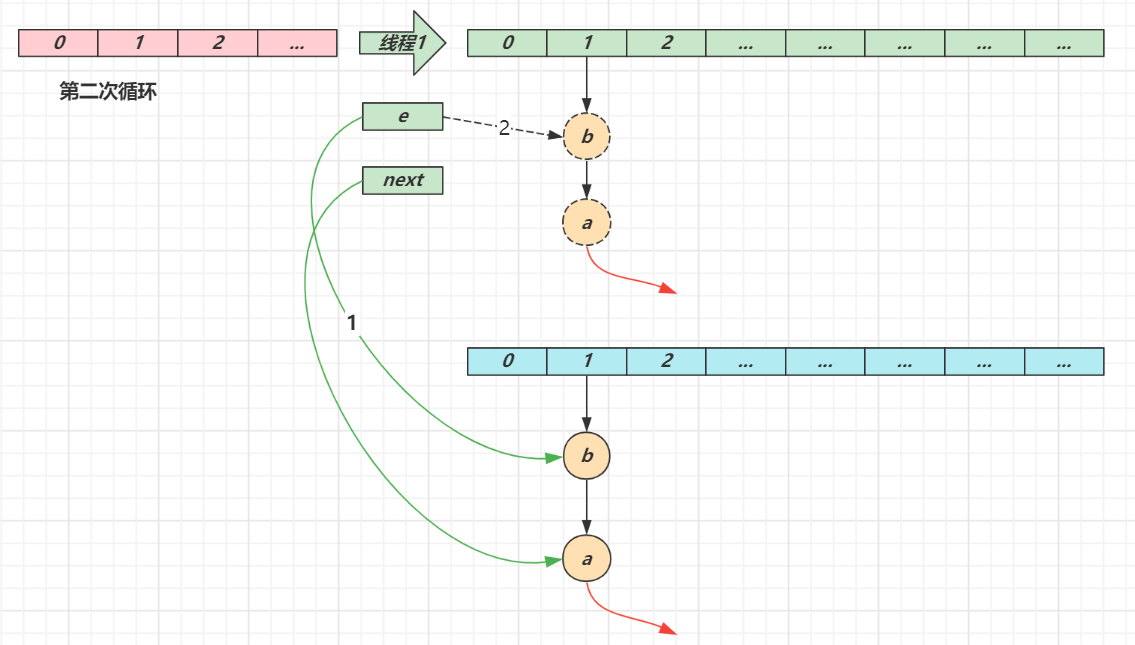
- 第三次循环
- next 指向了 null
- e 头插节点 a,a 的 next 指向了 b(之前 a.next 一直是 null),b 的 next 指向 a,死链已成
- 当循环结束时,e 指向 next 也就是 null,因此第四次循环时会正常退出
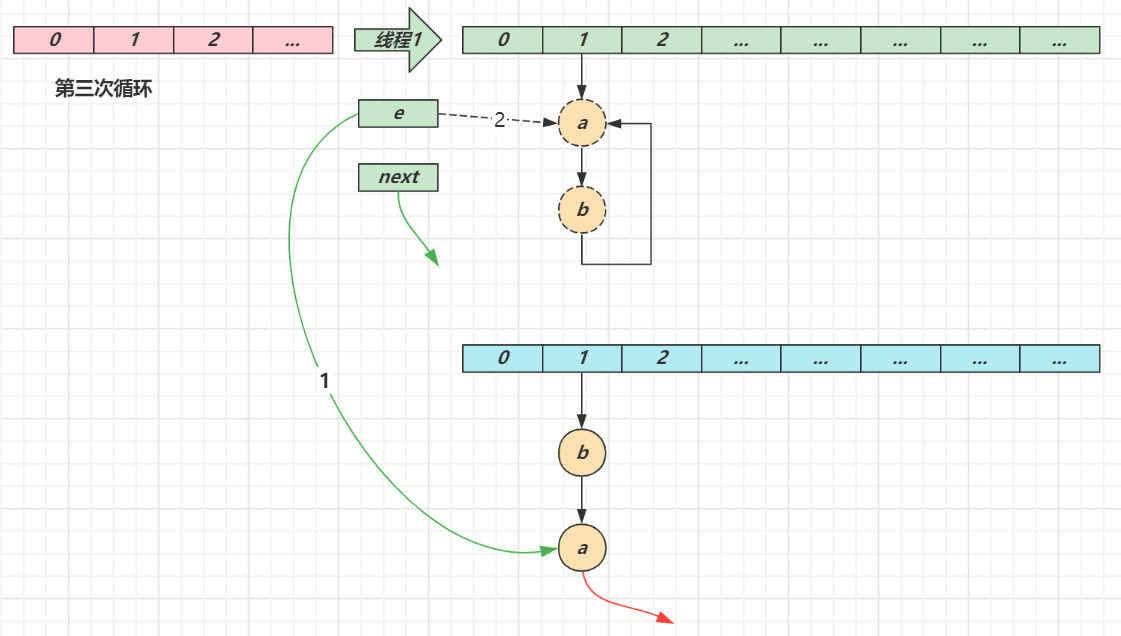
4.8 key 的设计
4.8.1 key 的设计要求
- HashMap 的 key 可以为 null,但 Map 的其他实现则不然 (比如TreeMap, HashTable. ConcurrentHashMap, 如果为Null,则报空指针)
- 作为 key 的对象,必须实现 hashCode 和 equals,并且 key 的内容不能修改(不可变)
- 解释:实现hashCode是为了让其具有更好的分布性,equals是为了当hash值相同时用equals判断是否为同一个对象.
