简介
本文将从以下几方面分别介绍 MYSQL 索引相关的知识:
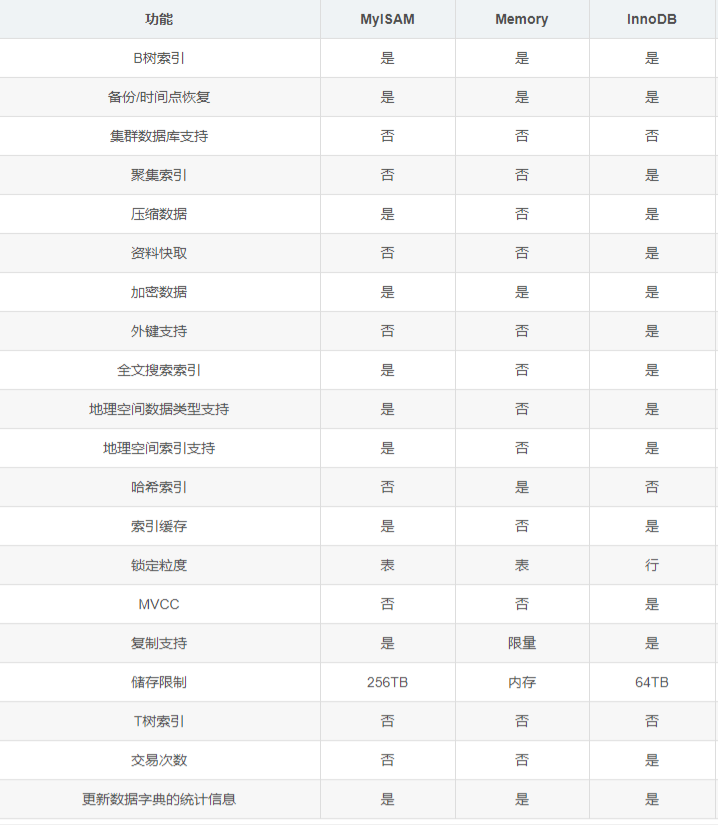
1、mysql 引擎对比:MyISAM、InnoDB、Memory y 引擎各自的优劣;
2、InnoDB 索引原理:为何要用 B+树,B+树可以存储的数据量;
3、索引的分类:聚簇索引 &非聚簇索引、联合索引、唯一索引等,这些索引在 B+树中如何存储及查询;
4、索引的使用:如何使用索引及索引失效的场景,避免踩坑;
mysql 引擎对比
mysql 目前支持的引擎有十几个,可以通过命令 show engines; 来查询自己数据库支持的引擎,mysql 默认的引擎为 InnoDB,我们接下来针对不同的引擎进行一个对比。
我们首先查看我们数据库支持的引擎:

其实日常中主要接触到的引擎就是:MyISAM、InnoDB、Memory,我们接下来针对这三种引擎的优劣做一个总结。
InnoDB 索引原理
mysql 索引使用的 B+树,是由二叉查找树、平衡二叉树和 B 树演化而来,网上类似的文章很多,大家可以自行搜索。简单而言:B+树在保证平衡的情况下,尽可能多的数据,B+树相比 B 树,将数据存储在叶子节点,使得树的阶数一样的情况下,B+树能存储的数据量更大。
首先,B+树的结构如下,非叶子节点存储键值,只有叶子节点存储数据。

B+树能存储的数据量
我们来看下一棵高度为 3 的 B+树,能存储的数据量。我们都知道,操作系统中磁盘的读取都是以页为单位,默认为 4kb(历史遗留,以现在机器的性能完全可以调整为 16kb 甚至更高),而在 mysql 中,读取数据时,也是按照页进行读取,msyql 中默认的页大小为 16kb,我们以 bigint 类型当索引为例,bigint 类型的大小为 8 字节,在 B+树中除了存储键值还有一个指针,指针的大小为 6 字节,因此,mysql 中一页可以存储的键值和指针数量为:16Kb/(8byte+6byte) = 16*1024byte/14byte = 1170,而在单个叶子节点中,记录数据大小通常设定为 1k,因此,当树高度为 2 时,数据量为 1170*16,高度为 3 时,达到千万级别。
B+树查询插入的策略
索引的分类
mysql 中,从不同的维度,将索引分为不同的类型,我们接下来分别详细介绍
聚簇索引和非聚簇索引
在 B+树能存储的数据量中,我们提到每个页中能存 16 条数据,每条数据大小上限为 1kb,这块是针对叶子节点中存储的是 mysql 的数据行而言,在 mysql 索引中,叶子节点存储的数据分为两种情况:1、索引为主键,叶子节点存储完整的数据行;2、索引为非主键,叶子节点存储的是主键指针,当需要获取完整的数据时,需要回表到聚簇索引中查询得到数据。mysql 官方对聚簇索引的解释:
The InnoDB term for a primary key index. InnoDB table storage is organized based on the values of the primary key columns, to speed up queries and sorts involving the primary key columns. For best performance, choose the primary key columns carefully based on the most performance-critical queries. Because modifying the columns of the clustered index is an expensive operation, choose primary columns that are rarely or never updated.
eg:我们假设建用户表,包含自增 id 为主键,以及年龄字段,下图左侧为聚簇索引,叶子节点存储整行数据,右侧为非聚簇索引,年龄设置的索引,叶子节点存储的是自增 id,因此根据年龄获取用户的姓名等信息时,需要根据 id 在次从聚簇索引中查询整条记录(回表:回表会带来额外的磁盘开销,因此需要尽量避免回表)。

