一.异常处理认识
1.基础认识
开发人员在编写程序时,难免会遇到错误,有的是编写人员疏忽造成的语法错误,有的是程序内部隐含逻辑问题造成的数据错误,还有的是程序运行时与系统的规则冲突造成的系统错误,等等。总的来说,编写程序时遇到的错误可大致分为 2 类,分别为语法错误和运行时错误。
2.python语法错误
语法错误,也就是解析代码时出现的错误。当代码不符合 Python 语法规则时,Python解释器在解析时就会报出 SyntaxError 语法错误,与此同时还会明确指出最早探测到错误的语句。例如:print "Hello,World!"
我们知道,Python 3 已不再支持上面这种写法,所以在运行时,解释器会报如下错误:
SyntaxError: Missing parentheses in call to ‘print’
我们来学英语–syntax: n.句法、句法规则、语构
语法错误多是开发者疏忽导致的,属于真正意义上的错误,是解释器无法容忍的,因此,只有将程序中的所有语法错误全部纠正,程序才能执行。
3.运行时错误
运行时错误,即程序在语法上都是正确的,但在运行时发生了错误。例如:a = 1/0
上面这句代码的意思是“用 1 除以 0,并赋值给 a 。因为 0 作除数是没有意义的,所以运行后会产生如下错误:
a = 1/0
Traceback (most recent call last):
File “<pyshell#2>”, line 1, in
a = 1/0
ZeroDivisionError: division by zero
以上运行输出结果中,前两段指明了错误的位置,最后一句表示出错的类型。在 Python 中,把这种运行时产生错误的情况叫做异常(Exceptions)。
在Python中,常见的异常情况有以下几种:

- SyntaxError:语法错误,通常是程序编写时出现的,例如使用了不合法的标识符、不完整的语句等。
- NameError:名称错误,通常是因为使用了不存在的变量或函数名造成的。
- TypeError:类型错误,通常是因为使用了不匹配的数据类型造成的,例如将字符串和数字相加或将元组和列表进行比较等。
- ValueError:数值错误,通常是因为使用了无效的数值,例如将一个无法转换为整数的字符串转换为整数类型。
- IndexError:索引错误,通常是因为使用了超出范围的索引或切片造成的。
- KeyError:键错误,通常是因为使用了不存在的键或没有初始化的字典造成的。
- AttributeError:属性错误,通常是因为使用了不存在的属性或操作不合法的属性造成的。
- ZeroDivisionError:除零错误,通常是因为在除法运算中分母为零造成的。
一般情况下,Python中的异常都能够给出明确的提示信息,有助于我们快速准确定位问题所在。在处理异常时,我们可以使用try…except…finally语句块进行处理,避免程序因为异常而意外终止。
4.异常处理
当一个程序发生异常时,代表该程序在执行时出现了非正常的情况,无法再执行下去。默认情况下,程序是要终止的。如果要避免程序退出,可以使用捕获异常的方式获取这个异常的名称,再通过其他的逻辑代码让程序继续运行,这种根据异常做出的逻辑处理叫作异常处理。
开发者可以使用异常处理全面地控制自己的程序。异常处理不仅仅能够管理正常的流程运行,还能够在程序出错时对程序进行必的处理。大大提高了程序的健壮性和人机交互的友好性。
二.异常处理
1.try except异常处理
Python 中,用try except语句块捕获并处理异常,其基本语法结构如下所示:
try:
可能产生异常的代码块
except [ (Error1, Error2, ... ) [as e] ]:
处理异常的代码块1
except [ (Error3, Error4, ... ) [as e] ]:
处理异常的代码块2
except [Exception]:
处理其它异常
该格式中,[] 括起来的部分可以使用,也可以省略。其中各部分的含义如下:
- (Error1, Error2,…) 、(Error3, Error4,…):其中,Error1、Error2、Error3 和 Error4 都是具体的异常类型。显然,一个 except 块可以同时处理多种异常。
- [as e]:作为可选参数,表示给异常类型起一个别名 e,这样做的好处是方便在 except 块中调用异常类型(后续会用到)。
