搜索系统的运行,简单来说,将用户的搜索词经过处理后,从数据库中找出答案,现在只聊智能问答的搜索系统,系统前期需要做数据存入,用户搜索时候再做数据读取,因此分为两个部分来讲。
1.数据存入
数据需要存入图数据库,
1.1,构建图谱需要根据非结构化数据情况,和项目需求定义需要抽取的实体类别和实体之间的关系,例如根据用户问法,想要查询出什么答案,根据答案内容定义实体类别和关系。
1.2,模型抽取,构建完实体后,接下来从非结构文本中抽取信息,我使用的是paddleNLP中信息抽取框架uie,
需要先按照实体标注规范标注模型训练集,然后训练出实体抽取模型,接下来抽取非结构化文档数据,抽取后的实体按照图谱标准格式存入图数据库和ES中。
具体实操步骤参考链接: link
2.数据读取
接下来直接使用paddleNLP中智能问答系统来搭建
简单介绍智能问答系统,问答系统是信息检索系统的一种高级形式,通过对用户输入的问题进行理解,然后从知识库中寻找答案,并直接反馈给用户。
使用paddleNLP中的问答系统,只用简单处理好自己的数据,并接入智能问答系统,
具体操作步骤以及常见问题,详见我之间的文档链接: link
我直接使用的是智能问答系统的后端,并且更换为自己的ES库,
paddleNLP中的智能问答系统预置的问答系统模型(召回模型、排序模型、阅读理解模型),
语义检索系统
1.场景概述
检索系统用户通过输入检索词Query,快速在海量数据中查找相关文档,其中包含语义检索系统,所谓的语义检索,其实也叫基于向量的检索,是指检索系统不在拘泥用户Query字面本身,而是能精准捕捉到用户Query后面的真正意图并以此搜索,从而精准向用户返回符合的结果,通过最先进的语义索引模型找到文本的向量表示,在高纬度空间中对它们进行索引,并度量查询向量与索引文章的相似程度,从而解决关键词索引带来的缺陷。
2.功能架构
语义索引能够较好地表征语义信息,语义检索系统的关键在于,采用语义而非关键词方式进行召回,达到更精准,更广泛的召回相似结果的目的,整体介绍如下:
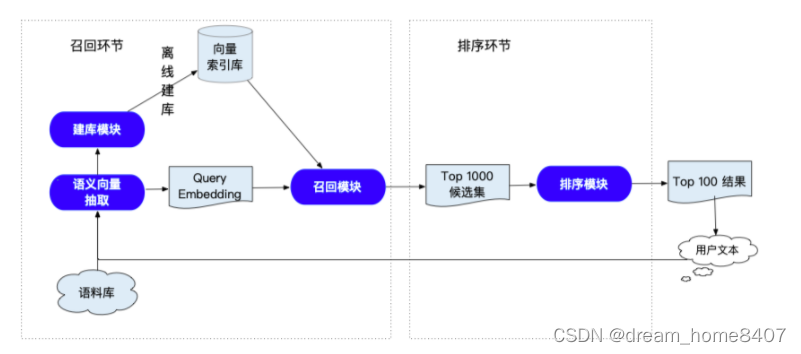
左侧是召回环节,核心是语义向量抽取模块,右侧是排序环节,核心是排序模型,召回环节需要用户通过自己的语料构建向量索引库,用户发起query之后,
就可以检索出相似度最高的向量,然后找出该向量对应的文本,排序环节主要对召回的文本进行重新排序,
召回模块
召回模块需要从千万量级数据中快速召回候选数据,首先需要抽取语料库中文本的Embedding,然后借助向量所有引擎例如Milvus实现高效ANN,从而实现候选集召回.召回模块负责从海量(千万级)候选文本中快速(毫秒级)筛选与有户查询词Query相关性较高的TopK Doc,
向量搜索引擎中的ANN用于高效的近似最近邻搜索(Approximate Nearest Neighbor Search)。在大规模数据集中,通过遍历每个数据点以查找最近邻是非常耗时的。ANN利用神经网络的并行性和分布式表示,通过构建一个高效的索引结构,可以加速最近邻搜索的过程。
ANN可以采用多种结构和算法,如k最近邻树(k-d tree)、球树(ball tree)、哈希表(hashing)、局部敏感哈希(LSH)等。这些方法基于不同的原理和数据结构,旨在快速识别与查询向量最接近的数据点,而不需要对整个数据集进行全局搜索。
milvus
排序模块
排序模型会在召回模型筛选出TopK Doc结果的基础上针对每一个Query,Doc进行两两匹配计算相关性,排序效法户更精准,
排序模块,是基于一种预训练模型ERNIE,训练Pair-wise语义匹配模型,基本思路是对样本构建文档对,两两比较,从比较中学习顺序,
评估指标
模型效果指标
1.语义检索召回阶段使用的指标是Recall@K,表示的是预测前topk结果和语料库中真实的前k个相关结果的重叠率,衡量的事检索系统的查全率,
2.排序阶段使用的指标为AUC,AUC反映的是分类器对样本的排序能力,如果完全随机对样本分类,那么AUC应该接近0.5,分类器越可能把真正的正样本排在前面,AUC值越大,分类性能越好.