唯一索引和普通索引
普通索引可以重复,唯一索引和主键一样,在表中唯一,不能重复
我们首先来介绍以下唯一索引和普通索引的查询过程
-
唯一索引,eg:select * from user where id = 110; 使用二分法,快速查找到 id=110 的记录后,停止检索直接返回数据;
-
普通索引,eg: select * from user where age = 50; 使用二分法快速查到 age 为 50 的记录,我们需要继续查找下一条记录,直到找到 age 不等于 50 的结束检索。因此,在普通索引查询的过程中,mysql 页大小为 16kb,数据过多的情况下,需要从磁盘中按页读取,这也是数据区分度不高的情况下,为什么不建议设索引。
我们了解了索引的查询过程,接下来需要继续了解当插入数据时,索引如何更新?
我们先来了解两个概念,change buffer 和 merge,change buffer 是将要更新的操作缓存下来,当下次数据加载到内存后,通过 merge 操作,将更新的操作同步,保证数据的正确性。
-
唯一索引:由于唯一索引需要判断是否重复,在这个过程中,需要将记录加载到内存中,因此在插入时,可以直接更新到内存中
-
普通索引:普通索引无需判重,因此先检查数据页是否在内存中,在的话直接插入,否则记录到 change buffer 中,等待 merge
merge 的时机
-
访问数据页码
-
后台定期 merge
-
数据库正常关闭
因此,change buffer 是否使用,取决于数据在插入后,是否会立即读取,如果立马读取,则 change buffer 的维护会有代价,带来副作用。
索引的使用
避免回表
我们可以看下图,当通过年龄查询用户时,由于非聚簇索引叶子节点存储的时主键(用户 id),因此,如果我们查询过程中,只需要用户 id 时,避免使用 select id, name from user where age = 10 这样的查询,由于查询结果需要查 name 字段,需要回表。
索引失效的场景
1、使用 like 查询时,通配符在前
2、对索引列进行函数运算(eg:create_time 字段创建了索引,在查询的 where 中:DATE_FORMATE(create_time)==“2222-02-12”)
3、计算导致索引失效(eg: where record_id+1 = 2)
4、类型转换导致索引试下(eg:where name=888,name 在数据库中是 varchar 类型,因此会进行隐形转换)
5、未遵循最左前缀匹配(eg:设置了联合索引:a、b、c,但在查询时,使用 where b = 1 and c = 2)
6、范围索引字段后的索引字段生效(eg:设置了联合索引:a、b、c,但在查询时,使用 where a = 1 and b > 3 and c = 3,这样 b 之后的索引就不生效了)
7、不等于(<>、!)索引失效
8、索引使用 is not null
9、使用 or
索引下推
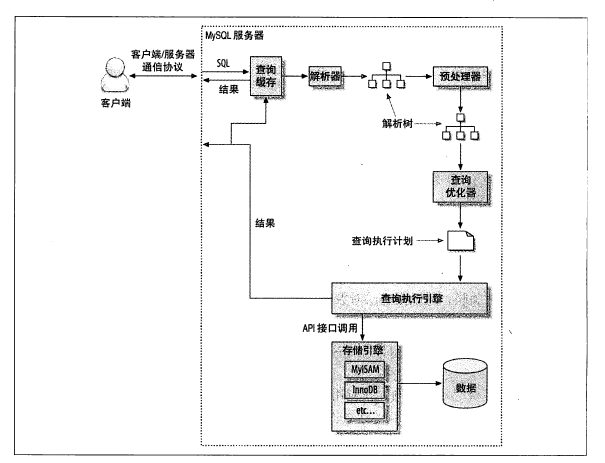
我们可以先看下客户端到服务器的查询过程:
-
客户端向服务端发送一条查询;
-
服务器首先查询缓存(8.0 开始不再支持查询缓存),命中则直接返回,否则继续下一步骤;
-
服务器进行 sql 语句解析,然后经过预处理器、优化器生成相应的执行计划;
-
根据执行计划,调用引擎 api 进行查询;
-
将数据返回给客户端。
索引下推 的下推其实时将部分上层(服务层)负责的事情,交给下层(引擎层)去处理。
我来来看个例子:现在有联合索引:r1、r2、r3
查询 sql: select * from user where r1 = 1 and r2 >= 50 and r3 = 1 and r4 = 11;
当不使用 ICP(索引下推时),查询过程如下:
1、mysql 服务层解析、预处理、优化后生成查询计划,调用存储引擎 api;
2、存储引擎读索引,索引过滤 r1=1,由于 r2>50 是范围查询,索引失效不查询,然后将符合 r1=1 的结果返回给服务层;
3、服务层再过滤 r2>50 and r3 = 1 and r4 = 11,将结果返回给客户端;
当使用 ICP 时,查询过程如下:
1、mysql 服务层解析、预处理、优化后生成查询计划,调用存储引擎 api;
2、存储引擎读索引,索引过滤 r1=1,同时将 r2>50 and r3 = 1 也过滤掉,将结果返回给服务层;
3、服务层再过滤 r4=11,将结果返回给客户端;
我们可以看到,当使用索引下推时,存储引擎和服务层之间传输的数据变少,减少了网络开销,但索引下推仅适用于二级索引,由于聚簇索引叶子节点存储的就是整行数据,没有减少磁盘 IO。