CRNN描述
CRNN是一种基于图像序列识别的神经网络,应用于场景文本识别。本文研究了场景文本识别问题,这是基于图像序列识别中最重要和最具挑战的任务之一。本文提出了一种新的神经网络结构,将特征提取、序列建模和转录集成到统一框架中。与以前的场景文本识别系统相比,本文提及的架构具有四个特性:(1)端到端可训练,不像现有算法,大多数都是单独训练和调整组件。(2)自然处理任意长度序列,不涉及字符分割或水平尺度标准化。(3)不局限于预定义词典,在无词典和基于词典的场景文本识别任务中都取得了显著的性能。(4)生成有效且更小的模型,在现实的应用场景中更实用。
论文: Baoguang Shi, Xiang Bai, Cong Yao, “An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition”, ArXiv, vol. abs/1507.05717, 2015.
模型架构
CRNN使用vgg16结构进行特征提取,附加两层双向LSTM,最后使用CTC计算损失。有关详细信息,请参见src/crnn.py。我们提供了2个版本的网络,使用不同的方法将hidden size传到class
numbers。您可以通过修改config.yaml中的model_version来选择不同版本。V1中,RNN之后增加了全连接层。 V2中,更改最后一个RNN的输出特征大小,输出具有相同分类数的特征。V2中,切换到内置LSTM
