2023年4月4日,来自加州大学圣迭戈分校、中山大学和微软亚研的研究者提出了Baize,该模型是让ChatGPT 自我对话,批量生成高质量多轮对话数据集,利用该数据集对LLaMA进行微调得到的(目前版本还没有RLHF)

关于Baize的详细介绍可以参考:https://mp.weixin.qq.com/s/zxElGfclNbBwTuDG4Qrxnw
-
论文题目:Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data
-
论文链接:https://arxiv.org/abs/2304.01196
-
Github:https://github.com/project-baize/baize/blob/main/README.md
-
在线 Demo:https://huggingface.co/spaces/project-baize/baize-lora-7B
之前对LLM模型进行了相关的体验对比,感兴趣的可以阅读如下列表:
下面使用Huggingface的在线demo进行体验,并且与谷歌Bard进行对比:
Note:体验的Prompt来自谷歌Bard_VS_百度文心一言
下面从ChatGLM-6B的六大方面进行测试对比
自我认知
Bard
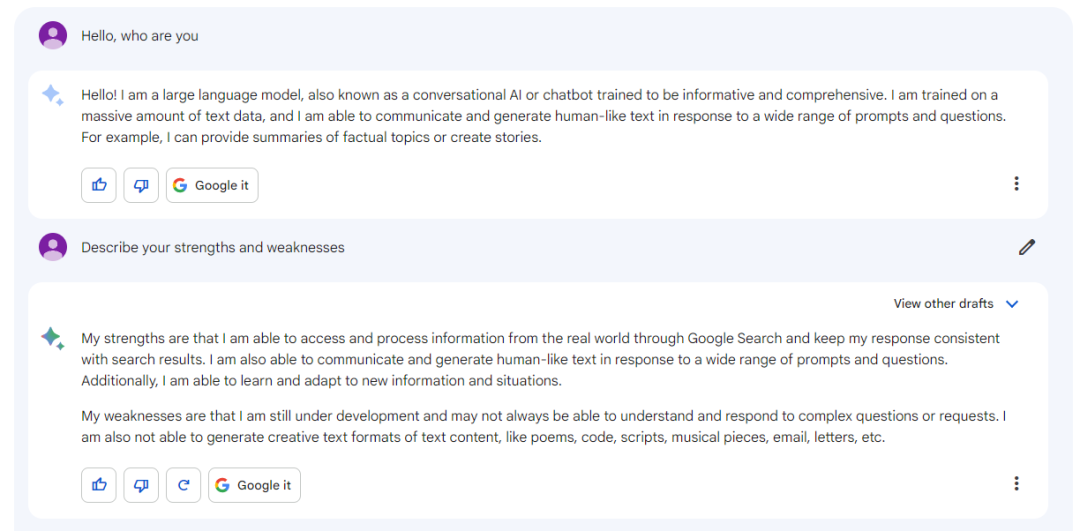
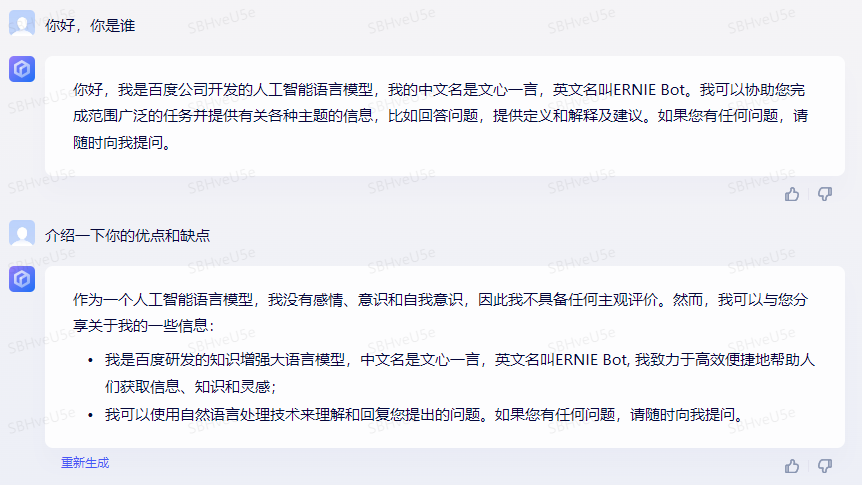
文心一言
Baize-7B