- key 的 hashCode 应该有良好的散列性
如果 key 可变,例如修改了 age 会导致再次查询时查询不到
public class HashMapMutableKey {
public static void main(String[] args) {
HashMap<Student, Object> map = new HashMap<>();
Student stu = new Student("张三", 18);
map.put(stu, new Object());
System.out.println(map.get(stu));
stu.age = 19;//修改key
System.out.println(map.get(stu));
}
static class Student {
String name;
int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
}

4.8.2 String 对象的 hashCode() 设计
- 目标是达到较为均匀的散列效果,每个字符串的 hashCode 足够独特
- 字符串中的每个字符都可以表现为一个数字,称为 S i S_i Si,其中 i 的范围是 0 ~ n - 1
- 散列公式为: S 0 ∗ 3 1 ( n − 1 ) + S 1 ∗ 3 1 ( n − 2 ) + … S i ∗ 3 1 ( n − 1 − i ) + … S ( n − 1 ) ∗ 3 1 0 S_0∗31^{(n-1)}+ S_1∗31^{(n-2)}+ … S_i ∗ 31^{(n-1-i)}+ …S_{(n-1)}∗31^0 S0∗31(n−1)+S1∗31(n−2)+…Si∗31(n−1−i)+…S(n−1)∗310
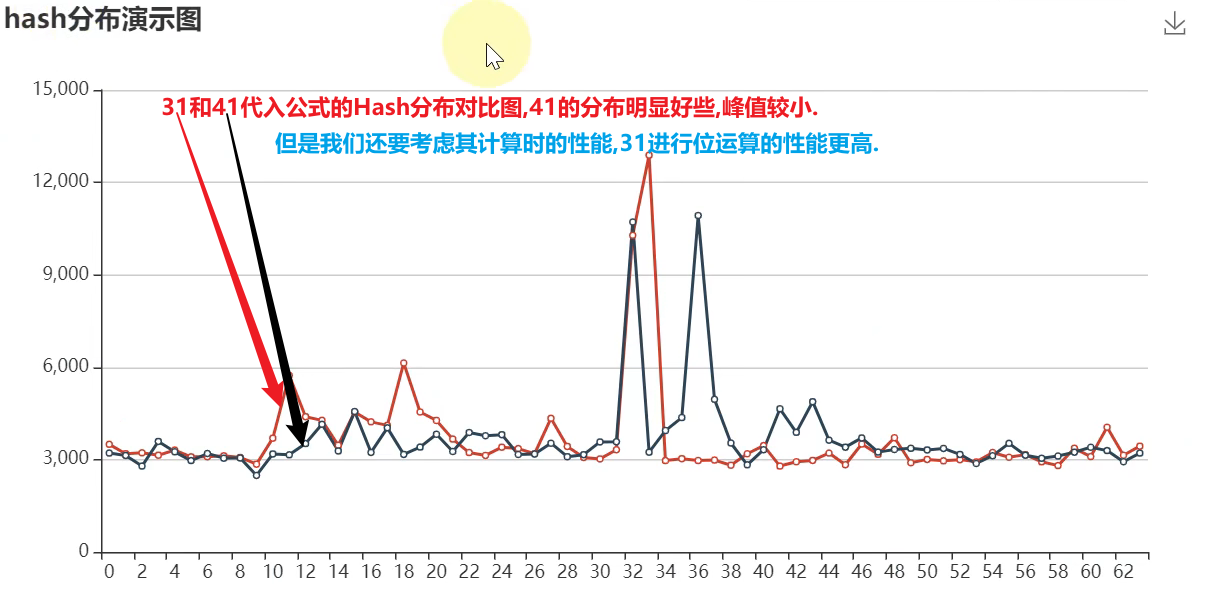