cell,而不是DynamicRNN算子,这样GPU和Ascend上都支持该模型。
体验MindSpore ModelZoo中的CRNN模型
如果你对MindSpore感兴趣,可以关注昇思MindSpore社区
一、环境准备
1.进入ModelArts官网
云平台帮助用户快速创建和部署模型,管理全周期AI工作流,选择下面的云平台以开始使用昇思MindSpore,可以在昇思教程中进入ModelArts官网
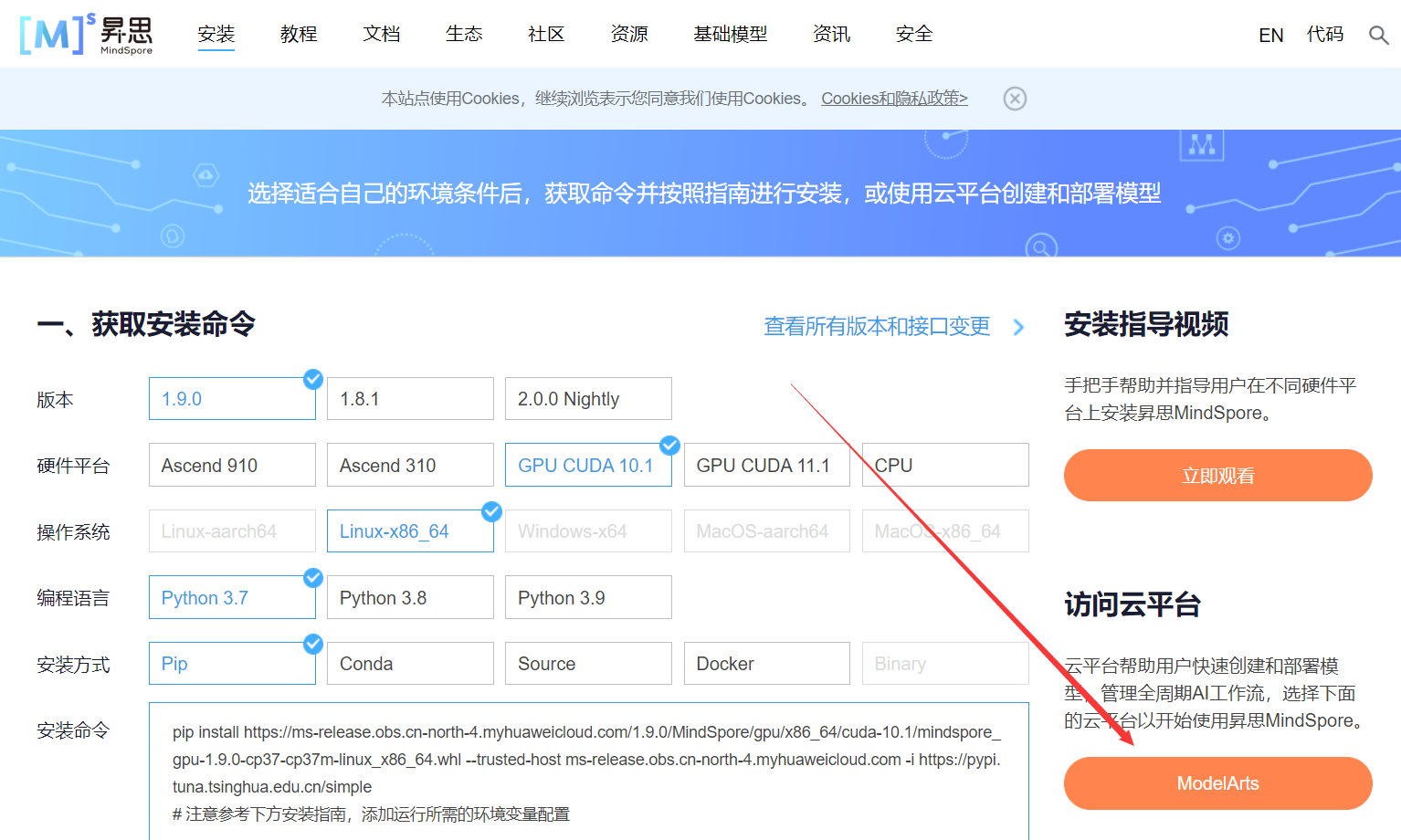
选择下方CodeLab立即体验
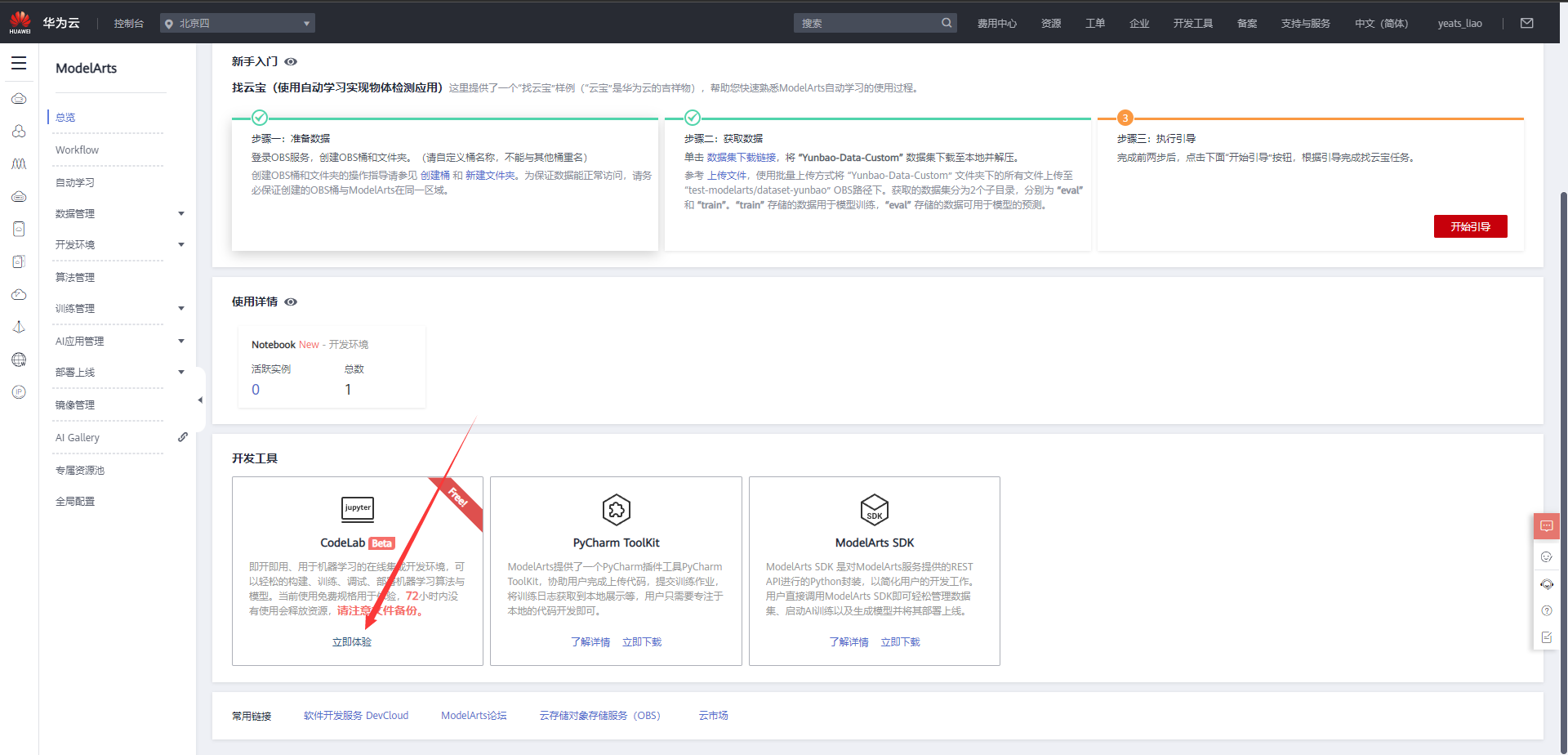
等待环境搭建完成
2.使用CodeLab体验Notebook实例
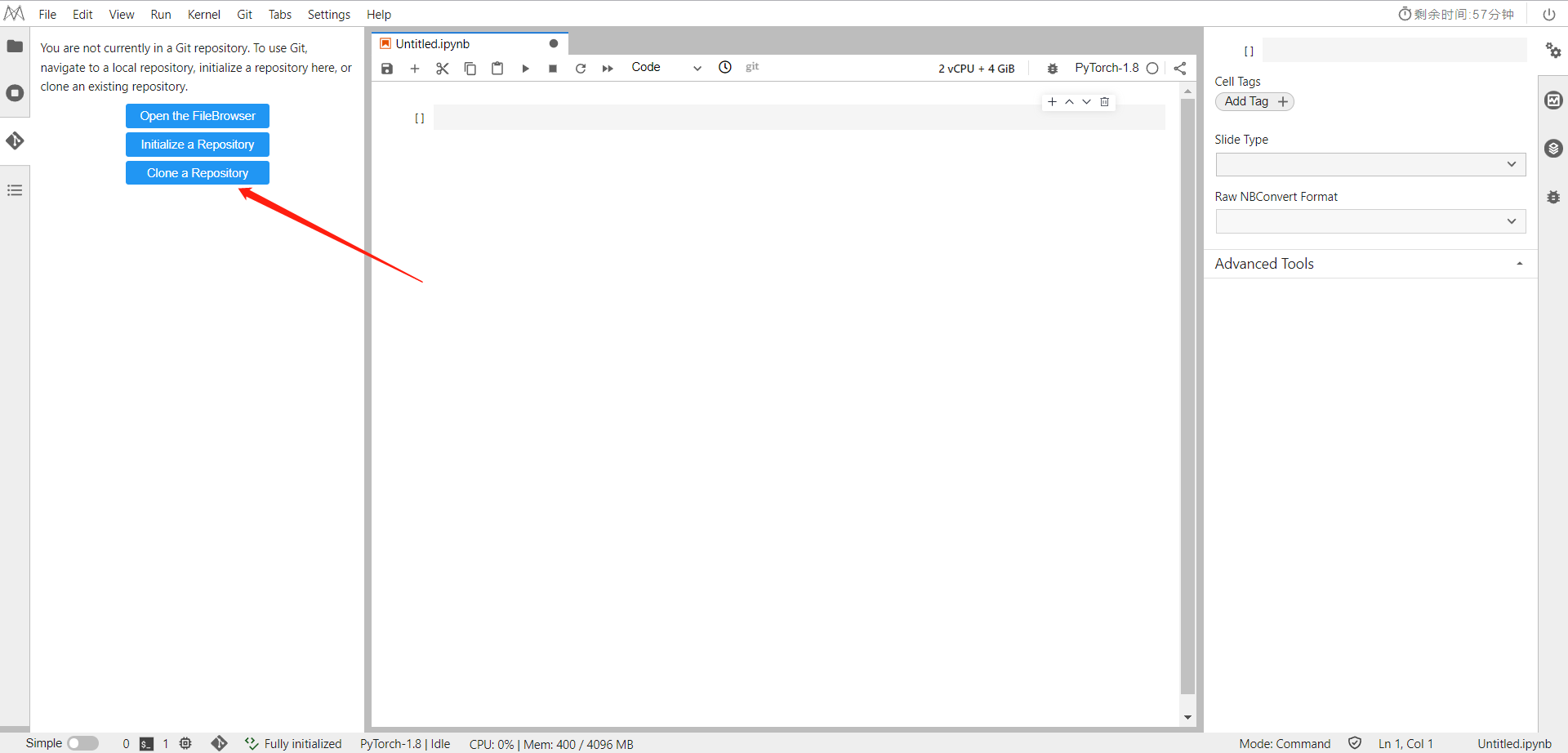
导入项目仓库,在CodeLab中Clone以下命令
https://gitee.com/mindspore/models.git
导入成功
在右侧切换规格为GPU架构
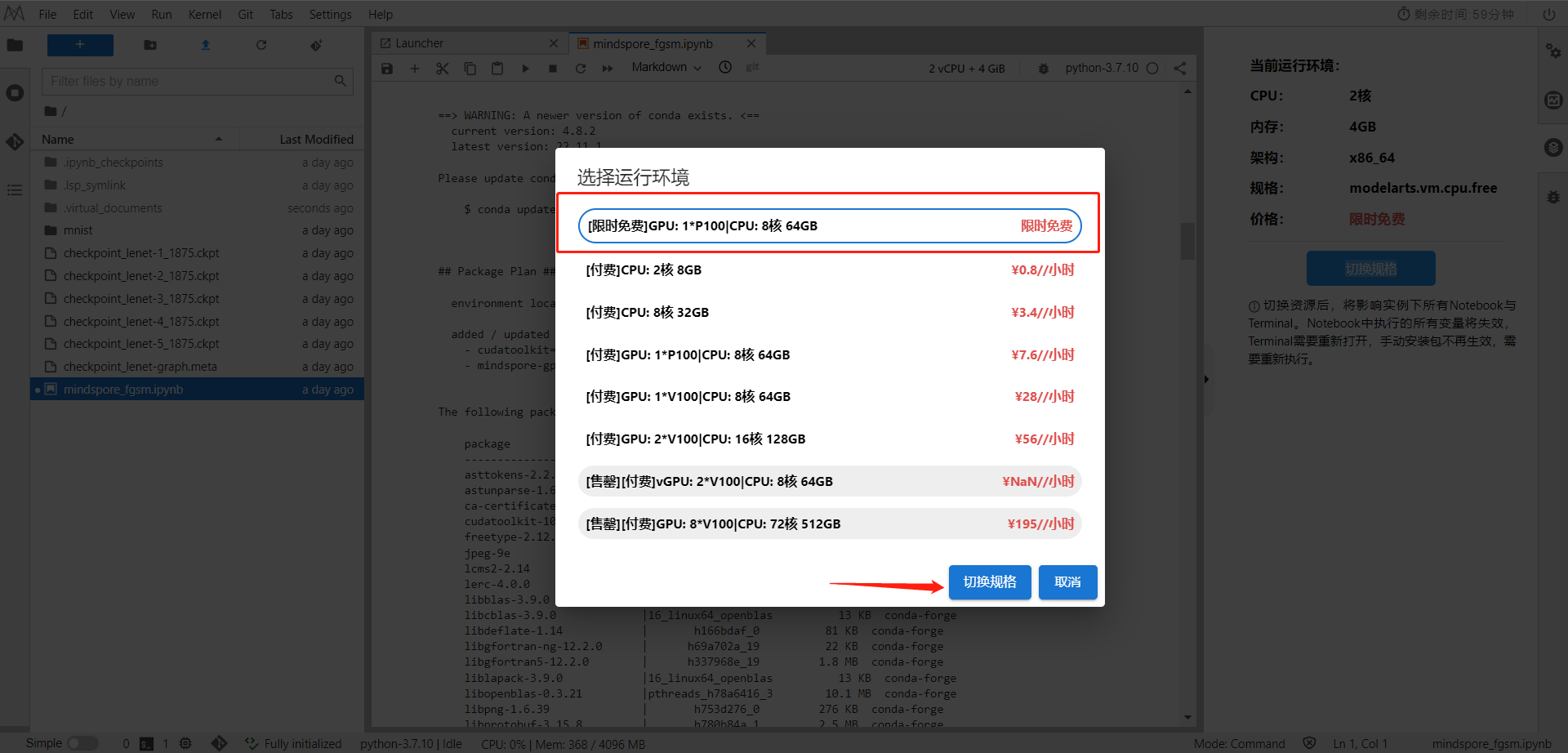
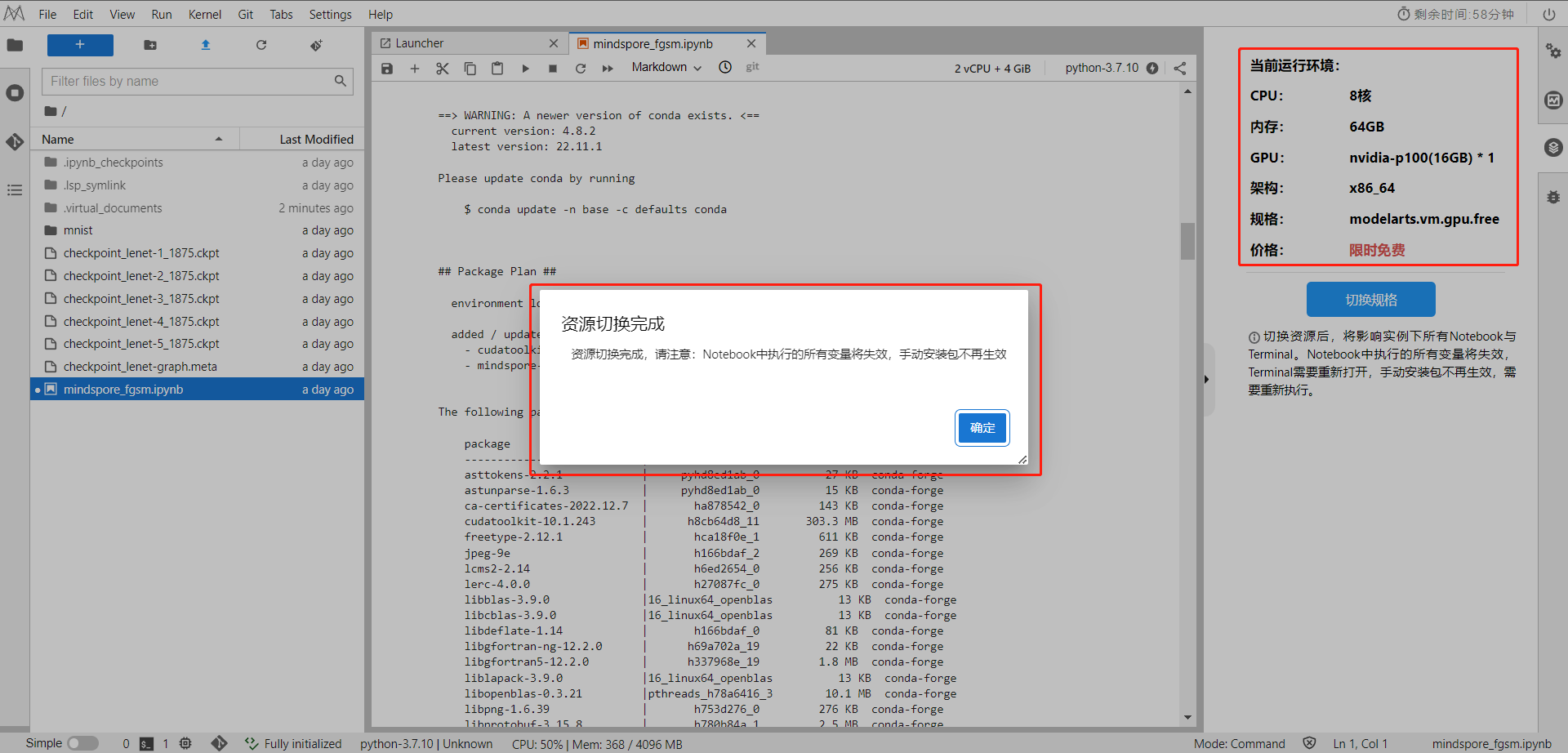