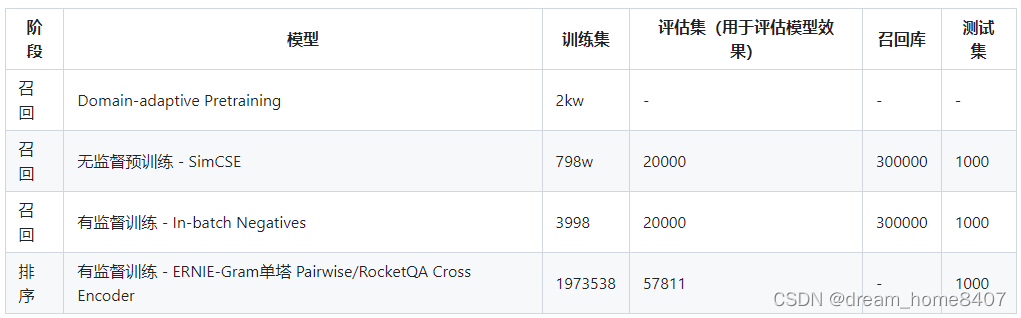
模型训练
(1)采用文献的 query, title,keywords,abstract 四个字段内容,构建无标签数据集进行 Domain-adaptive Pretraining;
(2)采用文献的 query,title,keywords 三个字段内容,构造无标签数据集,进行无监督召回训练SimCSE;
(3)使用文献的query, title, keywords,构造带正标签的数据集,不包含负标签样本,基于 In-batch Negatives 策略进行训练;
(4).排序阶段,使用用户点击( 作为正样本)和展现未点击(作为负样本)数据构造排序阶段的训练集,进行精排训练.

第一阶段使用的是Domain-adaptive pretrain 鲸鱼子使用预训练,是自然语言处理中一种用于优化预训练模型在特定领域中性能的技术,它目的是在特定领域数据上进行微调,使预训练模型适应目标领域,以下是该过程详细解释
1.预训练,首先使用ERNIE、BERT或者GPT,使用无监督学习在大规模通用语料库上进行预训练,在训练过程中,模型预测文本中的掩码单词或者句子来学习通用语言表示,这一步是为模型提供强大的语言理解能力,
2,收集特定领域的数据,为了使模型适应特定领域,
3.模型微调,手机特定领域的数据对预训练模型进行进一步微调,通过特定领域目标或者任务更新模型参数,并通过反向传播和梯度下降调整模型的权重,模型通过优化特定领域任务目标函数是使用特定领域数据来适应目标领域。
4.迁移学习,在特定领域进行微调后,适应的模型可以在目标领域中用于下游任务。
domain_adaptive_pretraining/
|—— scripts
|—— run_pretrain_static.sh # 静态图与训练bash脚本
├── ernie_static_to_dynamic.py # 静态图转动态图
├── run_pretrain_static.py # ernie1.0静态图预训练
├── args.py # 预训练的参数配置文件
└── data_tools # 预训练数据处理文件目录
SimCSE(Similarity Classification and Sentence Embedding)是一种用于学习句子表示和度量句子相似性的方法。SimCSE的目标是通过对输入句子进行编码,使得相似的句子在嵌入空间中更加接近,从而便于进行相似性度量和语义匹配任务。
SimCSE的核心思想是使用自我对比损失(Contrastive Loss)来训练模型。具体步骤如下:
句子编码:使用预训练的语言模型(如BERT)对输入句子进行编码,得到句子的表示向量。