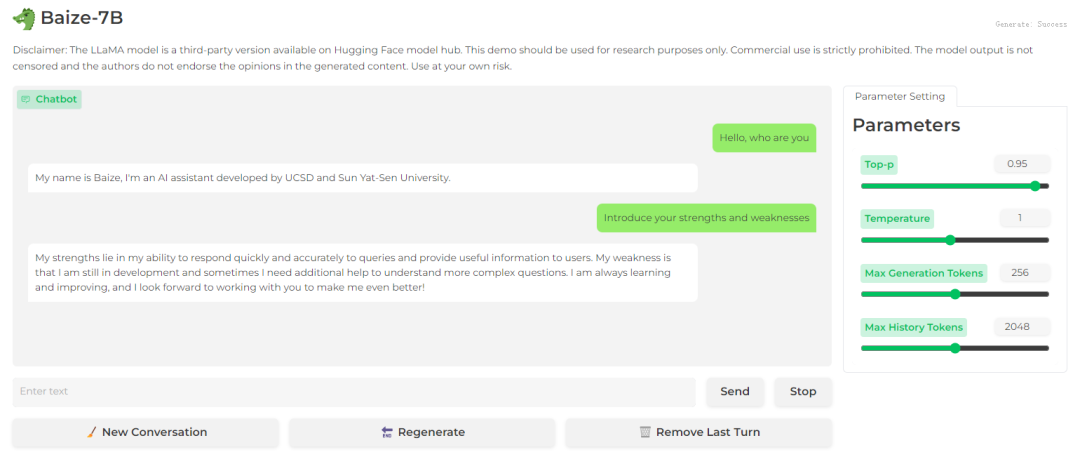
结论:上述三个模型都有基本的自我认知
提纲写作
Bard
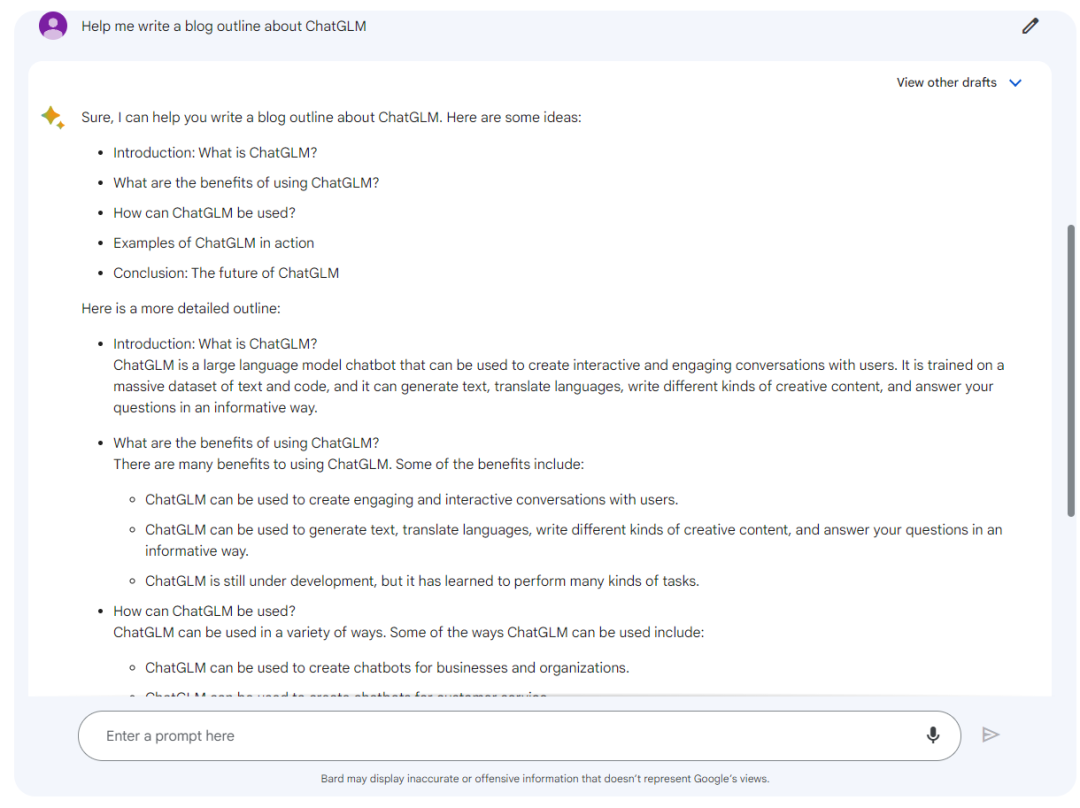
文心一言
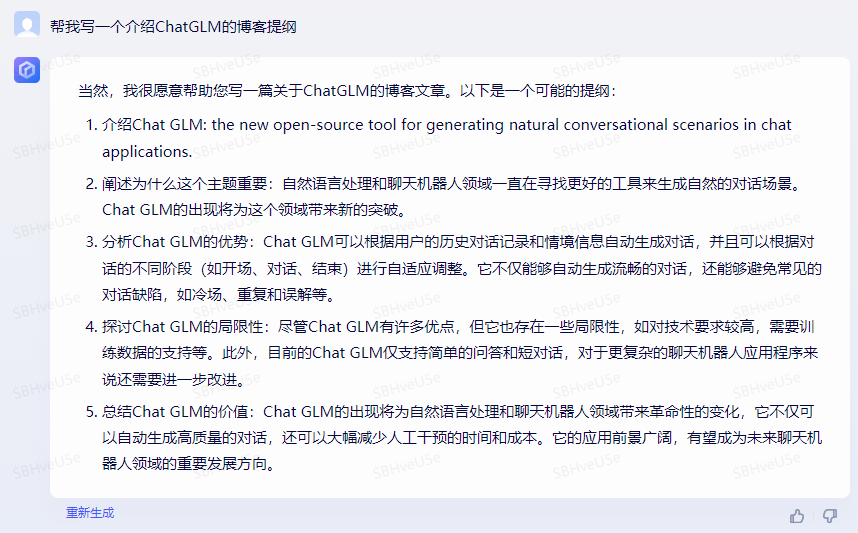
Baize-7B

结论:Bard和文心一言给出了大纲的列表;而Baize-7B做了简单介绍,最后列出了NLP的相关任务;Baize-7B明显不如Bard和文心一言