切换成功显示如下
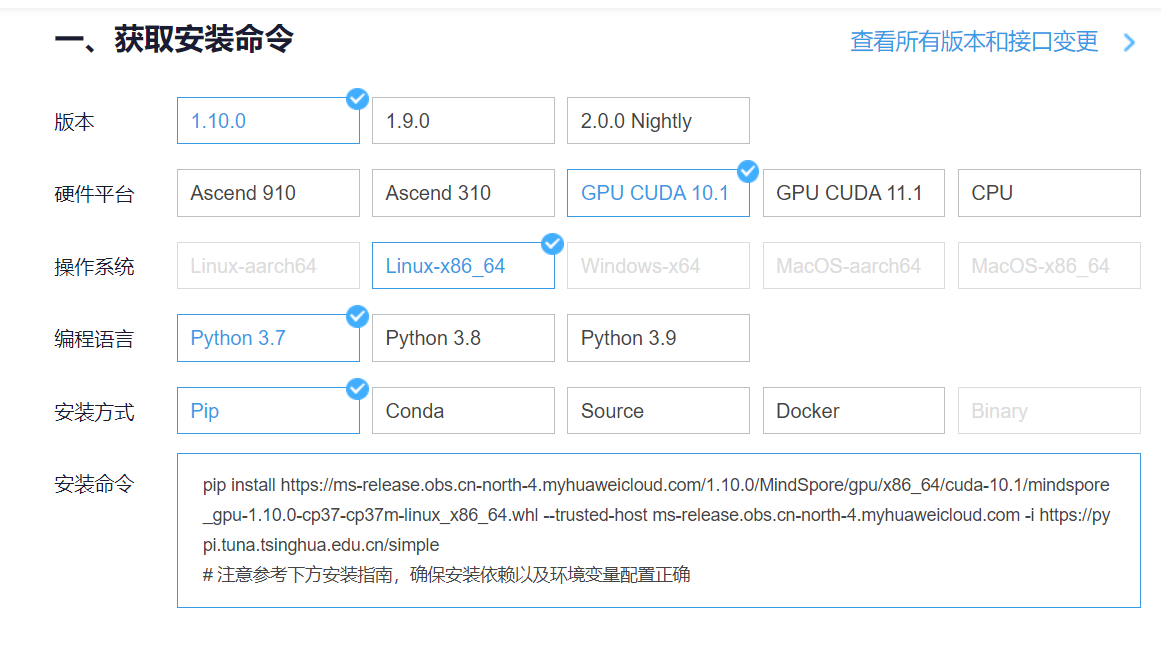
进入昇思MindSpore官网,点击上方的安装

获取安装命令
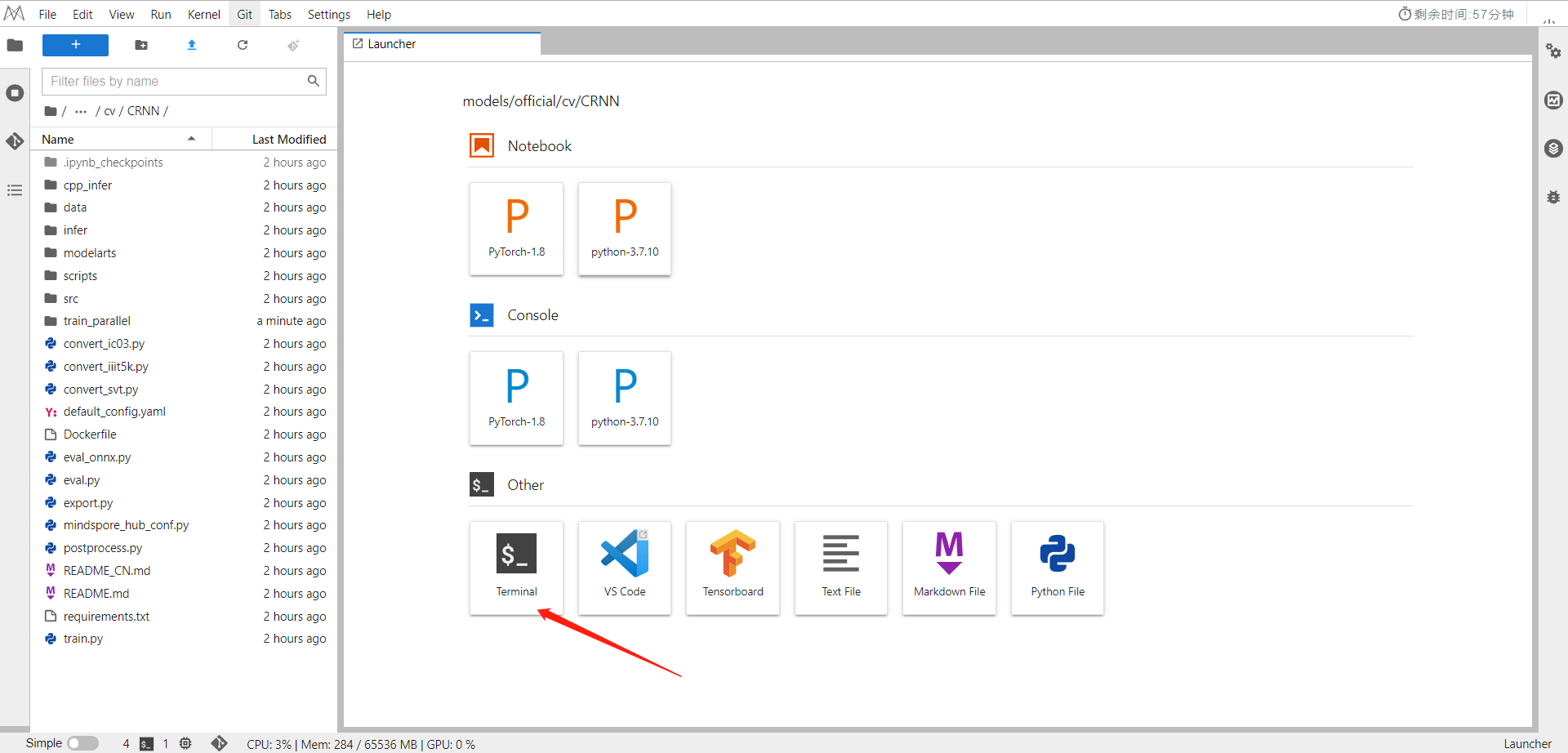
回到Notebook中,选择Terminal,依次运行命令
pip install --upgrade pip
conda install mindspore-gpu=1.9.0 cudatoolkit=10.1 -c mindspore -c conda-forge
pip install mindvision
依次运行即可

二、脚本说明
脚本及样例代码
crnn
├── README.md # CRNN描述
├── convert_ic03.py # 转换原始IC03数据集
├── convert_iiit5k.py # 转换原始IIIT5K数据集
├── convert_svt.py # 转换原始SVT数据集
├── requirements.txt # 数据集要求
├── scripts
│ ├── run_standalone_train_cpu.sh # 在CPU中启动单机训练
│ ├── run_eval_cpu.sh # 在CPU中启动评估