- [Exception]:作为可选参数,可以代指程序可能发生的所有异常情况,其通常用在最后一个 except 块。
从try except的基本语法格式可以看出,try 块有且仅有一个,但 except 代码块可以有多个,且每个 except 块都可以同时处理多种异常。
当程序发生不同的意外情况时,会对应特定的异常类型,Python 解释器会根据该异常类型选择对应的 except 块来处理该异常。
try except 语句的执行流程如下:
- 首先执行 try 中的代码块,如果执行过程中出现异常,系统会自动生成一个异常类型,并将该异常提交给 Python 解释器,此过程称为捕获异常。
- 当 Python 解释器收到异常对象时,会寻找能处理该异常对象的 except 块,如果找到合适的 except 块,则把该异常对象交给该 except 块处理,这个过程被称为处理异常。如果 Python 解释器找不到处理异常的 except 块,则程序运行终止,Python 解释器也将退出。
2.try except例子
try:
a = int(input("输入被除数:"))
b = int(input("输入除数:"))
c = a / b
print("您输入的两个数相除的结果是:", c )
except (ValueError, ArithmeticError):
print("程序发生了数字格式异常、算术异常之一")
except :
print("未知异常")
print("程序继续运行")
程序运行结果:
输入被除数:10
输入除数:b
程序发生了数字格式异常、算术异常之一
程序继续运行
3.获取异常的信息
其实,每种异常类型都提供了如下几个属性和方法,通过调用它们,就可以获取当前处理异常类型的相关信息:
- args:返回异常的错误编号和描述字符串;
- str(e):返回异常信息,但不包括异常信息的类型;
- repr(e):返回较全的异常信息,包括异常信息的类型。
举个例子:
try:
1/0
except Exception as e:
# 访问异常的错误编号和详细信息
print(e.args)
print(str(e))
print(repr(e))
输出结果:
(‘division by zero’,)
division by zero
ZeroDivisionError(‘division by zero’)
除此之外,如果想要更加详细的异常信息,可以使用 traceback 模块。
从程序中可以看到,由于 except 可能接收多种异常,因此为了操作方便,可以直接给每一个进入到此 except 块的异常,起一个统一的别名 e。
4.捕获同样异常
一个 try 块也可以对应多个 except 块,一个 except 块可以同时处理多种异常。如果我们想使用一个 except 块处理所有异常,就可以这样写:
try:
#...
except Exception:
#...
这种情况下,对于 try 块中可能出现的任何异常,Python 解释器都会交给仅有的这个 except 块处理,因为它的参数是 Exception,表示可以接收任何类型的异常。
下面举一个例子:
try:
a = int(input("输入 a:"))
b = int(input("输入 b:"))
print( a/b )
except ValueError:
print("数值错误:程序只能接收整数参数")
except ArithmeticError:
print("算术错误")
except Exception:
print("未知异常")
这里刚开始,或许有些疑惑,不是说Exception是所有通用异常吗,那为什么发生这个valueerror错误时,程序执行第一个except模块不是执行最后这个通用的异常模块呢?这是因为程序是顺序执行的,在捕获这个异常后比对第一个except模块时,比对成功就执行它了,执行完就跳出try模块了。所以如果你把第三个except Exception模块放在第一个,他就会执行这个模块。
三.try except模块补充
1.补充else
在原本的try except结构的基础上,Python 异常处理机制还提供了一个 else 块,也就是原有 try except 语句的基础上再添加一个 else 块,即try except else结构。