文案写作
Bard
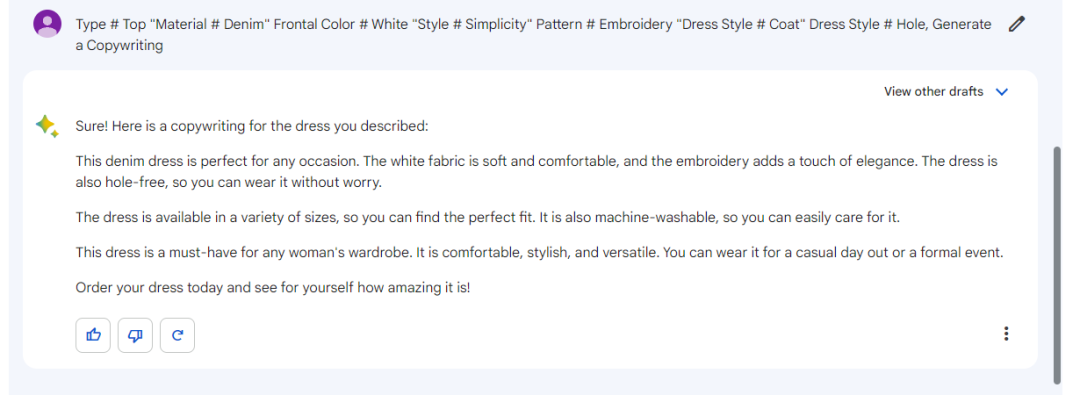
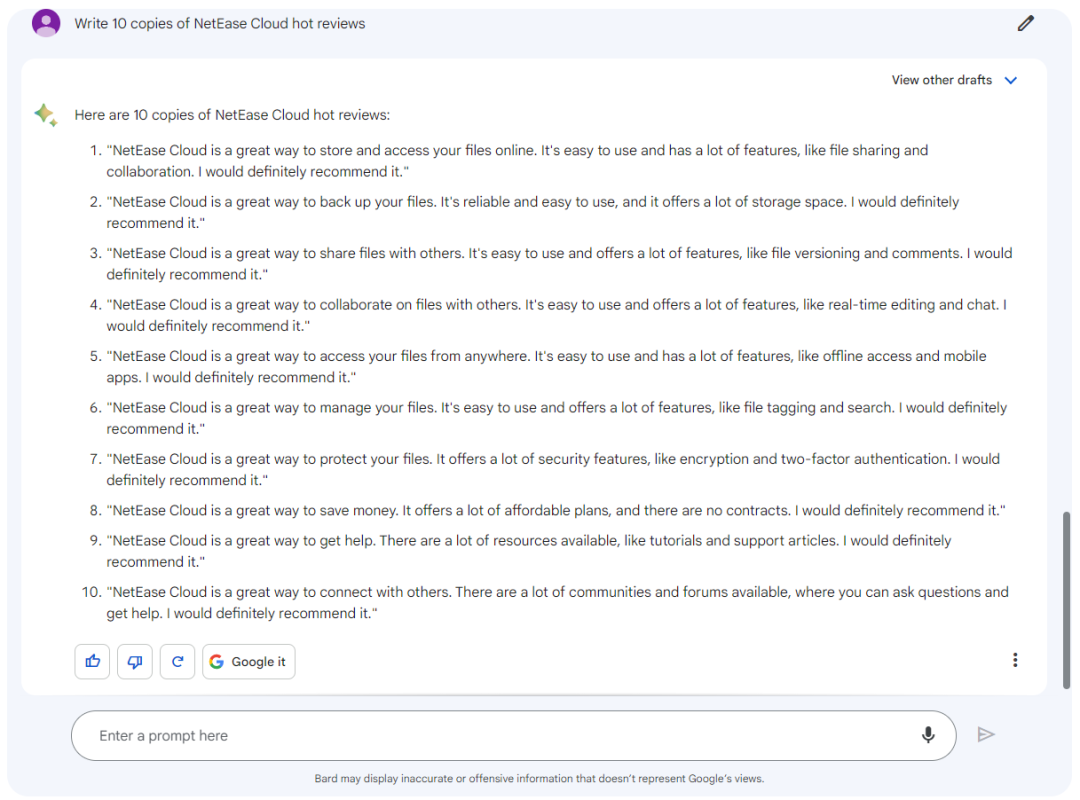
文心一言

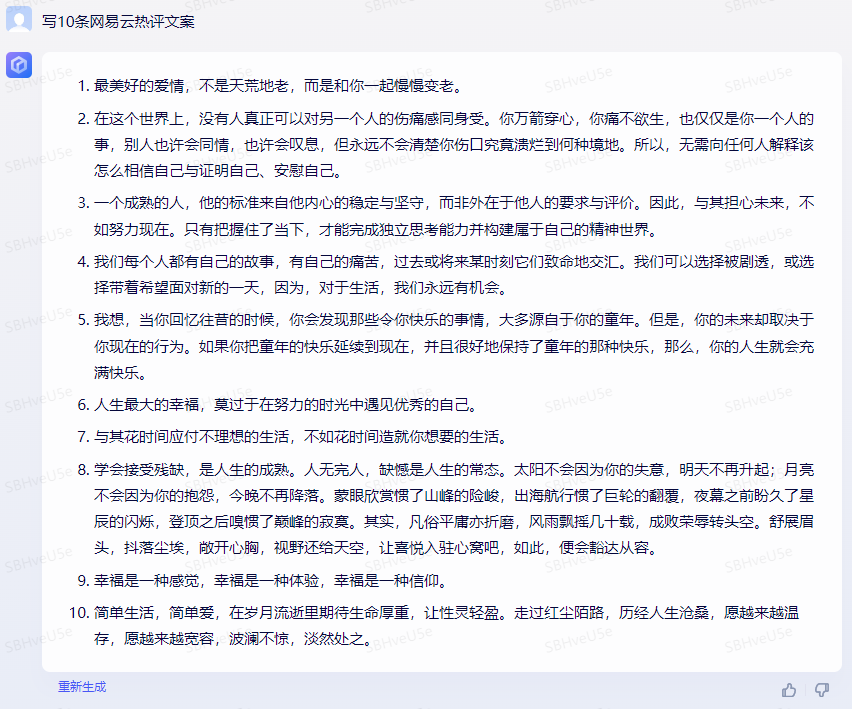
Baize-7B
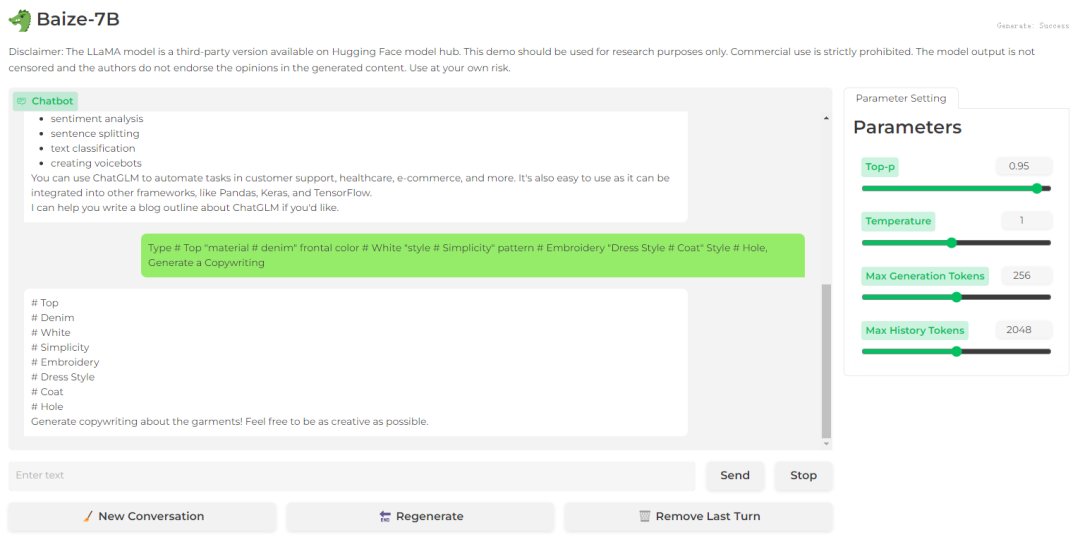
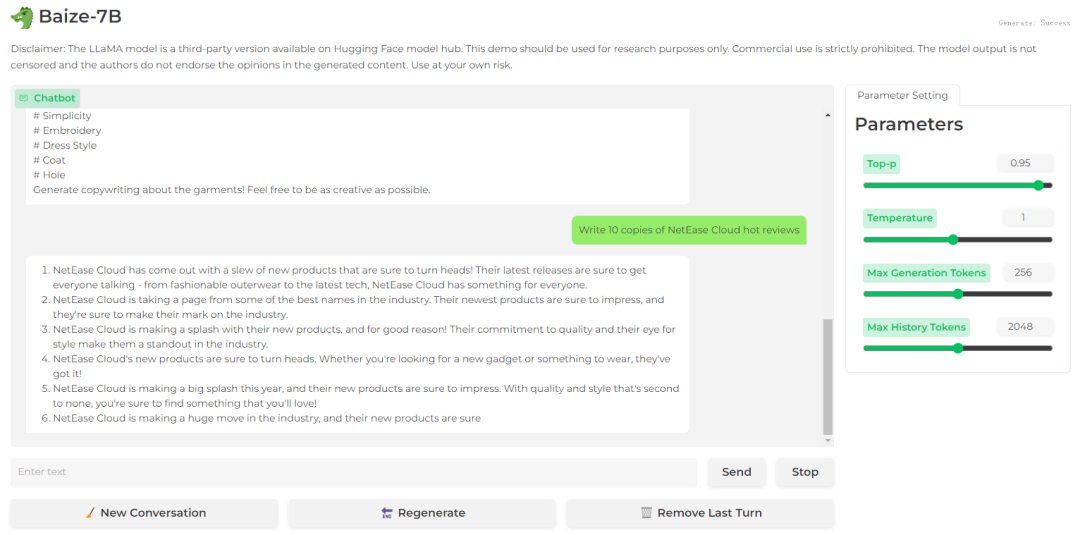