对比样本生成:对于每个输入句子,随机选择一个正样本和若干个负样本。正样本是与输入句子语义相似的另一个句子,而负样本是与输入句子语义不相似的句子。
对比损失计算:计算输入句子与正样本的相似性得分,并将其与输入句子与负样本的相似性得分进行比较。常用的相似性度量方法包括余弦相似度和内积。对比损失通过最大化输入句子与正样本的相似性得分,并最小化输入句子与负样本的相似性得分来训练模型。
训练和优化:使用反向传播算法和梯度下降优化器来更新模型参数,使得对比损失尽可能小。
SimCSE训练完成后,可以使用训练好的句子编码模型来计算任意两个句子之间的相似性得分。这可以应用于多种自然语言处理任务,如句子相似性判定、问答匹配、信息检索等。
SimCSE的优点在于无需标注数据即可进行自监督学习,通过对比损失来学习句子表示,从而克服了传统监督学习方法中需要大量标注数据的限制。同时,SimCSE在大规模无标签数据上进行训练,可以学习到更通用、丰富的句子表示。
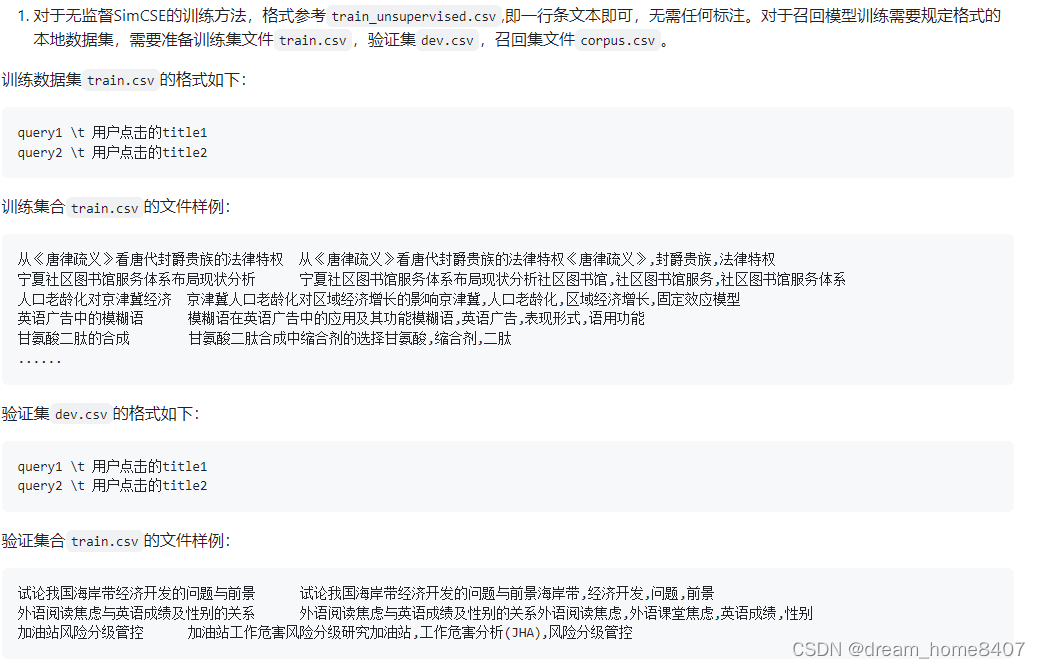
In-batch Negatives
link
如果想训练并接入自己训练的模型,对于召回和排序模型训练可以参考Neural Search,对于其中的答案抽取模型,训练教程请参考machine_reading_comprehension,召回和排序模型接入流程参考语义检索的Neural Search接入流程即可,阅读理解模型只需要在加载模型的时候,把模型名称换成您的模型的路径即可。
链接: link
代码解析
初始化Retriever Ranker Reader & Pipelines
1 Retriever
首先我们需要初始化一个Retriever,Retriever的作用是进行向量的抽取,实际使用的是DensePassageRetriever,DensePassageRetriever使用的是2个编码器模型,其中一个用来编码query文本,另一个编码passage文本,编码之后在检索阶段就比较query和passage两个向量。
2 Ranker
Ranker起到对retriever检索到的passage的重新排序,通过query和passage构成pair对,输入到模型进行打分,然后根据打分的分值对passage进行重新排序。这里使用的是ErnieRanker。
3 Reader
Reader的作用是扫描Rankder排序后的文本,然后抽取出最佳的K个答案,本项目使用的是ErnieReader,ErnieReader使用的是Ernie-Gram模型,并且在dureader数据集上进行了微调,用于答案片段的抽取。
链接: link