使用 else 包裹的代码,只有当 try 块没有捕获到任何异常时,才会得到执行;反之,如果 try 块捕获到异常,即便调用对应的 except 处理完异常,else 块中的代码也不会得到执行。
举个例子:
try:
result = 20 / int(input('请输入除数:'))
print(result)
except ValueError:
print('必须输入整数')
except ArithmeticError:
print('算术错误,除数不能为 0')
else:
print('没有出现异常')
print("继续执行")
2.finally:资源回收
Python 异常处理机制还提供了一个 finally 语句,通常用来为 try 块中的程序做扫尾清理工作。
注意,和 else 语句不同,finally 只要求和 try 搭配使用,而至于该结构中是否包含 except 以及 else,对于 finally 不是必须的(else 必须和 try except 搭配使用)。
在整个异常处理机制中,finally 语句的功能是:无论 try 块是否发生异常,最终都要进入 finally 语句,并执行其中的代码块。
基于 finally 语句的这种特性,在某些情况下,当 try 块中的程序打开了一些物理资源(文件、数据库连接等)时,由于这些资源必须手动回收,而回收工作通常就放在 finally 块中。
Python 垃圾回收机制,只能帮我们回收变量、类对象占用的内存,而无法自动完成类似关闭文件、数据库连接等这些的工作。
3.结构流程图
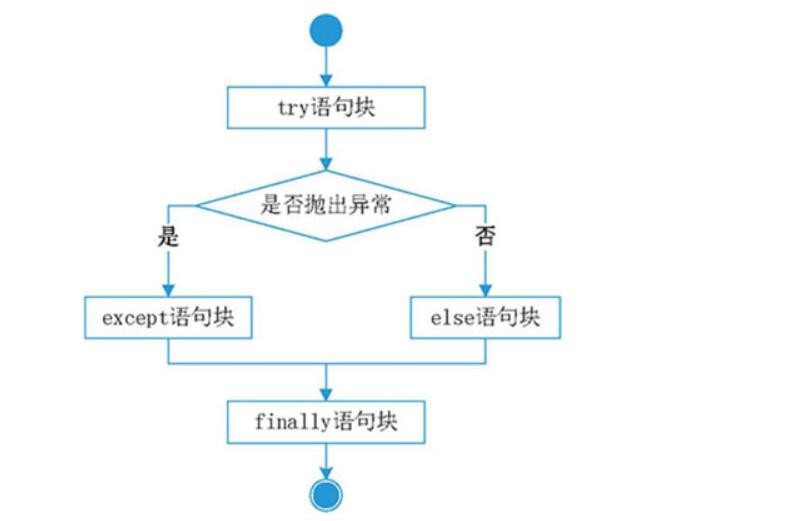
四.手动抛出异常
1.个人理解
由于在python中不像其他编程语言,定义一个变量前面需要用数据类型定义,所以python中的一个变量可以是任何数据类型。现在假设你用一个变量存入用户的电话(纯数字),但是现在有的用户它输入的是字母,程序并没有出现逻辑错误,检测不到异常,直到最后输出结果你才会发现报错。这个时候,就需要你自己手动来抛出这个异常。所谓抛出这个异常,就是使用raise告诉程序这里出现了异常,然后程序寻找对应的except模块进行处理,如果找不到就中止程序并报错。
2.raise语句
raise 语句的基本语法格式为:raise [exceptionName [(reason)]]
其中,用 [] 括起来的为可选参数,其作用是指定抛出的异常名称,以及异常信息的相关描述。如果可选参数全部省略,则 raise 会把当前错误原样抛出;如果仅省略 (reason),则在抛出异常时,将不附带任何的异常描述信息。
也就是说,raise 语句有如下三种常用的用法:
- raise:单独一个 raise。该语句引发当前上下文中捕获的异常(比如在 except 块中),或默认引发 RuntimeError 异常。
- raise 异常类名称:raise 后带一个异常类名称,表示引发执行类型的异常。
- raise 异常类名称(描述信息):在引发指定类型的异常的同时,附带异常的描述信息。
我们来用一个例子来了解它:
try:
a = input("输入一个数:")
#判断用户输入的是否为数字
if(not a.isdigit()):
raise ValueError("a 必须是数字")
except ValueError as e:
print("引发异常:",repr(e))
程序运行结果为:
输入一个数:a
引发异常: ValueError(‘a 必须是数字’,)
可以看到,当用户输入的不是数字时,程序会进入 if 判断语句,并执行 raise 引发 ValueError 异常。但由于其位于 try 块中,因为 raise 抛出的异常会被 try 捕获,并由 except 块进行处理。因此,虽然程序中使用了 raise 语句引发异常,但程序的执行是正常的,手动抛出的异常并不会导致程序崩溃。
注意:这里的raise可以不带参数,这样他抛出的就是默认的RuntimeError 异常。
3.获取异常信息
捕获异常时,有 2 种方式可获得更多的异常信息,分别是:
- 使用 sys 模块中的 exc_info 方法;
- 使用 traceback 模块中的相关函数。
模块 sys 中,有两个方法可以返回异常的全部信息,分别是 exc_info() 和 last_traceback(),这两个函数有相同的功能和用法,本节仅以 exc_info() 方法为例。