- 31 代入公式有较好的散列特性,并且 31 * h 可以被优化为
- 即 $32 ∗h -h $
- 即 2 5 ∗ h − h 2^5 ∗h -h 25∗h−h
- 即 h ≪ 5 − h h≪5 -h h≪5−h
散列分布对比图
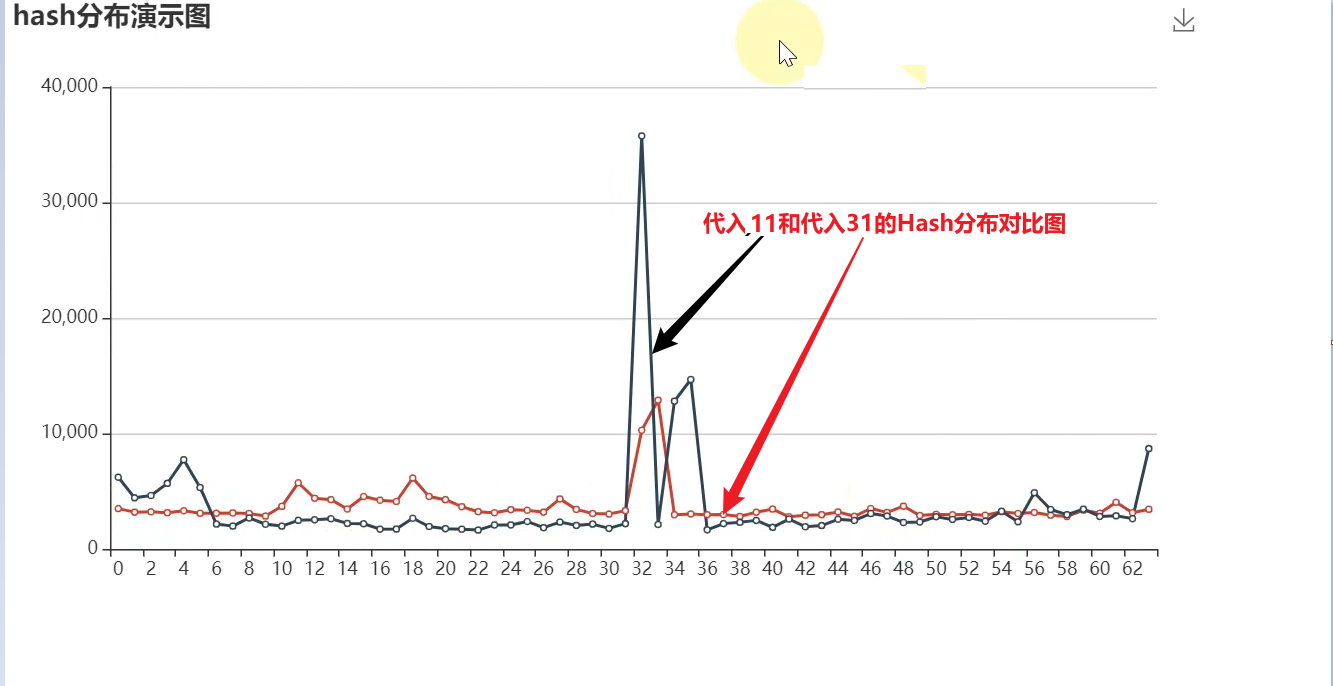
4.9 HashMap的相关面试题总结
要求
- 掌握 HashMap 的基本数据结构
- 掌握树化
- 理解索引计算方法、二次 hash 的意义、容量对索引计算的影响
- 掌握 put 流程、扩容、扩容因子
- 理解并发使用 HashMap 可能导致的问题
- 理解 key 的设计
4.9.1 基本数据结构
- 1.7 数组 + 链表
- 1.8 数组 + (链表 | 红黑树)
更形象的演示,见资料中的 hash-demo.jar,运行需要 jdk14 以上环境,进入 jar 包目录,执行下面命令
java -jar --add-exports java.base/jdk.internal.misc=ALL-UNNAMED hash-demo.jar
4.9.2 树化与退化
为何要用红黑树,为何一上来不树化? 树化阈值为啥是8,何时会树化,何时会退化为链表?
树化意义
- 红黑树用来避免 DoS 攻击,防止链表超长时性能下降,树化应当是偶然情况,是保底策略
- hash 表的查找,更新的时间复杂度是 O ( 1 ) O(1) O(1),而红黑树的查找,更新的时间复杂度是 O ( l o g 2 n ) O(log_2n ) O(log2n),TreeNode 占用空间也比普通 Node 的大,如非必要,尽量还是使用链表
DOS攻击:不断的向hashMap中加入hash值相同的元素,从而使链表长度增加,元素的查找速度下降.导致系统性能下降.