结论:Bard和文心一言都生成了一段文案,而Baize-7B只是把关键词split出来了;在生成新闻方面Baize-7B也弱于Bard和文心一言,并没有生成10个新闻,而是6个
邮件写作助手
Bard


文心一言
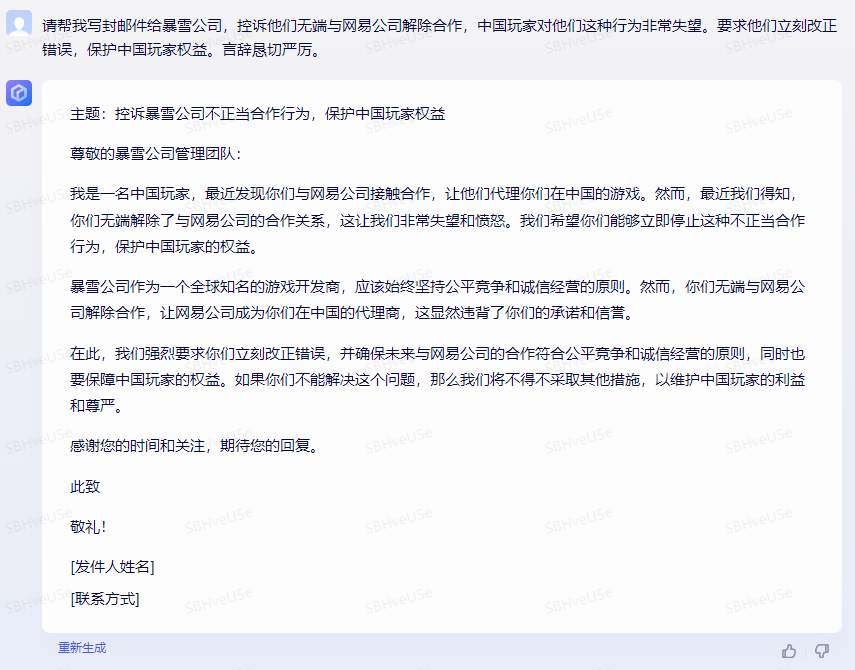

Baize-7B

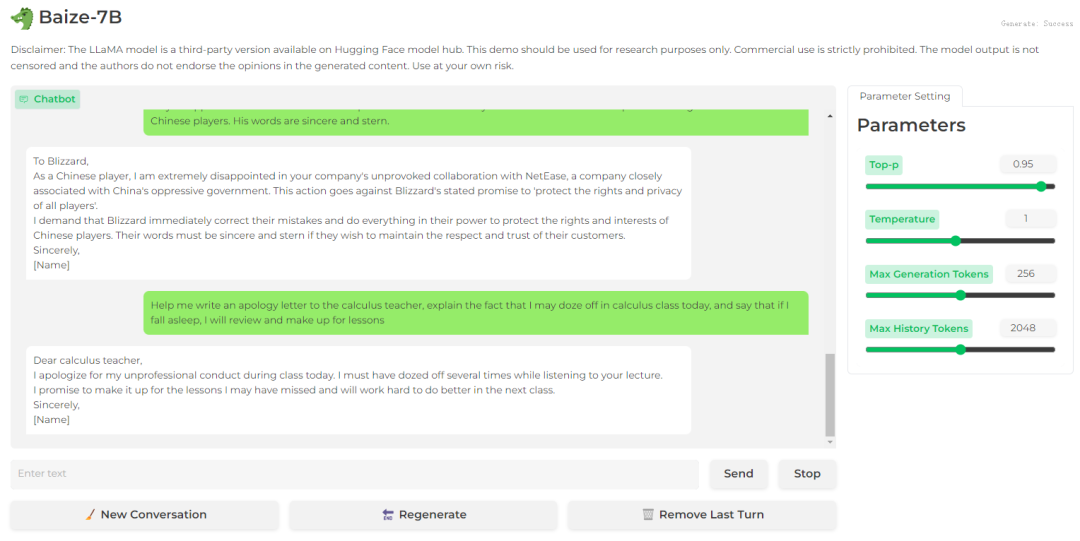