exc_info() 方法会将当前的异常信息以元组的形式返回,该元组中包含 3 个元素,分别为 type、value 和 traceback,它们的含义分别是:
- type:异常类型的名称,它是 BaseException 的子类
- value:捕获到的异常实例。
- traceback:是一个 traceback 对象。
举个例子:
#使用 sys 模块之前,需使用 import 引入
import sys
try:
x = int(input("请输入一个被除数:"))
print("30除以",x,"等于",30/x)
except:
print(sys.exc_info())
print("其他异常...")
当输入 0 时,程序运行结果为:
请输入一个被除数:0
(<class ‘ZeroDivisionError’>, ZeroDivisionError(‘division by zero’,), <traceback object at 0x000001FCF638DD48>)
其他异常…
输出结果中,第 2 行是抛出异常的全部信息,这是一个元组,有 3 个元素,第一个元素是一个 ZeroDivisionError 类;第 2 个元素是异常类型 ZeroDivisionError 类的一个实例;第 3 个元素为一个 traceback 对象。其中,通过前 2 个元素可以看出抛出的异常类型以及描述信息,对于第 3 个元素,是一个 traceback 对象,无法直接看出有关异常的信息,还需要对其做进一步处理。
4. traceback 模块
要查看 exc_info() 方法返回的traceback 对象包含的内容,需要先引进 traceback 模块,然后调用 traceback 模块中的 print_tb 方法,并将 sys.exc_info() 输出的 traceback 对象作为参数参入。例如:
#使用 sys 模块之前,需使用 import 引入
import sys
#引入traceback模块
import tracebacktry:
x = int(input("请输入一个被除数:"))
print("30除以",x,"等于",30/x)
except:
#print(sys.exc_info())
traceback.print_tb(sys.exc_info()[2])
print("其他异常...")
输入 0,程序运行结果为:
请输入一个被除数:0
File “C:\Users\mengma\Desktop\demo.py”, line 7, in
print(“30除以”,x,“等于”,30/x)
其他异常…
可以看到,输出信息中包含了更多的异常信息,包括文件名、抛出异常的代码所在的行数、抛出异常的具体代码。
五.自定义异常
1.自定义异常
其实,在前面章节中,已经涉及到了异常类的创建,例如:
class SelfExceptionError(Exception):
pass
try:
raise SelfExceptionError()
except SelfExceptionError as err:
print("捕捉到自定义异常")
运行结果为:
捕捉到自定义异常
可以看到,此程序中就自定义了一个名为 SelfExceptionError 的异常类,只不过该类是一个空类。
另外,系统自带的异常只要触发会自动抛出(比如 NameError、ValueError 等),但用户自定义的异常需要用户自己决定什么时候抛出。也就是说,自定义的异常需要使用 raise 手动抛出。
2.使用异常机制
成功的异常处理应该实现如下 4 个目标:
- 使程序代码混乱最小化。
- 捕获并保留诊断信息。
- 通知合适的人员。
- 采用合适的方式结束异常活动。
不可否认,Python 的异常机制确实方便,但滥用异常机制也会带来一些负面影响。过度使用异常主要表现在两个方面:
- 把异常和普通错误混淆在一起,不再编写任何错误处理代码,而是以简单地引发异常来代苦所有的错误处理。
- 使用异常处理来代替流程控制。熟悉了异常使用方法后,程序员可能不再愿意编写烦琐的错误处理代码,而是简单地引发异常。实际上这样做是不对的,对于完全己知的错误和普通的错误,应该编写处理这种错误的代码,增加程序的健壮性。只有对于外部的、不能确定和预知的运行时错误才使用异常。