树化阈值
- hash 值如果足够随机,则在 hash 表内按泊松分布,在负载因子 0.75 的情况下,长度超过 8 的链表出现概率是 0.00000006,树化阈值选择 8 就是为了让树化几率足够小
树化规则
- 当链表长度超过树化阈值 8 时,先尝试扩容来减少链表长度,如果数组容量已经 >=64,才会进行树化
退化规则
- 情况1:在扩容时如果拆分树时,树元素个数 <= 6 则会退化链表
- 情况2:remove 树节点时,若 root、root.left、root.right、root.left.left 有一个为 null ,也会退化为链表
4.9.3 索引计算
索引计算方法
- 首先,计算对象的 hashCode() ==》原始Hash
- 再进行调用 HashMap 的 hash() 方法进行二次哈希
- 二次 hash() 是为了综合高位数据,让哈希分布更为均匀
- 最后 & (capacity – 1) 得到索引
数组容量为何是 2 的 n 次幂
- 计算索引时效率更高:如果是 2 的 n 次幂可以使用位与运算代替取模
- 扩容时重新计算索引效率更高: hash & oldCap == 0 的元素留在原来位置 ,否则新位置 = 旧位置 + oldCap
注意
- 二次 hash 是为了配合 容量是 2 的 n 次幂 这一设计前提,如果 hash 表的容量不是 2 的 n 次幂,则不必二次 hash
- 容量是 2 的 n 次幂 这一设计计算索引效率更好,但 hash 的分散性就不好,需要二次 hash 来作为补偿,没有采用这一设计的典型例子是 Hashtable
4.9.4 put 与扩容
put 流程
- HashMap 是懒惰创建数组的,首次使用才创建数组
- 计算索引(桶下标)
- 如果桶下标还没人占用,创建 Node 占位返回
- 如果桶下标已经有人占用
- 已经是 TreeNode 走红黑树的添加或更新逻辑
- 是普通 Node,走链表的添加或更新逻辑,如果链表长度超过树化阈值,走树化逻辑
- 返回前检查容量是否超过阈值,一旦超过进行扩容
1.7 与 1.8 的区别
-
链表插入节点时,1.7 是头插法,1.8 是尾插法
-
1.7 是大于等于阈值且没有空位时才扩容,而 1.8 是大于阈值就扩容
-
1.8 在扩容计算 Node 索引时,会优化
扩容(加载)因子为何默认是 0.75f
- 在空间占用与查询时间之间取得较好的权衡
- 大于这个值,空间节省了,但链表就会比较长影响性能
- 小于这个值,冲突减少了,但扩容就会更频繁,空间占用也更多
4.9.5 并发问题
扩容死链(1.7 会存在)
数据错乱(1.7,1.8 都会存在)
4.9.6 key 的设计
key 的设计要求
- HashMap 的 key 可以为 null,但 Map 的其他实现则不然 (比如TreeMap, HashTable. ConcurrentHashMap, 如果为Null,则报空指针)
- 作为 key 的对象,必须实现 hashCode 和 equals,并且 key 的内容不能修改(不可变)
- 解释:实现hashCode是为了让其具有更好的分布性,equals是为了当hash值相同时用equals判断是否为同一个对象.
- key 的 hashCode 应该有良好的散列性
String 对象的 hashCode() 设计
- 目标是达到较为均匀的散列效果,每个字符串的 hashCode 足够独特
- 字符串中的每个字符都可以表现为一个数字,称为 S i S_i Si,其中 i 的范围是 0 ~ n - 1
- 散列公式为: S 0 ∗ 3 1 ( n − 1 ) + S 1 ∗ 3 1 ( n − 2 ) + … S i ∗ 3 1 ( n − 1 − i ) + … S ( n − 1 ) ∗ 3 1 0 S_0∗31^{(n-1)}+ S_1∗31^{(n-2)}+ … S_i ∗ 31^{(n-1-i)}+ …S_{(n-1)}∗31^0 S0∗31(n−1)+S1∗31(n−2)+…Si∗31(n−1−i)+…S(n−1)∗310
- 31 代入公式有较好的散列特性,并且 31 * h 可以被优化为
- 即 $32 ∗h -h $
- 即 2 5 ∗ h − h 2^5 ∗h -h 25∗h−h
- 即 h ≪ 5 − h h≪5 -h h≪5−h