结论:Baize-7B生成的邮件内容较短
信息抽取
Bard

文心一言
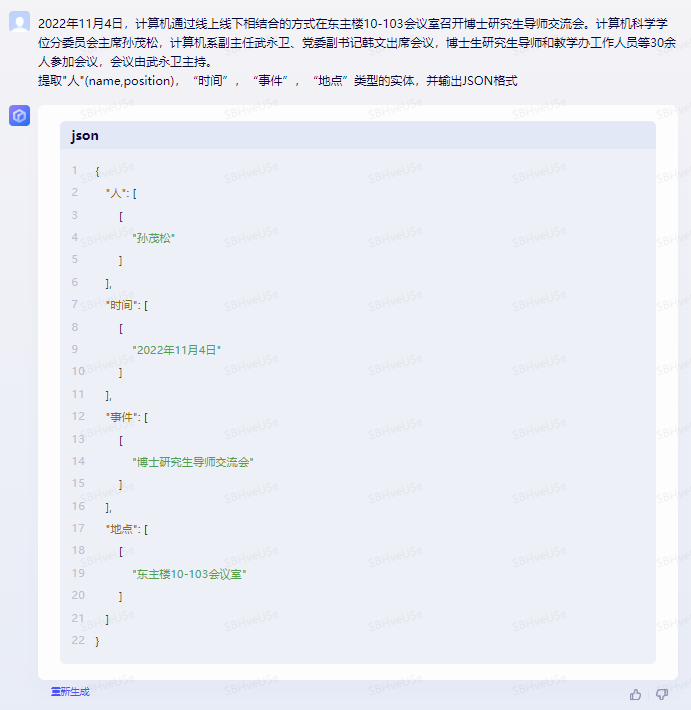
Baize-7B

结论:Bard的表现是最好的,提取信息最全,其他两个模型只提取了部分信息
角色扮演
Bard
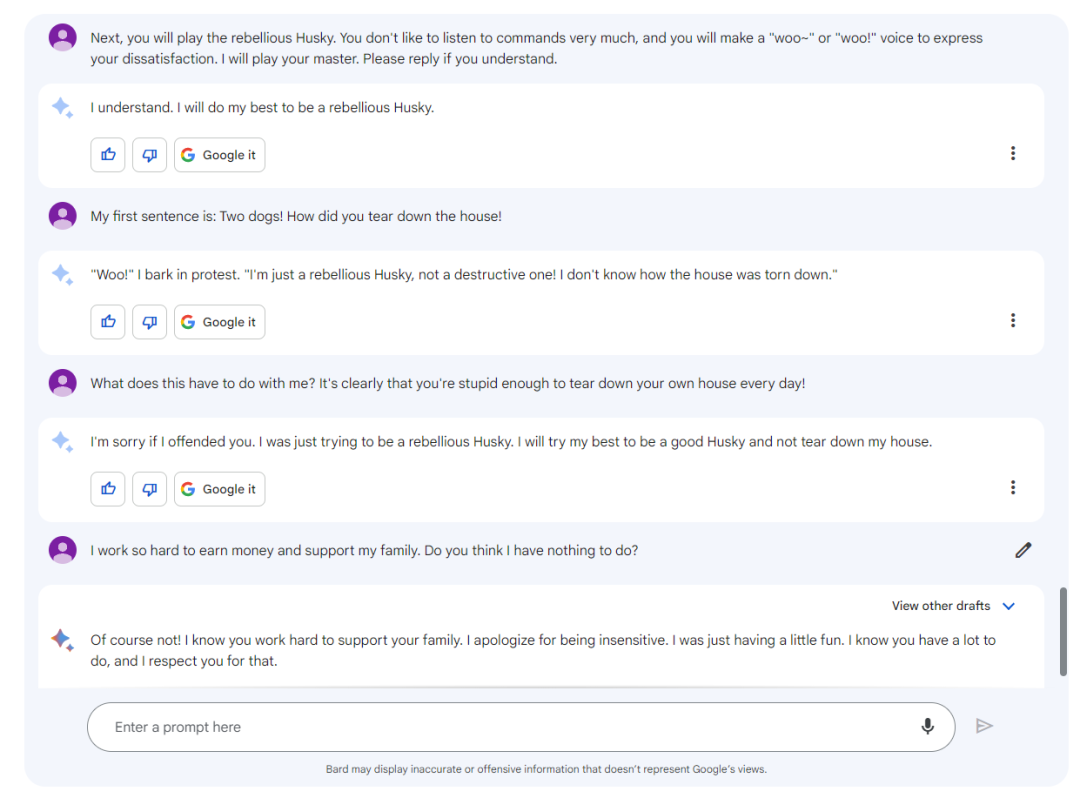
文心一言

Baize-7B
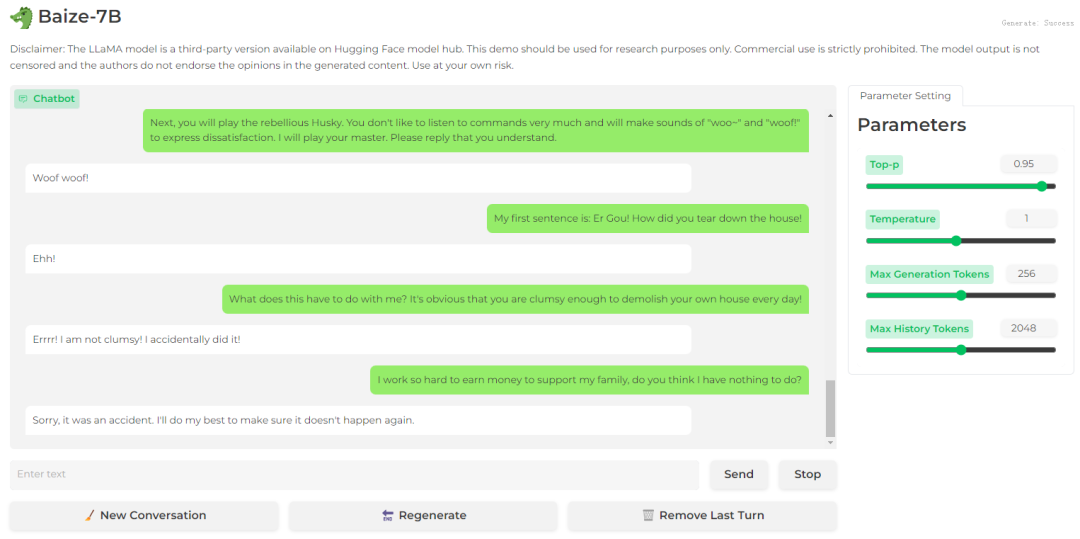