│ ├── run_distribute_train.sh # 在Ascend或GPU中启动分布式训练(8卡)
│ ├── run_eval.sh # 在Ascend或GPU中启动评估
│ └── run_standalone_train.sh # 在Ascend或GPU中启动单机训练(单卡)
│ └── run_eval_onnx.sh # Eval ONNX模型
├── src
│ ├── model_utils
│ ├── config.py # 参数配置
│ ├── moxing_adapter.py # ModelArts设备配置
│ └── device_adapter.py # 设备配置
│ └── local_adapter.py # 本地设备配置
│ ├── crnn.py # CRNN网络定义
│ ├── crnn_for_train.py # CRNN网络,带梯度、损失和梯度裁剪
│ ├── dataset.py # 训练和评估数据预处理
│ ├── eval_callback.py
│ ├── ic03_dataset.py # IC03数据预处理
│ ├── ic13_dataset.py # IC13数据预处理
│ ├── iiit5k_dataset.py # IIIT5K数据预处理
│ ├── loss.py # CTC损失定义
│ ├── metric.py # CRNN网络的准确率指标
│ └── svt_dataset.py # SVT数据预处理
└── train.py # 训练脚本
├── eval.py # 评估脚本
├── eval_onnx.py # ONNX模型评估脚本
├── default_config.yaml # 配置文件
训练脚本参数
# Ascend或GPU分布式训练
用法:bash scripts/run_distribute_train.sh [DATASET_NAME] [DATASET_PATH] [PLATFORM] [RANK_TABLE_FILE](if Ascend)
# Ascend或GPU单机训练
用法:bash scripts/run_standalone_train.sh [DATASET_NAME] [DATASET_PATH] [PLATFORM]
# CPU单机训练
用法:bash scripts/run_standalone_train_cpu.sh [DATASET_NAME] [DATASET_PATH]
三、数据集
注:可以运行原始论文中提到的数据集脚本,也可以运行在相关域/网络架构中广泛使用的脚本。下面将介绍如何使用相关数据集运行脚本。
