前言
这只是一个基础的爬取图片过程,其他图片的爬取大致过程也是这样
爬取原理
图片爬取属于聚焦爬虫,其编码流程大致如下:
- 指定url
- 发起请求
- 获取相应数据
- 数据解析
- 持久化存储、
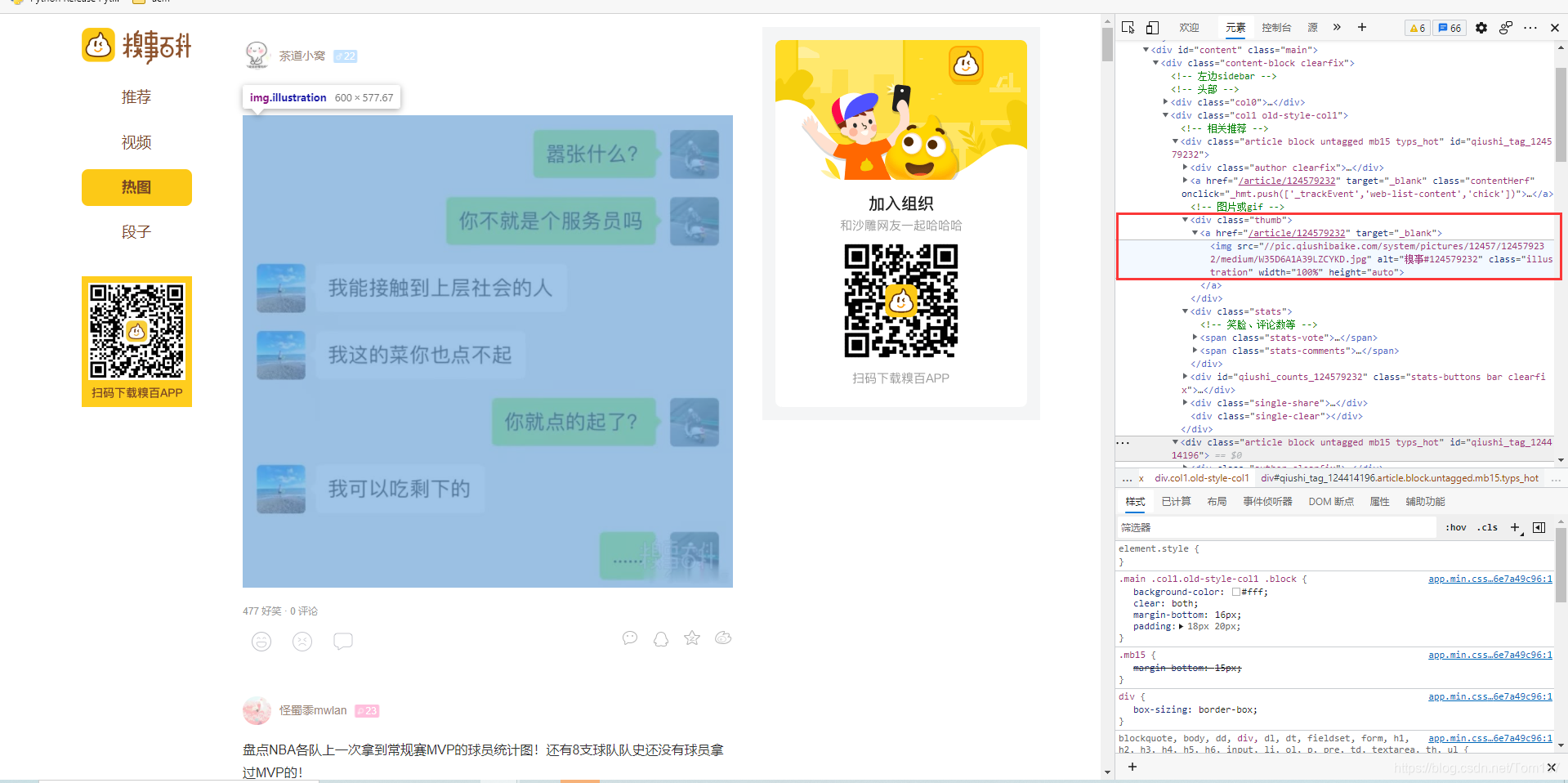
过程:首先要进入 糗事百科 网页,按F12进入爬虫工具页面,通过检查可以发现,图片都存在class =“thumb”的div中,但是这个div中不只是有图片,而且还有图片介绍,我们可以写一段 正则表达式 用来对img单独提取
ex = '<div class="thumb">.*?<img src="(.*?)" alt.*?</div>'
代码
import requests
import re
import os
url ='https://www.qiushibaike.com/imgrank/'
if not os.path.exists('./qiutu'):
os.mkdir('./qiutu')
headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.55'
}
#使用通用爬虫对URL对应一整张页面进行爬取
page_text = requests.get(url=url,headers=headers).text
#使用聚焦爬虫将页面中所有的糗图进行解析提取
ex = '<div class="thumb">.*?<img src="(.*?)" alt.*?</div>'
img_src_list = re.findall(ex,page_text,re.S)
for src in img_src_list:
#拼接出一个完整的图片url
src='https:'+src
# 请求到图片的二进制数据
img_data = requests.get(url=src,headers=headers).content
# 生成图片名称
img_name = src.split('/')[-1]
# 存储路径
imgPath = './qiutu/'+img_name
with open(imgPath,'wb') as fp:
fp.write(img_data)
print(img_name,'打印成功!')
爬取结果