六.调试程序
无论使用哪种编程语言,最常用的调试代码的方式是:使用输出语句(比如 C 语言中使用 printf,Python 中使用 print() 函数)输出程序运行过程中一些关键的变量的值,查看它们的值是否正确,从而找到出错的地方。这种调试方法最大的缺点是,当找到问题所在之后,需要再将用于调试的输出语句删掉。
1. logging 模块
Python的logging模块可以帮助我们在程序运行时记录日志信息,从而方便调试和排错。
使用logging模块,需要先进行初始化:
import logging
# 设置日志级别
logging.basicConfig(level=logging.DEBUG)
# 获取Logger实例
logger = logging.getLogger(__name__)
其中,basicConfig()函数用于配置日志的基础设置,包括日志级别、输出格式等。这里指定了日志级别为DEBUG,表示所有级别的日志都会被记录下来。
然后,就可以在代码中通过以下方式记录日志信息:
logger.debug('Debug information')
logger.info('Informational message')
logger.warning('Warning: %s', 'Danger, Will Robinson!')
logger.error('Error occurred')
logger.critical('Critical error -- aborting')
这些日志信息会根据其级别被记录到对应的输出渠道中,如控制台、文件等。默认情况下,日志信息会输出到标准输出(控制台)。
如果需要将日志输出到文件中,可以使用FileHandler类:
file_handler = logging.FileHandler('debug.log')
logger.addHandler(file_handler)
这里创建了一个名为debug.log的日志文件,并将FileHandler实例添加到logger中,从而将日志信息输出到该文件中。
2.IDLE调试程序
这里以pycharm为例:
使用 PyCharm 调试程序,可以方便地对代码进行单步调试、断点调试、变量监视等操作。下面是简要的调试流程:
- 打开 PyCharm 并打开需要调试的 Python 项目。
- 在 PyCharm 主界面中点击右上角的 Debug 按钮,或者使用快捷键 Shift+F9 进入调试模式。
- 在弹出的窗口中选择需要调试的 Python 文件并设置 breakpoints(断点)。可以在代码行号左侧点击一次来设置或取消一个断点,也可以通过右键点击相应代码行并选择 Toggle breakpoint 来设置断点。
- 点击 Debug 或者使用快捷键 F9 开始运行程序。运行过程中程序会在遇到断点时暂停执行,等待用户操作。
- 进入调试模式后,可以使用 Step Over(F10)、Step Into(F11)和 Step Out(Shift+F11)等命令分别进行单步调试、进入函数/方法调用以及从当前函数/方法返回。
- 在程序暂停执行时,可以查看变量的值、调用栈信息等内容。可以在 Debug 窗口的 Variables 和 Debugger tabs 中查看当前所有可用的变量及其值,并且还可以使用 Evaluate Expression 功能实时计算某个表达式的值。
- 在调试完成后,可以按下 Stop 按钮或者使用快捷键 Shift+F2 停止调试并退出调试模式。
3.Python assert调试程序
我们在一篇博客已经了解使用了assert语句,同时我们也可以使用它来调试程序。
通常情况下,assert 可以和 try except 异常处理语句配合使用,以前面代码为例:
try:
s_age = input("请输入您的年龄:")
age = int(s_age)
assert 20 < age < 80 , "年龄不在 20-80 之间"
print("您输入的年龄在20和80之间")
except AssertionError as e:
print("输入年龄不正确",e)
程序运行结果为:
请输入您的年龄:10
输入年龄不正确 年龄不在 20-80 之间
通过在程序的适当位置,使用 assert 语句判断变量或表达式的值,可以起到调试代码的作用。