我们使用论文中提到的五个数据集。在训练中,使用Jederberg等人发布的合成数据集(MJSynth和SynthText)作为训练数据,其中包含800万张训练图像及其对应的地面真值词。在评估中,使用四个流行的场景文本识别基准,即ICDAR
2003(IC03)、ICDAR2013(IC13)、IIIT 5k-word(IIIT5k)和街景文本(SVT)。
数据集准备
对于数据集IC03、IIIT5k和SVT,不能直接在CRNN中使用官网的原始数据集。
IC03,需要根据word.xml从原始图像中裁剪文本。 IIIT5k,需要从matlib数据文件中提取标注。
SVT,需要根据train.xml或test.xml从原始图像中裁剪文本。
我们提供了convert_ic03.py、convert_iiit5k.py、convert_svt.py作为上述预处理的示例参考。
将下载的数据集ICDAR 2003 Robust Reading Competitions
,放入data文件夹中

四、训练过程
设置config.py中的选项,包括学习率和其他网络超参。有关数据集的更多信息,请参阅MindSpore数据集准备教程。
运行run_standalone_train.sh进行CRNN模型的非分布式训练,目前支持Ascend和GPU。
bash scripts/run_standalone_train.sh [DATASET_NAME] [DATASET_PATH] [PLATFORM](optional)