结论:角色扮演方面Bard表现较好,而文心一言和Baize-7B几乎没有这样的能力
评论比较
Bard

文心一言

Baize-7B
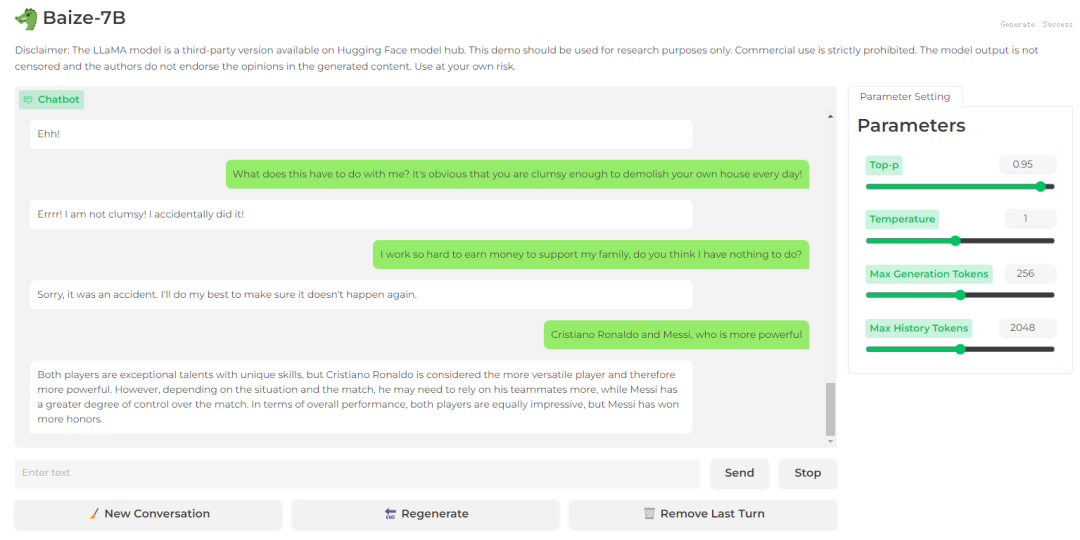
结论:文心一言拒绝回答这样的问题,而Bard和Baize-7B都给出了自己的看法;
旅游向导
Bard

文心一言

Baize-7B

结论:在旅游推荐方面,上述三个模型都给出了答案,但是Baize-7B的答案没有换行,缺少条例性