bash scripts/run_distribute_train.sh ic03 ./data GPU

可以看到在目录下生成了训练文件夹

分布式训练
在Ascend或GPU上运行run_distribute_train.sh进行CRNN模型的分布式训练
bash scripts/run_distribute_train.sh [DATASET_NAME] [DATASET_PATH] [PLATFORM] [RANK_TABLE_FILE](if Ascend)
检查train_parallel0/log.txt,将得到输出
断点续训练
如果想使用断点续训练功能,运行训练脚本时,[RESUME_CKPT]参数指定对应的checkpoint文件即可。
五、评估过程
运行run_eval.sh进行评估
bash scripts/run_eval_cpu.sh [DATASET_NAME] [DATASET_PATH] [CHECKPOINT_PATH]
检查eval/log.txt,将得到以下输出:
result: {'CRNNAccuracy': (0.806)}
训练时评估
添加并设置run_eval为True来启动shell,还需添加eval_dataset来选择评估数据集。如果希望在训练时进行评估,添加eval_dataset_path来启动shell。当run_eval为True时,可设置参数选项:save_best_ckpt、eval_start_epoch、eval_interval。
六、推理过程
导出MindIR
python export.py --ckpt_file [CKPT_PATH] --file_name [FILE_NAME] --file_format [FILE_FORMAT] --device_target [DEVICE_TARGET] --model_version [MODEL_VERSION](required for cpu)
必须设置ckpt_file参数。 FILE_FORMAT:取值范围[“AIR”, “MINDIR”]
在Ascend 310上推理
# Ascend 310推理
bash run_infer_310.sh [MINDIR_PATH] [DATA_PATH] [ANN_FILE_PATH] [DATASET] [DEVICE_ID]
推理结果保存在当前路径中,可以在acc.log文件中查看如下结果
correct num: 2042 , total num: 3000
result CRNNAccuracy is: 0.806666666666